

Contents
- Introduction
- Important concepts for a Kubernetes backup process
- Why are K8s backups necessary?
- The value of Kubernetes backups
- The advantages of Kubernetes backup operations
- Kubernetes data types that need to be backed up
- What should you back up in a Kubernetes environment?
- How Does GitOps Affect Your Kubernetes Backup Strategy?
- Best practices for Kubernetes backup operations
- How should you design Kubernetes backup schedules and retention policies?
- How do you secure Kubernetes backups and meet compliance requirements?
- Methodology for choosing the best possible Kubernetes backup solution
- Kubernetes backup solution market
- What checklist should teams follow for Kubernetes backup readiness?
- The K8s backup solution from Bacula Enterprise
- Conclusion
- Why you can trust us
- Frequently Asked Questions
Introduction
Kubernetes (also known as K8s) is a container orchestration platform that helps manage and scale applications – often a preferred choice for companies that can take advantage of the containerized app architecture. The flexibility of Kubernetes means many deployments look very different from each other. However, unique structures typically bring with them unique recovery and uptime challenges, all of which are part of the challenge of using Kubernetes in your business IT infrastructure.
While an assumption about Kubernetes previously being used mainly by DevOps teams may have been somewhat correct, many companies are now actively deploying containers in operational environments. They are also increasingly relying on containers to deploy applications instead of using traditional VMs. This is due to the various advantages of flexibility, performance, and cost that containers can provide. However, as containers move into the operations side of the IT environment, there is increasing concern about the security aspects of containers in production systems that must stay available, including their persistent data in the context of backup and restore processes.
Originally, the overwhelming majority of containerized apps were stateless, allowing them to have a much easier deployment process on a public cloud. But that changed in time, with a lot more stateful applications being deployed in containers than before. This change is why backup and recovery in Kubernetes is now an important topic for a lot of organizations.
Important concepts for a Kubernetes backup process
- The importance of Kubernetes backups revolves around data security, since information is the most important resource of any modern business and almost always requires that this data is kept safe, secure and private. In the context of Kubernetes, valuable information usually also includes its configurations, secrets, etcd database, persistent volumes, etc.
- Proper backup strategy configuration can offer plenty of versatility and functionality to a Kubernetes environment, including app-level backups, namespace-level backups, snapshots, backup validation, versioning, backup policies, and many others.
- Correct restoration configuration is just as important, considering how many different parts of the process can potentially fail. Rigorous backup testing, documentation consulting, and constant vigilance during recovery are a part of what has to be maintained for successful recovery processes.
- Kubernetes backups can encounter a range of challenges – be it data consistency concerns, compliance standards, data security, and version compatibility, among others. The good news is that most of these pitfalls can be avoided or mitigated with a certain level of preparation.
Why are K8s backups necessary?
A Kubernetes environment is dynamic, distributed and inherently more prone to data loss than a conventional infrastructure. This section deals with the various failure factors that make backups indispensable, the different categories of failure, corresponding recovery strategies, and the need for backup needs to be explicitly documented into SLAs and runbooks.
What risks do Kubernetes clusters face without backups?
In a Kubernetes environment, there are dangers above and beyond standard infrastructure problems.
- Targeted supply-chain attacks against container images or Helm repositories can easily slip malicious code that is hard to detect before it causes harm
- Cloud IAM roles that have been improperly configured can expose – or worse – damage the cluster resources on an entire scale
- Auto-scaling events can quickly catch stateful workloads unprepared, causing invisible but permanent data corruption
Risks such as these can multiply extremely rapidly on distributed systems, where the blast radius of a single event can spread to dozens of workloads in dozens of namespaces.
How do application, cluster, and data failures differ?
Kubernetes failures often happen in different layers and have correspondingly different recovery strategies. The failure might only impact a single workload, it might impact the entire cluster, or it might impact data stored externally from both. The subsequent sections will address each of these failures in more detail, but knowing this distinction beforehand also sets the stage for understanding why a one-backup-fits-all strategy is rarely successful.
When should backups be part of your SLAs and runbooks?
Backups need to be mandatory when a workload has a defined RTO and/or RPO. If you’re committed to a recovery time objective – that metric should come with a documented and tested restoration process, meaning that the frequency of backups, retention, and restore process should be documented prior to an incident, not after it.
Workloads found in an on-call runbook should be accounted for with an explicit ownership and a documented backup policy. Compliance-regulated environments add their own layer to the process, requiring proof of the backups existing, being tested, and meeting the necessary documented retention policies.
The value of Kubernetes backups
The very nature of Kubernetes environments makes it harder for more traditional backup systems and techniques to work well in the context of Kubernetes nodes and applications. Both RPO and RTO may indeed be far more critical since applications that are part of an operational deployment need to constantly be up and running, especially critical infrastructure elements.
This leads us to discern key business continuity elements that are practically necessary for every enterprise in general and a clear necessity when it comes to K8s backup’s best practices: backup and recovery, local high availability, disaster recovery, ransomware protection, human error, and so on. In a Kubernetes environment, the context of these aspects of backup can slightly change from their normal definition.
Local high availability
Local high availability as a feature is more about failure prevention/protection from within a specific data center or across availability zones (if we’re talking about the cloud, for example). A “local” failure occurs in the infrastructure/node/app used to run the application. In a perfect scenario, your Kubernetes backup solution should be able to react to this failure by keeping the app working, essentially meaning no downtime to the end user. One of the most common examples of a local failure is a stuck cloud volume that happens after a node failure.
In this perspective, local high availability as a feature can be considered a core part of the data protection strategy. For one, to perform such a task, your solution needs to offer some sort of a data replication system locally, and it also has to be in the data path first. It is important to mention that providing local availability via backup restoration is still considered backup and restore and not local high availability due to the overall recovery time.
Backup and restore
Backup and restore is another important element of an operational Kubernetes system. In most use cases, it backs up the entire application from a local Kubernetes cluster to an offsite location. The context of Kubernetes also brings up another important consideration – whether or not the backup software “understands” what is included in a Kubernetes app, such as:
- App configuration;
- Kubernetes resources;
- Data
A correct Kubernetes backup needs to save all of the parts above as a single unit for it to be useful in the Kubernetes system after restoring it. Targeting specific VMs, servers, or disks does not mean that software “understands” Kubernetes apps. Ideally, Kubernetes software should be able to back up specific applications, specific groups of applications, as well as the entire Kubernetes namespace. That’s not to say that it is completely different from the regular backup process – Kubernetes backups can also benefit greatly from some of the regular features of a usual backup, including retention, scheduling, encryption, tiering, and so on.
Disaster recovery
Disaster Recovery (DR) capability is essential to any organization using Kubernetes in a mission-critical situation, just as it does in employing any other technology. First, DR needs to “understand” the context of Kubernetes backups, just like backup and restore. It can also have different levels of both RTO and RPO and different levels of protection according to these levels. For example, there could be a strict Zero RPO requirement that implies strictly zero downtime, or there could be a 15-minute RPO with somewhat less strict requirements. It’s also not uncommon for different apps to have completely different RTOs and RPOs within the same database.
Another important distinction of a Kubernetes-specific disaster recovery system is that it should also be able to work with metadata to some extent (labels, app replicas, etc.). An inability to provide this feature could easily lead to a disjointed recovery in general, as well as general data loss or additional downtime.
Ransomware protection
The importance of Kubernetes systems (especially those generating persistent data) backups rivals that of regular data backups. Valuable data should be safeguarded to avoid unacceptable risk. Information is invaluable, and having a dedicated plan (or several) in mind for situations where business data becomes either corrupted or otherwise compromised is highly recommended by Bacula Systems.
A lot of these protection measures work effectively against both accidental and malicious events, as well. Intentional attacks resulting in data breaches using ransomware, impersonation, and other measures have become all too common, and it is completely unrealistic to think that your company will never be a target of such an event. As such, preparing yourself for these situations can offer benefits in terms of a number of extremely important factors, such as meeting compliance, protecting personal and business reputation, protecting customers and employees, and above all, generally avoiding serious damage to a business and/or organization.
Human error
The severity of a single human error can be significant (accidental deletions, incorrect configurations, unintentional update rollout). While automation of some functions can mitigate somewhat against human error, it is typically impossible to automate every single process in most companies.
In this context, backup and disaster recovery plans serve to ensure a company can continue its business in an effective capacity after an accident involving incorrect command or a configuration error.
The advantages of Kubernetes backup operations
Kubernetes backups have multiple advantages – often similar to regular backup operations on any other data type. It is a great way of maintaining the reliability, availability, and integrity of Kubernetes applications and appdata. Some of the most common advantages are presented below.
Hardware failure impact mitigation
Technically speaking, hardware failures are inevitable and can strike at practically any moment; be it a network failure, a power outage, a storage unit malfunction, and any other type of event leading to either data corruption or data loss. Kubernetes backups can offer a high level of protection against such actions by offering a redundant copy of information that can be restored to any other environment if the original hardware is no longer available, minimizing downtime and improving business continuity.
Disaster recovery
Most natural disasters are capable of completely wiping out the entire physical infrastructure of a company, including its Kubernetes clusters and possibly even the primary backups of those clusters. The existence of an off-site backup is therefore one of many benefits that disaster recovery strategy provides to its users, offering a way to quickly rebuild the entire cluster network to resume operations within an acceptable time period.
Data loss prevention
Accidental mistakes and mismanagement are surprisingly common to this day, away and separate from the rising number of malicious data breaches. Every human being can make mistakes, and the inability to roll back a certain action, deletion or modification drastically increases the probability of a permanent data loss for sensitive information. Regular K8s backups help to ensure that accidents caused unintentionally can still be recovered from, one way or another.
Defense against cyber attacks
Cyber threats have been significantly increasing for a number of years now, and the situation is almost universally expected to deteriorate further. Every IT infrastructure is constantly under the risk of a cyber attack, and the existence of defined and secure backup measures is critical to protect entire businesses. Failure to do so poses a significant risk to the ongoing existence of the business itself.
Assistance for testing and development environments
Regular Kubernetes cluster backups often have an additional value: they can also serve as a great help in testing and development processes, significantly simplifying the process of creating replicas of clusters for development purposes without affecting the original data. That way, the experimentation can prove much more fruitful and efficient, offering plenty of development opportunities for the business itself.
Kubernetes data types that need to be backed up
The usual reason containerization is employed is to create and run a secure, reliable, and lightweight runtime environment for applications, making a system that is consistent from host to host. Typically, these systems create persistent data – and when that is the case, this data is usually of value and, therefore, should be backed up. In addition, the entire container system itself should be protected and backed up so that if some kind of loss or corruption occurs, the system can be rapidly recovered, minimizing the loss of systems and services – and potential business – to an organization.
Kubernetes is the most popular container technology in use today. As such, the topic of different Kubernetes data types that have to be backed up requires a thorough examination.
As with any complex system, Kubernetes and Docker have a number of specific data types that they’ll need to rebuild the entire database properly in case of a disaster. To make it easier, it’s possible to split all of the data and config file types into two different categories: configuration and persistent data.
Configuration (and desired-state information) includes:
- Kubernetes etcd database
- Docker files
- Images from Docker files
Persistent data (changed or created by containers themselves) are:
- Databases
- Persistent volumes
Kubernetes etcd database
It is an integral part of the system containing information about cluster states. It can be backed up either manually or automatically, depending on your backup solution. The manual method is via etcdctl snapshot save db command, which creates a single file with the name snapshot.db.
Another method of doing the same thing is via triggering that same command right before creating a backup of the directory that this file would appear in. This is one of the ways of integrating this specific backup into the entire environment.
Docker files
Since Docker containers themselves are run from images, these images have to be based on something – and those are, in turn, created from Docker files. For a correct Docker configuration, it is recommended to use a repository as a version-control system for the entirety of your Docker files (GitHub, for example). For the sake of easier pulling of earlier versions, all Docker files should be stored in one specific repository that allows users to pull older versions of those files if necessary.
An additional repository is also recommended for the YAML files that are associated with all of the Kubernetes deployments; those exist in the form of text files. Backing up these repositories is also a must, using either the third-party tools or the built-in capabilities of something like GitHub.
It’s important to mention that you can still spawn the Docker files to be backed up, even if you’re running containers from images without their Docker files. There’s a specific command that is docker image history, which allows you to create a Docker file from your current image. There are also several third-party tools that can do the same, as well.
Images from Docker files
Docker images themselves also should be backed up in a repository. Both the private repository and the public one can be used for that exact purpose. Various cloud providers tend to provide private repositories to their clients, too. If you’re missing the image that your container runs from, a specific command that is docker commit should be able to create that image.
Databases
Integrity is also crucial when dealing with databases that containers use to store their data. In some cases, shutting down the container in question before creating a backup of the data is possible, but then again, the downtime required is likely to result in a lot of problems for the company in question.
Another method of doing database backups inside containers is via connecting to the database engine itself. A bind mount should be used beforehand to attach a volume that could be backed up in the first place, and then you can use mysqldump command (or similar) to create a backup. The backup file in question should also be backed up using your backup system afterward.
Persistent volumes
There are different methods for containers to gain access to a persistent storage of sorts. For example, if it’s about traditional Docker volumes, those reside in a directory below the Docker configuration. Bind mounts, on the other hand, could be any directory that is mounted inside of a container. Despite the fact that traditional volumes are preferable in the Docker community, both of those are relatively the same when it comes to backing up data. A third way of doing the same operation is via mounting an NFS directory or a single object as a volume inside of a container.
All three of these methods have the same problem when it comes to backing up data – the consistency of a backup is not complete if the data inside of a container changes mid-backup. Of course, it’s always possible to gain consistency by shutting off the volume before backing up, but in most cases, downtime for such systems is not realistic for the sake of business continuity.
There are some ways of backing up data within containers that are method-specific. For example, traditional docker volumes could be mounted to another container that would not be changing any of the data until the backup process is complete. Or if you’re using a bind-mounted volume, it’s possible to create a tar image of an entire volume and then back up the image.
Unfortunately, all of those options can be really difficult to pull off when it comes to Kubernetes. For that exact reason, it’s always recommended to store stateful information in the database and outside the container filesystem.
That being said, if you’re using a bind-mounted directory or an NFS-mounted file system as a persistent storage, it’s also possible to back up that data using regular methods, like a snapshot. This should get you much more consistency than the traditional file-level backup of the same volume.
What should you back up in a Kubernetes environment?
There are different types of data in a Kubernetes environment, and each type requires its own recovery considerations. It’s easy to understand what needs backing up, where most teams struggle is which components should be backed up and why. Understanding what needs backing up is the easy part – however, most teams struggle with what components should take precedence, and why.
What does and doesn’t an etcd backup actually recover?
Etcd is the single source of truth for your entire cluster’s state. As such, it’s the single most important thing to back up and the most misunderstood component at the same time. An etcd snapshot allows you to revert your entire cluster’s state to a point in time, but if your live cluster has moved too far ahead of your snapshot – you will end up with consistency gaps between what etcd reports as running and what is actually there.
An etcd snapshot by itself is insufficient to completely recover your cluster in a disaster scenario because, while it contains cluster state, it doesn’t contain any application data (which is stored in Persistent Volumes) and doesn’t promise that the reverted state will match the state of the cluster you have rebuilt. Application-level backups are what provides that missing information, and it’s important to treat etcd snapshots as complementary to app-level backups rather than a replacement for them.
Do you need to back up persistent volumes (PV) and persistent volume claims (PVC)?
Yes, it’s necessary to back up both PV and PVC, but their priority depends on what exactly is in them. Some PVs carry much more valuable data than others – a PV providing persistence for a stateful database is not at the same risk factor as a PV that holds cached content.
Before choosing your backup frequency it makes sense to tier your PVs by recovery criticality to ensure your backup schedule reflects business needs and doesn’t have equal emphasis on all volumes.
What cluster metadata (manifests, RBAC, CRDs, configmaps, secrets) is essential?
All of this metadata matters, but not at the same level when it comes to time-sensitive recovery scenarios.
Losing RBAC configuration and CRDs is the most disruptive option here, as they define what you are allowed to do, and what the rest of the cluster uses as their defined resource definitions. Without this information, the applications you restore are highly likely to come back in an inaccessible or broken state.
ConfigMaps and secrets also define how your applications work, and are also frequently the most overlooked candidates in a manual backup strategy. Manifests are also highly important, but if you have a GitOps system in place – it should be relatively simple to recover them from source control, making them a little lower on the priority list.
How should you treat ephemeral data and logs?
Ephemeral data – anything that lives only for the lifetime of a pod – generally shouldn’t be backed up, and attempting to do so adds complexity without meaningful recovery value.
Logs are usually in a similar position – they are not supposed to be backed up as a part of a Kubernetes backup strategy. The much better option is to have a dedicated observability pipeline that sends these logs to external storage independently of the backup process.
A more appropriate question here would be whether any data you’re currently considering ephemeral would need to persist. If it does – it should be transferred to a persistent volume instead of being included in a backup scope.
How Does GitOps Affect Your Kubernetes Backup Strategy?
GitOps is an operational model where the Git repository stores the entire state of a Kubernetes environment – with all the manifests, resource definitions, and configurations. The information in question is also continuously reconciled against the live cluster with the help of a dedicated tool. Instead of applying changes directly to your cluster, changes go through Git first – making the repository in question a single source of truth for what the cluster should look like at any point in time.
It has quickly become a widespread pattern in Kubernetes environments, changing the backup equation in specific ways – and the implications of this are not always straightforward, either. Knowing where it helps and where it stops is essential before deciding how much backup coverage to layer on top of it.
How does GitOps change your approach to configuration backup?
If your Kubernetes manifests, RBAC configurations, and resource definitions are stored in Git and continuously reconciled by a tool like ArgoCD or Flux – you already have a form of version-controlled configuration backup.
Any declarative resource that lives in your Git repository can be reapplied to a new or recovered cluster without needing a separate backup of that resource. This is a significant simplification to the backup configuration process, as manifests and cluster resource descriptions that are already being managed with GitOps can become lower priority items in your dedicated backup strategy.
What does GitOps not cover, and where do dedicated backups still apply?
GitOps manages desired state, not runtime state or data. As such, the persistent volumes, secrets not committed to Git, database contents, and states that only exist within a running cluster are all invisible to it.
An entirely GitOps-managed cluster can still suffer massive data loss if persistent volumes aren’t backed up independently. Secrets are usually explicitly excluded from repositories due to security implications, so they also require independent backup coverage.
GitOps is not an alternative to a backup strategy; instead, they are complementary, and recognizing the boundary between them helps one avoid unsafe assumptions about what’s covered.
Best practices for Kubernetes backup operations
There are a number of best practices that can be used to improve the overall state of K8s backups, including cluster resiliency, data safety, and recovery reliability.
Backup persistent data and cluster state
The cluster state includes key components for a Kubernetes environment, including secrets, ConfigMaps, etcd, and more. The persistent data volumes are the majority of a data size, with regular files, databases, user data, logs, etc.
Set up backup automation
Backup automation reduces the probability of a human error and introduces an element of consistency and predictability into the backup process. Plenty of third-party backup solutions can offer advanced automation capabilities, such as the ability to plan backup schedules with specific RTOs and RPOs in mind.
Use different backup types when possible
Kubernetes data can be backed up using different backup approaches, if the software allows for it. For example, incremental backups can offer a significant decrease in total storage space taken by only capturing information that has been modified in any way since the last backup.
Test backed up data
Backups themselves do not become invulnerable as soon as they are created, and there is a possibility that the information was somehow corrupted or lost during the process. Performing test restoration processes on a regular basis makes it easier to detect such errors and resolve them before any kind of disaster.
Implement backup encryption
Backup encryption should be implemented, when necessary, for information in transit and at rest to ensure the highest possible level of security. Encryption helps with protecting data against data breaches and unauthorized access. There are plenty of different encryption algorithms to choose from, if the backup solution supports them.
Consider using immutable storage
The usage of data immutability strategies can be an important component of a backup strategy. Some backup solutions offer software immutability, while others provide dedicated hardware options such as WORM (write-once-read-many) to protect information against cyber threats.
Remember about retention policies and versioning
Versioning is the process of storing past copies of your information for compliance or convenience reasons. A properly configured retention policy should elaborate on how long the retention time period is going to be in order to find the balance between storage consumption and meeting all the necessary requirements.
Check for multi-cluster backup capabilities
If your current environment uses multiple Kubernetes clusters, making sure that your backup solution can offer centralized backup can be paramount. The ability to handle multiple environments at once can greatly simplify the backup process and improve the overall convenience of working in such an environment.
Implement cloud-native backup software
The compatibility with dynamic cloud infrastructures is an important feature for any competent Kubernetes backup solution. One reason for this is the evolving services that cloud computing offers can bring additional security benefits to an organization. Making sure that the backup software of your choosing is cloud-native and can integrate with different cloud storage services may be critical.
Think through your entire disaster recovery strategy
Backup strategies are often better if designed with disaster recovery in mind, and Kubernetes is no exception. For example, making sure that backups can be restored to different clusters would cover situations such as migration or complete cluster failure. Alternatively, support for cross-cloud and cross-region backups makes it possible to resolve cloud-centric issues or regional outages.
Ensure the security of Kubernetes secrets
Kubernetes secrets include plenty of sensitive information that is worth protecting – passwords, API keys, certificates, etc. This kind of information should receive the highest possible priority when it comes to data security, with full encryption, data immutability, and so on.
Try to optimize the cost of backup storage
If possible, it is typically important to implement various storage management techniques to reduce the total backup size in your storage environment. Compression and deduplication are equally effective at that, but both have their own disadvantages. The same could be said for most cloud-specific storage saving strategies as well.
Monitor backup processes on a regular basis
It is perhaps unreasonable to expect someone to keep an eye on automated backup processes 24/7. As such, dedicated monitoring and notification systems should be implemented to make sure that everything is running smoothly. Most solutions even have an option to send a dedicated notification to a specific person if some sort of irregularity was detected during the backup process.
Implement namespace-level backups for multi-tenant clusters
The aforementioned multi-tenant environments can be supported with the help of namespace-level backups. That way, each tenant’s information would have a separate backup file, limiting the potential data exposure between tenants while also offering plenty of flexibility for the recovery processes.
Provide documentation for the entire backup and recovery pipeline
The entire backup and recovery process should be well-documented, including detailed instructions on how a backup is set up, monitored, verified, and so on. The same logic applies to the restoration processes. Such documentation should also cover roles and responsibilities of employees responsible for backup administration tasks.
How should you design Kubernetes backup schedules and retention policies?
Knowing what to back up is only half the battle. The other half is deciding how often to back up and for how long to keep backed up data. Backup schedules and retention policies not linked to a tangible recovery objective invariably become either too aggressive (resulting in wasted storage and compute resources) or too infrequent (resulting in unrecoverable periods following a failure).
How frequently should you back up etcd, PVs, and application data?
Each component doesn’t need to be backed up at the same frequency, as it’s a common error to make. Etcd is constantly changing along with the cluster state, so an hourly snapshot is fine in most production environments. However, a rapidly changing cluster with a high churn in deployments or configurations might require more frequent snapshots.
Persistent volumes carrying transactional or user-generated data should be snapshotted at least as frequently as your RPO allows, since that’s where the most operationally significant data lives. Application-level backups can be less frequent in most cases, as long as the application itself has a certain degree of tolerance for event replay or state reconstruction. However, that tolerance must be thoroughly validated against current RPO before it’s built into your schedule rather than treated as a safe assumption.
What retention windows align with RPO and RTO requirements?
Two questions should drive retention:
- How far back do you really need to recover?
- How fast do you need to be able to recover?
A low RPO doesn’t imply long retention, so keeping 30 days of hourly snapshots is rarely practical and is often expensive. A better practice would be to use tiered retention: shorter-duration, highly-frequent backups for operational recovery combined with longer-duration but less frequent backups for audit or compliance purposes. The key is that retention windows should be explicitly approved by whoever owns the recovery SLA, not decided unilaterally by the team running the backups.
How can lifecycle and tiering reduce backup costs?
Backup storage cost for Kubernetes clusters can balloon quickly, especially when working with large persistent volumes or frequent snapshotting. Implementing a lifecycle policy helps reduce costs dramatically without reducing your recovery capability.
Lifecycle policies automatically archive backups to cheaper storage tiers as they age – moving from high-performance block storage to object storage after a certain period, for example. This does come with a trade-off, however, as cheaper storage tiers are usually associated with longer recovery times.
Before implementing lifecycle policies it’s important to review the retrieval times for each of the cheaper tiers and see if that aligns with your RTO for older recovery points. Most major cloud providers include native support for lifecycle policies within their object storage solutions, so implementing such policies should pose little-to-no difficulty in most cases – once you’ve determined your retention period.
How do you secure Kubernetes backups and meet compliance requirements?
Scheduling backups is only one piece of the operational puzzle. Actually protecting the backups themselves and demonstrating compliance with relevant governance legislation are both separate challenges that are often addressed too late in the lifecycle. The sheer value of backup data – as a complete picture of the infrastructure – makes it an attractive target, and there is a growing focus on governance requirements over it.
How should backup data be encrypted at rest and in transit?
The critical architectural decision in this context isn’t really about what encryption algorithm to use (since most current backup products have a default you should stick with anyway), but rather about making sure that encryption is applied on an end-to-end basis.
If the data at rest is encrypted but the transit between the cluster and the storage target is unencrypted – the data won’t be secure during transfer. If the encryption keys are stored in close proximity to the backup data that they are encrypting – they are likely insecure as well.
Encryption keys must be stored separately from the backup target, be it with the help of a key management service or a hardware security module. Access to those keys should also only be handled by an entity that has permission to access the backup itself.
Who should have access to backup and restore capabilities?
Restore access is frequently equated to backup access, but they have completely different risk implications. The capacity to restore a backup to potentially a separate cluster or namespace is equivalent to being able to relocate sensitive data, and thus has a higher control requirement than that for simply creating the backup itself.
In practice, backup creation can reasonably be automated and broadly permitted, while restore operations should require explicit authorization – ideally with a second approver for production environments. That distinction should be reflected in your RBAC configuration and documented clearly enough to survive team changes.
What audit, logging, and immutability features are necessary for compliance?
In addition to ensuring that backups exist, compliance frameworks will also demand that a company can prove their existence. Each backup operation, access attempt, and restoration request will need to be auditable and retained according to your framework’s needs – which means logs must be written in a manner that’s tamper-evident.
Immutable storage, which prevents the deletion or modification of backup data for a specific amount of time, is rapidly becoming mandatory instead of optional in environments managing private or financial information – and HIPAA and SOC 2 specifically mention its necessity.
This also means that both the audit trail and the data being backed up need to be afforded equal importance: data that you can’t prove to be compliant offers less value when auditors come calling.
Methodology for choosing the best possible Kubernetes backup solution
There are a good number of different third-party solutions offering Kubernetes backup capabilities in one way or another. K8s backup is a very important task, so the topic of choosing a backup solution is just as important. Accordingly, we can offer an in-depth methodology on how to choose the best possible Kubernetes backup solution for your specific organization.
Data types covered by the solution
Checking whether the backup solution offers the ability to support a required data type is a priority for any company or business looking for a Kubernetes backup solution. As such, we have added information about what data types every single solution from our list can create a backup of. The overall result of this comparison is presented below in a table (the table in question is split in two parts for easier viewing experience).
Table #1
| Software | Kasten | Portworx | Cohesity | OpenEBS | Veritas |
| Deployments | Yes | Yes | Yes | Yes | Yes |
| StatefulSets | Yes | Yes | Yes | Yes | Yes |
| DaemonSets | Yes | Yes | Yes | Yes | Yes |
| Pods | Yes | Yes | Yes | Yes | Yes |
| Services | Yes | Yes | Yes | Yes | Yes |
| Secrets and/or ConfigMaps | Yes | Yes | Yes | Yes | Yes |
| Persistent Volumes | Yes | Yes | Yes | No data | Yes |
| Namespaces | Yes | Yes | Yes | No data | Yes |
| Applications | Yes (Integrations) | No data | Yes (Messaging + Databases) | No data | No data |
| Storage Infrastructure | No data | No data | Yes | No data | No data |
Table #2
| Software | Stash | Rubrik | Druva | Zerto | Longhorn |
| Deployments | Yes | Yes | Yes | Yes | Yes |
| StatefulSets | Yes | Yes | Yes | Yes | Yes |
| DaemonSets | Yes | Yes | Yes | Yes | Yes |
| Pods | Yes | Yes | Yes | Yes | Yes |
| Services | Yes | Yes | Yes | Yes | Yes |
| Secrets and/or ConfigMaps | Yes | Yes | Yes | Yes | Yes |
| Persistent Volumes | Yes | Yes | Yes | Yes | Yes |
| Namespaces | Yes | Yes | Yes | Yes | No data |
| Applications | No data | Yes (Databases) | Yes (Databases) | No data | No data |
| Storage Infrastructure | No data | Yes | No data | No data | No data |
It should be noted that support for different data types is an important factor, but it is not a deal-breaker most of the time, so it is highly recommended to view this as one of several factors in this comparison.
Customer ratings
These ratings can be interpreted in many different ways – how good the solution is at its job, how competent it is with customer feedback, how it can (or cannot) evolve over time, and so on. In our case, customer ratings from third-party websites exist to showcase the solution’s overall competency using various review-gathering websites such as Capterra, TrustRadius, and G2.
Capterra is a review aggregator platform that offers verified reviews, guidance, insights, and solution comparisons. Their customers are thoroughly checked for the fact that they are, in fact, real customers of the solution in question, and there is no option for vendors to remove customer reviews. Capterra holds over 2 million verified reviews in almost a thousand different categories, making it a great option for finding all kinds of reviews about a specific product.
TrustRadius is a review platform that proclaims its commitment to truth. It uses a multi-step process to ensure review authenticity, and every single review is also vetted to be detailed, deep, and thorough by the company’s own Research Team. There is no way for vendors to hide or delete user reviews in one way or another.
G2 is another good example of a review aggregator platform that boasts over 2.4 million verified reviews to date with over 100,000 different vendors presented. G2 has its own validation system for user reviews that is claimed to be extremely effective in proving that every single review is authentic and genuine. G2 also offers separate services for marketing purposes, as well as investing, tracking, and more.
Key features (as well as advantages/disadvantages)
The list of important factors that a competent Kubernetes backup solution has to have includes the following:
- High data availability for better disaster recovery and higher tolerance to various issues with clusters and containers.
- Different backup types, including incremental and app-aware backups.
- Backup granularity, with the ability to create backups of specific objects, and not just entire namestates (volumes, pods, PVs, etc.).
- Backup scheduling for more simplistic day-to-day operations.
- Integration with cloud storage providers (Azure Blob, GCP, S3, etc.) for easier backup process and more variety in terms of backup storage.
- Data encryption capabilities for better information protection.
- Support for custom workloads allows the possibility of extending backup functionality via plugins and integrations.
This is also represented by the “advantages/disadvantages” category (if applicable), showcasing both the positives and the negatives of the solution gathered from a multitude of user reviews.
Pricing
A solution’s features are important to the end user, but the topic of price is just as important. Some companies have a very limited budget, and others need a specific feature set despite a potentially high price. However, most potential clients fit somewhere in between these two examples. It is highly recommended to check both the price and the feature set of the solution while also weighing it one against another – even if the solution is within your budget, it may not be as good of a deal on a per-feature basis as its competition.
A personal opinion of the author
The only completely subjective part of this methodology is the author’s opinion on the subject (Kubernetes backup solution, in our case). There are plenty of different use cases for this particular category, including interesting information about the solution that did not fit in any of the previous categories or just the author’s personal opinion about this specific topic.
Kubernetes backup solution market
In the context of these three important factors/features, let’s look at a few more examples of a K8s backup and recovery solution.
Kasten K10

Kasten K10 (recently acquired by Veeam) is a backup and restore solution that also takes pride in its mobility and disaster recovery systems. The backup process with Kasten is simplified thanks to its ability to automatically discover applications, as well as many other features, such as data encryption, role-based access control and a user-friendly interface. At the same time, it can work with many different data services, such as MySQL, PostgreSQL, MongoDB, Cassandra, AWS, and so on.
Local high availability is not available with it since Kasten does not directly support replication within a single cluster and relies on the underlying data storage systems instead. Disaster recovery is also only partially “there” since Kasten can’t achieve zero RPO case cases due to the lack of a data path component. Also noteworthy is the fact that Kasten’s backups are asynchronous only, which is typically an additional downtime between operations.
Data types covered by Kasten K10:
Kasten K10 can create backups of -usually- all the data that Kubernetes generates, including Services, Deployments, PVs, Namespaces, and so on. There are only two exceptions here – Kasten’s Application coverage can also be extended and improved via Integrations with other backup and recovery solutions.
Customer ratings:
- (Kasten) G2 – 4.7/5 stars based on 10 customer reviews
- (Veeam) Capterra – 4.8/5 stars based on 69 customer reviews
- (Veeam) TrustRadius – 8.8/10 stars based on 1,237 customer reviews
- (Veeam) G2 – 4.6/5 stars based on 387 customer reviews
Key features:
- Impressive scalability and efficiency
- Highly effective ransomware protection
- Created using cloud-native architectural principles
Pricing (at the time of writing):
- Kasten K10’s pricing page claims that there are three Editions of the software (even though there is only one actual Edition, and the other two are the free version and the trial version, respectively)
- “Free” is a very limited version of Kasten K10 with bare minimum Kubernetes backup capabilities, including up to 5 nodes at most, as well as backup/restore operations, disaster recovery, ransomware protection, and most of Kasten’s other capabilities
- “Enterprise Trial” is Kasten’s version of a timed free trial, offering the complete feature set of Kasten, an upper limit of 50 nodes, as well as customer support, Kasten-assisted deployment, and data protection assessment.
- “Enterprise” is the only actual subscription tier that Kasten K10 has; it completely removes the “number of nodes” limitation and offers Kasten’s complete set of backup and recovery features.
- It is worth noting that there is no pricing information available on the official Kasten website, which means that the only way to receive such information is to request a personalized quote from the company in question.
My personal opinion on Kasten K10:
Kasten K10 is a rather competent backup solution that works with a number of different environment types – including Kubernetes, Cassandra, PostgreSQL, MySQL, and more. It was also recently acquired by Veeam – one of the most well-known enterprise-grade backup solutions on the market. Kasten managed to keep its name so far, presenting itself as “Kasten by Veeam” in most cases. It is not a bad solution in and of itself, but its Kubernetes-related capabilities are rather basic and limited. It translates most of its general capabilities onto Kubernetes backups, such as data encryption and RBAC, but creating these backups is not a simple process. Kasten does not offer local high availability for Kubernetes, its disaster recovery implementation is only partial (non-zero RPOs), and all of the backups are strictly asynchronous.
Portworx

Portworx PX-Backup is a data management company that develops a cloud-based storage platform to manage and access the database for Kubernetes projects. It is another example of a data management solution, and despite its limitations as such, one of the key benefits of using Portworx is the high availability of data.
Backup and recovery operations, Kubernetes apps understanding, local high availability, and disaster recovery, among other features – all of which make Portworx a good solution for Kubernetes backup. Considering how varied third-party Kubernetes backup solutions are, Portworx may also be interesting to a user who is specifically looking for Kubernetes backup capabilities.
Another significant part of PX-Backup is its scalability, allowing for on-demand backups / scheduled backups of hundreds of applications at once. The solution also supports multi-database setups and can restore apps directly to the cloud services, such as Amazon, Google, Microsoft, etc.
Data types covered by Portworx:
Portworx supports the creation of backups for Namespaces, PVs, DaemonSets, Deployments, and more. T-I was unable to find information about whether it can or cannot support Application backup or Storage Infrastructure backup, though.
Customer ratings:
- G2 – 4.4/5 stars based on 16 customer reviews
Advantages:
- High-performance, reliable backup solution
- Scalable and reliable infrastructure
- Data encryption and detailed access control
Shortcomings:
- Software configuration as a whole may be somewhat complicated
- Customer support experience is inconsistent
- Security capabilities are limited in the context of large enterprise deployments
Pricing (at the time of writing):
- Portworx’s pricing model is fairly simple – there is a free version available for all users that create a Portworx account; this version is limited to 1 cluster and up to 1 TB of application data
- There is also a paid version of the software with a full feature set, including app-aware backups, single-click restore, ransomware protection, and so on. Unfortunately, there is no official pricing available on the Portworx website; it can only be obtained by contacting the company directly for a personalized quote.
My personal opinion on Portworx:
Portworx promotes itself as a Data Services Platform, offering a lot of capabilities that are mostly centered around Kubernetes and its containers. The Portworx Platform can offer plenty of services, including backup, disaster recovery, storage, DevOps, and database. Portworx backups offer high availability, application awareness, and plenty of features that are usually unavailable in Kubernetes backup offerings. It is a fast and scalable solution, but it also has its downsides. One example of such a downside is a rather limited overall presence on the market, which creates plenty of uncomfortable factors, such as the lack of detailed tutorials on the Internet. The solution in question can also be rather complicated, making it challenging to work with for newcomers in this field.
Cohesity

Cohesity is a relatively popular competitor in the field of general backup and recovery, but its Kubernetes-related capabilities still have some room to grow. First of all, Kubernetes is a relatively new addition for them, in that it has added the understanding for Kubernetes apps. However, it only works for all of the applications within the same namespace, and you can’t protect specific apps within that one namespace.
On the other hand, there are also rapid recovery capabilities, app-tier incremental backups based on policies, data state consolidation, and many other capabilities.
Data types covered by Cohesity:
Cohesity’s solution supports Namespace backups, Service backups, Deployment backups, and more. There is support for Storage Infrastructure backup, and the only notable factor for this category is that Cohesity’s Applications backup can also cover Databases the apps are working in, as well as Messaging systems deployed in Kubernetes.
Customer ratings:
- Capterra – 4.6/5 stars based on 48 customer reviews
- TrustRadius – 8.9/10 stars based on 59 customer reviews
- G2 – 4.4/5 stars based on 45 customer reviews
Advantages:
- Simple and convenient backup and recovery management
- Painless and easy initial setup process and configuration
- Easy scheduling with the help of profile creation allows for more automation
- App-aware incremental backups, rapid recovery capabilities for Kubernetes apps, and more
Shortcomings:
- Some of the updates have to be installed manually using a command line, which is a stark contrast from the usual GUI-based automatic update installation
- Customer support relies a lot on standard replies and can be less than helpful
- The Kubernetes backup feature is relatively new for Cohesity, and it can be a bit rough around the edges
Pricing (at the time of writing):
- Cohesity’s pricing information is not publicly available on their official website and the only way to obtain such information is by contacting the company directly for a free trial or a guided demo.
- The unofficial information about Cohesity’s pricing states that its hardware appliances alone have a starting price of $110,000 USD
My personal opinion on Cohesity:
Cohesity is a solid backup and recovery solution that supports a number of different storage types while also offering many features to work with. The entire solution is built using an unusual node-like structure that makes Cohesity extremely easy to scale both ways. It is fast, versatile, and a great option for creating backups of application infrastructures. As for its Kubernetes-related capabilities specifically – they definitely could use some work in the future since Kubernetes support is a relatively new addition to Cohesity, and some nuances are still being ironed out on a regular basis. It can only protect app data from the same namespace, and there is no option to protect specific applications, as well – only the entire namespace. At the same time, Cohesity can offer quite a lot of its own capabilities that are now applicable to Kubernetes backups, including data state consolidation, incremental backup support, and more.
OpenEBS

OpenEBS is another example of a solution that has managed to achieve some results with only one of the three features from our list, and in this case it’s all about Local high availability.
At the same time, OpenEBS can also integrate with Velero, creating a combined Kubernetes solution that excels in Kubernetes data migration. OpenEBS, on its own, can only back up individual applications (a direct opposite of what Cohesity does). There are also features such as multi-cloud storage, its open-source nature, and a large list of supported Kubernetes platforms, from AWS and Digital Ocean to Minikube, Packet, Vagrant, GCP, and more.
However, this may not cover a user’s needs since some users might need those namespace backups in specific use cases.
Data types covered by OpenEBS:
OpenEBS is quite a versatile solution; it can create backups of entire Deployments, as well as Pods, ConfigMaps, StatefulSets, etc. However, it is rather limited in comparison with others, including the lack of Storage Infrastructure backup, no Application backup, and the absence of Namespace-level and PV-level backups.
Key features:
- Uses Container Attached Storage patterns for better backup efficiency
- Allows stateful applications to have quick and easy access to both Replicated PVs and Dynamic Local PVs
- Simplifies cross-cloud application management, including storage replication and automated provisioning
Pricing (at the time of writing):
- OpenEBS is a free and open-source solution, but there are also third-party individuals and companies that may provide either services or products related to OpenEBS in some way, shape or form.
My personal opinion on OpenEBS:
OpenEBS is a great contrast to Cohesity here – it is a relatively small data management solution that focuses specifically on Kubernetes environments while also putting most of its capabilities into local high data availability as the main feature. The software in question can be easily integrated with Velero – another small-scale free and open-source software that offers a lot more in terms of Kubernetes backups. This kind of integration creates a rather powerful (and free) backup and data management offering completely free of charge that works with a variety of Kubernetes platforms, offers multi-cloud storage support, provides data migration capabilities, and so on. As with practically any free solution of that scale, the biggest issue of OpenEBS (and Velero) is a rather steep learning curve that makes it difficult to get into at first and drastically increases the time necessary to master all of the solution’s capabilities.
Veritas

Veritas is a well-established backup software provider that has been on the market for several decades now; it is widely preferred by older and bigger businesses for that exact reason. It can offer plenty of different features and capabilities while also supporting a variety of target storage types ranging from physical storage to VMs, databases, cloud storage, and more. As for its Kubernetes capabilities – Veritas can offer extensive logging capabilities, simple yet effective administration, RBAC support, high data availability, data replication, and many others. It is a great option for backup and recovery tasks as a whole, bringing data protection and feature richness in a single package.
Data types covered by Veritas:
The capabilities of Veritas in the realm of Kubernetes backups are rather impressive, including coverage for Namespaces, Deployments, Secrets, Pods, and so on. However, it does not have the ability to perform Application backups, and the same could be said for Storage Infrastructure backups.
Customer ratings:
- Capterra – 4.0/5 stars based on 7 customer reviews
- TrustRadius – 6.8/10 stars based on 150 customer reviews
- G2 – 4.1/5 stars based on 230 customer reviews
Advantages:
- An extremely wide and varied feature set, often considered one of the biggest feature packages on the market.
- A relatively outdated visual state of the interface does not change the fact that it is easy to work with for all kinds of customers, including complete newcomers in this field.
- The customer support experience gathered plenty of positive reviews over the years, with the support team providing quick and concise answers to a wide variety of issues.
Shortcomings:
- The report management system is somewhat rigid, there is no way to customize the target file path for automatically created reports.
- LTO tape library integration is available to an extent but operates with a number of serious flaws so far.
- Report exporting as a whole is rather challenging to perform.
Pricing (at the time of writing):
- There is no official pricing information that could be found on Veritas’ website, the only way to obtain such information is to contact the company itself directly.
My personal opinion on Veritas:
Veritas is often praised as one of the older backup and recovery solutions on the market, which is still in shape and competing with other prominent solutions. That’s not to say that age is the only advantage Veritas can offer – it also has an extremely wide feature set, an impressively user-friendly interface, and an extremely helpful customer support team. Veritas also manages to greatly simplify and improve various aspects of managing Kubernetes containers – including backup and recovery capabilities for container data, automatic failover and failback, traffic distribution across instances, automatic namespace discovery, and more. Veritas offers easy and accessible backup and recovery operations to containerized applications, making it a rather convenient Kubernetes backup solution. Veritas does have a few problems with its reporting system as a whole, and its LTO tape integration is rather problematic, but none of these issues affect Kubernetes-related capabilities enough to be a real issue for existing and future users. Overall, price can be a barrier.
Stash

Stash is a backup and disaster recovery solution that was built specifically for Kubernetes in the first place. It can restore Kubernetes data on several different levels, including databases (MongoDB, MySQL, PostgreSQL), volumes (stateful sets, deployments, standalone volumes), and even regular Kubernetes resources (secrets, YAML configs, etc.). It supports a number of automation options, can be integrated with multiple cloud storage providers, supports custom workloads, and more. It is also a relatively new solution in this field, so it does have some growing pains here and there.
Data types covered by Stash:
Stash is a relatively small backup solution, but its Kubernetes coverage is still quite impressive – with support for Deployments, Services, Pods, DaemonSets, and even Storage Infrastructure backups. However, it cannot create Namespace-level copies of Kubernetes, and there is also no support for Application backup, either.
Key features:
- Support for CSI VolumeSnapshotter functionality allows for Stash’s Kubernetes backup options to be expanded quite significantly.
- The capability to be integrated with the Restic tool brings in features such as deduplication, encryption, incremental backups, and more.
- Stash can work with a number of cloud storage providers as backup storage – Azure Blob, GCP, AWS S3, etc.
- There are plenty of scheduling options available, all of which can be customized in multiple ways.
Pricing (at the time of writing):
- There is no official pricing information available on the Stash website, but there is a “contact us” prompt, meaning that all of the pricing information is highly personalized and is not obtainable via public means.
My personal opinion on Stash:
Stash might just be the least known backup solution on this list. It is a very small-scale backup and disaster recovery solution for Kubernetes specifically and nothing else. Stash can work with Kubernetes resources, volumes, and even databases, offering the ability to create backups of plenty of environments and data types – from MongoDB and PostgreSQL to YAML configs of deployments. It is a fast solution with plenty of Kubernetes-centric capabilities that are a rarity in other backup solutions. For example, Stash supports CSI VolumeSnapshotter functionality, and it can also be integrated with the Restic tool for better and more versatile data protection operations. It is still under development, but it shows quite a lot of promise for the future, and the overall complexity of the solution is probably the biggest issue right now – an issue that can be fixed with time and effort.
Rubrik

Quite a lot of other, bigger players in the backup and recovery field have begun offering their own services in terms of Kubernetes backup and restore – Rubrik is a good example: it enables users to implement Rubrik’s vast management feature set in the field of Kubernetes deployments.
It allows for flexibility in terms of restoration destination, as well as the protection of Kubernetes objects and a unified platform that provides insights and an overview of the entire system. There are also features like backup automatization, granular recovery, snapshot replication, and more. Rubrik can also work with Persistent Volumes and is capable of replicating namespaces – offering you variation when it comes to development and testing before deployment.
Data types covered by Rubrik:
Rubrik is one of the best options on this list when it comes to all kinds of Kubernetes data types it can create a backup of. This includes Deployments, Namespaces, Storage Infrastructure, Services, Pods, StatefulSets, and practically everything else. The only factor worth noting here is that Druva can cover both Applications and Databases they’re used by.
Customer ratings:
- Capterra – 4.7/5 stars based on 45 customer reviews
- TrustRadius – 9.1/10 stars based on 198 customer reviews
- G2 – 4.6/5 stars based on 59 customer reviews
Advantages:
- A versatile backup and recovery solution with high performance
- A variety of integrations with other services and technologies, such as SQL Server, VMware, M365, etc.
- Reliable data protection capabilities with good encryption, strong security, and ransomware
- Supports plenty of features for Kubernetes apps, including snapshot replication, backup automation, granular recovery, and many others
Shortcomings:
- RBAC implementation is somewhat basic and lacks a lot of the necessary features that competitors have
- Very limited audit/reporting customization and not enough details in reports, in general
- The solution’s overall cost may be too much for smaller or medium-sized companies and businesses
- Limited scalability
Pricing (at the time of writing):
- Rubrik’s pricing information is not publicly available on their official website and the only way to obtain such information is by contacting the company directly for a personalized demo or one of the guided tours.
- The unofficial information states that there are several different hardware appliances that Rubrik can offer, such as:
- Rubrik R334 Node – from $100,000 for a 3-node with 8-Core Intel processes, 36 TB of storage, etc.
- Rubrik R344 Node – from $200,000 for a 4-node with similar parameters to R334, 48 TB of storage, etc.
- Rubrik R500 Series Node – from $115,000 for a 4-node with Intel 8-Core processors, 8×16 DIMM memory, etc.
My personal opinion on Rubrik:
Rubrik’s capabilities in terms of Kubernetes specifically may not be particularly extensive, but the solution itself is well-known and respected in the industry, providing a sophisticated backup and recovery platform with a massive number of capabilities. Rubrik can offer protection, data migration, and general support for Kubernetes instances, mostly by expanding its own existing features to cover Kubernetes environments. Rubrik can replicate namespaces and can work with Persistent Volumes, making it a rather interesting offer to consider for larger companies. However, it would be fair to mention that Rubrik has its own share of disadvantages that are yet to be fixed, including somewhat basic scalability, rigid reporting/audit system, and a rather high price tag as a whole.
Druva

Another variation of such a solution is presented by Druva, providing a rather simple but effective Kubernetes backup and restore solution with all of the expected basic features – snapshots, backup and restore, automatization, and some additional functionalities. Druva can also restore entire applications within Kubernetes, with a lot of mobility when it comes to the restoration destination.
Additionally, Druva supports multiple admin roles, can create copies of workloads for troubleshooting purposes, and can back up specific areas like namespaces or app groups. There’s also a variety of retention options, comprehensive Kubernetes data protection, and support for Amazon EC2 and EKS (custom container workloads).
Data types covered by Druva:
There is no information about whether Druva supports Kubernetes Storage Infrastructure backups. Other than that, it supports practically everything else – Namespaces, Pods, DaemonSets, StatefulSets, ConfigMaps, and even Persistent Volumes. It can also cover Applications and Databases that are associated with these applications.
Customer ratings:
- Capterra – 4.7/5 stars based on 17 customer reviews
- TrustRadius – 9.3/10 stars based on 419 customer reviews
- G2 – 4.6/5 stars based on 416 customer reviews
Advantages:
- GUI, as a whole, receives a lot of praise.
- Backup immutability and data encryption are just examples of how serious Druva is when it comes to data security.
- Customer support is quick and useful.
- Data protection, snapshots, automated backups, and other features for Kubernetes apps.
Shortcomings:
- First-time setup is not easy to perform by yourself.
- Windows snapshots and SQL cluster backups are simplistic and barely customizable.
- Slow restore speed from the cloud.
- Scalability can be limited.
Pricing (at the time of writing):
- Druva’s pricing is fairly sophisticated and offers different pricing plans depending on the type of device or application that is covered.
- Hybrid workloads:
- “Hybrid business” – $210 per month per Terabyte of data after deduplication, offering an easy business backup with plenty of features such as global deduplication, VM file-level recovery, NAS storage support, etc.
- “Hybrid enterprise” – $240 per month per Terabyte of data after deduplication, an extension of the previous offering with LTR (long-term retention) features, storage insights/recommendations, cloud cache, etc.
- “Hybrid elite” – $300 per month per Terabyte of data after deduplication, adds cloud disaster recovery to the previous package, creating the ultimate solution for data management and disaster recovery
- There are also features that Druva sells separately, such as accelerated ransomware recovery, cloud disaster recovery (available to Hybrid elite users), security posture & observability, and deployment for U.S. government cloud
- SaaS applications:
- “Business” – $2.5 per month per user, the most basic package of SaaS app coverage (Microsoft 365 and Google Workspace, the price is calculated per single app), can offer 5 storage regions, 10 GB of storage per user, as well as basic data protection
- “Enterprise” – $4 per month per user for either/or Microsoft 365 or Google Workspace coverage with features such as groups and public folders, as well as Salesforce.com coverage for $3.5 per month per user (includes metadata restore, automated backups, compare tools, etc.)
- “Elite” – $7 per month per user for Microsoft 365/Google Workspace, $5.25 for Salesforce, includes GDPR compliance check, eDiscovery enablement, federated search, GCC High support, and many other features
- Some features here can also be purchased separately, such as Sandbox seeding (Salesforce), Sensitive data governance (Google Workspace & Microsoft 365), GovCloud support (Microsoft 365), etc.
- Endpoints:
- “Enterprise” – $8 per month per user, can offer SSO support, CloudCache, DLP support, data protection per data source, and 50 GB of storage per user with delegated administration.
- “Elite” – $10 per month per user, adds features such as federated search, additional data collection, defensible deletion, advanced deployment capabilities, and more.
- There are also plenty of features that could be purchased separately here, including advanced deployment capabilities (available in the Elite subscription tier), ransomware recovery/response, sensitive data governance, and GovCloud support.
- AWS workloads:
- “Freemium” is a free offering from Druva for AWS workload coverage; it can cover up to 20 AWS resources at once (no more than 2 accounts) while offering features such as VPC cloning, cross-region, and cross-account DR, file-level recovery, AWS Organizations integration, API access, etc.
- “Enterprise” – $7 per month per resource, starting from 20 resources, has an upper limit of 25 accounts and extends upon the previous version’s capabilities with features such as data lock, file-level search, the ability to import existing backups, the ability to prevent manual deletion, 24/7 support with 4 hours of response time at most, etc.
- “Elite” – $9 per month per resource, has no limitations on managed resources or accounts, adds auto-protection by VPC, AWS account, as well as GovCloud support, and less than 1 hour of support response time guaranteed by SLA.
- Users of Enterprise and Elite pricing plans can also purchase Druva’s capability to save air-gapped EC2 backups to Druva Cloud for an additional price.
- It is easy to see how one can get confused with Druva’s pricing scheme as a whole. Luckily, Druva themselves have a dedicated webpage with the sole purpose of creating a personalized estimate of a company’s TCO with Druva in just a few minutes (a pricing calculator).
My personal opinion on Druva:
Druva offers a cloud-native and app-aware backup and recovery solution that solves one of the most common issues of Kubernetes – the fact that the failed cluster is always restored in a blank state after failing for some reason. The software itself is provided using a Storage-as-a-Service model, and it is quite competent in protecting Kubernetes environments (as well as plenty of other storage types). Druva can back up data, restore data, automate a number of tasks, create backups of specific applications, and back up specific areas (app groups or namespaces, for example). The solution also supports EKS and Amazon EC2, making it quite the outlier on this list – and on the general market. Druva does have a few issues with it, including a rather complicated first-time configuration process and a rather slow performance when it comes to retrieving backups from cloud storage, but the overall solution is quite capable, especially for Kubernetes environments.
Zerto

Zerto is also a good choice if you’re looking for a multifunctional backup management platform with native Kubernetes support. It offers everything you’d want from a modern Kubernetes backup and restore solution – CDP (continuous data protection), data replication via snapshots, and minimal vendor lock-in thanks to Zerto supporting all of the Kubernetes platforms in the enterprise field.
Zerto also offers data protection as one of the core strategies from day one, offering applications the ability to be generated with protection from the start. Zerto also has many automation capabilities, is capable of providing extensive insights, and can work with different cloud storages at once.
Data types covered by Zerto:
Zerto’s position in terms of Kubernetes data coverage is simple – it cannot work with Applications or Storage Infrastructures, but everything else can be backed up with no issues whatsoever – be it Deployments, Namespaces, Services, Pods, etc.
Customer ratings:
- Capterra – 4.8/5 stars based on 25 customer reviews
- TrustRadius – 8.6/10 stars based on 113 customer reviews
- G2 – 4.6/5 stars based on 73 customer reviews
Advantages:
- Management simplicity for disaster recovery tasks
- Ease of integration with existing infrastructures, both on-premise and in the cloud
- Workload migration capabilities and plenty of other features
- Zerto’s Kubernetes capabilities are also quite vast and varied, including continuous data protection, snapshot replication, and more
Shortcomings:
- Can only be deployed on Windows operating systems
- Reporting features are somewhat rigid
- Can be quite expensive for larger enterprises and businesses
Pricing (at the time of writing):
- The official Zerto website offers three different licensing categories – Zerto for VMs, Zerto for SaaS, and Zerto for Kubernetes
- Zerto’s licensing for Kubernetes specifically can be acquired in two different forms
- “Zerto Data Protection” is a data protection software that delivers continuous backup and recovery features across the entire application deployment lifecycle, it includes long-term retention, cloning, local replication, orchestrated backups, and more
- “Enterprise Cloud Edition” is a cloud-based version of the previous offering that also offers continuous backup and recovery throughout the entire application development lifecycle, it expands upon the existing feature set with features such as orchestrated disaster recovery and always-on remote replication
- There is no official pricing information available for Zerto’s solution, it can only be acquired via a personalized quote or purchased through one of Zerto’s sales partners
My personal opinion on Zerto:
Zerto as a backup solution is a good option for multiple use cases at once – it is a comprehensive platform that supports a variety of different storage types. Zerto can work with Azure, AWS, and Google Cloud as cloud storage providers; it supports VM coverage, container coverage, and plenty of other use cases. It can offer data protection as one of its biggest and most comprehensive features, and there are plenty of options for Kubernetes environments specifically – be it minimal vendor lock-in, data replication capabilities, CDP support, and more. Some features of Zerto are also applicable to all of the different storage types at the same time, be it data analysis with extensive insights, plenty of automation options, etc.
Longhorn

Longhorn is probably the least known out of the solutions discussed on this blog. Its community is relatively small for an open-source solution, and it does not allow for complete Kubernetes backups with metadata and resources to make app-aware recovery happen. However, there is one unique feature about it that stands out, and it’s called DR Volume. DR Volume can be set up as a both source and a destination, making the volume active in a new cluster that’s based on the latest backed-up data.
Longhorn’s capabilities to work with many different container platform types and allow for different backup methods are what differentiates it from the rest, and there’s already an ability to support Kubernetes Engine, Docker deployments, and K3 distributions. Docker containers, for example, have to create a tarball that could act as a backup for Longhorn.
Data types covered by Longhorn:
For a free solution, Longhorn can offer quite the package of data type coverage to its users – including backups for Deployments, StatefulSets, Services, Secrets, Pods, and more. It does not have the ability to back up Namespaces, Applications, or Storage Infrastructure.
Customer ratings:
Key features:
- Infrastructure-agnostic solution
- Easy deployment process
- Convenient and useful dashboard
- Simple customization for backup and disaster recovery policies
Pricing (at the time of writing):
- Longhorn is a free and open-source Kubernetes backup solution that was originally developed by Rancher Labs but was later donated to CNCF (Cloud Native Computing Foundation) and is now considered a stand-alone sandbox project.
- Rancher itself does have a separate premium pricing tier called Rancher Prime – it offers a variety of features to expand and improve the original Rancher’s functionality, but its price is not publicly available on the official website.
My personal opinion on Longhorn:
Similar to a number of previous examples, Longhorn does not offer complete Kubernetes coverage – meaning that there would be no app-aware backups. At the same time, it is an interesting option for small-scale businesses and companies on a budget – considering that Longhorn is free, supports a number of container variants, and even multiple backup methods. Longhorn can also offer its own unusual feature called DR Volume – a volume that can be set as both a destination and a source, making it immediately active in the cluster that was newly created using the existing backup data. It is also relatively simple for a free and open-source solution, although some degree of a learning curve is still to be expected.
Velero.io

Velero is an open-source Kubernetes backup and recovery solution with migration capabilities. It supports snapshots for persistent volumes and cluster states, making both migration and restoration possible in different environments. It is a well-known solution in the Kubernetes backup sphere, offering reliable disaster recovery capabilities for Kubernetes clusters along with cluster migration, long-term retention for compliance purposes, and more.
Key features:
- Cluster migration with different configurations.
- Cluster-wide protection and granularity in backup processes.
- Extensive disaster recovery capabilities for business continuity purposes.
- Backup scheduling with plenty of options to choose from.
- Integration with the API to create persistent volume snapshots for large datasets.
- Support for a number of cloud storage providers, including Azure Blob, Google Cloud, AWS S3, etc.
Pricing (at the time of writing):
- Velero.io is a completely free and open-source tool with no price attached to the software.
My personal opinion on Velero.io:
Velero is an interesting option for backup and recovery tasks in Kubernetes environments, considering that it is free and can offer extensive granularity in its capabilities. It supports different storage providers, can be integrated with the API of the platform for persistent snapshots, and is generally a surprisingly convenient solution for many situations. It is not particularly usable in most enterprise-grade use cases due to the sheer scope of operations necessary, and the lack of most popular security features such as encryption would make it difficult to work with for businesses that deal with sensitive information, but the solution overall is still worth looking over, at the very least.
What checklist should teams follow for Kubernetes backup readiness?
Having the recovery strategy on paper is not the same as having it ready to perform. Let this checklist help you to ensure the decisions and configurations made within this document are implemented in tangible and verifiable ways.
Have you inventoried critical workloads and data scopes?
Before anything else, you need to know exactly what you’re protecting. Without a clear inventory, backup policies tend to be either too broad or full of gaps.
- All namespaces and workloads are documented and classified by criticality
- Persistent volumes are categorized by recovery priority
- Custom resources and CRDs associated with each workload are identified
- Stateful applications are distinguished from stateless ones in your inventory
- Data ownership is assigned for each critical workload
Are RPO, RTO, and retention policies documented and approved?
Recovery requirements that haven’t been formally agreed on tend to shift under pressure. These should be locked down before an incident, not negotiated during one.
- RPO and RTO targets are defined for each workload tier
- Backup frequency for etcd, PVs, and application data reflects those targets
- Retention windows are documented and approved by whoever owns the recovery SLA
- Lifecycle and tiering policies are in place for older backup data
- Policies are reviewed and reapproved after any significant infrastructure change
Is monitoring, alerting, and access control for backups in place?
A backup process that runs silently and fails silently offers false confidence. Operational controls need to be as robust as the backup process itself.
- Backup jobs are monitored and failures trigger alerts to the right people
- Backup and restore access is separated in RBAC configuration
- Restore operations require explicit authorization for production environments
- Encryption is applied consistently across the entire backup pipeline
- Key management is handled independently of backup storage
Do you have the tried and tested runbooks for common restore scenarios?
Documentation that hasn’t been tested is a hypothesis, not a runbook. Regular testing is what turns a recovery plan into a recovery capability.
- Runbooks exist for at least the most common restore scenarios: single namespace, full cluster, and etcd recovery
- Restore procedures have been tested end-to-end in a non-production environment
- Recovery time from each scenario has been measured against your RTO
- Runbooks are version controlled and reviewed after every test or incident
- Ownership of each runbook is assigned and current
The K8s backup solution from Bacula Enterprise
The very nature of Kubernetes environments makes them at once very dynamic and potentially complex. Backing up a Kubernetes cluster should not add unnecessarily to complexity. And, of course, it is usually important – if not critical – for System Administrators and other IT personnel to have centralized control over the complete backup and recovery system of the entire organization, including any Kubernetes environments. In this way, factors such as compliance, manageability, speed, efficiency, and business continuity become much more realistic. At the same time, the agile approach of development teams should not be thus compromised in any way.
Bacula Enterprise is unique in this space because it is a comprehensive enterprise solution for complete IT environments (not just Kubernetes) that also offers natively integrated Kubernetes backup and recovery, including multiple clusters, whether the applications or data reside outside or inside a specific cluster. Bacula brings other advantages with it, in that it is especially secure, protected and stable. These qualities become critical in the context of organizations that need to ensure the highest possible levels of security.
Cluster Recovery
Every company’s Operations Department recognizes the need to have a proper recovery strategy when it comes to cluster recovery, upgrades and other situations. A cluster that is in an unrecoverable state can be reverted back to the stable state with Bacula if both the configuration files and the persistent volumes of the cluster were backed up correctly beforehand.
Another way of showing Bacula’s working methods is by using the picture below:
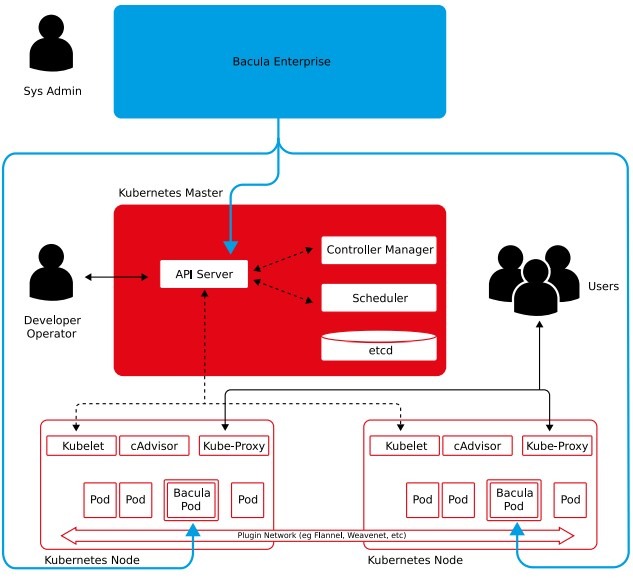
One of the prime advantages of Bacula’s Kubernetes module is the ability to backup various Kubernetes resources, including:
- Pods;
- Services;
- Deployments;
- Persistent volumes.
Features of Bacula Enterprise’s Kubernetes module
The way this module works is that the solution itself is not a part of the Kubernetes environment but instead accesses the relevant data inside the cluster via Bacula pods that are attached to single Kubernetes nodes in a cluster. The deployment of these pods is automatic and it works on an “as needed” basis.
Some other features that the K8s backup module provides also include the following:
- Kubernetes backup and restore for persistent volumes;
- Restoration of a single Kubernetes configuration resource;
- The ability to restore configuration files and/or data from persistent volumes to the local directory;
- The ability to backup resource configuration of Kubernetes clusters.
It’s also worth noting that Bacula readily supports multiple cloud storage platforms simultaneously, including AWS, Google, Glacier, Oracle Cloud, Azure and many others, at the level of native integration. Hybrid cloud capabilities are thus built in, including advanced cloud management and automated cloud caching features, allowing for easy integration of either public or private cloud services to support various tasks.
Solution flexibility is particularly important nowadays, with a lot of companies and enterprises becoming ever more complex in terms of different hypervisor families and containers. At the same time, this significantly raises the demand for vendor flexibility for all of the database vendors. Bacula’s capabilities in this regard are substantially high, combining its broad compatibility list with various technologies to reach especially high flexibility standards without locking into one vendor.
The ever-increasing complexity of different aspects of any organization’s job is always rising, and it’s more often than not easier and more cost-efficient to use one solution for the entire IT environment, and not several solutions at once. Bacula is designed to do exactly this, and is also able to provide both a traditional web-based interface for your configuration needs, as well as the classic command line type of control. These two interfaces can even be used simultaneously.
Bacula’s Kubernetes backup plugin allows for two main target types for restore operations:
- Restore to a local directory;
- Restore to a cluster.
Regular and/or automated backups are highly recommended to ensure the best possible backup and recovery environment for containers. Testing your backups from time to time should be mandatory for your System Administrator, as well. In the next picture, you’ll see a part of the restoration process, namely the Restore Selection part, in which you can choose what files and/or directories you want to restore:
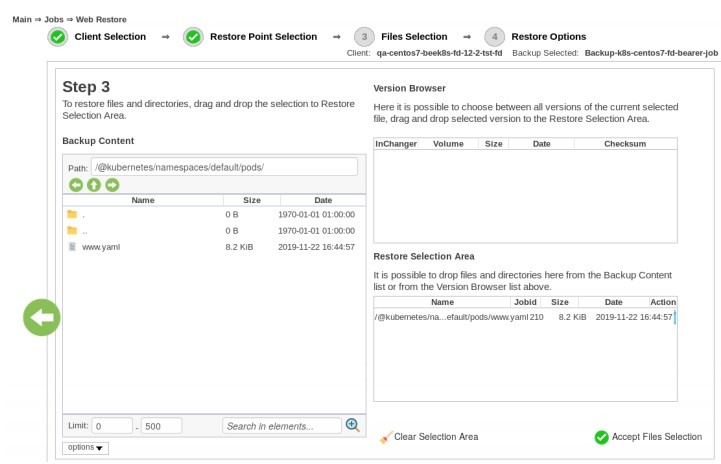
Another part of the restoration process that you’ll encounter is the advanced restore options page, which looks like this:
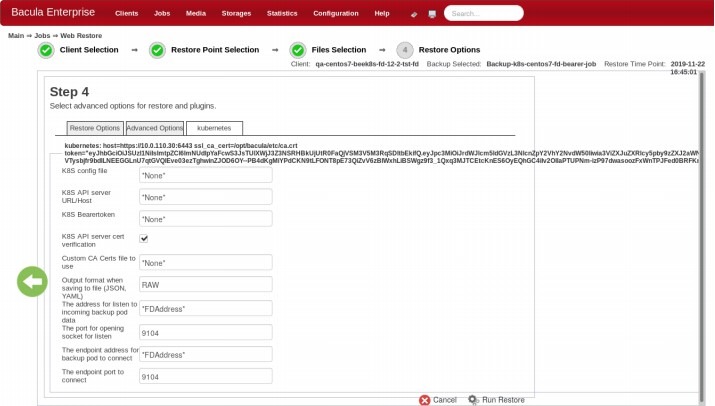
Here you can specify multiple different options, such as output format, KBS config file path, endpoint port, and more.
It’s also easy to watch over the entire restoration process after the customization is complete, thanks to the restore job log page writing every action one by one:
Another important capability of the Kubernetes module is the Plugin Listing feature, offering plenty of useful information about your available Kubernetes resources, including namespaces, persistent volumes, and so on. To do that, the module is using a special .ls command with a specific plugin=<plugin> parameter.
Bacula’s Kubernetes module offers a variety of features, some of which are:
- Fast and efficient cluster resource redeployment;
- Kubernetes cluster state safeguarding;
- Saving configurations to be used in other operations;
- Keeping amended configurations as secure as possible and restoring the exact same state as before.
Although this happens often, it is heavily recommended to avoid paying your vendor based on data volume. It makes no sense to be held to ransom now or in the future by a provider that is ready to take advantage of your organization in this way. Instead, take a close look at Bacula Systems’ licensing models, which remove its customers from exposure to data growth charges while making it far easier for customers’ procurement departments to forecast future costs, too. This more reasonable approach from Bacula comes from its open-source roots and may appeal to teams that extensively work within DevOps environments.
Conclusion
At the end of the day, Kubernetes users have plenty of different choices when it comes to backup and recovery software. Some of it is only created to manage Kubernetes data, while other solutions add Kubernetes to their existing list of features.
Smaller businesses that are looking for a solution that can only perform Kubernetes backups may find Longhorn or OpenEBS to be preferable to the rest of the examples on our list. Alternatively, bigger businesses with plenty of different storage types in their own infrastructure may need a comprehensive and highly secure backup solution that covers their entire company’s IT systems with no fragmentation and is able to view overall backup and recovery from a centralized management interface – something that solutions such as Bacula Enterprise are built for. The final choice would depend greatly on a single client’s needs and priorities, including business size, necessary features, and so on.
Why you can trust us
Bacula Systems is all about accuracy and consistency, our materials always try to provide the most objective point of view on different technologies, products, and companies. In our reviews, we use many different methods such as product info and expert insights to generate the most informative content possible.
Our materials offer all kinds of factors about every single solution presented, be it feature sets, pricing, customer reviews, etc. Bacula’s product strategy is overlooked and controlled by Jorge Gea – the CTO at Bacula Systems of Bacula Systems, and Rob Morrison – the Marketing Director of Bacula Systems.
Before joining Bacula Systems, Jorge was for many years the CTO of Whitebearsolutions SL, where he led the Backup and Storage area and the WBSAirback solution. Jorge now provides leadership and guidance in current technological trends, technical skills, processes, methodologies and tools for the rapid and exciting development of Bacula products. Responsible for the product roadmap, Jorge is actively involved in the architecture, engineering and development process of Bacula components. Jorge holds a Bachelor degree in computer science engineering from the University of Alicante, a Doctorate in computation technologies and a Master Degree in network administration.
Rob started his IT marketing career with Silicon Graphics in Switzerland, performing strongly in various marketing management roles for almost 10 years. In the next 10 years, Rob also held various marketing management positions in JBoss, Red Hat, and Pentaho ensuring market share growth for these well-known companies. He is a graduate of Plymouth University and holds an Honours Digital Media and Communications degree.
Bacula Systems is all about accuracy and consistency, our information always tries to provide the most objective point of view on different technologies, products, and companies. In our reviews, we use many different methods, such as product info and expert insights, to generate the most informative content possible.
Our materials offer all kinds of factors about every single solution presented, be it feature sets, pricing, customer reviews, etc. Bacula’s product strategy is overlooked and controlled by Jorge Gea – the CTO at Bacula Systems of Bacula Systems, and Rob Morrison – the Marketing Director of Bacula Systems.
Before joining Bacula Systems, Jorge was for many years the CTO of Whitebearsolutions SL, where he led the Backup and Storage area and the WBSAirback solution. Jorge now provides leadership and guidance in current technological trends, technical skills, processes, methodologies, and tools for the rapid and exciting development of Bacula products. Responsible for the product roadmap, Jorge is actively involved in the architecture, engineering, and development process of Bacula components. Jorge holds a Bachelor’s degree in computer science engineering from the University of Alicante, a Doctorate in computation technologies, and a Master’s Degree in network administration.
Rob started his IT marketing career with Silicon Graphics in Switzerland, performing strongly in various marketing management roles for almost 10 years. In the next 10 years, Rob also held various marketing management positions in JBoss, Red Hat, and Pentaho ensuring market share growth for these well-known companies. He is a graduate of Plymouth University and holds an Honours Digital Media and Communications degree.
Frequently Asked Questions
What is the primary purpose of Kubernetes backups?
The purpose of a Kubernetes backup is similar to why most backups are made – to create secure copies of information to be recovered in case of any disaster, accidental or intentional. A proper backup package can be the solution to system failures, data loss, data corruption, data theft, and many other situations when the entire company’s existence relies on whether the data can be restored or not.
How complex are Kubernetes backups in comparison with traditional VM backups?
The containerized nature of Kubernetes workloads is the primary reason why these backups are considered more challenging and sophisticated than regular VM backups. Each Kubernetes application includes several microservices, with the requirement to back up both a cluster state and an application state for proper functioning, making proper restoration without losing continuity very challenging. Additionally, the ever-changing nature of Kubernetes clusters adds another layer of difficulty on top of everything else, making the backup and recovery processes even more complex.
What backup software is the best possible option for Kubernetes backups?
It is difficult to say that a single solution is the absolute best possible option for a specific use case, considering how every company has its own specific set of circumstances and requirements. Most companies are also on a strict budget when it comes to backup software, meaning that the total feature range would have a lower priority than the price of the solution. At the end of the day, the most useful solution on this list is going to be the one that is suitable for the largest number and widest range of potential use cases – in that situation, Bacula Enterprise would be the undisputed winner from this list.
What can Bacula offer for multi-cloud Kubernetes environments?
Bacula provides the flexibility of data restoration and disaster recovery by allowing backup storage across different cloud storage environments. Restoring information to any compatible cluster instead of the cluster that the data was copied from is also an option here. The resilience and redundancy of a Kubernetes environment is drastically increased that way, especially when it comes to various cloud-specific outages. Bacula also allows its users to restore both namespaces and entire clusters in different cloud storage environments, providing extensive continuity without tying up users to the same cloud storage. One critical aspect that is often somewhat overlooked by Kubernetes architects is the need of their organization to get the very highest levels of security possible. Compared to practically all other backup providers, Bacula has higher levels of security built into its architecture, its methodologies, its processes and its individual features.
What kind of environment types does Bacula support?
Not only can Bacula work with on-premises and cloud-based Kubernetes clusters, but it also supports hybrid environments, making it possible to mix and match both deployment options for the highest possible level of flexibility, efficiency and security in different environments.


Thank you for the informative guide on Kubernetes backup. Your expertise helps ensure data resilience in modern cloud environments.