

Contents
- Einleitung
- Wichtige Konzepte für einen Kubernetes-Backup-Prozess
- Warum sind K8s-Backups notwendig?
- Der Wert von Kubernetes-Backups
- Die Vorteile von Kubernetes-Backup-Vorgängen
- Kubernetes-Datentypen, die gesichert werden müssen
- Was sollten Sie in einer Kubernetes-Umgebung sichern?
- Wie wirkt sich GitOps auf Ihre Kubernetes-Backup-Strategie aus?
- Best Practices für Kubernetes-Backup-Vorgänge
- Wie sollten Sie Kubernetes-Backup-Zeitpläne und Aufbewahrungsrichtlinien gestalten?
- Wie sichern Sie Kubernetes-Backups und erfüllen Compliance-Anforderungen?
- Methodik zur Auswahl der bestmöglichen Kubernetes-Backup-Lösung
- Markt für Kubernetes-Sicherungslösungen
- Welche Checkliste sollten Teams befolgen, um für Kubernetes-Backups gerüstet zu sein?
- Die K8s-Backup-Lösung von Bacula Enterprise
- Fazit
- Warum Sie uns vertrauen können
- Häufig gestellte Fragen
Einleitung
Kubernetes (auch bekannt als K8s) ist eine Plattform zur Container-Orchestrierung, die bei der Verwaltung und Skalierung von Anwendungen hilft – oft die bevorzugte Wahl für Unternehmen, die von der Architektur containerisierter Anwendungen profitieren können. Die Flexibilität von Kubernetes führt dazu, dass sich viele Bereitstellungen stark voneinander unterscheiden. Einzigartige Strukturen bringen jedoch in der Regel einzigartige Herausforderungen hinsichtlich Wiederherstellung und Verfügbarkeit mit sich, die alle Teil der Herausforderung sind, Kubernetes in Ihrer Unternehmens-IT-Infrastruktur einzusetzen.
Während die Annahme, dass Kubernetes früher hauptsächlich von DevOps-Teams genutzt wurde, vielleicht bis zu einem gewissen Grad zutraf, setzen viele Unternehmen Container mittlerweile aktiv in Produktionsumgebungen ein. Sie verlassen sich zudem zunehmend auf Container zur Bereitstellung von Anwendungen, anstatt traditionelle VMs zu verwenden. Dies ist auf die verschiedenen Vorteile in Bezug auf Flexibilität, Leistung und Kosten zurückzuführen, die Container bieten können. Da Container jedoch zunehmend in den operativen Bereich der IT-Umgebung Einzug halten, wächst die Sorge um die Sicherheitsaspekte von Containern in Produktionssystemen, die stets verfügbar bleiben müssen – einschließlich ihrer persistenten Daten im Zusammenhang mit Backup- und Wiederherstellungsprozessen.
Ursprünglich waren die allermeisten containerisierten Anwendungen zustandslos, was ihnen einen wesentlich einfacheren Bereitstellungsprozess in einer öffentlichen Cloud ermöglichte. Dies hat sich jedoch im Laufe der Zeit geändert, da heute weitaus mehr zustandsbehaftete Anwendungen in Containern bereitgestellt werden als zuvor. Diese Veränderung ist der Grund, warum Backup und Wiederherstellung in Kubernetes mittlerweile für viele Unternehmen ein wichtiges Thema sind.
Wichtige Konzepte für einen Kubernetes-Backup-Prozess
- Die Bedeutung von Kubernetes-Backups dreht sich um Datensicherheit, da Informationen die wichtigste Ressource jedes modernen Unternehmens sind und fast immer erfordern, dass diese Daten sicher, geschützt und vertraulich aufbewahrt werden. Im Kontext von Kubernetes umfassen wertvolle Informationen in der Regel auch Konfigurationen, Secrets, die etcd-Datenbank, persistente Volumes usw.
- Eine ordnungsgemäße Konfiguration der Backup-Strategie kann einer Kubernetes-Umgebung zahlreiche Vielseitigkeiten und Funktionen bieten, darunter Backups auf Anwendungsebene, Backups auf Namespace-Ebene, Snapshots, Backup-Validierung, Versionierung, Backup-Richtlinien und vieles mehr.
- Eine korrekte Konfiguration der Wiederherstellung ist ebenso wichtig, wenn man bedenkt, wie viele verschiedene Teile des Prozesses potenziell fehlschlagen können. Rigorose Backup-Tests, Beratung zur Dokumentation und ständige Wachsamkeit während der Wiederherstellung sind Teil dessen, was für erfolgreiche Wiederherstellungsprozesse gewährleistet werden muss.
- Kubernetes-Backups können auf eine Reihe von Herausforderungen stoßen – seien es Bedenken hinsichtlich der Datenkonsistenz, Compliance-Standards, Datensicherheit und Versionskompatibilität, um nur einige zu nennen. Die gute Nachricht ist, dass die meisten dieser Fallstricke mit einem gewissen Maß an Vorbereitung vermieden oder gemildert werden können.
Warum sind K8s-Backups notwendig?
Eine Kubernetes-Umgebung ist dynamisch, verteilt und von Natur aus anfälliger für Datenverluste als eine herkömmliche Infrastruktur. Dieser Abschnitt befasst sich mit den verschiedenen Ausfallfaktoren, die Backups unverzichtbar machen, den unterschiedlichen Ausfallkategorien, den entsprechenden Wiederherstellungsstrategien sowie der Notwendigkeit, Backup-Anforderungen explizit in SLAs und Runbooks zu dokumentieren.
Welchen Risiken sind Kubernetes-Cluster ohne Backups ausgesetzt?
In einer Kubernetes-Umgebung bestehen Gefahren, die über die üblichen Infrastrukturprobleme hinausgehen.
- Gezielte Angriffe auf die Lieferkette gegen Container-Images oder Helm-Repositorys können leicht bösartigen Code einschleusen, der schwer zu erkennen ist, bevor er Schaden anrichtet
- Cloud-IAM-Rollen, die unsachgemäß konfiguriert wurden, können die Cluster-Ressourcen auf breiter Ebene offenlegen – oder schlimmer noch – beschädigen
- Auto-Scaling-Ereignisse können zustandsbehaftete Workloads schnell unvorbereitet treffen und unsichtbare, aber dauerhafte Datenbeschädigungen verursachen
Risiken wie diese können sich in verteilten Systemen extrem schnell vervielfachen, wo sich die Auswirkungen eines einzelnen Ereignisses auf Dutzende von Workloads in Dutzenden von Namespaces ausbreiten können.
Wie unterscheiden sich Anwendungs-, Cluster- und Datenausfälle?
Kubernetes-Ausfälle treten häufig in verschiedenen Schichten auf und erfordern entsprechend unterschiedliche Wiederherstellungsstrategien. Der Ausfall kann sich nur auf eine einzelne Workload auswirken, auf den gesamten Cluster oder auf Daten, die extern von beiden gespeichert werden. In den folgenden Abschnitten werden diese Ausfälle jeweils näher behandelt, doch das Vorabwissen um diese Unterscheidung schafft auch die Grundlage dafür, zu verstehen, warum eine Einheitsstrategie für Backups selten erfolgreich ist.
Wann sollten Backups Teil Ihrer SLAs und Runbooks sein?
Backups müssen obligatorisch sein, wenn für eine Workload ein definiertes RTO und/oder RPO gilt. Wenn Sie sich zu einem Recovery Time Objective verpflichtet haben, sollte diese Kennzahl mit einem dokumentierten und getesteten Wiederherstellungsprozess einhergehen. Das bedeutet, dass die Häufigkeit der Backups, die Aufbewahrungsdauer und der Wiederherstellungsprozess vor einem Vorfall dokumentiert werden sollten, nicht erst danach.
Workloads, die in einem Bereitschafts-Runbook aufgeführt sind, sollten mit einer expliziten Zuständigkeit und einer dokumentierten Backup-Richtlinie berücksichtigt werden. Compliance-regulierte Umgebungen fügen dem Prozess eine eigene Ebene hinzu, die den Nachweis erfordert, dass die Backups vorhanden sind, getestet wurden und die erforderlichen dokumentierten Aufbewahrungsrichtlinien erfüllen.
Der Wert von Kubernetes-Backups
Die Natur von Kubernetes-Umgebungen erschwert es traditionelleren Backup-Systemen und -Techniken, im Kontext von Kubernetes-Knoten und -Anwendungen gut zu funktionieren. Sowohl RPO als auch RTO können in der Tat weitaus kritischer sein, da Anwendungen, die Teil einer operativen Bereitstellung sind, ständig verfügbar sein müssen, insbesondere kritische Infrastrukturelemente.
Dies führt uns dazu, wichtige Elemente der Geschäftskontinuität zu identifizieren, die für jedes Unternehmen im Allgemeinen praktisch notwendig sind und eine klare Notwendigkeit darstellen, wenn es um Best Practices für K8s-Backups geht: Backup und Wiederherstellung, lokale Hochverfügbarkeit, Disaster Recovery, Ransomware-Schutz, menschliches Versagen und so weiter. In einer Kubernetes-Umgebung kann sich der Kontext dieser Aspekte der Datensicherung gegenüber ihrer üblichen Definition leicht ändern.
Lokale Hochverfügbarkeit
Lokale Hochverfügbarkeit als Funktion bezieht sich eher auf Ausfallprävention bzw. Schutz innerhalb eines bestimmten Rechenzentrums oder über Verfügbarkeitszonen hinweg (wenn wir beispielsweise von der Cloud sprechen). Ein „lokaler“ Ausfall tritt in der Infrastruktur, dem Knoten oder der Anwendung auf, die zur Ausführung der Anwendung verwendet wird. Im Idealfall sollte Ihre Kubernetes-Backup-Lösung auf diesen Ausfall reagieren können, indem sie den Betrieb der Anwendung aufrechterhält, was im Wesentlichen bedeutet, dass für den Endbenutzer keine Ausfallzeiten entstehen. Eines der häufigsten Beispiele für einen lokalen Ausfall ist ein blockiertes Cloud-Volume, das nach einem Knotenausfall auftritt.
Aus dieser Perspektive kann lokale Hochverfügbarkeit als Funktion als zentraler Bestandteil der Datensicherungsstrategie betrachtet werden. Zum einen muss Ihre Lösung zur Erfüllung einer solchen Aufgabe lokal eine Art Datenreplikationssystem bieten, und dieses muss zudem im Datenpfad an erster Stelle stehen. Es ist wichtig zu erwähnen, dass die Bereitstellung lokaler Verfügbarkeit über die Wiederherstellung von Backups aufgrund der Gesamtwiederherstellungszeit weiterhin als Backup und Wiederherstellung und nicht als lokale Hochverfügbarkeit betrachtet wird.
Sicherung und Wiederherstellung
Sicherung und Wiederherstellung ist ein weiteres wichtiges Element eines operativen Kubernetes-Systems. In den meisten Anwendungsfällen wird die gesamte Anwendung von einem lokalen Kubernetes-Cluster an einen externen Standort gesichert. Der Kontext von Kubernetes wirft zudem eine weitere wichtige Frage auf – nämlich, ob die Sicherungssoftware „versteht“, was in einer Kubernetes-Anwendung enthalten ist, wie zum Beispiel:
- Anwendungskonfiguration;
- Kubernetes-Ressourcen;
- Daten
Eine korrekte Kubernetes-Sicherung muss alle oben genannten Teile als eine Einheit speichern, damit sie nach der Wiederherstellung im Kubernetes-System nutzbar ist. Das Anvisieren bestimmter VMs, Server oder Festplatten bedeutet nicht, dass die Software Kubernetes-Anwendungen „versteht“. Im Idealfall sollte Kubernetes-Software in der Lage sein, bestimmte Anwendungen, bestimmte Gruppen von Anwendungen sowie den gesamten Kubernetes-Namespace zu sichern. Das bedeutet nicht, dass sich dieser Prozess vollständig vom regulären Backup-Prozess unterscheidet – Kubernetes-Backups können ebenfalls erheblich von einigen der üblichen Funktionen eines normalen Backups profitieren, darunter Aufbewahrungsfristen, Zeitplanung, Verschlüsselung, Tiering und so weiter.
Disaster Recovery
Die Disaster Recovery (DR)-Fähigkeit ist für jedes Unternehmen, das Kubernetes in einer geschäftskritischen Situation einsetzt, unverzichtbar – genau wie bei der Nutzung jeder anderen Technologie. Zunächst muss die DR den Kontext von Kubernetes-Backups „verstehen“, genau wie bei der Sicherung und Wiederherstellung. Sie kann zudem unterschiedliche Stufen von RTO und RPO sowie je nach diesen Stufen unterschiedliche Schutzstufen aufweisen. So könnte es beispielsweise eine strenge Zero-RPO-Anforderung geben, die absolut keine Ausfallzeit impliziert, oder es könnte ein 15-Minuten-RPO mit etwas weniger strengen Anforderungen bestehen. Es ist zudem nicht ungewöhnlich, dass verschiedene Anwendungen innerhalb derselben Datenbank völlig unterschiedliche RTOs und RPOs aufweisen.
Ein weiterer wichtiger Unterschied eines Kubernetes-spezifischen Disaster-Recovery-Systems besteht darin, dass es in gewissem Umfang auch mit Metadaten (Labels, App-Replikate usw.) arbeiten können sollte. Die Unfähigkeit, diese Funktion bereitzustellen, könnte leicht zu einer unzusammenhängenden Wiederherstellung im Allgemeinen sowie zu allgemeinem Datenverlust oder zusätzlichen Ausfallzeiten führen.
Schutz vor Ransomware
Die Bedeutung von Backups für Kubernetes-Systeme (insbesondere solche, die persistente Daten generieren) ist mit der von regulären Daten-Backups vergleichbar. Wertvolle Daten sollten gesichert werden, um inakzeptable Risiken zu vermeiden. Informationen sind von unschätzbarem Wert, und Bacula Systems empfiehlt dringend, einen (oder mehrere) dedizierten Plan(e) für Situationen parat zu haben, in denen Geschäftsdaten beschädigt oder anderweitig kompromittiert werden.
Viele dieser Schutzmaßnahmen wirken sowohl gegen versehentliche als auch gegen böswillige Vorfälle. Vorsätzliche Angriffe, die zu Datenverletzungen durch Ransomware, Identitätsdiebstahl und andere Maßnahmen führen, sind nur allzu häufig geworden, und es ist völlig unrealistisch zu glauben, dass Ihr Unternehmen niemals Ziel eines solchen Vorfalls sein wird. Daher kann die Vorbereitung auf diese Situationen Vorteile in Bezug auf eine Reihe äußerst wichtiger Faktoren bieten, wie z. B. die Einhaltung von Compliance-Vorgaben, den Schutz der persönlichen und geschäftlichen Reputation, den Schutz von Kunden und Mitarbeitern und vor allem die allgemeine Vermeidung schwerwiegender Schäden für ein Unternehmen und/oder eine Organisation.
Menschliches Versagen
Die Folgen eines einzigen menschlichen Fehlers können erheblich sein (versehentliches Löschen, falsche Konfigurationen, unbeabsichtigte Aktualisierungsbereitstellung). Zwar kann die Automatisierung einiger Funktionen menschliches Versagen etwas abmildern, doch ist es in den meisten Unternehmen in der Regel unmöglich, jeden einzelnen Prozess zu automatisieren.
In diesem Zusammenhang dienen Backup- und Disaster-Recovery-Pläne dazu, sicherzustellen, dass ein Unternehmen seinen Geschäftsbetrieb nach einem Vorfall mit einem falschen Befehl oder einem Konfigurationsfehler effektiv fortsetzen kann.
Die Vorteile von Kubernetes-Backup-Vorgängen
Kubernetes-Backups bieten zahlreiche Vorteile – oft ähnlich wie reguläre Backup-Vorgänge bei anderen Datentypen. Sie sind eine hervorragende Möglichkeit, die Zuverlässigkeit, Verfügbarkeit und Integrität von Kubernetes-Anwendungen und App-Daten zu gewährleisten. Einige der häufigsten Vorteile sind im Folgenden aufgeführt.
Minderung der Auswirkungen von Hardwareausfällen
Technisch gesehen sind Hardwareausfälle unvermeidbar und können praktisch jederzeit auftreten; sei es ein Netzwerkausfall, ein Stromausfall, eine Fehlfunktion einer Speichereinheit oder jede andere Art von Ereignis, das zu Datenbeschädigung oder Datenverlust führt. Kubernetes-Backups bieten ein hohes Maß an Schutz vor solchen Vorfällen, indem sie eine redundante Kopie der Daten bereitstellen, die in jede andere Umgebung wiederhergestellt werden kann, falls die ursprüngliche Hardware nicht mehr verfügbar ist. Dadurch werden Ausfallzeiten minimiert und die Geschäftskontinuität verbessert.
Notfallwiederherstellung
Die meisten Naturkatastrophen sind in der Lage, die gesamte physische Infrastruktur eines Unternehmens vollständig zu zerstören, einschließlich seiner Kubernetes-Cluster und möglicherweise sogar der primären Backups dieser Cluster. Das Vorhandensein eines externen Backups ist daher einer von vielen Vorteilen, die eine Notfallwiederherstellungsstrategie ihren Nutzern bietet, da sie eine Möglichkeit darstellt, das gesamte Clusternetzwerk schnell wiederherzustellen, um den Betrieb innerhalb eines akzeptablen Zeitraums wieder aufzunehmen.
Verhinderung von Datenverlusten
Versehentliche Fehler und Missmanagement sind bis heute überraschend häufig, ganz abgesehen von der steigenden Zahl böswilliger Datenverletzungen. Jeder Mensch kann Fehler machen, und die Unmöglichkeit, eine bestimmte Aktion, Löschung oder Änderung rückgängig zu machen, erhöht die Wahrscheinlichkeit eines dauerhaften Datenverlusts bei sensiblen Informationen drastisch. Regelmäßige K8s-Backups tragen dazu bei, sicherzustellen, dass unbeabsichtigte Unfälle auf die eine oder andere Weise noch behoben werden können.
Abwehr von Cyberangriffen
Cyberbedrohungen nehmen seit einigen Jahren deutlich zu, und es wird fast überall davon ausgegangen, dass sich die Lage weiter verschlechtern wird. Jede IT-Infrastruktur ist ständig dem Risiko eines Cyberangriffs ausgesetzt, und das Vorhandensein definierter und sicherer Backup-Maßnahmen ist entscheidend für den Schutz ganzer Unternehmen. Ein Versäumnis in dieser Hinsicht stellt ein erhebliches Risiko für den Fortbestand des Unternehmens selbst dar.
Unterstützung für Test- und Entwicklungsumgebungen
Regelmäßige Backups von Kubernetes-Clustern bieten oft einen zusätzlichen Nutzen: Sie können auch eine große Hilfe bei Test- und Entwicklungsprozessen sein und die Erstellung von Cluster-Replikaten für Entwicklungszwecke erheblich vereinfachen, ohne die Originaldaten zu beeinträchtigen. Auf diese Weise können Experimente wesentlich fruchtbarer und effizienter verlaufen und dem Unternehmen selbst zahlreiche Entwicklungsmöglichkeiten bieten.
Kubernetes-Datentypen, die gesichert werden müssen
Der übliche Grund für den Einsatz von Containerisierung ist die Schaffung und der Betrieb einer sicheren, zuverlässigen und schlanken Laufzeitumgebung für Anwendungen, wodurch ein System entsteht, das von Host zu Host konsistent ist. In der Regel erzeugen diese Systeme persistente Daten – und wenn dies der Fall ist, sind diese Daten meist von Wert und sollten daher gesichert werden. Darüber hinaus sollte das gesamte Containersystem selbst geschützt und gesichert werden, damit das System im Falle eines Verlusts oder einer Beschädigung schnell wiederhergestellt werden kann, wodurch der Verlust von Systemen und Diensten – und potenziellen Geschäften – für ein Unternehmen minimiert wird.
Kubernetes ist die derzeit beliebteste Container-Technologie. Daher erfordert das Thema der verschiedenen Kubernetes-Datentypen, die gesichert werden müssen, eine gründliche Untersuchung.
Wie bei jedem komplexen System verfügen Kubernetes und Docker über eine Reihe spezifischer Datentypen, die erforderlich sind, um die gesamte Datenbank im Katastrophenfall ordnungsgemäß wiederherzustellen. Zur Vereinfachung lassen sich alle Daten- und Konfigurationsdateitypen in zwei verschiedene Kategorien unterteilen: Konfigurationsdaten und persistente Daten.
Zur Konfiguration (und zu den Informationen zum gewünschten Zustand) gehören:
- Kubernetes-etcd-Datenbank
- Docker-Dateien
- Images aus Docker-Dateien
Persistente Daten (die von den Containern selbst geändert oder erstellt wurden) sind:
- Datenbanken
- Persistente Volumes
Kubernetes-etcd-Datenbank
Sie ist ein integraler Bestandteil des Systems und enthält Informationen über den Status des Clusters. Sie kann je nach Ihrer Backup-Lösung entweder manuell oder automatisch gesichert werden. Die manuelle Methode erfolgt über den Befehl etcdctl snapshot save db, der eine einzelne Datei mit dem Namen snapshot.db erstellt.
Eine weitere Möglichkeit, dasselbe zu erreichen, besteht darin, denselben Befehl unmittelbar vor der Erstellung einer Sicherung des Verzeichnisses auszuführen, in dem diese Datei enthalten wäre. Dies ist eine der Möglichkeiten, diese spezifische Sicherung in die gesamte Umgebung zu integrieren.
Docker-Dateien
Da Docker-Container selbst aus Images ausgeführt werden, müssen diese Images auf etwas basieren – und diese wiederum werden aus Docker-Dateien erstellt. Für eine korrekte Docker-Konfiguration wird empfohlen, ein Repository als Versionskontrollsystem für alle Ihre Docker-Dateien zu verwenden (z. B. GitHub). Um das Abrufen früherer Versionen zu vereinfachen, sollten alle Docker-Dateien in einem bestimmten Repository gespeichert werden, das es Benutzern ermöglicht, bei Bedarf ältere Versionen dieser Dateien abzurufen.
Ein zusätzliches Repository wird auch für die YAML-Dateien empfohlen, die mit allen Kubernetes-Deployments verbunden sind; diese liegen in Form von Textdateien vor. Die Sicherung dieser Repositorys ist ebenfalls ein Muss, entweder mithilfe von Tools von Drittanbietern oder der integrierten Funktionen von Diensten wie GitHub.
Es ist wichtig zu erwähnen, dass Sie die zu sichernden Docker-Dateien auch dann erstellen können, wenn Sie Container aus Images ohne deren Docker-Dateien ausführen. Es gibt einen speziellen Befehl namens docker image history, mit dem Sie aus Ihrem aktuellen Image eine Docker-Datei erstellen können. Es gibt auch mehrere Tools von Drittanbietern, die dasselbe leisten können.
Images aus Docker-Dateien
Docker-Images selbst sollten ebenfalls in einem Repository gesichert werden. Sowohl das private als auch das öffentliche Repository können genau für diesen Zweck genutzt werden. Verschiedene Cloud-Anbieter stellen ihren Kunden in der Regel ebenfalls private Repositorys zur Verfügung. Falls Ihnen das Image fehlt, auf dem Ihr Container läuft, sollte ein spezieller Befehl namens docker commit in der Lage sein, dieses Image zu erstellen.
Datenbanken
Die Integrität ist auch entscheidend, wenn es um Datenbanken geht, die Container zur Speicherung ihrer Daten nutzen. In einigen Fällen ist es möglich, den betreffenden Container herunterzufahren, bevor eine Datensicherung erstellt wird, doch die dadurch erforderliche Ausfallzeit dürfte für das betreffende Unternehmen zahlreiche Probleme mit sich bringen.
Eine weitere Methode zur Erstellung von Datenbank-Backups innerhalb von Containern besteht darin, eine Verbindung zur Datenbank-Engine selbst herzustellen. Zunächst sollte ein Bind-Mount verwendet werden, um ein Volume anzuhängen, das überhaupt erst gesichert werden kann, und anschließend können Sie den Befehl mysqldump (oder einen ähnlichen) verwenden, um ein Backup zu erstellen. Die betreffende Backup-Datei sollte anschließend ebenfalls mit Ihrem Backup-System gesichert werden.
Persistente Volumes
Es gibt verschiedene Methoden, mit denen Container Zugriff auf eine Art persistenten Speicher erhalten. Bei traditionellen Docker-Volumes beispielsweise befinden sich diese in einem Verzeichnis unterhalb der Docker-Konfiguration. Bind-Mounts hingegen können beliebige Verzeichnisse sein, die innerhalb eines Containers eingebunden werden. Obwohl traditionelle Volumes in der Docker-Community bevorzugt werden, sind beide Methoden in Bezug auf die Datensicherung relativ gleichwertig. Eine dritte Möglichkeit, denselben Vorgang durchzuführen, besteht darin, ein NFS-Verzeichnis oder ein einzelnes Objekt als Volume innerhalb eines Containers einzubinden.
Alle drei Methoden weisen beim Datensichern dasselbe Problem auf: Die Konsistenz einer Sicherung ist nicht gewährleistet, wenn sich die Daten innerhalb eines Containers während der Sicherung ändern. Natürlich ist es immer möglich, Konsistenz zu gewährleisten, indem man das Volume vor der Sicherung abschaltet, doch in den meisten Fällen ist eine Ausfallzeit für solche Systeme im Interesse der Geschäftskontinuität nicht realistisch.
Es gibt einige methodspezifische Möglichkeiten, Daten innerhalb von Containern zu sichern. Beispielsweise könnten traditionelle Docker-Volumes in einen anderen Container eingebunden werden, der keine der Daten verändert, bis der Sicherungsprozess abgeschlossen ist. Oder wenn Sie ein bind-gemountetes Volume verwenden, ist es möglich, ein tar-Image des gesamten Volumes zu erstellen und dieses Image dann zu sichern.
Leider können all diese Optionen bei Kubernetes sehr schwer umzusetzen sein. Genau aus diesem Grund wird immer empfohlen, zustandsbezogene Informationen in der Datenbank und außerhalb des Container-Dateisystems zu speichern.
Wenn Sie jedoch ein bind-gemountetes Verzeichnis oder ein NFS-gemountetes Dateisystem als persistenten Speicher verwenden, ist es auch möglich, diese Daten mit herkömmlichen Methoden wie einem Snapshot zu sichern. Dies sollte Ihnen eine wesentlich höhere Konsistenz bieten als die herkömmliche Sicherung auf Dateiebene desselben Volumes.
Was sollten Sie in einer Kubernetes-Umgebung sichern?
In einer Kubernetes-Umgebung gibt es verschiedene Arten von Daten, und jede Art erfordert eigene Überlegungen zur Wiederherstellung. Es ist leicht zu verstehen, was gesichert werden muss; die meisten Teams tun sich jedoch schwer mit der Frage, welche Komponenten gesichert werden sollten und warum. Zu verstehen, was gesichert werden muss, ist der einfache Teil – die meisten Teams haben jedoch Schwierigkeiten damit, welche Komponenten Vorrang haben sollten und warum.
Was stellt ein etcd-Backup tatsächlich wieder her und was nicht?
Etcd ist die einzige verlässliche Quelle für den Status Ihres gesamten Clusters. Als solche ist sie das Wichtigste, was gesichert werden muss, und gleichzeitig die am meisten missverstandene Komponente. Ein etcd-Snapshot ermöglicht es Ihnen, den Status Ihres gesamten Clusters auf einen bestimmten Zeitpunkt zurückzusetzen; wenn Ihr Live-Cluster jedoch zu weit über Ihren Snapshot hinaus fortgeschritten ist, entstehen Konsistenzlücken zwischen dem, was etcd als laufend meldet, und dem, was tatsächlich vorhanden ist.
Ein etcd-Snapshot allein reicht nicht aus, um Ihren Cluster in einem Katastrophenfall vollständig wiederherzustellen, da er zwar den Cluster-Zustand enthält, jedoch keine Anwendungsdaten (die in Persistent Volumes gespeichert sind) und keine Garantie dafür bietet, dass der wiederhergestellte Zustand mit dem Zustand des von Ihnen neu aufgebauten Clusters übereinstimmt. Backups auf Anwendungsebene liefern diese fehlenden Informationen, und es ist wichtig, etcd-Snapshots als Ergänzung zu Backups auf Anwendungsebene zu betrachten und nicht als Ersatz dafür.
Müssen Sie Persistent Volumes (PV) und Persistent Volume Claims (PVC) sichern?
Ja, es ist notwendig, sowohl PV als auch PVC zu sichern, aber ihre Priorität hängt davon ab, was genau sich in ihnen befindet. Einige PVs enthalten wesentlich wertvollere Daten als andere – ein PV, das Persistenz für eine zustandsbehaftete Datenbank bietet, unterliegt nicht demselben Risikofaktor wie ein PV, das zwischengespeicherte Inhalte enthält.
Bevor Sie Ihre Sicherungshäufigkeit festlegen, ist es sinnvoll, Ihre PVs nach Wiederherstellungskritikalität zu klassifizieren, um sicherzustellen, dass Ihr Sicherungsplan den geschäftlichen Anforderungen entspricht und nicht alle Volumes gleich gewichtet.
Welche Cluster-Metadaten (Manifeste, RBAC, CRDs, ConfigMaps, Secrets) sind unverzichtbar?
All diese Metadaten sind wichtig, jedoch nicht in gleichem Maße, wenn es um zeitkritische Wiederherstellungsszenarien geht.
Der Verlust von RBAC-Konfigurationen und CRDs ist hier die störendste Option, da diese definieren, was Sie tun dürfen und was der Rest des Clusters als definierte Ressourcendefinitionen verwendet. Ohne diese Informationen ist es sehr wahrscheinlich, dass die von Ihnen wiederhergestellten Anwendungen in einem unzugänglichen oder fehlerhaften Zustand zurückkehren.
ConfigMaps und Secrets definieren ebenfalls, wie Ihre Anwendungen funktionieren, und sind zudem häufig die am meisten übersehenen Elemente in einer manuellen Backup-Strategie. Manifeste sind ebenfalls sehr wichtig, aber wenn Sie über ein GitOps-System verfügen, sollte es relativ einfach sein, sie aus der Quellcodeverwaltung wiederherzustellen, wodurch sie auf der Prioritätenliste etwas weiter unten stehen.
Wie sollten Sie mit kurzlebigen Daten und Logs umgehen?
Kurzlebige Daten – alles, was nur für die Lebensdauer eines Pods existiert – sollten im Allgemeinen nicht gesichert werden, und der Versuch, dies zu tun, erhöht die Komplexität, ohne einen sinnvollen Wiederherstellungswert zu bieten.
Protokolle befinden sich in der Regel in einer ähnlichen Situation – sie sollten im Rahmen einer Kubernetes-Backup-Strategie nicht gesichert werden. Die weitaus bessere Option ist eine dedizierte Observability-Pipeline, die diese Protokolle unabhängig vom Backup-Prozess an einen externen Speicher sendet.
Eine passendere Frage wäre hier, ob Daten, die Sie derzeit als kurzlebig betrachten, überhaupt persistent sein müssen. Falls ja, sollten sie auf ein persistentes Volume übertragen werden, anstatt in den Backup-Umfang aufgenommen zu werden.
Wie wirkt sich GitOps auf Ihre Kubernetes-Backup-Strategie aus?
GitOps ist ein Betriebsmodell, bei dem das Git-Repository den gesamten Zustand einer Kubernetes-Umgebung speichert – mit allen Manifesten, Ressourcendefinitionen und Konfigurationen. Die betreffenden Informationen werden zudem mithilfe eines speziellen Tools kontinuierlich mit dem Live-Cluster abgeglichen. Anstatt Änderungen direkt auf Ihren Cluster anzuwenden, durchlaufen diese zunächst Git – wodurch das betreffende Repository zur einzigen Quelle der Wahrheit dafür wird, wie der Cluster zu jedem Zeitpunkt aussehen sollte.
Es hat sich schnell zu einem weit verbreiteten Muster in Kubernetes-Umgebungen entwickelt und die Backup-Situation in bestimmter Weise verändert – und die Auswirkungen davon sind auch nicht immer eindeutig. Zu wissen, wo es hilft und wo es an seine Grenzen stößt, ist entscheidend, bevor Sie entscheiden, wie viel Backup-Abdeckung Sie darüber legen.
Wie verändert GitOps Ihren Ansatz bei der Konfigurationssicherung?
Wenn Ihre Kubernetes-Manifeste, RBAC-Konfigurationen und Ressourcendefinitionen in Git gespeichert und kontinuierlich durch ein Tool wie ArgoCD oder Flux abgeglichen werden, verfügen Sie bereits über eine Form der versionskontrollierten Konfigurationssicherung.
Jede deklarative Ressource, die sich in Ihrem Git-Repository befindet, kann auf einen neuen oder wiederhergestellten Cluster angewendet werden, ohne dass eine separate Sicherung dieser Ressource erforderlich ist. Dies stellt eine erhebliche Vereinfachung des Konfigurations-Backup-Prozesses dar, da Manifeste und Cluster-Ressourcenbeschreibungen, die bereits mit GitOps verwaltet werden, in Ihrer dedizierten Backup-Strategie eine geringere Priorität einnehmen können.
Was deckt GitOps nicht ab, und wo sind dedizierte Backups weiterhin erforderlich?
GitOps verwaltet den gewünschten Zustand, nicht den Laufzeitzustand oder die Daten. Daher sind persistente Volumes, nicht in Git festgeschriebene Secrets, Datenbankinhalte und Zustände, die nur innerhalb eines laufenden Clusters existieren, für GitOps unsichtbar.
Ein vollständig von GitOps verwalteter Cluster kann dennoch massive Datenverluste erleiden, wenn persistente Volumes nicht separat gesichert werden. Secrets werden aus Sicherheitsgründen in der Regel explizit aus Repositorys ausgeschlossen, sodass auch sie eine eigenständige Backup-Abdeckung erfordern.
GitOps ist keine Alternative zu einer Backup-Strategie; vielmehr ergänzen sich beide, und das Erkennen der Grenze zwischen ihnen hilft dabei, unsichere Annahmen darüber zu vermeiden, was abgedeckt ist.
Best Practices für Kubernetes-Backup-Vorgänge
Es gibt eine Reihe von Best Practices, mit denen sich der Gesamtzustand von K8s-Backups verbessern lässt, darunter die Ausfallsicherheit des Clusters, die Datensicherheit und die Zuverlässigkeit der Wiederherstellung.
Sichern Sie persistente Daten und den Cluster-Status
Der Cluster-Status umfasst Schlüsselkomponenten einer Kubernetes-Umgebung, darunter Secrets, ConfigMaps, etcd und mehr. Die persistenten Datenvolumes machen den Großteil der Datenmenge aus, darunter reguläre Dateien, Datenbanken, Benutzerdaten, Protokolle usw.
Richten Sie eine automatisierte Datensicherung ein
Die Automatisierung der Datensicherung verringert die Wahrscheinlichkeit menschlicher Fehler und sorgt für Konsistenz und Vorhersehbarkeit im Sicherungsprozess. Zahlreiche Backup-Lösungen von Drittanbietern bieten erweiterte Automatisierungsfunktionen, wie beispielsweise die Möglichkeit, Sicherungspläne unter Berücksichtigung spezifischer RTOs und RPOs zu erstellen.
Verwenden Sie nach Möglichkeit verschiedene Backup-Typen
Kubernetes-Daten können mit unterschiedlichen Backup-Ansätzen gesichert werden, sofern die Software dies zulässt. Beispielsweise können inkrementelle Backups den gesamten Speicherplatzbedarf erheblich reduzieren, da nur Informationen erfasst werden, die seit dem letzten Backup in irgendeiner Weise geändert wurden.
Testen Sie gesicherte Daten
Backups sind nicht von vornherein unanfällig, sobald sie erstellt wurden, und es besteht die Möglichkeit, dass die Informationen während des Prozesses beschädigt wurden oder verloren gingen. Durch regelmäßige Testwiederherstellungen lassen sich solche Fehler leichter erkennen und beheben, bevor es zu einer Katastrophe kommt.
Implementieren Sie eine Backup-Verschlüsselung
Eine Backup-Verschlüsselung sollte bei Bedarf für Daten während der Übertragung und im Ruhezustand implementiert werden, um ein Höchstmaß an Sicherheit zu gewährleisten. Verschlüsselung trägt dazu bei, Daten vor Datenlecks und unbefugtem Zugriff zu schützen. Es stehen zahlreiche verschiedene Verschlüsselungsalgorithmen zur Auswahl, sofern die Backup-Lösung diese unterstützt.
Erwägen Sie den Einsatz von unveränderlichem Speicher
Der Einsatz von Strategien zur Datenunveränderlichkeit kann ein wichtiger Bestandteil einer Backup-Strategie sein. Einige Backup-Lösungen bieten Software-Unveränderlichkeit, während andere spezielle Hardware-Optionen wie WORM (Write-Once-Read-Many) bereitstellen, um Informationen vor Cyber-Bedrohungen zu schützen.
Beachten Sie Aufbewahrungsrichtlinien und Versionierung
Versionierung ist der Prozess der Speicherung früherer Kopien Ihrer Daten aus Compliance- oder praktischen Gründen. Eine ordnungsgemäß konfigurierte Aufbewahrungsrichtlinie sollte festlegen, wie lange die Aufbewahrungsfrist sein soll, um ein Gleichgewicht zwischen Speicherverbrauch und der Erfüllung aller notwendigen Anforderungen zu finden.
Prüfen Sie die Funktionen für Multi-Cluster-Backups
Wenn Ihre aktuelle Umgebung mehrere Kubernetes-Cluster nutzt, kann es von entscheidender Bedeutung sein, sicherzustellen, dass Ihre Backup-Lösung eine zentralisierte Sicherung bietet. Die Fähigkeit, mehrere Umgebungen gleichzeitig zu verwalten, kann den Backup-Prozess erheblich vereinfachen und den Arbeitskomfort in einer solchen Umgebung insgesamt verbessern.
Implementieren Sie cloudnative Backup-Software
Die Kompatibilität mit dynamischen Cloud-Infrastrukturen ist ein wichtiges Merkmal jeder kompetenten Kubernetes-Backup-Lösung. Ein Grund dafür ist, dass die sich weiterentwickelnden Dienste, die Cloud-Computing bietet, einem Unternehmen zusätzliche Sicherheitsvorteile bringen können. Es kann entscheidend sein, sicherzustellen, dass die Backup-Software Ihrer Wahl cloudnativ ist und sich in verschiedene Cloud-Speicherdienste integrieren lässt.
Überdenken Sie Ihre gesamte Disaster-Recovery-Strategie
Backup-Strategien sind oft besser, wenn sie unter Berücksichtigung der Disaster Recovery konzipiert werden, und Kubernetes bildet da keine Ausnahme. Wenn Sie beispielsweise sicherstellen, dass Backups auf verschiedenen Clustern wiederhergestellt werden können, sind Situationen wie Migrationen oder ein vollständiger Clusterausfall abgedeckt. Alternativ ermöglicht die Unterstützung von cloud- und regionenübergreifenden Backups die Behebung von cloud-spezifischen Problemen oder regionalen Ausfällen.
Gewährleisten Sie die Sicherheit von Kubernetes-Secrets
Kubernetes-Secrets enthalten zahlreiche sensible Informationen, die es zu schützen gilt – Passwörter, API-Schlüssel, Zertifikate usw. Diese Art von Informationen sollte in Bezug auf die Datensicherheit höchste Priorität erhalten, mit vollständiger Verschlüsselung, Datenunveränderlichkeit und so weiter.
Versuchen Sie, die Kosten für Backup-Speicher zu optimieren
Wenn möglich, ist es in der Regel wichtig, verschiedene Speicherverwaltungstechniken zu implementieren, um die Gesamtgröße der Backups in Ihrer Speicherumgebung zu reduzieren. Komprimierung und Deduplizierung sind dabei gleichermaßen effektiv, haben jedoch beide ihre eigenen Nachteile. Dasselbe gilt auch für die meisten cloudspezifischen Strategien zur Speichereinsparung.
Überwachen Sie Backup-Prozesse regelmäßig
Es ist vielleicht unrealistisch zu erwarten, dass jemand automatisierte Backup-Prozesse rund um die Uhr im Auge behält. Daher sollten spezielle Überwachungs- und Benachrichtigungssysteme implementiert werden, um sicherzustellen, dass alles reibungslos läuft. Die meisten Lösungen bieten sogar die Möglichkeit, eine spezielle Benachrichtigung an eine bestimmte Person zu senden, falls während des Backup-Prozesses eine Unregelmäßigkeit festgestellt wird.
Implementieren Sie Backups auf Namespace-Ebene für Multi-Tenant-Cluster
Die oben genannten Multi-Tenant-Umgebungen können mithilfe von Backups auf Namespace-Ebene unterstützt werden. Auf diese Weise würden die Daten jedes Mandanten in einer separaten Backup-Datei gespeichert, was das Risiko einer Datenpreisgabe zwischen Mandanten begrenzt und gleichzeitig viel Flexibilität für die Wiederherstellungsprozesse bietet.
Stellen Sie eine Dokumentation für die gesamte Backup- und Wiederherstellungspipeline bereit
Der gesamte Backup- und Wiederherstellungsprozess sollte gut dokumentiert sein, einschließlich detaillierter Anweisungen dazu, wie ein Backup eingerichtet, überwacht, überprüft wird usw. Das Gleiche gilt für die Wiederherstellungsprozesse. Eine solche Dokumentation sollte auch die Rollen und Verantwortlichkeiten der Mitarbeiter abdecken, die für Backup-Verwaltungsaufgaben zuständig sind.
Wie sollten Sie Kubernetes-Backup-Zeitpläne und Aufbewahrungsrichtlinien gestalten?
Zu wissen, was gesichert werden muss, ist nur die halbe Miete. Die andere Hälfte besteht darin, zu entscheiden, wie oft gesichert werden soll und wie lange die gesicherten Daten aufbewahrt werden sollen. Backup-Zeitpläne und Aufbewahrungsrichtlinien, die nicht an ein konkretes Wiederherstellungsziel geknüpft sind, werden unweigerlich entweder zu aggressiv (was zu einer Verschwendung von Speicher- und Rechenressourcen führt) oder zu selten (was nach einem Ausfall zu nicht wiederherstellbaren Zeiträumen führt).
Wie häufig sollten Sie etcd, PVs und Anwendungsdaten sichern?
Es ist ein häufiger Fehler anzunehmen, dass jede Komponente mit derselben Häufigkeit gesichert werden muss. Etcd ändert sich ständig entsprechend dem Cluster-Status, daher ist ein stündlicher Snapshot in den meisten Produktionsumgebungen ausreichend. Ein sich schnell verändernder Cluster mit hoher Fluktuation bei Bereitstellungen oder Konfigurationen erfordert jedoch möglicherweise häufigere Snapshots.
Persistente Volumes, die Transaktions- oder benutzergenerierte Daten enthalten, sollten mindestens so häufig gesichert werden, wie es Ihr RPO zulässt, da sich dort die betrieblich wichtigsten Daten befinden. Backups auf Anwendungsebene können in den meisten Fällen seltener erfolgen, solange die Anwendung selbst eine gewisse Toleranz für die Wiederholung von Ereignissen oder die Rekonstruktion des Zustands aufweist. Diese Toleranz muss jedoch gründlich anhand des aktuellen RPO validiert werden, bevor sie in Ihren Zeitplan aufgenommen wird, anstatt als sichere Annahme behandelt zu werden.
Welche Aufbewahrungsfristen entsprechen den RPO- und RTO-Anforderungen?
Zwei Fragen sollten die Aufbewahrung bestimmen:
- Wie weit zurück müssen Sie wirklich wiederherstellen können?
- Wie schnell müssen Sie wiederherstellen können?
Ein niedriges RPO bedeutet nicht zwangsläufig eine lange Aufbewahrungsdauer, daher ist es selten praktikabel und oft kostspielig, stündliche Snapshots über 30 Tage hinweg aufzubewahren. Eine bessere Vorgehensweise wäre die Verwendung einer mehrstufigen Aufbewahrung: Backups mit kürzerer Dauer und hoher Häufigkeit für die operative Wiederherstellung in Kombination mit Backups mit längerer Dauer, aber geringerer Häufigkeit für Audit- oder Compliance-Zwecke. Entscheidend ist, dass die Aufbewahrungsfenster ausdrücklich von demjenigen genehmigt werden, der für das Wiederherstellungs-SLA verantwortlich ist, und nicht einseitig von dem Team festgelegt werden, das die Backups durchführt.
Wie können Lebenszyklus und Tiering die Backup-Kosten senken?
Die Kosten für Backup-Speicher bei Kubernetes-Clustern können schnell in die Höhe schnellen, insbesondere bei der Arbeit mit großen persistenten Volumes oder häufigen Snapshots. Die Implementierung einer Lebenszyklusrichtlinie hilft, die Kosten drastisch zu senken, ohne Ihre Wiederherstellungsfähigkeit zu beeinträchtigen.
Lebenszyklusrichtlinien archivieren Backups automatisch in kostengünstigere Speicherebenen, sobald sie älter werden – beispielsweise durch die Verlagerung von hochleistungsfähigem Blockspeicher in Objektspeicher nach einer bestimmten Zeit. Dies ist jedoch mit einem Kompromiss verbunden, da kostengünstigere Speicherebenen in der Regel mit längeren Wiederherstellungszeiten einhergehen.
Vor der Implementierung von Lebenszyklusrichtlinien ist es wichtig, die Abrufzeiten für jede der kostengünstigeren Ebenen zu überprüfen und zu prüfen, ob diese mit Ihrem RTO für ältere Wiederherstellungspunkte übereinstimmen. Die meisten großen Cloud-Anbieter bieten native Unterstützung für Lebenszyklusrichtlinien innerhalb ihrer Objektspeicherlösungen an, sodass die Implementierung solcher Richtlinien in den meisten Fällen kaum oder gar keine Schwierigkeiten bereiten sollte – sobald Sie Ihre Aufbewahrungsfrist festgelegt haben.
Wie sichern Sie Kubernetes-Backups und erfüllen Compliance-Anforderungen?
Die Planung von Backups ist nur ein Teil des betrieblichen Puzzles. Der eigentliche Schutz der Backups selbst und der Nachweis der Einhaltung relevanter Governance-Vorschriften sind beides separate Herausforderungen, die oft zu spät im Lebenszyklus angegangen werden. Der schiere Wert von Backup-Daten – als vollständiges Abbild der Infrastruktur – macht sie zu einem attraktiven Ziel, und es wird zunehmend Wert auf die damit verbundenen Governance-Anforderungen gelegt.
Wie sollten Backup-Daten im Ruhezustand und während der Übertragung verschlüsselt werden?
Die entscheidende architektonische Entscheidung in diesem Zusammenhang betrifft nicht wirklich die Wahl des Verschlüsselungsalgorithmus (da die meisten aktuellen Backup-Produkte eine Standardeinstellung haben, an die Sie sich ohnehin halten sollten), sondern vielmehr die Sicherstellung, dass die Verschlüsselung durchgängig angewendet wird.
Wenn die Daten im Ruhezustand verschlüsselt sind, die Übertragung zwischen dem Cluster und dem Speicherziel jedoch unverschlüsselt erfolgt, sind die Daten während der Übertragung nicht sicher. Wenn die Verschlüsselungsschlüssel in unmittelbarer Nähe zu den Backup-Daten gespeichert werden, die sie verschlüsseln, sind sie wahrscheinlich ebenfalls unsicher.
Verschlüsselungsschlüssel müssen getrennt vom Backup-Ziel gespeichert werden, sei es mithilfe eines Schlüsselverwaltungsdienstes oder eines Hardware-Sicherheitsmoduls. Der Zugriff auf diese Schlüssel sollte zudem nur von einer Stelle verwaltet werden, die über die Berechtigung zum Zugriff auf das Backup selbst verfügt.
Wer sollte Zugriff auf Backup- und Wiederherstellungsfunktionen haben?
Der Zugriff auf die Wiederherstellung wird häufig mit dem Zugriff auf das Backup gleichgesetzt, doch haben diese Funktionen völlig unterschiedliche Risikoauswirkungen. Die Möglichkeit, ein Backup möglicherweise auf einen separaten Cluster oder Namespace wiederherzustellen, entspricht der Fähigkeit, sensible Daten zu verlagern, und unterliegt daher strengeren Kontrollanforderungen als die bloße Erstellung des Backups selbst.
In der Praxis kann die Erstellung von Backups sinnvollerweise automatisiert und allgemein zugelassen werden, während Wiederherstellungsvorgänge eine ausdrückliche Genehmigung erfordern sollten – idealerweise mit einem zweiten Genehmiger für Produktionsumgebungen. Diese Unterscheidung sollte sich in Ihrer RBAC-Konfiguration widerspiegeln und klar genug dokumentiert werden, um auch bei Teamwechseln Bestand zu haben.
Welche Audit-, Protokollierungs- und Unveränderlichkeitsfunktionen sind für die Compliance erforderlich?
Neben der Sicherstellung, dass Backups vorhanden sind, verlangen Compliance-Rahmenwerke auch, dass ein Unternehmen deren Existenz nachweisen kann. Jeder Backup-Vorgang, jeder Zugriffsversuch und jede Wiederherstellungsanforderung muss gemäß den Anforderungen Ihres Rahmenwerks überprüfbar sein und aufbewahrt werden – was bedeutet, dass Protokolle so geschrieben werden müssen, dass Manipulationen erkennbar sind.
Unveränderlicher Speicher, der das Löschen oder Ändern von Backup-Daten für einen bestimmten Zeitraum verhindert, wird in Umgebungen, in denen private oder finanzielle Informationen verwaltet werden, zunehmend zur Pflicht statt zur Option – und HIPAA sowie SOC 2 erwähnen ausdrücklich dessen Notwendigkeit.
Dies bedeutet auch, dass sowohl dem Audit-Trail als auch den gesicherten Daten gleiche Bedeutung beigemessen werden muss: Daten, deren Compliance Sie nicht nachweisen können, bieten weniger Wert, wenn Auditoren anklopfen.
Methodik zur Auswahl der bestmöglichen Kubernetes-Backup-Lösung
Es gibt eine ganze Reihe verschiedener Lösungen von Drittanbietern, die auf die eine oder andere Weise Kubernetes-Backup-Funktionen bieten. Das K8s-Backup ist eine sehr wichtige Aufgabe, daher ist die Auswahl einer Backup-Lösung ebenso wichtig. Dementsprechend können wir Ihnen eine detaillierte Methodik anbieten, wie Sie die bestmögliche Kubernetes-Backup-Lösung für Ihr spezifisches Unternehmen auswählen können.
Von der Lösung abgedeckte Datentypen
Die Überprüfung, ob die Backup-Lösung die Unterstützung eines erforderlichen Datentyps bietet, hat für jedes Unternehmen oder jeden Betrieb, der nach einer Kubernetes-Backup-Lösung sucht, oberste Priorität. Daher haben wir Informationen darüber hinzugefügt, von welchen Datentypen jede einzelne Lösung aus unserer Liste ein Backup erstellen kann. Das Gesamtergebnis dieses Vergleichs wird unten in einer Tabelle dargestellt (die betreffende Tabelle ist zur besseren Übersichtlichkeit in zwei Teile unterteilt).
Tabelle Nr. 1
| Software | Kasten | Portworx | Cohesity | OpenEBS | Veritas |
| Einsätze | Ja | Ja | Ja | Ja | Ja |
| StatefulSets | Ja | Ja | Ja | Ja | Ja |
| DaemonSets | Ja | Ja | Ja | Ja | Ja |
| Pods | Ja | Ja | Ja | Ja | Ja |
| Dienstleistungen | Ja | Ja | Ja | Ja | Ja |
| Geheimnisse und/oder ConfigMaps | Ja | Ja | Ja | Ja | Ja |
| Persistent Volumes | Ja | Ja | Ja | Keine Daten | Ja |
| Namensräume | Ja | Ja | Ja | Keine Daten | Ja |
| Anwendungen | Ja (Integrationen) | Keine Daten | Ja (Messaging + Datenbanken) | Keine Daten | Keine Daten |
| Speicherinfrastruktur | Keine Daten | Keine Daten | Ja | Keine Daten | Keine Daten |
Tabelle 2
| Software | Stash | Rubrik | Druva | Zerto | Longhorn |
| Einsätze | Ja | Ja | Ja | Ja | Ja |
| StatefulSets | Ja | Ja | Ja | Ja | Ja |
| DaemonSets | Ja | Ja | Ja | Ja | Ja |
| Pods | Ja | Ja | Ja | Ja | Ja |
| Dienstleistungen | Ja | Ja | Ja | Ja | Ja |
| Geheimnisse und/oder ConfigMaps | Ja | Ja | Ja | Ja | Ja |
| Persistent Volumes | Ja | Ja | Ja | Ja | Ja |
| Namensräume | Ja | Ja | Ja | Ja | Keine Daten |
| Anwendungen | Keine Daten | Ja (Datenbanken) | Ja (Datenbanken) | Keine Daten | Keine Daten |
| Speicherinfrastruktur | Keine Daten | Ja | Keine Daten | Keine Daten | Keine Daten |
Es sollte beachtet werden, dass die Unterstützung verschiedener Datentypen ein wichtiger Faktor ist, aber in den meisten Fällen kein Ausschlusskriterium darstellt. Daher wird dringend empfohlen, dies als einen von mehreren Faktoren in diesem Vergleich zu betrachten.
Kundenbewertungen
Diese Bewertungen können auf viele verschiedene Arten interpretiert werden – wie gut die Lösung ihre Aufgabe erfüllt, wie kompetent sie mit Kundenfeedback umgeht, wie sie sich im Laufe der Zeit weiterentwickeln kann (oder nicht) und so weiter. In unserem Fall gibt es Kundenbewertungen von Drittanbieter-Websites, um die Gesamtkompetenz der Lösung mithilfe verschiedener Websites zur Erfassung von Bewertungen wie Capterra, TrustRadius und G2 zu präsentieren.
Capterra ist eine Plattform zur Aggregation von Bewertungen, die verifizierte Bewertungen, Anleitungen, Einblicke und Lösungsvergleiche bietet. Die Kunden werden gründlich darauf überprüft, ob sie tatsächlich echte Kunden der betreffenden Lösung sind, und es gibt keine Möglichkeit für Anbieter, Kundenbewertungen zu entfernen. Capterra verfügt über mehr als 2 Millionen verifizierte Bewertungen in fast tausend verschiedenen Kategorien und ist damit eine hervorragende Option, um alle Arten von Bewertungen zu einem bestimmten Produkt zu finden.
TrustRadius ist eine Bewertungsplattform, die sich der Wahrheit verschrieben hat. Sie verwendet einen mehrstufigen Prozess, um die Authentizität der Bewertungen sicherzustellen, und jede einzelne Bewertung wird vom unternehmenseigenen Forschungsteam auf ihre Ausführlichkeit, Tiefe und Gründlichkeit überprüft. Es gibt keine Möglichkeit für Anbieter, Nutzerbewertungen auf die eine oder andere Weise zu verbergen oder zu löschen.
G2 ist ein weiteres gutes Beispiel für eine Bewertungsplattform, die bis heute über 2,4 Millionen verifizierte Bewertungen mit über 100.000 verschiedenen Anbietern vorweisen kann. G2 verfügt über ein eigenes Validierungssystem für Nutzerbewertungen, das angeblich äußerst effektiv ist, um zu beweisen, dass jede einzelne Bewertung authentisch und echt ist. G2 bietet auch separate Dienstleistungen für Marketingzwecke sowie für Investitionen, Nachverfolgung und vieles mehr an.
Hauptmerkmale (sowie Vor- und Nachteile)
Zu den wichtigen Faktoren, die eine kompetente Kubernetes-Backup-Lösung aufweisen muss, gehören:
- Hohe Datenverfügbarkeit für eine bessere Notfallwiederherstellung und eine höhere Toleranz gegenüber verschiedenen Problemen mit Clustern und Containern.
- Verschiedene Sicherungstypen, einschließlich inkrementeller und anwendungsbezogener Sicherungen.
- Granularität der sicherungen mit der möglichkeit, sicherungen bestimmter objekte und nicht nur ganzer namestates (volumes, pods, PVs usw.) zu erstellen.
- Sicherungsplanung für einfachere tägliche abläufe.
- Integration mit cloud-speicheranbietern (Azure Blob, GCP, S3 usw.) für einen einfacheren sicherungsprozess und mehr vielfalt in bezug auf den sicherungsspeicher.
- Datenverschlüsselungsfunktionen für einen besseren informationsschutz.
- Unterstützung für benutzerdefinierte Workloads ermöglicht die Erweiterung der Sicherungsfunktionalität über Plugins und Integrationen.
Dies wird auch durch die Kategorie „Vorteile/Nachteile“ (falls zutreffend) dargestellt, in der sowohl die positiven als auch die negativen Aspekte der Lösung aus einer Vielzahl von Nutzerbewertungen hervorgehen.
Preisgestaltung
Die Funktionen einer Lösung sind für den Endbenutzer wichtig, aber das Thema Preis ist genauso wichtig. Einige Unternehmen haben ein sehr begrenztes Budget, andere benötigen trotz eines potenziell hohen Preises einen bestimmten Funktionsumfang. Die meisten potenziellen Kunden liegen jedoch irgendwo zwischen diesen beiden Beispielen. Es wird dringend empfohlen, sowohl den Preis als auch den Funktionsumfang der Lösung zu prüfen und gegeneinander abzuwägen. Selbst wenn die Lösung innerhalb Ihres Budgets liegt, ist sie möglicherweise nicht so gut, wenn man sie auf die einzelnen Funktionen aufteilt, wie die der Konkurrenz.
Eine persönliche Meinung des Autors
Der einzige völlig subjektive Teil dieser Methodik ist die Meinung des Autors zu diesem Thema (in unserem Fall die Backup-Lösung von Kubernetes). Es gibt viele verschiedene Anwendungsfälle für diese spezielle Kategorie, einschließlich interessanter Informationen über die Lösung, die in keine der vorherigen Kategorien passte, oder einfach nur die persönliche Meinung des Autors zu diesem speziellen Thema.
Markt für Kubernetes-Sicherungslösungen
Betrachten wir vor dem Hintergrund dieser drei wichtigen Faktoren bzw. Merkmale einige weitere Beispiele für eine K8s-Lösung zur Datensicherung und -wiederherstellung.
Kasten K10

Kasten K10 (kürzlich von Veeam übernommen) ist eine Sicherungs- und Wiederherstellungslösung, die auch auf ihre Mobilitäts- und Disaster-Recovery-Systeme stolz ist. Der Sicherungsprozess mit Kasten wird durch die Fähigkeit, Anwendungen automatisch zu erkennen, sowie durch viele andere Funktionen wie Datenverschlüsselung, rollenbasierte Zugriffskontrolle und eine benutzerfreundliche Oberfläche vereinfacht. Gleichzeitig kann es mit vielen verschiedenen Datendiensten wie MySQL, PostgreSQL, MongoDB, Cassandra, AWS usw. zusammenarbeiten.
Eine lokale Hochverfügbarkeit ist damit nicht möglich, da Kasten die Replikation innerhalb eines einzelnen Clusters nicht direkt unterstützt und stattdessen auf die zugrunde liegenden Datenspeichersysteme angewiesen ist. Auch die Notfallwiederherstellung ist nur teilweise „gegeben“, da Kasten aufgrund des Fehlens einer Datenpfadkomponente keine RPO-Fälle von null erreichen kann. Bemerkenswert ist auch die Tatsache, dass die Sicherungen von Kasten nur asynchron sind, was in der Regel eine zusätzliche Ausfallzeit zwischen den Vorgängen bedeutet.
Datentypen, die von Kasten K10 abgedeckt werden:
Kasten K10 kann Sicherungen von – in der Regel – allen Daten erstellen, die Kubernetes generiert, einschließlich Services, Deployments, PVs, Namespaces usw. Es gibt hier nur zwei Ausnahmen: Die Anwendungsabdeckung von Kasten kann auch durch die Integration mit anderen Sicherungs- und Wiederherstellungslösungen erweitert und verbessert werden.
Kundenbewertungen:
- (Kasten) G2 – 4,7/5 Sternen basierend auf 10 Kundenbewertungen
- (Veeam) Capterra – 4,8/5 Sternen basierend auf 69 Kundenbewertungen
- (Veeam) TrustRadius – 8,8/10 Sternen basierend auf 1.237 Kundenbewertungen
- (Veeam) G2 – 4,6/5 Sternen basierend auf 387 Kundenbewertungen
Hauptmerkmale:
- Beeindruckende Skalierbarkeit und Effizienz
- Hochwirksamer Schutz vor Ransomware
- Erstellt unter Verwendung von Cloud-nativen Architekturprinzipien
Preise (zum Zeitpunkt der Erstellung):
- Auf der Preisseite von Kasten K10 wird behauptet, dass es drei Editionen der Software gibt (obwohl es nur eine tatsächliche Edition gibt und die anderen beiden die kostenlose Version bzw. die Testversion sind).
- „Free“ ist eine sehr eingeschränkte Version von Kasten K10 mit einem Minimum an Kubernetes-Sicherungsfunktionen, einschließlich maximal 5 Knoten, sowie Sicherungs-/Wiederherstellungsvorgängen, Notfallwiederherstellung, Ransomware-Schutz und den meisten anderen Funktionen von Kasten
- „Enterprise Trial“ ist Kastens Version einer zeitlich begrenzten kostenlosen Testversion, die den vollständigen Funktionsumfang von Kasten, eine Obergrenze von 50 Knoten sowie Kundensupport, eine von Kasten unterstützte Bereitstellung und eine Datenschutzbewertung bietet.
- „Enterprise“ ist die einzige tatsächliche Abonnementstufe, die Kasten K10 anbietet. Sie hebt die Beschränkung der „Anzahl der Knoten“ vollständig auf und bietet den vollständigen Satz an Sicherungs- und Wiederherstellungsfunktionen von Kasten.
- Es ist erwähnenswert, dass auf der offiziellen Kasten-Website keine Preisinformationen verfügbar sind, was bedeutet, dass die einzige Möglichkeit, solche Informationen zu erhalten, darin besteht, ein individuelles Angebot von dem betreffenden Unternehmen anzufordern.
Meine persönliche Meinung zu Kasten K10:
Kasten K10 ist eine recht leistungsfähige Backup-Lösung, die mit einer Vielzahl unterschiedlicher Umgebungen kompatibel ist – darunter Kubernetes, Cassandra, PostgreSQL, MySQL und weitere. Vor kurzem wurde das Unternehmen von Veeam übernommen – einem der bekanntesten Anbieter von Backup-Lösungen für Unternehmen auf dem Markt. Kasten konnte seinen Namen bislang beibehalten und präsentiert sich in den meisten Fällen als „Kasten by Veeam“. An sich ist es keine schlechte Lösung, doch sind seine Kubernetes-bezogenen Funktionen eher grundlegend und begrenzt. Es überträgt die meisten seiner allgemeinen Funktionen auf Kubernetes-Backups, wie beispielsweise Datenverschlüsselung und RBAC, doch die Erstellung dieser Backups ist kein einfacher Vorgang. Kasten bietet keine lokale Hochverfügbarkeit für Kubernetes, seine Disaster-Recovery-Implementierung ist nur teilweise vorhanden (RPOs ungleich Null) und alle Backups sind streng asynchron.
Portworx

Portworx PX-Backup ist ein Datenverwaltungsunternehmen, das eine Cloud-basierte Speicherplattform entwickelt, um die Datenbank für Kubernetes-Projekte zu verwalten und darauf zuzugreifen. Es ist ein weiteres Beispiel für eine Datenverwaltungslösung, und trotz ihrer Einschränkungen als solche ist einer der Hauptvorteile der Verwendung von Portworx die hohe Verfügbarkeit von Daten.
Zu den Funktionen gehören unter anderem Sicherungs- und Wiederherstellungsvorgänge, das Verständnis von Kubernetes-Apps, lokale Hochverfügbarkeit und Notfallwiederherstellung. All dies macht Portworx zu einer guten Lösung für die Sicherung von Kubernetes. Wenn man bedenkt, wie unterschiedlich die Kubernetes-Sicherungslösungen von Drittanbietern sind, könnte Portworx auch für Benutzer interessant sein, die speziell nach Kubernetes-Sicherungsfunktionen suchen.
Ein weiterer wichtiger Bestandteil von PX-Backup ist seine Skalierbarkeit, die On-Demand-Sicherungen/geplante Sicherungen von Hunderten von Anwendungen auf einmal ermöglicht. Die Lösung unterstützt auch Multi-Datenbank-Setups und kann Anwendungen direkt in den Cloud-Diensten wie Amazon, Google, Microsoft usw. wiederherstellen.
Datentypen, die von Portworx abgedeckt werden:
Portworx unterstützt die Erstellung von Sicherungen für Namespaces, PVs, DaemonSets, Deployments und mehr. T-I konnte jedoch keine Informationen darüber finden, ob es die Sicherung von Anwendungen oder die Sicherung der Speicherinfrastruktur unterstützt oder nicht.
Kundenbewertungen:
- G2 – 4,4/5 Sternen basierend auf 16 Kundenbewertungen
Vorteile:
- Leistungsstarke und zuverlässige sicherung
- Skalierbare und zuverlässige Infrastruktur
- Datenverschlüsselung und detaillierte Zugriffskontrolle
Mängel:
- Die Software-Konfiguration kann insgesamt etwas kompliziert sein
- Die Erfahrung mit dem Kundensupport ist uneinheitlich
- Die Sicherheitsfunktionen sind im Zusammenhang mit der Bereitstellung in großen Unternehmen begrenzt
Preise (zum Zeitpunkt der Erstellung dieses Artikels):
- Das Preismodell von Portworx ist recht einfach: Es gibt eine kostenlose Version für alle Benutzer, die ein Portworx-Konto erstellen. Diese Version ist auf 1 Cluster und bis zu 1 TB Anwendungsdaten beschränkt
- Es gibt auch eine kostenpflichtige Version der Software mit vollem Funktionsumfang, einschließlich anwendungsbezogener Sicherungen, Wiederherstellung mit einem Klick, Ransomware-Schutz usw. Leider sind auf der Portworx-Website keine offiziellen Preise verfügbar; diese können nur direkt beim Unternehmen angefordert werden, um ein individuelles Angebot zu erhalten.
Meine persönliche Meinung zu Portworx:
Portworx bewirbt sich selbst als eine Daten-Service-Plattform, die viele Funktionen bietet, die sich hauptsächlich um Kubernetes und seine Container drehen. Die Portworx-Plattform kann zahlreiche Dienste anbieten, darunter Sicherung, Notfallwiederherstellung, Speicherung, DevOps und Datenbank. Portworx-Sicherungen bieten hohe Verfügbarkeit, Anwendungsbewusstsein und viele Funktionen, die in Kubernetes-Sicherungsangeboten normalerweise nicht verfügbar sind. Es handelt sich um eine schnelle und skalierbare Lösung, die jedoch auch ihre Nachteile hat. Ein Beispiel für einen solchen Nachteil ist die insgesamt eher begrenzte Präsenz auf dem Markt, was zu einer Reihe von unangenehmen Faktoren führt, wie z. B. das Fehlen detaillierter Tutorials im Internet. Die betreffende Lösung kann auch recht kompliziert sein, was die Arbeit für Neueinsteiger in diesem Bereich erschwert.
Cohesity

Cohesity ist ein relativ beliebter Konkurrent im Bereich der allgemeinen Sicherung und Wiederherstellung, aber seine Kubernetes-bezogenen Fähigkeiten haben noch etwas Spielraum nach oben. Zunächst einmal ist Kubernetes für sie eine relativ neue Ergänzung, da sie nun über das Verständnis für Kubernetes-Apps verfügen. Es funktioniert jedoch nur für alle Anwendungen innerhalb desselben Namespace, und Sie können keine spezifischen Apps innerhalb dieses einen Namespace schützen.
Andererseits gibt es auch Funktionen für eine schnelle Wiederherstellung, inkrementelle Sicherungen auf Anwendungsebene auf Richtlinienbasis, Konsolidierung des Datenstatus und viele andere Funktionen.
Datentypen, die von Cohesity abgedeckt werden:
Die Lösung von Cohesity unterstützt Namespace-Sicherungen, Service-Sicherungen, Bereitstellungssicherungen und vieles mehr. Es gibt Unterstützung für die Sicherung der Speicherinfrastruktur, und der einzige bemerkenswerte Faktor für diese Kategorie ist, dass die Anwendungssicherung von Cohesity auch Datenbanken abdecken kann, in denen die Anwendungen arbeiten, sowie Messaging-Systeme, die in Kubernetes eingesetzt werden.
Kundenbewertungen:
- Capterra – 4,6/5 Sternen basierend auf 48 Kundenbewertungen
- TrustRadius – 8,9/10 Sternen basierend auf 59 Kundenbewertungen
- G2 – 4,4/5 Sternen basierend auf 45 Kundenbewertungen
Vorteile:
- Einfache und bequeme Verwaltung von Sicherungen und Wiederherstellungen
- Mühelose und einfache Ersteinrichtung und Konfiguration
- Einfache Planung mithilfe der Profilerstellung ermöglicht mehr Automatisierung
- App-fähige inkrementelle Sicherungen, schnelle Wiederherstellungsfunktionen für Kubernetes-Apps und mehr
Mängel:
- Einige der Updates müssen manuell über eine Befehlszeile installiert werden, was im krassen Gegensatz zur üblichen GUI-basierten automatischen Update-Installation steht
- Die „unveränderlichen Sicherungen“ von Cohesity können von einem Benutzer mit Administratorrechten weiterhin geändert oder gelöscht werden
- Der Kundensupport stützt sich stark auf Standardantworten und kann weniger hilfreich sein
- Die Kubernetes-Funktion zur Sicherung ist für Cohesity relativ neu und kann noch etwas unausgereift sein
Preise (zum Zeitpunkt der Erstellung dieses Artikels):
- Die Preisinformationen von Cohesity sind auf der offiziellen Website nicht öffentlich zugänglich. Die einzige Möglichkeit, an solche Informationen zu gelangen, besteht darin, das Unternehmen direkt zu kontaktieren, um eine kostenlose Testversion oder eine geführte Demo zu erhalten.
- Die inoffiziellen Informationen über die Preisgestaltung von Cohesity besagen, dass allein die Hardware-Geräte einen Einstiegspreis von 110.000 USD haben
Meine persönliche Meinung zu Cohesity:
Cohesity ist eine solide Sicherungs- und Wiederherstellungslösung, die eine Reihe verschiedener Speichertypen unterstützt und gleichzeitig viele Funktionen für die Arbeit bietet. Die gesamte Lösung basiert auf einer ungewöhnlichen knotenartigen Struktur, die eine äußerst einfache Skalierung von Cohesity in beide Richtungen ermöglicht. Es ist schnell, vielseitig und eine großartige Option für die Erstellung von Sicherungen von Anwendungsinfrastrukturen. Was speziell die Kubernetes-bezogenen Funktionen betrifft, so könnten sie in Zukunft definitiv noch verbessert werden, da die Kubernetes-Unterstützung eine relativ neue Ergänzung zu Cohesity ist und einige Nuancen noch regelmäßig ausgebügelt werden. Es kann nur Anwendungsdaten aus demselben Namespace schützen, und es gibt auch keine Option, bestimmte Anwendungen zu schützen – nur den gesamten Namespace. Gleichzeitig kann Cohesity eine ganze Reihe eigener Funktionen anbieten, die jetzt für Kubernetes-Sicherungen anwendbar sind, darunter die Konsolidierung des Datenstatus, die Unterstützung inkrementeller Sicherungen und vieles mehr.
OpenEBS

OpenEBS ist ein weiteres Beispiel für eine Lösung, die mit nur einer der drei Funktionen aus unserer Liste einige Ergebnisse erzielt hat, und in diesem Fall dreht sich alles um lokale Hochverfügbarkeit.
Gleichzeitig lässt sich OpenEBS auch mit Velero integrieren, wodurch eine kombinierte Kubernetes-Lösung entsteht, die sich bei der Kubernetes-Datenmigration besonders auszeichnet. OpenEBS allein kann lediglich einzelne Anwendungen sichern (das genaue Gegenteil von dem, was Cohesity leistet). Hinzu kommen Funktionen wie Multi-Cloud-Speicher, der Open-Source-Charakter sowie eine umfangreiche Liste unterstützter Kubernetes-Plattformen, von AWS und Digital Ocean bis hin zu Minikube, Packet, Vagrant, GCP und weiteren.
Dies deckt jedoch möglicherweise nicht die Bedürfnisse eines Benutzers ab, da einige Benutzer diese Namespace-Sicherungen in bestimmten Anwendungsfällen benötigen könnten.
Datentypen, die von OpenEBS abgedeckt werden:
OpenEBS ist eine recht vielseitige Lösung; sie kann Sicherungen ganzer Bereitstellungen sowie von Pods, ConfigMaps, StatefulSets usw. erstellen. Im Vergleich zu anderen Lösungen ist sie jedoch eher eingeschränkt, u. a. aufgrund des Fehlens einer Sicherung der Speicherinfrastruktur, einer Anwendungssicherung und von Sicherungen auf Namespace- und PV-Ebene.
Hauptmerkmale:
- Verwendet Container Attached Storage-Muster für eine bessere Effizienz der Sicherung
- Ermöglicht zustandsbehafteten Anwendungen einen schnellen und einfachen Zugriff auf replizierte PVs und dynamische lokale PVs
- Vereinfacht die cloudübergreifende Anwendungsverwaltung, einschließlich Speicherreplikation und automatisierter Bereitstellung
Preise (zum Zeitpunkt der Erstellung):
- OpenEBS ist eine kostenlose Open-Source-Lösung, aber es gibt auch Einzelpersonen und Unternehmen von Drittanbietern, die in irgendeiner Form Dienstleistungen oder Produkte im Zusammenhang mit OpenEBS anbieten können.
Meine persönliche Meinung zu OpenEBS:
OpenEBS steht hier in starkem Kontrast zu Cohesity – es handelt sich um eine relativ kleine Datenmanagement-Lösung, die sich speziell auf Kubernetes-Umgebungen konzentriert und gleichzeitig den Schwerpunkt auf lokale hohe Datenverfügbarkeit als Hauptmerkmal legt. Die betreffende Software lässt sich problemlos mit Velero integrieren – einer weiteren kleinen, kostenlosen Open-Source-Software, die in Bezug auf Kubernetes-Backups weitaus mehr zu bieten hat. Diese Art der Integration schafft ein ziemlich leistungsstarkes (und kostenloses) Backup- und Datenmanagement-Angebot, das völlig kostenlos ist, mit einer Vielzahl von Kubernetes-Plattformen funktioniert, Multi-Cloud-Speicherunterstützung bietet, Datenmigrationsfunktionen bereitstellt und so weiter. Wie bei praktisch jeder kostenlosen Lösung dieser Größenordnung ist das größte Problem von OpenEBS (und Velero) eine recht steile Lernkurve, die den Einstieg zunächst erschwert und den Zeitaufwand für die Beherrschung aller Funktionen der Lösung drastisch erhöht.
Veritas

Veritas ist ein etablierter Anbieter von Sicherungssoftware, der seit mehreren Jahrzehnten auf dem Markt ist. Aus genau diesem Grund wird er von älteren und größeren Unternehmen bevorzugt. Er bietet zahlreiche verschiedene Funktionen und Fähigkeiten und unterstützt gleichzeitig eine Vielzahl von Zielspeichertypen, die von physischen Speichern bis hin zu VMs, Datenbanken, Cloud-Speichern und mehr reichen. Was die Kubernetes-Funktionen betrifft, so bietet Veritas umfangreiche Protokollierungsfunktionen, eine einfache, aber effektive Verwaltung, RBAC-Unterstützung, hohe Datenverfügbarkeit, Datenreplikation und vieles mehr. Es ist eine großartige Option für Sicherungs- und Wiederherstellungsaufgaben insgesamt, da es Datenschutz und Funktionsreichtum in einem einzigen Paket vereint.
Datentypen, die von Veritas abgedeckt werden:
Die Fähigkeiten von Veritas im Bereich der Kubernetes-Sicherungen sind ziemlich beeindruckend, einschließlich der Abdeckung von Namespaces, Deployments, Secrets, Pods und so weiter. Allerdings ist es nicht in der Lage, Anwendungssicherungen durchzuführen, und dasselbe gilt für Sicherungen der Speicherinfrastruktur.
Kundenbewertungen:
- Capterra – 4.0/5 Sterne basierend auf 7 Kundenbewertungen
- TrustRadius – 6,8/10 Sternen basierend auf 150 Kundenbewertungen
- G2 – 4,1/5 Sternen basierend auf 230 Kundenbewertungen
Vorteile:
- Ein äußerst umfangreicher und vielfältiger Funktionsumfang, der oft als eines der umfangreichsten Funktionspakete auf dem Markt angesehen wird.
- Ein relativ veralteter visueller Zustand der Benutzeroberfläche ändert nichts an der Tatsache, dass sie für alle Arten von Kunden, einschließlich völliger Neulinge auf diesem Gebiet, einfach zu bedienen ist.
- Die Erfahrung des Kundensupports hat im Laufe der Jahre viele positive Bewertungen erhalten, wobei das Support-Team schnelle und präzise Antworten auf eine Vielzahl von Fragen liefert.
Mängel:
- Das Berichtsverwaltungssystem ist etwas starr, es gibt keine Möglichkeit, den Zieldateipfad für automatisch erstellte Berichte anzupassen.
- Die Integration der LTO-Bandbibliothek ist in gewissem Umfang möglich, weist jedoch bisher eine Reihe schwerwiegender Mängel auf.
- Der Export von Berichten ist insgesamt eher schwierig.
Preise (zum Zeitpunkt der Erstellung dieses Artikels):
- Auf der Website von Veritas sind keine offiziellen Preisinformationen zu finden. Die einzige Möglichkeit, solche Informationen zu erhalten, besteht darin, das Unternehmen direkt zu kontaktieren.
Meine persönliche Meinung zu Veritas:
Veritas wird oft als eine der älteren Sicherungs- und Wiederherstellungslösungen auf dem Markt gelobt, die immer noch in Form ist und mit anderen führenden Lösungen konkurriert. Das soll nicht heißen, dass das Alter der einzige Vorteil ist, den Veritas bieten kann – es hat auch einen extrem breiten Funktionsumfang, eine beeindruckend benutzerfreundliche Oberfläche und ein äußerst hilfreiches Kundensupport-Team. Veritas schafft es auch, verschiedene Aspekte der Verwaltung von Kubernetes-Containern erheblich zu vereinfachen und zu verbessern – einschließlich Sicherungs- und Wiederherstellungsfunktionen für Containerdaten, automatischem Failover und Failback, Verkehrsverteilung über Instanzen hinweg, automatischer Namespace-Erkennung und mehr. Veritas bietet einfache und leicht zugängliche Sicherungs- und Wiederherstellungsvorgänge für containerisierte Anwendungen und ist damit eine recht bequeme Kubernetes-Sicherungslösung. Veritas hat zwar einige Probleme mit seinem Berichtssystem insgesamt und die Integration von LTO-Bändern ist eher problematisch, aber keines dieser Probleme beeinträchtigt die Kubernetes-bezogenen Funktionen so sehr, dass es für bestehende und zukünftige Benutzer ein echtes Problem darstellen würde. Insgesamt kann der Preis ein Hindernis darstellen.
Stash

Stash ist eine Lösung für die sicherung und katastrophenwiederherstellung, die in erster Linie speziell für Kubernetes entwickelt wurde. Sie kann Kubernetes-Daten auf verschiedenen Ebenen wiederherstellen, darunter Datenbanken (MongoDB, MySQL, PostgreSQL), Volumes (Stateful Sets, Bereitstellungen, Standalone-Volumes) und sogar reguläre Kubernetes-Ressourcen (Geheimnisse, YAML-Konfigurationen usw.). Es unterstützt eine Reihe von Automatisierungsoptionen, kann in mehrere Cloud-Speicheranbieter integriert werden, unterstützt benutzerdefinierte Arbeitslasten und vieles mehr. Es handelt sich auch um eine relativ neue Lösung in diesem Bereich, sodass es hier und da noch einige Anlaufschwierigkeiten gibt.
Datentypen, die von Stash abgedeckt werden:
Stash ist eine relativ kleine Sicherungslösung, aber die Kubernetes-Abdeckung ist dennoch recht beeindruckend – mit Unterstützung für Bereitstellungen, Dienste, Pods, DaemonSets und sogar Sicherungen der Speicherinfrastruktur. Es können jedoch keine Kopien von Kubernetes auf Namespace-Ebene erstellt werden, und es gibt auch keine Unterstützung für Anwendungssicherungen.
Hauptmerkmale:
- Durch die Unterstützung der CSI VolumeSnapshotter-Funktionalität können die Kubernetes-Sicherungsoptionen von Stash erheblich erweitert werden.
- Die Möglichkeit der Integration in das Restic-Tool bringt Funktionen wie Deduplizierung, Verschlüsselung, inkrementelle Sicherungen und vieles mehr mit sich.
- Stash kann mit einer Reihe von Cloud-Speicheranbietern als Sicherungsspeicher zusammenarbeiten – Azure Blob, GCP, AWS S3 usw.
- Es gibt zahlreiche Planungsoptionen, die alle auf verschiedene Weise angepasst werden können.
Preise (zum Zeitpunkt der Erstellung dieses Artikels):
- Auf der Stash-Website sind keine offiziellen Preisinformationen verfügbar, aber es gibt eine „Kontakt“-Aufforderung, was bedeutet, dass alle Preisinformationen stark personalisiert sind und nicht über öffentliche Mittel abgerufen werden können.
Meine persönliche Meinung zu Stash:
Stash ist vielleicht die am wenigsten bekannte Sicherungslösung auf dieser Liste. Es handelt sich um eine sehr kleine Sicherungs- und Notfallwiederherstellungslösung speziell für Kubernetes und nichts anderes. Stash kann mit Kubernetes-Ressourcen, -Volumes und sogar -Datenbanken arbeiten und bietet die Möglichkeit, Sicherungen zahlreicher Umgebungen und Datentypen zu erstellen – von MongoDB und PostgreSQL bis hin zu YAML-Konfigurationen von Bereitstellungen. Es handelt sich um eine schnelle Lösung mit zahlreichen Kubernetes-zentrierten Funktionen, die bei anderen Sicherungslösungen selten sind. So unterstützt Stash beispielsweise die CSI VolumeSnapshotter-Funktionalität und kann auch in das Restic-Tool integriert werden, um bessere und vielseitigere Datenschutzmaßnahmen zu ermöglichen. Es befindet sich noch in der Entwicklung, aber es ist vielversprechend für die Zukunft, und die Gesamtkomplexität der Lösung ist derzeit wahrscheinlich das größte Problem – ein Problem, das mit Zeit und Mühe behoben werden kann.
Rubrik

Viele andere, größere Akteure im Bereich Backup und Wiederherstellung bieten inzwischen ihre eigenen Dienste für die Sicherung und Wiederherstellung von Kubernetes an – Rubrik ist ein gutes Beispiel: Es ermöglicht Benutzern, Rubriks umfangreiche Verwaltungsfunktionen im Bereich der Kubernetes-Bereitstellungen zu implementieren.
Es ermöglicht Flexibilität in Bezug auf das Wiederherstellungsziel sowie den Schutz von Kubernetes-Objekten und eine einheitliche Plattform, die Einblicke und einen Überblick über das gesamte System bietet. Es gibt auch Funktionen wie die Automatisierung von Sicherungen, granulare Wiederherstellung, Snapshot-Replikation und vieles mehr. Rubrik kann auch mit persistenten Volumes arbeiten und ist in der Lage, Namespaces zu replizieren – so haben Sie vor der Bereitstellung verschiedene Möglichkeiten für Entwicklung und Tests.
Datentypen, die von Rubrik abgedeckt werden:
Rubrik ist eine der besten Optionen auf dieser Liste, wenn es um alle Arten von Kubernetes-Datentypen geht, von denen eine Sicherung erstellt werden kann. Dazu gehören Bereitstellungen, Namespaces, Speicherinfrastruktur, Dienste, Pods, StatefulSets und praktisch alles andere. Der einzige erwähnenswerte Faktor ist, dass Druva sowohl Anwendungen als auch Datenbanken abdecken kann, von denen sie verwendet werden.
Kundenbewertungen:
- Capterra – 4,7/5 Sternen basierend auf 45 Kundenbewertungen
- TrustRadius – 9,1/10 Sternen basierend auf 198 Kundenbewertungen
- G2 – 4,6/5 Sternen basierend auf 59 Kundenbewertungen
Vorteile:
- Eine vielseitige Sicherungs- und Wiederherstellungslösung mit hoher Leistung
- Eine Vielzahl von Integrationen mit anderen Diensten und Technologien, wie SQL Server, VMware, M365 usw.
- Zuverlässige Datenschutzfunktionen mit guter Verschlüsselung, starker Sicherheit und Ransomware
- Unterstützt zahlreiche Funktionen für Kubernetes-Anwendungen, einschließlich Snapshot-Replikation, Sicherungsautomatisierung, granulare Wiederherstellung und viele andere
Mängel:
- Die RBAC-Implementierung ist eher einfach und es fehlen viele der erforderlichen Funktionen, die die Konkurrenz bietet
- Sehr begrenzte Anpassungsmöglichkeiten bei Audits/Berichten und im Allgemeinen nicht genügend Details in Berichten
- Die Gesamtkosten der Lösung könnten für kleinere oder mittelgroße Unternehmen und Betriebe zu hoch sein
- Begrenzte Skalierbarkeit
Preise (zum Zeitpunkt der Erstellung dieses Artikels):
- Rubriks Preisinformationen sind auf der offiziellen Website nicht öffentlich verfügbar. Die einzige Möglichkeit, an solche Informationen zu gelangen, besteht darin, das Unternehmen direkt zu kontaktieren, um eine personalisierte Demo oder eine der geführten Touren zu erhalten.
- Die inoffiziellen Informationen besagen, dass Rubrik mehrere verschiedene Hardware-Geräte anbietet, wie z. B.:
- Rubrik R334 Node – ab 100.000 $ für einen 3-Node mit 8-Core Intel-Prozessoren, 36 TB Speicher usw.
- Rubrik R344 Node – ab 200.000 $ für einen 4-Node mit ähnlichen Parametern wie R334, 48 TB Speicher usw.
- Rubrik R500 Series Node – ab 115.000 $ für einen 4-Node mit Intel 8-Core-Prozessoren, 8×16 DIMM-Speicher usw.
Meine persönliche Meinung zu Rubrik:
Rubrik verfügt zwar nicht über besonders umfangreiche Kubernetes-Funktionen, aber die Lösung selbst ist in der Branche bekannt und angesehen und bietet eine ausgeklügelte Sicherungs- und Wiederherstellungsplattform mit einer Vielzahl von Funktionen. Rubrik kann Schutz, Datenmigration und allgemeinen Support für Kubernetes-Instanzen bieten, hauptsächlich durch die Erweiterung seiner eigenen vorhandenen Funktionen auf Kubernetes-Umgebungen. Rubrik kann Namespaces replizieren und mit Persistent Volumes arbeiten, was es zu einem interessanten Angebot für größere Unternehmen macht. Es sollte jedoch erwähnt werden, dass Rubrik auch einige Nachteile hat, die noch behoben werden müssen, darunter eine eher grundlegende Skalierbarkeit, ein starres Berichts-/Auditsystem und ein insgesamt recht hoher Preis.
Druva

Eine weitere Variante einer solchen Lösung wird von Druva vorgestellt, die eine recht einfache, aber effektive Kubernetes-Lösung für Sicherung und Wiederherstellung mit allen erwarteten Grundfunktionen bietet – Snapshots, Sicherung und Wiederherstellung, Automatisierung und einige zusätzliche Funktionalitäten. Druva kann auch ganze Anwendungen innerhalb von Kubernetes wiederherstellen, wobei das Wiederherstellungsziel sehr flexibel ist.
Darüber hinaus unterstützt Druva mehrere Administratorrollen, kann Kopien von Workloads zu Fehlerbehebungszwecken erstellen und bestimmte Bereiche wie Namespaces oder App-Gruppen sichern. Es gibt auch eine Vielzahl von Aufbewahrungsoptionen, umfassenden Kubernetes-Datenschutz und Unterstützung für Amazon EC2 und EKS (benutzerdefinierte Container-Workloads).
Von Druva abgedeckte Datentypen:
Es gibt keine Informationen darüber, ob Druva Kubernetes Storage Infrastructure sicherungen unterstützt. Abgesehen davon unterstützt es praktisch alles andere – Namespaces, Pods, DaemonSets, StatefulSets, ConfigMaps und sogar Persistent Volumes. Es kann auch Anwendungen und Datenbanken abdecken, die mit diesen Anwendungen verbunden sind.
Kundenbewertungen:
- Capterra – 4,7/5 Sternen basierend auf 17 Kundenbewertungen
- TrustRadius – 9,3/10 Sternen basierend auf 419 Kundenbewertungen
- G2 – 4,6/5 Sternen basierend auf 416 Kundenbewertungen
Vorteile:
- Die grafische Benutzeroberfläche wird insgesamt sehr gelobt.
- Die Unveränderlichkeit von Sicherungen und die Datenverschlüsselung sind nur Beispiele dafür, wie ernst Druva die Datensicherheit nimmt.
- Der Kundensupport ist schnell und hilfreich.
- Datenschutz, Snapshots, automatische Sicherungen und andere Funktionen für Kubernetes-Apps.
Mängel:
- Die Ersteinrichtung ist nicht einfach selbst durchzuführen.
- Windows-Snapshots und SQL-Cluster-Sicherungen sind simpel und kaum anpassbar.
- Langsame Wiederherstellungsgeschwindigkeit aus der Cloud.
- Die Skalierbarkeit kann eingeschränkt sein.
Preise (zum Zeitpunkt der Erstellung):
- Die Preisgestaltung von Druva ist recht komplex und bietet je nach Art des abgedeckten Geräts oder der abgedeckten Anwendung unterschiedliche Preispläne.
- Hybride Arbeitslasten:
- „Hybrid business“ – 210 $ pro Monat und Terabyte an Daten nach Deduplizierung, bietet eine einfache geschäftliche Sicherung mit zahlreichen Funktionen wie globale Deduplizierung, Wiederherstellung auf VM-Dateiebene, NAS-Speicherunterstützung usw.
- „Hybrid Enterprise“ – 240 $ pro Monat und Terabyte an Daten nach Deduplizierung, eine Erweiterung des vorherigen Angebots mit LTR-Funktionen (Langzeitaufbewahrung), Speicherinformationen/-empfehlungen, Cloud-Cache usw.
- „Hybrid Elite“ – 300 $ pro Monat und Terabyte an Daten nach Deduplizierung, ergänzt das vorherige Paket um Cloud-Disaster-Recovery und schafft so die ultimative Lösung für Datenmanagement und Disaster Recovery
- Es gibt auch Funktionen, die Druva separat verkauft, wie z. B. beschleunigte Ransomware-Wiederherstellung, Cloud-Notfallwiederherstellung (verfügbar für Hybrid-Elite-Benutzer), Sicherheitslage & Beobachtbarkeit und Bereitstellung für die Cloud der US-Regierung
- SaaS-Anwendungen:
- „Business“ – 2,50 USD pro Monat und Benutzer, das grundlegendste Paket der SaaS-Anwendungsabdeckung (Microsoft 365 und Google Workspace, der Preis wird pro einzelner Anwendung berechnet), kann 5 Speicherregionen, 10 GB Speicherplatz pro Benutzer sowie grundlegenden Datenschutz bieten
- „Enterprise“ – 4 $ pro Monat und Benutzer für die Abdeckung von entweder Microsoft 365 oder Google Workspace mit Funktionen wie Gruppen und öffentlichen Ordnern sowie Salesforce.com-Abdeckung für 3,50 $ pro Monat und Benutzer (einschließlich Metadatenwiederherstellung, automatisierte Sicherungen, Vergleichstools usw.)
- „Elite“ – 7 $ pro Monat und Benutzer für Microsoft 365/Google Workspace, 5,25 $ für Salesforce, einschließlich DSGVO-Konformitätsprüfung, eDiscovery-Aktivierung, föderierte Suche, GCC-High-Support und viele weitere Funktionen
- Einige der hier aufgeführten Funktionen können auch separat erworben werden, z. B. Sandbox-Seeding (Salesforce), Governance sensibler Daten (Google Workspace & Microsoft 365), GovCloud-Support (Microsoft 365) usw.
- Endpunkte:
- „Enterprise“ – 8 $ pro Monat und Benutzer, kann SSO-Unterstützung, CloudCache, DLP-Unterstützung, Datenschutz pro Datenquelle und 50 GB Speicherplatz pro Benutzer mit delegierter Verwaltung bieten.
- „Elite“ – 10 $ pro Monat und Benutzer, bietet zusätzliche Funktionen wie föderierte Suche, zusätzliche Datenerfassung, rechtfertigbare Löschung, erweiterte Bereitstellungsfunktionen und vieles mehr.
- Es gibt auch zahlreiche Funktionen, die hier separat erworben werden können, darunter erweiterte Bereitstellungsfunktionen (verfügbar in der Elite-Abonnementstufe), Ransomware-Wiederherstellung/Reaktion, Governance sensibler Daten und GovCloud-Support.
- AWS-Arbeitslasten:
- „Freemium“ ist ein kostenloses Angebot von Druva für die Abdeckung von AWS-Arbeitslasten; es kann bis zu 20 AWS-Ressourcen auf einmal abdecken (nicht mehr als 2 Konten) und bietet gleichzeitig Funktionen wie VPC-Klonen, regions- und kontenübergreifende DR, Wiederherstellung auf Dateiebene, Integration von AWS-Organisationen, API-Zugriff usw.
- „Enterprise“ – 7 $ pro Monat und Ressource, ab 20 Ressourcen, mit einer Obergrenze von 25 Konten und erweitert die Funktionen der vorherigen Version um Funktionen wie Datensperre, Suche auf Dateiebene, die Möglichkeit, vorhandene Sicherungen zu importieren, die Möglichkeit, manuelles Löschen zu verhindern, 24/7-Support mit einer Reaktionszeit von höchstens 4 Stunden usw.
- „Elite“ – 9 $ pro Monat und Ressource, ohne Einschränkungen bei verwalteten Ressourcen oder Konten, mit automatischem Schutz durch VPC, AWS-Konto sowie GovCloud-Support und einer durch SLA garantierten Reaktionszeit von weniger als 1 Stunde.
- Benutzer von Enterprise- und Elite-Preisplänen können die Möglichkeit von Druva, luftleere EC2-Sicherungen in der Druva Cloud zu speichern, gegen einen Aufpreis erwerben.
- Es ist leicht zu erkennen, wie man bei Druvas Preisschema insgesamt verwirrt werden kann. Glücklicherweise hat Druva selbst eine spezielle Webseite, die ausschließlich dazu dient, in wenigen Minuten einen personalisierten Kostenvoranschlag für die TCO eines Unternehmens mit Druva zu erstellen (ein Preisrechner).
Meine persönliche Meinung zu Druva:
Druva bietet eine Cloud-native und App-fähige Sicherungs- und Wiederherstellungslösung, die eines der häufigsten Probleme von Kubernetes löst – die Tatsache, dass der ausgefallene Cluster nach einem Ausfall aus irgendeinem Grund immer in einem leeren Zustand wiederhergestellt wird. Die Software selbst wird über ein Storage-as-a-Service-Modell bereitgestellt und ist sehr kompetent im Schutz von Kubernetes-Umgebungen (sowie vieler anderer Speichertypen). Druva kann Daten sichern, Daten wiederherstellen, eine Reihe von Aufgaben automatisieren, Sicherungen bestimmter Anwendungen erstellen und bestimmte Bereiche (z. B. Anwendungsgruppen oder Namespaces) sichern. Die Lösung unterstützt auch EKS und Amazon EC2, was sie zu einem echten Ausreißer auf dieser Liste – und auf dem allgemeinen Markt – macht. Druva hat zwar ein paar Probleme, darunter ein recht komplizierter erstmaliger Konfigurationsprozess und eine eher langsame Leistung beim Abrufen von Sicherungen aus dem Cloud-Speicher, aber die Gesamtlösung ist durchaus leistungsfähig, insbesondere für Kubernetes-Umgebungen.
Zerto

Zerto ist auch eine gute Wahl, wenn Sie nach einer multifunktionalen Backup-Management-Plattform mit nativer Kubernetes-Unterstützung suchen. Sie bietet alles, was Sie von einer modernen Kubernetes-Lösung für Sicherung und Wiederherstellung erwarten – kontinuierliche Datensicherung (CDP), Datenreplikation über Snapshots und minimale Anbieterbindung, da Zerto alle Kubernetes-Plattformen im Unternehmensbereich unterstützt.
Zerto bietet außerdem vom ersten Tag an Datenschutz als eine der Kernstrategien an und bietet die Möglichkeit, Anwendungen von Anfang an mit Schutz zu generieren. Zerto verfügt außerdem über zahlreiche Automatisierungsfunktionen, kann umfassende Einblicke bieten und mit verschiedenen Cloud-Speichern gleichzeitig arbeiten.
Datentypen, die von Zerto abgedeckt werden:
Zertos Position in Bezug auf die Kubernetes-Datenabdeckung ist einfach: Es kann nicht mit Anwendungen oder Speicherinfrastrukturen arbeiten, aber alles andere kann ohne Probleme gesichert werden – seien es Bereitstellungen, Namespaces, Dienste, Pods usw.
Kundenbewertungen:
- Capterra – 4,8/5 Sternen basierend auf 25 Kundenbewertungen
- TrustRadius – 8,6/10 Sternen basierend auf 113 Kundenbewertungen
- G2 – 4,6/5 Sternen basierend auf 73 Kundenbewertungen
Vorteile:
- Einfaches Management für Disaster-Recovery-Aufgaben
- Einfache Integration in bestehende Infrastrukturen, sowohl vor Ort als auch in der Cloud
- Funktionen zur Workload-Migration und viele weitere Funktionen
- Die Kubernetes-Funktionen von Zerto sind ebenfalls sehr umfangreich und vielfältig, einschließlich kontinuierlicher Datensicherung, Snapshot-Replikation und mehr
Mängel:
- Kann nur auf Windows-Betriebssystemen eingesetzt werden
- Die Berichtsfunktionen sind etwas starr
- Kann für größere Unternehmen und Betriebe recht teuer sein
Preise (zum Zeitpunkt der Erstellung):
- Die offizielle Zerto-Website bietet drei verschiedene Lizenzkategorien an – Zerto für VMs, Zerto für SaaS und Zerto für Kubernetes
- Die Zerto-Lizenz speziell für Kubernetes kann in zwei verschiedenen Formen erworben werden
- „Zerto Data Protection“ ist eine Datenschutzsoftware, die Funktionen für kontinuierliche Sicherung und Wiederherstellung über den gesamten Lebenszyklus der Anwendungsbereitstellung hinweg bietet. Sie umfasst langfristige Aufbewahrung, Klonen, lokale Replikation, orchestrierte Sicherungen und vieles mehr
- „Enterprise Cloud Edition“ ist eine Cloud-basierte Version des vorherigen Angebots, die ebenfalls eine kontinuierliche Sicherung und Wiederherstellung während des gesamten Lebenszyklus der Anwendungsentwicklung bietet. Sie erweitert den bestehenden Funktionsumfang um Funktionen wie eine koordinierte Notfallwiederherstellung und eine stets verfügbare Fernreplikation
- Es gibt keine offiziellen Preisinformationen für die Lösung von Zerto, sie kann nur über ein personalisiertes Angebot oder über einen der Vertriebspartner von Zerto erworben werden
Meine persönliche Meinung zu Zerto:
Zerto als Lösung für die datensicherung ist eine gute Option für mehrere Anwendungsfälle gleichzeitig – es handelt sich um eine umfassende Plattform, die eine Vielzahl verschiedener Speichertypen unterstützt. Zerto kann mit Azure, AWS und Google Cloud als Cloud-Speicheranbieter zusammenarbeiten und unterstützt VM-Abdeckung, Container-Abdeckung und viele andere Anwendungsfälle. Es kann Datenschutz als eine seiner größten und umfassendsten Funktionen bieten, und es gibt viele Optionen speziell für Kubernetes-Umgebungen – sei es eine minimale Anbieterbindung, Datenreplikationsfunktionen, CDP-Unterstützung und vieles mehr. Einige Funktionen von Zerto sind auch auf alle verschiedenen Speichertypen gleichzeitig anwendbar, sei es die Datenanalyse mit umfassenden Erkenntnissen, zahlreiche Automatisierungsoptionen usw.
Longhorn

Longhorn ist wahrscheinlich die am wenigsten bekannte der in diesem Blog besprochenen Lösungen. Die Community ist für eine Open-Source-Lösung relativ klein und es sind keine vollständigen Kubernetes-Sicherungen mit Metadaten und Ressourcen möglich, um eine anwendungsorientierte Wiederherstellung zu ermöglichen. Es gibt jedoch eine einzigartige Funktion, die heraussticht, und zwar DR Volume. DR Volume kann sowohl als Quelle als auch als Ziel eingerichtet werden, wodurch das Volume in einem neuen Cluster aktiv wird, der auf den neuesten gesicherten Daten basiert.
Longhorns Fähigkeit, mit vielen verschiedenen Containerplattformtypen zu arbeiten und verschiedene Sicherungsmethoden zu ermöglichen, unterscheidet es von anderen, und es gibt bereits die Möglichkeit, Kubernetes Engine, Docker-Bereitstellungen und K3-Distributionen zu unterstützen. Docker-Container müssen beispielsweise einen Tarball erstellen, der als Sicherung für Longhorn dienen könnte.
Datentypen, die von Longhorn abgedeckt werden:
Als kostenlose Lösung bietet Longhorn seinen Benutzern ein umfassendes Paket zur Abdeckung von Datentypen – einschließlich Sicherungen für Bereitstellungen, StatefulSets, Dienste, Geheimnisse, Pods und mehr. Es ist nicht in der Lage, Namespaces, Anwendungen oder Speicherinfrastrukturen zu sichern.
Kundenbewertungen:
- Capterra – 4,3/5 Sternen basierend auf 6 Kundenbewertungen
- G2 – 4,8/5 Sternen basierend auf 3 Kundenbewertungen
Hauptmerkmale:
- Infrastrukturunabhängige Lösung
- Einfacher Bereitstellungsprozess
- Praktisches und nützliches Dashboard
- Einfache Anpassung für Richtlinien zur Sicherung und Notfallwiederherstellung
Preise (zum Zeitpunkt der Erstellung):
- Longhorn ist eine kostenlose Open-Source-Kubernetes-Sicherungslösung, die ursprünglich von Rancher Labs entwickelt, später aber an die CNCF (Cloud Native Computing Foundation) gespendet wurde und nun als eigenständiges Sandbox-Projekt gilt.
- Rancher selbst hat eine separate Premium-Preisstufe namens Rancher Prime – sie bietet eine Vielzahl von Funktionen zur Erweiterung und Verbesserung der ursprünglichen Rancher-Funktionalität, aber der Preis ist auf der offiziellen Website nicht öffentlich verfügbar.
Meine persönliche Meinung zu Longhorn:
Ähnlich wie bei einer Reihe früherer Beispiele bietet Longhorn keine vollständige Kubernetes-Abdeckung, d. h. es gibt keine App-sensitiven Sicherungen. Gleichzeitig ist es eine interessante Option für kleine Unternehmen und Unternehmen mit kleinem Budget, da Longhorn kostenlos ist, eine Reihe von Containervarianten unterstützt und sogar mehrere Sicherungsmethoden bietet. Longhorn kann auch eine eigene ungewöhnliche Funktion namens DR Volume bieten – ein Volume, das sowohl als Ziel als auch als Quelle festgelegt werden kann und somit sofort in dem Cluster aktiv ist, der neu mit den vorhandenen Sicherungsdaten erstellt wurde. Für eine kostenlose Open-Source-Lösung ist dies auch relativ einfach, obwohl noch ein gewisser Lernaufwand zu erwarten ist.
Velero.io

Velero ist eine Open-Source-Lösung für die Sicherung und Wiederherstellung von Kubernetes mit Migrationsfunktionen. Sie unterstützt Snapshots für persistente Volumes und Clusterzustände, wodurch sowohl die Migration als auch die Wiederherstellung in verschiedenen Umgebungen möglich sind. Es handelt sich um eine bekannte Lösung im Bereich der Kubernetes-Sicherung, die zuverlässige Disaster-Recovery-Funktionen für Kubernetes-Cluster sowie Clustermigration, langfristige Aufbewahrung zu Compliance-Zwecken und vieles mehr bietet.
Hauptmerkmale:
- Clustermigration mit verschiedenen Konfigurationen.
- Clusterweiter Schutz und Granularität in Sicherungsprozessen.
- Umfangreiche Disaster-Recovery-Funktionen für die Geschäftskontinuität.
- Planung von Sicherungen mit zahlreichen Optionen zur Auswahl.
- Integration in die API zur Erstellung persistenter Volume-Snapshots für große Datensätze.
- Unterstützung für eine Reihe von Cloud-Speicheranbietern, darunter Azure Blob, Google Cloud, AWS S3 usw.
Preise (zum Zeitpunkt der Erstellung):
- Velero.io ist ein völlig kostenloses Open-Source-Tool, für das kein Preis festgelegt wurde.
Meine persönliche Meinung zu Velero.io:
Velero ist eine interessante Option für Sicherungs- und Wiederherstellungsaufgaben in Kubernetes-Umgebungen, da es kostenlos ist und eine hohe Granularität in seinen Funktionen bietet. Es unterstützt verschiedene Speicheranbieter, kann in die API der Plattform für persistente Snapshots integriert werden und ist im Allgemeinen eine überraschend praktische Lösung für viele Situationen. Für die meisten Anwendungsfälle in Unternehmen ist sie aufgrund des schieren Umfangs der erforderlichen Vorgänge nicht besonders geeignet, und das Fehlen der meisten gängigen Sicherheitsfunktionen wie Verschlüsselung würde die Arbeit für Unternehmen, die mit sensiblen Informationen umgehen, erschweren. Dennoch lohnt es sich, einen Blick auf die Lösung zu werfen, zumindest einen kurzen.
Welche Checkliste sollten Teams befolgen, um für Kubernetes-Backups gerüstet zu sein?
Eine Wiederherstellungsstrategie auf dem Papier zu haben, ist nicht dasselbe wie sie einsatzbereit zu haben. Diese Checkliste soll Ihnen dabei helfen, sicherzustellen, dass die in diesem Dokument getroffenen Entscheidungen und Konfigurationen konkret und überprüfbar umgesetzt werden.
Haben Sie kritische Workloads und Datenbereiche inventarisiert?
Zunächst einmal müssen Sie genau wissen, was Sie schützen. Ohne eine klare Bestandsaufnahme neigen Backup-Richtlinien dazu, entweder zu weit gefasst oder voller Lücken zu sein.
- Alle Namespaces und Workloads sind dokumentiert und nach Kritikalität klassifiziert
- Persistente Volumes sind nach Wiederherstellungspriorität kategorisiert
- Mit jeder Workload verbundene benutzerdefinierte Ressourcen und CRDs sind identifiziert
- In Ihrem Bestand werden zustandsbehaftete Anwendungen von zustandslosen unterschieden
- Für jede kritische Workload ist die Datenverantwortung zugewiesen
Sind RPO-, RTO- und Aufbewahrungsrichtlinien dokumentiert und genehmigt?
Wiederherstellungsanforderungen, die nicht formell vereinbart wurden, neigen dazu, sich unter Druck zu verschieben. Diese sollten vor einem Vorfall festgelegt werden, nicht währenddessen ausgehandelt.
- RPO- und RTO-Ziele sind für jede Workload-Ebene definiert
- Die Backup-Häufigkeit für etcd, PVs und Anwendungsdaten entspricht diesen Zielen
- Aufbewahrungsfristen sind dokumentiert und von demjenigen genehmigt, der für das Wiederherstellungs-SLA verantwortlich ist
- Es gibt Richtlinien für den Lebenszyklus und die Einstufung älterer Backup-Daten
- Richtlinien werden nach jeder wesentlichen Infrastrukturänderung überprüft und erneut genehmigt
Sind Überwachung, Alarmierung und Zugriffskontrolle für Backups vorhanden?
Ein Backup-Prozess, der still im Hintergrund läuft und still scheitert, vermittelt ein trügerisches Gefühl der Sicherheit. Die operativen Kontrollen müssen ebenso robust sein wie der Backup-Prozess selbst.
- Backup-Jobs werden überwacht, und Fehler lösen Warnmeldungen an die zuständigen Personen aus
- Der Zugriff auf Backup und Wiederherstellung ist in der RBAC-Konfiguration getrennt
- Wiederherstellungsvorgänge erfordern eine ausdrückliche Autorisierung für Produktionsumgebungen
- Die Verschlüsselung wird konsistent über die gesamte Backup-Pipeline hinweg angewendet
- Die Schlüsselverwaltung erfolgt unabhängig vom Backup-Speicher
Verfügen Sie über bewährte Runbooks für gängige Wiederherstellungsszenarien?
Nicht getestete Dokumentation ist eine Hypothese, kein Runbook. Regelmäßige Tests machen aus einem Wiederherstellungsplan eine Wiederherstellungsfähigkeit.
- Es existieren Runbooks zumindest für die gängigsten Wiederherstellungsszenarien: Einzel-Namespace, vollständiger Cluster und etcd-Wiederherstellung
- Wiederherstellungsverfahren wurden in einer Nicht-Produktionsumgebung durchgängig getestet
- Die Wiederherstellungszeit für jedes Szenario wurde anhand Ihres RTO gemessen
- Runbooks unterliegen der Versionskontrolle und werden nach jedem Test oder Vorfall überprüft
- Die Zuständigkeit für jedes Runbook ist zugewiesen und auf dem neuesten Stand
Die K8s-Backup-Lösung von Bacula Enterprise
Die Natur von Kubernetes-Umgebungen macht sie gleichzeitig sehr dynamisch und potenziell komplex. Die Sicherung eines Kubernetes-Clusters sollte die Komplexität nicht unnötig erhöhen. Und natürlich ist es für Systemadministratoren und anderes IT-Personal in der Regel wichtig – wenn nicht sogar entscheidend –, eine zentralisierte Kontrolle über das gesamte Backup- und Wiederherstellungssystem der gesamten Organisation zu haben, einschließlich aller Kubernetes-Umgebungen. Auf diese Weise werden Faktoren wie Compliance, Verwaltbarkeit, Geschwindigkeit, Effizienz und Geschäftskontinuität wesentlich realistischer. Gleichzeitig sollte der agile Ansatz der Entwicklungsteams dadurch in keiner Weise beeinträchtigt werden.
Bacula Enterprise ist in diesem Bereich einzigartig, da es sich um eine umfassende Unternehmenslösung für komplette IT-Umgebungen (nicht nur Kubernetes) handelt, die zudem nativ integrierte Kubernetes-Backups und -Wiederherstellungen bietet, einschließlich mehrerer Cluster, unabhängig davon, ob sich die Anwendungen oder Daten außerhalb oder innerhalb eines bestimmten Clusters befinden. Bacula bringt weitere Vorteile mit sich, da es besonders sicher, geschützt und stabil ist. Diese Eigenschaften werden im Kontext von Organisationen entscheidend, die ein Höchstmaß an Sicherheit gewährleisten müssen.
Cluster-Wiederherstellung
Die Betriebsabteilung jedes Unternehmens erkennt die Notwendigkeit einer geeigneten Wiederherstellungsstrategie, wenn es um Cluster-Wiederherstellung, Upgrades und andere Situationen geht. Ein Cluster, der sich in einem nicht wiederherstellbaren Zustand befindet, kann mit Bacula in den stabilen Zustand zurückversetzt werden, wenn sowohl die Konfigurationsdateien als auch die persistenten Volumes des Clusters zuvor korrekt gesichert wurden.
Eine weitere Möglichkeit, die Arbeitsweise von Bacula zu veranschaulichen, ist die folgende Abbildung:
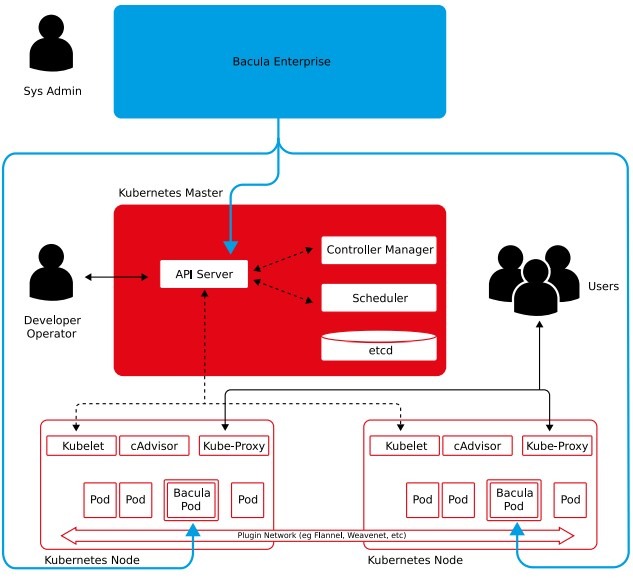
Einer der Hauptvorteile des Kubernetes-Moduls von Bacula ist die Möglichkeit, verschiedene Kubernetes-Ressourcen zu sichern, darunter:
- Pods;
- Dienste;
- Bereitstellungen;
- Persistente Volumes.
Funktionen des Kubernetes-Moduls von Bacula Enterprise
Dieses Modul funktioniert so, dass die Lösung selbst nicht Teil der Kubernetes-Umgebung ist, sondern stattdessen über Bacula-Pods, die an einzelne Kubernetes-Knoten in einem Cluster angeschlossen sind, auf die relevanten Daten innerhalb des Clusters zugreift. Die Bereitstellung dieser Pods erfolgt automatisch und nach Bedarf.
Zu den weiteren Funktionen, die das K8s-Backup-Modul bietet, gehören unter anderem:
- Kubernetes-Sicherung und -Wiederherstellung für persistente Volumes;
- Wiederherstellung einer einzelnen Kubernetes-Konfigurationsressource;
- Die Möglichkeit, Konfigurationsdateien und/oder Daten von persistenten Volumes im lokalen Verzeichnis wiederherzustellen;
- Die Möglichkeit, die Ressourcenkonfiguration von Kubernetes-Clustern zu sichern.
Es ist auch erwähnenswert, dass Bacula mehrere Cloud-Speicherplattformen gleichzeitig unterstützt, darunter AWS, Google, Glacier, Oracle Cloud, Azure und viele andere, auf der Ebene der nativen Integration. Hybride Cloud-Funktionen sind somit integriert, einschließlich fortschrittlicher Cloud-Management- und automatisierter Cloud-Caching-Funktionen, die eine einfache Integration von öffentlichen oder privaten Cloud-Diensten zur Unterstützung verschiedener Aufgaben ermöglichen.
Die Flexibilität von Lösungen ist heutzutage besonders wichtig, da viele Unternehmen und Konzerne in Bezug auf verschiedene Hypervisor-Familien und Container immer komplexer werden. Gleichzeitig steigt dadurch die Nachfrage nach Anbieterflexibilität für alle Datenbankanbieter erheblich. Baculas Fähigkeiten in dieser Hinsicht sind beträchtlich hoch, da es seine breite Kompatibilitätsliste mit verschiedenen Technologien kombiniert, um besonders hohe Flexibilitätsstandards zu erreichen, ohne sich an einen Anbieter zu binden.
Die Komplexität der verschiedenen Aspekte der Arbeit eines Unternehmens nimmt ständig zu, und in den meisten Fällen ist es einfacher und kostengünstiger, eine einzige Lösung für die gesamte IT-Umgebung zu verwenden und nicht mehrere Lösungen gleichzeitig. Bacula ist genau dafür ausgelegt und kann sowohl eine traditionelle webbasierte Oberfläche für Ihre Konfigurationsanforderungen als auch die klassische Befehlszeilensteuerung bereitstellen. Diese beiden Schnittstellen können sogar gleichzeitig verwendet werden.
Das Kubernetes-Backup-Plugin von Bacula ermöglicht zwei Haupttypen von Zielen für Wiederherstellungsvorgänge:
- Wiederherstellung in einem lokalen Verzeichnis;
- Wiederherstellung in einem Cluster…
Regelmäßige und/oder automatisierte sicherungen werden dringend empfohlen, um die bestmögliche sicherungs- und Wiederherstellungsumgebung für Container zu gewährleisten. Auch für Ihren Systemadministrator sollte es obligatorisch sein, Ihre sicherungen von Zeit zu Zeit zu testen. Im nächsten Bild sehen Sie einen Teil des Wiederherstellungsprozesses, nämlich den Teil „Auswahl wiederherstellen“, in dem Sie auswählen können, welche Dateien und/oder Verzeichnisse Sie wiederherstellen möchten:
Ein weiterer Teil des Wiederherstellungsprozesses, auf den Sie stoßen werden, ist die Seite mit den erweiterten Wiederherstellungsoptionen, die wie folgt aussieht:
Hier können Sie mehrere verschiedene Optionen angeben, z. B. Ausgabeformat, Pfad der KBS-Konfigurationsdatei, Endpunkt-Port und mehr.
Es ist auch einfach, den gesamten Wiederherstellungsprozess nach Abschluss der Anpassung zu überwachen, da auf der Protokollseite des Wiederherstellungsauftrags jede Aktion einzeln aufgezeichnet wird:
Eine weitere wichtige Funktion des Kubernetes-Moduls ist die Plugin-Auflistung, die zahlreiche nützliche Informationen über Ihre verfügbaren Kubernetes-Ressourcen bietet, darunter Namespaces, persistente Volumes usw. Zu diesem Zweck verwendet das Modul einen speziellen ls-Befehl mit einem spezifischen plugin=<plugin>-Parameter.
Das Kubernetes-Modul von Bacula bietet eine Vielzahl von Funktionen, darunter:
- Schnelle und effiziente Umverteilung von Cluster-Ressourcen;
- Sicherung des Kubernetes-Cluster-Status;
- Speichern von Konfigurationen zur Verwendung in anderen Vorgängen;
- Sicherstellung, dass geänderte Konfigurationen so sicher wie möglich sind und der Zustand von zuvor wiederhergestellt werden kann.
Auch wenn dies häufig vorkommt, wird dringend empfohlen, eine Bezahlung Ihres Anbieters auf Basis des Datenvolumens zu vermeiden. Es macht keinen Sinn, sich jetzt oder in Zukunft von einem Anbieter erpressen zu lassen, der bereit ist, Ihr Unternehmen auf diese Weise auszunutzen. Sehen Sie sich stattdessen die Lizenzmodelle von Bacula Systems genauer an, die Kunden vor Gebühren aufgrund von Datenwachstum schützen und es den Beschaffungsabteilungen der Kunden zudem erheblich erleichtern, zukünftige Kosten zu prognostizieren. Dieser vernünftigere Ansatz von Bacula entspringt seinen Open-Source-Wurzeln und könnte für Teams interessant sein, die intensiv in DevOps-Umgebungen arbeiten.
Fazit
Letztendlich haben Kubernetes-Benutzer eine Vielzahl von Optionen, wenn es um Software für die Sicherung und Wiederherstellung geht. Einige davon sind nur für die Verwaltung von Kubernetes-Daten konzipiert, während andere Lösungen Kubernetes zu ihrer bestehenden Liste von Funktionen hinzufügen.
Kleinere Unternehmen, die nach einer Lösung suchen, die ausschließlich Kubernetes-Backups durchführen kann, könnten Longhorn oder OpenEBS gegenüber den übrigen Beispielen auf unserer Liste bevorzugen. Alternativ benötigen größere Unternehmen mit einer Vielzahl unterschiedlicher Speichertypen in ihrer eigenen Infrastruktur möglicherweise eine umfassende und hochsichere Backup-Lösung, die die gesamten IT-Systeme des Unternehmens ohne Fragmentierung abdeckt und die es ermöglicht, den gesamten Backup- und Wiederherstellungsprozess über eine zentrale Verwaltungsoberfläche zu überblicken – genau dafür sind Lösungen wie Bacula Enterprise konzipiert. Die endgültige Entscheidung hängt stark von den individuellen Anforderungen und Prioritäten des jeweiligen Kunden ab, darunter die Unternehmensgröße, die erforderlichen Funktionen und so weiter.
Warum Sie uns vertrauen können
Bei Bacula Systems dreht sich alles um Genauigkeit und Konsistenz. Unsere Materialien versuchen immer, die objektivste Sichtweise auf verschiedene Technologien, Produkte und Unternehmen zu bieten. In unseren Bewertungen verwenden wir viele verschiedene Methoden wie Produktinformationen und Expertenmeinungen, um möglichst informative Inhalte zu erstellen.
Unsere Materialien bieten alle möglichen Faktoren zu jeder einzelnen vorgestellten Lösung, seien es Funktionsmerkmale, Preise, Kundenbewertungen usw. Die Produktstrategie von Bacula wird von Jorge Gea – dem CTO von Bacula Systems – und Rob Morrison – dem Marketing Director von Bacula Systems – überwacht und gesteuert.
Vor seinem Eintritt bei Bacula Systems war Jorge viele Jahre lang CTO bei Whitebearsolutions SL, wo er den Bereich Sicherung und Speicherung sowie die WBSAirback-Lösung leitete. Jorge bietet nun Führung und Anleitung in aktuellen technologischen Trends, technischen Fähigkeiten, Prozessen, Methoden und Werkzeugen für die schnelle und spannende Entwicklung von Bacula-Produkten. Jorge ist für die Produkt-Roadmap verantwortlich und aktiv in die Architektur, das Engineering und den Entwicklungsprozess der Bacula-Komponenten eingebunden. Jorge hat einen Bachelor-Abschluss in Informatik-Ingenieurwesen von der Universität Alicante, einen Doktortitel in Computertechnologien und einen Master-Abschluss in Netzwerkadministration.
Rob begann seine IT-Marketing-Karriere bei Silicon Graphics in der Schweiz, wo er fast 10 Jahre lang in verschiedenen Marketing-Management-Positionen erfolgreich tätig war. In den darauffolgenden 10 Jahren hatte Rob verschiedene Marketing-Management-Positionen bei JBoss, Red Hat und Pentaho inne und sorgte für ein Wachstum der Marktanteile dieser bekannten Unternehmen. Er ist Absolvent der Plymouth University und hat einen Abschluss mit Auszeichnung in Digitalen Medien und Kommunikation.
Bei Bacula Systems dreht sich alles um Genauigkeit und Konsistenz. Unsere Informationen versuchen immer, die objektivste Sichtweise auf verschiedene Technologien, Produkte und Unternehmen zu bieten. In unseren Bewertungen verwenden wir viele verschiedene Methoden, wie z. B. Produktinformationen und Expertenmeinungen, um möglichst informative Inhalte zu erstellen.
Unsere Materialien bieten alle möglichen Faktoren zu jeder einzelnen vorgestellten Lösung, seien es Funktionsmerkmale, Preise, Kundenbewertungen usw. Die Produktstrategie von Bacula wird von Jorge Gea – dem CTO von Bacula Systems – und Rob Morrison – dem Marketing Director von Bacula Systems – überwacht und gesteuert.
Vor seinem Eintritt bei Bacula Systems war Jorge viele Jahre lang CTO bei Whitebearsolutions SL, wo er den Bereich Sicherung und Speicherung sowie die WBSAirback-Lösung leitete. Jorge bietet nun Führung und Anleitung in aktuellen technologischen Trends, technischen Fähigkeiten, Prozessen, Methoden und Werkzeugen für die schnelle und spannende Entwicklung von Bacula-Produkten. Jorge ist für die Produkt-Roadmap verantwortlich und aktiv in die Architektur, das Engineering und den Entwicklungsprozess der Bacula-Komponenten eingebunden. Jorge hat einen Bachelor-Abschluss in Informatik-Ingenieurwesen von der Universität Alicante, einen Doktortitel in Computertechnologien und einen Master-Abschluss in Netzwerkadministration.
Rob begann seine IT-Marketing-Karriere bei Silicon Graphics in der Schweiz, wo er fast 10 Jahre lang in verschiedenen Marketing-Management-Positionen erfolgreich tätig war. In den darauffolgenden 10 Jahren hatte Rob verschiedene Marketing-Management-Positionen bei JBoss, Red Hat und Pentaho inne und sorgte für ein Wachstum der Marktanteile dieser bekannten Unternehmen. Er ist Absolvent der Plymouth University und hat einen Abschluss in Digitalen Medien und Kommunikation mit Auszeichnung.
Häufig gestellte Fragen
Was ist der Hauptzweck von Kubernetes-Sicherungen?
Der Zweck einer Kubernetes-Sicherung ähnelt dem Zweck der meisten Sicherungen – es werden sichere Kopien von Informationen erstellt, die im Falle einer Katastrophe, ob versehentlich oder absichtlich, wiederhergestellt werden können. Ein ordnungsgemäßes Sicherungspaket kann die Lösung für Systemausfälle, Datenverlust, Datenbeschädigung, Datendiebstahl und viele andere Situationen sein, in denen die Existenz des gesamten Unternehmens davon abhängt, ob die Daten wiederhergestellt werden können oder nicht.
Wie komplex sind Kubernetes-Sicherungen im Vergleich zu herkömmlichen VM-Sicherungen?
Die Containerisierung von Kubernetes-Arbeitslasten ist der Hauptgrund dafür, dass diese Sicherungen als anspruchsvoller und komplexer gelten als herkömmliche VM-Sicherungen. Jede Kubernetes-Anwendung umfasst mehrere Mikrodienste, wobei sowohl ein Cluster- als auch ein Anwendungsstatus gesichert werden müssen, damit sie ordnungsgemäß funktionieren. Dies macht eine ordnungsgemäße Wiederherstellung ohne Kontinuitätsverlust zu einer großen Herausforderung. Darüber hinaus stellt die sich ständig ändernde Natur von Kubernetes-Clustern eine weitere Schwierigkeit dar, die die Sicherungs- und Wiederherstellungsprozesse noch komplexer macht.
Welche Sicherungssoftware ist die beste Option für Kubernetes-Sicherungen?
Es lässt sich kaum behaupten, dass eine einzige Lösung die absolut beste Option für einen bestimmten Anwendungsfall ist, da jedes Unternehmen seine ganz eigenen Gegebenheiten und Anforderungen hat. Die meisten Unternehmen haben zudem ein striktes Budget für Backup-Software, was bedeutet, dass der gesamte Funktionsumfang eine geringere Priorität hat als der Preis der Lösung. Letztendlich wird die nützlichste Lösung auf dieser Liste diejenige sein, die für die größte Anzahl und das breiteste Spektrum potenzieller Anwendungsfälle geeignet ist – in dieser Situation wäre Bacula Enterprise der unangefochtene Sieger dieser Liste.
Was kann Bacula für Multi-Cloud-Kubernetes-Umgebungen bieten?
Bacula bietet die Flexibilität der Datenwiederherstellung und Notfallwiederherstellung, indem es die Sicherung von Daten in verschiedenen Cloud-Speicherumgebungen ermöglicht. Die Wiederherstellung von Informationen in einem beliebigen kompatiblen Cluster anstelle des Clusters, aus dem die Daten kopiert wurden, ist hier ebenfalls eine Option. Die Ausfallsicherheit und Redundanz einer Kubernetes-Umgebung wird auf diese Weise drastisch erhöht, insbesondere bei verschiedenen Cloud-spezifischen Ausfällen. Bacula ermöglicht es seinen Benutzern auch, sowohl Namespaces als auch ganze Cluster in verschiedenen Cloud-Speicherumgebungen wiederherzustellen, wodurch eine umfassende Kontinuität gewährleistet wird, ohne dass die Benutzer an denselben Cloud-Speicher gebunden sind. Ein kritischer Aspekt, der von Kubernetes-Architekten oft übersehen wird, ist die Notwendigkeit ihrer Organisation, das höchstmögliche Sicherheitsniveau zu erreichen. Im Vergleich zu praktisch allen anderen Anbietern von sicherungen verfügt Bacula über ein höheres Maß an Sicherheit, das in seine Architektur, seine Methoden, seine Prozesse und seine einzelnen Funktionen integriert ist.
Welche Arten von Umgebungen unterstützt Bacula?
Bacula kann nicht nur mit lokalen und cloudbasierten Kubernetes-Clustern arbeiten, sondern unterstützt auch hybride Umgebungen, sodass beide Bereitstellungsoptionen für ein Höchstmaß an Flexibilität, Effizienz und Sicherheit in verschiedenen Umgebungen kombiniert werden können.

