

Contents
- Introdução
- Conceitos importantes para um processo de backup no Kubernetes
- Por que os backups do K8s são necessários?
- O valor dos backups do Kubernetes
- As vantagens das operações de backup do Kubernetes
- Tipos de dados do Kubernetes que precisam ser copiados
- O que você deve fazer backup em um ambiente Kubernetes?
- Como o GitOps afeta sua estratégia de backup do Kubernetes?
- Práticas recomendadas para operações de backup do Kubernetes
- Como você deve projetar agendas de backup e políticas de retenção do Kubernetes?
- Como proteger backups do Kubernetes e atender aos requisitos de conformidade?
- Metodologia para escolher a melhor solução de backup para Kubernetes
- Mercado de soluções de backup do Kubernetes
- Que lista de verificação as equipes devem seguir para garantir a prontidão do backup do Kubernetes?
- A solução de backup para K8s da Bacula Enterprise
- Conclusão
- Por que você pode confiar em nós
- Perguntas frequentes
Introdução
O Kubernetes (também conhecido como K8s) é uma plataforma de orquestração de contêineres que auxilia no gerenciamento e na escalabilidade de aplicações – frequentemente a escolha preferida de empresas que podem tirar proveito da arquitetura de aplicações em contêineres. A flexibilidade do Kubernetes faz com que muitas implantações sejam muito diferentes umas das outras. No entanto, estruturas exclusivas geralmente trazem consigo desafios específicos de recuperação e disponibilidade, os quais fazem parte do desafio de utilizar o Kubernetes na infraestrutura de TI da sua empresa.
Embora a suposição de que o Kubernetes era usado anteriormente principalmente por equipes de DevOps possa ter sido, em certa medida, correta, muitas empresas estão agora implantando ativamente contêineres em ambientes operacionais. Elas também estão cada vez mais confiando nos contêineres para implantar aplicações, em vez de usar VMs tradicionais. Isso se deve às várias vantagens de flexibilidade, desempenho e custo que os contêineres podem oferecer. No entanto, à medida que os contêineres passam para o lado operacional do ambiente de TI, cresce a preocupação com os aspectos de segurança dos contêineres em sistemas de produção que devem permanecer disponíveis, incluindo seus dados persistentes no contexto dos processos de backup e restauração.
Originalmente, a esmagadora maioria dos aplicativos em contêineres era stateless, o que lhes permitia um processo de implantação muito mais fácil em uma nuvem pública. Mas isso mudou com o tempo, com muito mais aplicativos com estado sendo implantados em contêineres do que antes. Essa mudança é a razão pela qual o backup e a recuperação no Kubernetes são agora um tema importante para muitas organizações.
Conceitos importantes para um processo de backup no Kubernetes
- A importância dos backups no Kubernetes gira em torno da segurança dos dados, uma vez que a informação é o recurso mais importante de qualquer empresa moderna e quase sempre exige que esses dados sejam mantidos em segurança, protegidos e privados. No contexto do Kubernetes, informações valiosas geralmente também incluem suas configurações, segredos, banco de dados etcd, volumes persistentes, etc.
- A configuração adequada da estratégia de backup pode oferecer ampla versatilidade e funcionalidade a um ambiente Kubernetes, incluindo backups no nível do aplicativo, backups no nível do namespace, snapshots, validação de backup, controle de versões, políticas de backup e muitos outros.
- A configuração correta da restauração é igualmente importante, considerando quantas partes diferentes do processo podem potencialmente falhar. Testes rigorosos de backup, consultoria em documentação e vigilância constante durante a recuperação fazem parte do que deve ser mantido para que os processos de recuperação sejam bem-sucedidos.
- Os backups do Kubernetes podem enfrentar uma série de desafios – sejam eles questões de consistência de dados, padrões de conformidade, segurança de dados e compatibilidade de versões, entre outros. A boa notícia é que a maioria dessas armadilhas pode ser evitada ou mitigada com um certo nível de preparação.
Por que os backups do K8s são necessários?
Um ambiente Kubernetes é dinâmico, distribuído e inerentemente mais propenso à perda de dados do que uma infraestrutura convencional. Esta seção aborda os vários fatores de falha que tornam os backups indispensáveis, as diferentes categorias de falha, as estratégias de recuperação correspondentes e a necessidade de que as exigências de backup sejam explicitamente documentadas em SLAs e runbooks.
Quais riscos os clusters do Kubernetes enfrentam sem backups?
Em um ambiente Kubernetes, existem perigos que vão muito além dos problemas padrão de infraestrutura.
- Ataques direcionados à cadeia de suprimentos contra imagens de contêineres ou repositórios Helm podem facilmente introduzir código malicioso que é difícil de detectar antes que cause danos
- Funções de IAM na nuvem que foram configuradas incorretamente podem expor — ou pior — danificar os recursos do cluster em toda a escala
- Eventos de autoescala podem rapidamente pegar cargas de trabalho com estado desprevenidas, causando corrupção de dados invisível, mas permanente
Riscos como esses podem se multiplicar extremamente rápido em sistemas distribuídos, onde o alcance de um único evento pode se espalhar para dezenas de cargas de trabalho em dezenas de namespaces.
Como diferem as falhas de aplicativos, clusters e dados?
As falhas do Kubernetes geralmente ocorrem em camadas diferentes e têm estratégias de recuperação correspondentemente distintas. A falha pode afetar apenas uma única carga de trabalho, pode afetar todo o cluster ou pode afetar dados armazenados externamente a ambos. As seções a seguir abordarão cada uma dessas falhas com mais detalhes, mas conhecer essa distinção antecipadamente também prepara o terreno para compreender por que uma estratégia de “um backup para todos” raramente é bem-sucedida.
Quando os backups devem fazer parte de seus SLAs e runbooks?
Os backups precisam ser obrigatórios quando uma carga de trabalho tem um RTO e/ou RPO definido. Se você está comprometido com um objetivo de tempo de recuperação – essa métrica deve vir acompanhada de um processo de restauração documentado e testado, o que significa que a frequência dos backups, a retenção e o processo de restauração devem ser documentados antes de um incidente, não depois dele.
As cargas de trabalho encontradas em um runbook de plantão devem ser contabilizadas com uma responsabilidade explícita e uma política de backup documentada. Ambientes regulados por conformidade adicionam sua própria camada ao processo, exigindo comprovação de que os backups existem, estão sendo testados e atendem às políticas de retenção documentadas necessárias.
O valor dos backups do Kubernetes
A própria natureza dos ambientes Kubernetes torna mais difícil que sistemas e técnicas de backup mais tradicionais funcionem bem no contexto de nós e aplicativos do Kubernetes. Tanto o RPO quanto o RTO podem, de fato, ser muito mais críticos, uma vez que as aplicações que fazem parte de uma implantação operacional precisam estar constantemente em funcionamento, especialmente os elementos de infraestrutura crítica.
Isso nos leva a identificar elementos-chave de continuidade de negócios que são praticamente necessários para todas as empresas em geral e uma necessidade clara quando se trata das melhores práticas de backup do K8s: backup e recuperação, alta disponibilidade local, recuperação de desastres, proteção contra ransomware, erro humano e assim por diante. Em um ambiente Kubernetes, o contexto desses aspectos do backup pode variar ligeiramente em relação à sua definição normal.
Alta disponibilidade local
A alta disponibilidade local, como recurso, diz respeito mais à prevenção de falhas/proteção dentro de um data center específico ou entre zonas de disponibilidade (se estivermos falando da nuvem, por exemplo). Uma falha “local” ocorre na infraestrutura/nó/aplicativo usado para executar a aplicação. Em um cenário ideal, sua solução de backup do Kubernetes deve ser capaz de reagir a essa falha mantendo o aplicativo em funcionamento, o que significa, essencialmente, nenhum tempo de inatividade para o usuário final. Um dos exemplos mais comuns de falha local é um volume na nuvem travado que ocorre após uma falha de nó.
Nessa perspectiva, a alta disponibilidade local como recurso pode ser considerada parte essencial da estratégia de proteção de dados. Por um lado, para realizar tal tarefa, sua solução precisa oferecer algum tipo de sistema de replicação de dados localmente, e também precisa estar no caminho dos dados em primeiro lugar. É importante mencionar que fornecer disponibilidade local por meio da restauração de backup ainda é considerado backup e restauração, e não alta disponibilidade local, devido ao tempo total de recuperação.
Backup e restauração
Backup e restauração é outro elemento importante de um sistema Kubernetes operacional. Na maioria dos casos de uso, ele faz o backup de toda a aplicação de um cluster Kubernetes local para um local externo. O contexto do Kubernetes também levanta outra consideração importante – se o software de backup “entende” ou não o que está incluído em uma aplicação Kubernetes, como:
- Configuração da aplicação;
- Recursos do Kubernetes;
- Dados
Um backup correto do Kubernetes precisa salvar todas as partes acima como uma única unidade para que seja útil no sistema Kubernetes após a restauração. Direcionar-se a VMs, servidores ou discos específicos não significa que o software “compreenda” os aplicativos do Kubernetes. Idealmente, o software do Kubernetes deve ser capaz de fazer backup de aplicativos específicos, grupos específicos de aplicativos, bem como de todo o namespace do Kubernetes. Isso não quer dizer que seja completamente diferente do processo de backup regular – os backups do Kubernetes também podem se beneficiar muito de alguns dos recursos comuns de um backup normal, incluindo retenção, agendamento, criptografia, hierarquização e assim por diante.
Recuperação de desastres
A capacidade de Recuperação de Desastres (DR) é essencial para qualquer organização que utilize o Kubernetes em uma situação de missão crítica, assim como ocorre ao empregar qualquer outra tecnologia. Primeiro, a DR precisa “compreender” o contexto dos backups do Kubernetes, assim como o backup e a restauração. Ela também pode ter diferentes níveis de RTO e RPO e diferentes níveis de proteção de acordo com esses níveis. Por exemplo, pode haver um requisito estrito de RPO zero, que implica tempo de inatividade estritamente nulo, ou pode haver um RPO de 15 minutos com requisitos um pouco menos rigorosos. Também não é incomum que diferentes aplicativos tenham RTOs e RPOs completamente distintos dentro do mesmo banco de dados.
Outra distinção importante de um sistema de recuperação de desastres específico para o Kubernetes é que ele também deve ser capaz de trabalhar com metadados até certo ponto (rótulos, réplicas de aplicativos, etc.). A incapacidade de fornecer esse recurso poderia facilmente levar a uma recuperação desarticulada em geral, bem como à perda geral de dados ou a tempo de inatividade adicional.
Proteção contra ransomware
A importância dos backups de sistemas Kubernetes (especialmente aqueles que geram dados persistentes) rivaliza com a dos backups regulares de dados. Dados valiosos devem ser protegidos para evitar riscos inaceitáveis. A informação é inestimável, e a Bacula Systems recomenda fortemente que se tenha em mente um plano dedicado (ou vários) para situações em que os dados comerciais sejam corrompidos ou de outra forma comprometidos.
Muitas dessas medidas de proteção funcionam de maneira eficaz tanto contra eventos acidentais quanto contra eventos maliciosos. Ataques intencionais que resultam em violações de dados por meio de ransomware, falsificação de identidade e outras medidas tornaram-se muito comuns, e é completamente irrealista pensar que sua empresa nunca será alvo de tal evento. Assim, preparar-se para essas situações pode oferecer benefícios em termos de vários fatores extremamente importantes, como cumprir a conformidade, proteger a reputação pessoal e empresarial, proteger clientes e funcionários e, acima de tudo, evitar danos graves a uma empresa e/ou organização.
Erro humano
A gravidade de um único erro humano pode ser significativa (exclusões acidentais, configurações incorretas, implementação não intencional de atualizações). Embora a automação de algumas funções possa mitigar um pouco os erros humanos, normalmente é impossível automatizar todos os processos na maioria das empresas.
Nesse contexto, os planos de backup e recuperação de desastres servem para garantir que uma empresa possa continuar seus negócios de forma eficaz após um acidente envolvendo um comando incorreto ou um erro de configuração.
As vantagens das operações de backup do Kubernetes
Os backups do Kubernetes apresentam múltiplas vantagens — muitas vezes semelhantes às operações regulares de backup em qualquer outro tipo de dados. É uma excelente maneira de manter a confiabilidade, a disponibilidade e a integridade das aplicações e dos dados de aplicativos do Kubernetes. Algumas das vantagens mais comuns são apresentadas a seguir.
Mitigação do impacto de falhas de hardware
Tecnicamente falando, falhas de hardware são inevitáveis e podem ocorrer a qualquer momento; seja uma falha de rede, uma queda de energia, um mau funcionamento da unidade de armazenamento ou qualquer outro tipo de evento que leve à corrupção ou perda de dados. Os backups do Kubernetes podem oferecer um alto nível de proteção contra tais eventos, fornecendo uma cópia redundante das informações que pode ser restaurada em qualquer outro ambiente caso o hardware original não esteja mais disponível, minimizando o tempo de inatividade e melhorando a continuidade dos negócios.
Recuperação de desastres
A maioria dos desastres naturais é capaz de destruir completamente toda a infraestrutura física de uma empresa, incluindo seus clusters do Kubernetes e, possivelmente, até mesmo os backups primários desses clusters. A existência de um backup externo é, portanto, um dos muitos benefícios que a estratégia de recuperação de desastres oferece aos usuários, proporcionando uma maneira de reconstruir rapidamente toda a rede de clusters para retomar as operações dentro de um prazo aceitável.
Prevenção contra perda de dados
Erros acidentais e má gestão são surpreendentemente comuns até hoje, independentemente do número crescente de violações maliciosas de dados. Todo ser humano pode cometer erros, e a incapacidade de reverter uma determinada ação, exclusão ou modificação aumenta drasticamente a probabilidade de perda permanente de dados para informações confidenciais. Backups regulares do K8s ajudam a garantir que acidentes causados involuntariamente ainda possam ser recuperados, de uma forma ou de outra.
Defesa contra ataques cibernéticos
As ameaças cibernéticas vêm aumentando significativamente há vários anos, e espera-se, de forma quase universal, que a situação se deteriore ainda mais. Toda infraestrutura de TI está constantemente sob o risco de um ataque cibernético, e a existência de medidas de backup definidas e seguras é fundamental para proteger empresas inteiras. A falta disso representa um risco significativo para a própria continuidade da empresa.
Assistência para ambientes de teste e desenvolvimento
Os backups regulares de clusters do Kubernetes costumam ter um valor adicional: eles também podem servir como uma grande ajuda nos processos de teste e desenvolvimento, simplificando significativamente o processo de criação de réplicas de clusters para fins de desenvolvimento sem afetar os dados originais. Dessa forma, a experimentação pode se mostrar muito mais proveitosa e eficiente, oferecendo inúmeras oportunidades de desenvolvimento para a própria empresa.
Tipos de dados do Kubernetes que precisam ser copiados
A razão usual pela qual a conteinerização é empregada é criar e executar um ambiente de execução seguro, confiável e leve para aplicações, tornando o sistema consistente de host para host. Normalmente, esses sistemas geram dados persistentes — e, quando isso ocorre, esses dados geralmente têm valor e, portanto, devem ser copiados. Além disso, todo o sistema de contêineres em si deve ser protegido e ter seu backup feito para que, caso ocorra algum tipo de perda ou corrupção, o sistema possa ser rapidamente recuperado, minimizando a perda de sistemas e serviços — e de negócios em potencial — para uma organização.
O Kubernetes é a tecnologia de contêineres mais popular em uso atualmente. Como tal, o tema dos diferentes tipos de dados do Kubernetes que precisam de backup requer uma análise minuciosa.
Assim como em qualquer sistema complexo, o Kubernetes e o Docker possuem vários tipos de dados específicos necessários para reconstruir todo o banco de dados adequadamente em caso de desastre. Para facilitar, é possível dividir todos os tipos de dados e arquivos de configuração em duas categorias diferentes: configuração e dados persistentes.
A configuração (e as informações de estado desejado) inclui:
- Banco de dados etcd do Kubernetes
- Arquivos Docker
- Imagens de arquivos Docker
Os dados persistentes (alterados ou criados pelos próprios contêineres) são:
- Bancos de dados
- Volumes persistentes
Banco de dados etcd do Kubernetes
É parte integrante do sistema, contendo informações sobre os estados do cluster. Pode ser copiado manualmente ou automaticamente, dependendo da sua solução de backup. O método manual é feito por meio do comando etcdctl snapshot save db, que cria um único arquivo com o nome snapshot.db.
Outro método para fazer o mesmo é acionar esse mesmo comando imediatamente antes de criar um backup do diretório em que esse arquivo estaria localizado. Essa é uma das maneiras de integrar esse backup específico a todo o ambiente.
Arquivos Docker
Como os próprios contêineres Docker são executados a partir de imagens, essas imagens precisam se basear em algo — e essas, por sua vez, são criadas a partir de arquivos Docker. Para uma configuração correta do Docker, recomenda-se usar um repositório como sistema de controle de versão para todos os seus arquivos Docker (GitHub, por exemplo). Para facilitar a recuperação de versões anteriores, todos os arquivos Docker devem ser armazenados em um repositório específico que permita aos usuários recuperar versões mais antigas desses arquivos, se necessário.
Recomenda-se também um repositório adicional para os arquivos YAML associados a todas as implantações do Kubernetes; esses arquivos existem na forma de arquivos de texto. Fazer backup desses repositórios também é imprescindível, seja utilizando ferramentas de terceiros ou os recursos integrados de plataformas como o GitHub.
É importante mencionar que você ainda pode gerar os arquivos Docker a serem copiados, mesmo que esteja executando contêineres a partir de imagens sem seus arquivos Docker. Existe um comando específico, o docker image history, que permite criar um arquivo Docker a partir de sua imagem atual. Existem também várias ferramentas de terceiros que podem fazer o mesmo.
Imagens a partir de arquivos Docker
As próprias imagens Docker também devem ser copiadas para um repositório. Tanto o repositório privado quanto o público podem ser usados exatamente para esse fim. Vários provedores de nuvem tendem a fornecer repositórios privados aos seus clientes também. Caso a imagem a partir da qual seu contêiner é executado esteja faltando, um comando específico, o docker commit, deve ser capaz de criar essa imagem.
Bancos de dados
A integridade também é crucial ao lidar com bancos de dados que os contêineres utilizam para armazenar seus dados. Em alguns casos, é possível desligar o contêiner em questão antes de criar um backup dos dados, mas, por outro lado, o tempo de inatividade necessário provavelmente resultará em muitos problemas para a empresa em questão.
Outro método para fazer backups de bancos de dados dentro de contêineres é conectando-se ao próprio mecanismo do banco de dados. Deve-se usar um bind mount previamente para anexar um volume que possa ser copiado, e então você pode usar o comando mysqldump (ou similar) para criar um backup. O arquivo de backup em questão também deve ser copiado usando seu sistema de backup posteriormente.
Volumes persistentes
Existem diferentes métodos para que os contêineres obtenham acesso a algum tipo de armazenamento persistente. Por exemplo, no caso dos volumes tradicionais do Docker, estes residem em um diretório abaixo da configuração do Docker. As montagens bind, por outro lado, podem ser qualquer diretório montado dentro de um contêiner. Apesar de os volumes tradicionais serem preferidos na comunidade Docker, ambos são relativamente semelhantes quando se trata de fazer backup de dados. Uma terceira maneira de realizar a mesma operação é montando um diretório NFS ou um único objeto como um volume dentro de um contêiner.
Todos esses três métodos apresentam o mesmo problema quando se trata de fazer backup de dados – a consistência de um backup não é completa se os dados dentro de um contêiner forem alterados no meio do processo. É claro que sempre é possível garantir a consistência desligando o volume antes do backup, mas, na maioria dos casos, o tempo de inatividade para tais sistemas não é viável para a continuidade dos negócios.
Existem algumas maneiras específicas de fazer backup de dados dentro de contêineres. Por exemplo, volumes tradicionais do Docker poderiam ser montados em outro contêiner que não alteraria nenhum dado até que o processo de backup fosse concluído. Ou, se você estiver usando um volume montado por bind, é possível criar uma imagem tar de um volume inteiro e, em seguida, fazer o backup dessa imagem.
Infelizmente, todas essas opções podem ser realmente difíceis de executar quando se trata do Kubernetes. Exatamente por esse motivo, é sempre recomendável armazenar informações com estado no banco de dados e fora do sistema de arquivos do contêiner.
Dito isso, se você estiver usando um diretório montado por bind ou um sistema de arquivos montado por NFS como armazenamento persistente, também é possível fazer backup desses dados usando métodos comuns, como um snapshot. Isso deve proporcionar muito mais consistência do que o backup tradicional no nível do arquivo do mesmo volume.
O que você deve fazer backup em um ambiente Kubernetes?
Existem diferentes tipos de dados em um ambiente Kubernetes, e cada tipo requer suas próprias considerações de recuperação. É fácil entender o que precisa ser copiado; onde a maioria das equipes tem dificuldade é em determinar quais componentes devem ser copiados e por quê. Entender o que precisa ser copiado é a parte fácil – no entanto, a maioria das equipes tem dificuldade em decidir quais componentes devem ter prioridade e por quê.
O que um backup do etcd realmente recupera e o que não recupera?
O etcd é a única fonte de verdade para o estado de todo o seu cluster. Como tal, é o elemento mais importante a ser copiado e, ao mesmo tempo, o componente mais mal compreendido. Um snapshot do etcd permite reverter o estado de todo o seu cluster para um determinado momento, mas se o seu cluster ativo tiver avançado muito além do seu snapshot – você acabará enfrentando inconsistências entre o que o etcd relata como em execução e o que realmente está presente.
Um snapshot do etcd, por si só, é insuficiente para recuperar completamente seu cluster em um cenário de desastre, pois, embora contenha o estado do cluster, ele não contém nenhum dado de aplicativo (que é armazenado em Volumes Persistentes) e não garante que o estado revertido corresponderá ao estado do cluster que você reconstruiu. Os backups no nível do aplicativo são o que fornecem essas informações ausentes, e é importante tratar os snapshots do etcd como complementares aos backups no nível do aplicativo, em vez de um substituto para eles.
É necessário fazer backup de volumes persistentes (PV) e reivindicações de volume persistente (PVC)?
Sim, é necessário fazer backup tanto de PV quanto de PVC, mas a prioridade depende do que exatamente está contido neles. Alguns PVs contêm dados muito mais valiosos do que outros – um PV que fornece persistência para um banco de dados com estado não apresenta o mesmo fator de risco que um PV que armazena conteúdo em cache.
Antes de escolher sua frequência de backup, faz sentido classificar seus PVs por criticidade de recuperação para garantir que sua programação de backup reflita as necessidades de negócios e não dê igual ênfase a todos os volumes.
Quais metadados do cluster (manifestos, RBAC, CRDs, configmaps, segredos) são essenciais?
Todos esses metadados são importantes, mas não no mesmo nível quando se trata de cenários de recuperação sensíveis ao tempo.
Perder a configuração RBAC e os CRDs é a opção mais prejudicial aqui, pois eles definem o que você tem permissão para fazer e o que o restante do cluster utiliza como suas definições de recursos. Sem essas informações, é altamente provável que as aplicações restauradas voltem em um estado inacessível ou danificado.
ConfigMaps e segredos também definem como suas aplicações funcionam e são frequentemente os elementos mais negligenciados em uma estratégia de backup manual. Manifestos também são de grande importância, mas se você tiver um sistema GitOps em vigor – deve ser relativamente simples recuperá-los do controle de código-fonte, o que os coloca um pouco mais abaixo na lista de prioridades.
Como você deve tratar dados efêmeros e logs?
Dados efémeros – qualquer coisa que exista apenas durante o tempo de vida de um pod – geralmente não devem ser copiados, e tentar fazê-lo adiciona complexidade sem oferecer valor significativo para a recuperação.
Logs geralmente estão em uma posição semelhante – eles não devem ser copiados como parte de uma estratégia de backup do Kubernetes. A opção muito melhor é ter um pipeline de observabilidade dedicado que envie esses logs para um armazenamento externo independentemente do processo de backup.
Uma pergunta mais apropriada aqui seria se quaisquer dados que você esteja atualmente considerando efêmeros precisariam persistir. Se precisarem – eles devem ser transferidos para um volume persistente em vez de serem incluídos no escopo do backup.
Como o GitOps afeta sua estratégia de backup do Kubernetes?
GitOps é um modelo operacional em que o repositório Git armazena todo o estado de um ambiente Kubernetes – com todos os manifestos, definições de recursos e configurações. As informações em questão também são continuamente reconciliadas com o cluster ativo com a ajuda de uma ferramenta dedicada. Em vez de aplicar as alterações diretamente ao seu cluster, elas passam primeiro pelo Git — tornando o repositório em questão uma única fonte de verdade sobre como o cluster deve estar em qualquer momento.
Isso rapidamente se tornou um padrão generalizado em ambientes Kubernetes, alterando a equação do backup de maneiras específicas — e as implicações disso nem sempre são simples. É essencial saber onde isso ajuda e onde se limita antes de decidir qual a cobertura de backup a ser sobreposta a isso.
Como o GitOps muda sua abordagem ao backup de configuração?
Se seus manifestos do Kubernetes, configurações de RBAC e definições de recursos estão armazenados no Git e são continuamente reconciliados por uma ferramenta como o ArgoCD ou o Flux – você já possui uma forma de backup de configuração com controle de versão.
Qualquer recurso declarativo que resida em seu repositório Git pode ser reaplicado a um cluster novo ou recuperado sem a necessidade de um backup separado desse recurso. Isso representa uma simplificação significativa no processo de configuração de backup, já que manifestos e descrições de recursos de cluster que já estão sendo gerenciados com o GitOps podem se tornar itens de menor prioridade em sua estratégia de backup dedicada.
O que o GitOps não abrange, e onde os backups dedicados ainda se aplicam?
O GitOps gerencia o estado desejado, não o estado em tempo de execução ou os dados. Assim, os volumes persistentes, os segredos não submetidos ao Git, o conteúdo de bancos de dados e os estados que existem apenas dentro de um cluster em execução são todos invisíveis para ele.
Um cluster inteiramente gerenciado pelo GitOps ainda pode sofrer perda massiva de dados se os volumes persistentes não forem copiados de forma independente. Os segredos são geralmente excluídos explicitamente dos repositórios devido a implicações de segurança, portanto, também requerem cobertura de backup independente.
O GitOps não é uma alternativa a uma estratégia de backup; em vez disso, eles são complementares, e reconhecer a fronteira entre eles ajuda a evitar suposições inseguras sobre o que está coberto.
Práticas recomendadas para operações de backup do Kubernetes
Há uma série de práticas recomendadas que podem ser utilizadas para melhorar o estado geral dos backups do K8s, incluindo resiliência do cluster, segurança dos dados e confiabilidade da recuperação.
Faça backup de dados persistentes e do estado do cluster
O estado do cluster inclui componentes-chave para um ambiente Kubernetes, incluindo segredos, ConfigMaps, etcd e muito mais. Os volumes de dados persistentes representam a maior parte do tamanho dos dados, com arquivos comuns, bancos de dados, dados de usuários, logs, etc.
Configure a automação de backup
A automação de backup reduz a probabilidade de erros humanos e introduz um elemento de consistência e previsibilidade no processo de backup. Inúmeras soluções de backup de terceiros podem oferecer recursos avançados de automação, como a capacidade de planejar agendas de backup levando em conta RTOs e RPOs específicos.
Utilize diferentes tipos de backup sempre que possível
Os dados do Kubernetes podem ser copiados usando diferentes abordagens de backup, se o software permitir. Por exemplo, backups incrementais podem oferecer uma redução significativa no espaço total de armazenamento ocupado, capturando apenas as informações que foram modificadas de alguma forma desde o último backup.
Teste os dados copiados
Os backups em si não se tornam invulneráveis assim que são criados, e existe a possibilidade de que as informações tenham sido de alguma forma corrompidas ou perdidas durante o processo. Realizar processos de restauração de teste regularmente facilita a detecção desses erros e sua resolução antes de qualquer tipo de desastre.
Implemente a criptografia de backup
A criptografia de backup deve ser implementada, quando necessário, para informações em trânsito e em repouso, a fim de garantir o mais alto nível possível de segurança. A criptografia ajuda a proteger os dados contra violações de segurança e acesso não autorizado. Há diversos algoritmos de criptografia à sua escolha, desde que a solução de backup os suporte.
Considere o uso de armazenamento imutável
O uso de estratégias de imutabilidade de dados pode ser um componente importante de uma estratégia de backup. Algumas soluções de backup oferecem imutabilidade por software, enquanto outras fornecem opções de hardware dedicadas, como WORM (write-once-read-many), para proteger as informações contra ameaças cibernéticas.
Lembre-se das políticas de retenção e do controle de versões
O controle de versões é o processo de armazenamento de cópias anteriores de suas informações por motivos de conformidade ou conveniência. Uma política de retenção devidamente configurada deve especificar qual será o período de retenção, a fim de encontrar o equilíbrio entre o consumo de armazenamento e o cumprimento de todos os requisitos necessários.
Verifique se há recursos de backup para múltiplos clusters
Se o seu ambiente atual utiliza múltiplos clusters do Kubernetes, garantir que sua solução de backup ofereça backup centralizado pode ser fundamental. A capacidade de lidar com vários ambientes ao mesmo tempo pode simplificar significativamente o processo de backup e melhorar a conveniência geral de se trabalhar nesse tipo de ambiente.
Implemente um software de backup nativo da nuvem
A compatibilidade com infraestruturas dinâmicas de nuvem é um recurso importante para qualquer solução de backup de Kubernetes competente. Uma razão para isso é que os serviços em evolução oferecidos pela computação em nuvem podem trazer benefícios adicionais de segurança para uma organização. Certificar-se de que o software de backup de sua escolha seja nativo da nuvem e possa se integrar a diferentes serviços de armazenamento em nuvem pode ser fundamental.
Pense cuidadosamente em toda a sua estratégia de recuperação de desastres
As estratégias de backup costumam ser melhores quando projetadas tendo em mente a recuperação de desastres, e o Kubernetes não é exceção. Por exemplo, garantir que os backups possam ser restaurados em diferentes clusters cobriria situações como migração ou falha total do cluster. Alternativamente, o suporte a backups entre nuvens e entre regiões torna possível resolver problemas centrados na nuvem ou interrupções regionais.
Garanta a segurança dos segredos do Kubernetes
Os segredos do Kubernetes incluem muitas informações confidenciais que merecem proteção – senhas, chaves de API, certificados, etc. Esse tipo de informação deve receber a maior prioridade possível quando se trata de segurança de dados, com criptografia completa, imutabilidade de dados e assim por diante.
Tente otimizar o custo do armazenamento de backup
Se possível, geralmente é importante implementar várias técnicas de gerenciamento de armazenamento para reduzir o tamanho total do backup em seu ambiente de armazenamento. A compactação e a deduplicação são igualmente eficazes para isso, mas ambas têm suas próprias desvantagens. O mesmo pode ser dito sobre a maioria das estratégias de economia de armazenamento específicas para a nuvem.
Monitore os processos de backup regularmente
Talvez não seja razoável esperar que alguém fique de olho nos processos de backup automatizados 24 horas por dia, 7 dias por semana. Assim, sistemas dedicados de monitoramento e notificação devem ser implementados para garantir que tudo esteja funcionando sem problemas. A maioria das soluções possui até mesmo uma opção para enviar uma notificação específica a uma pessoa determinada caso alguma irregularidade seja detectada durante o processo de backup.
Implemente backups no nível do namespace para clusters multilocatários
Os ambientes multilocatários mencionados acima podem ser suportados com a ajuda de backups no nível do namespace. Dessa forma, as informações de cada locatário teriam um arquivo de backup separado, limitando a exposição potencial de dados entre locatários e, ao mesmo tempo, oferecendo ampla flexibilidade para os processos de recuperação.
Forneça documentação para todo o pipeline de backup e recuperação
Todo o processo de backup e recuperação deve ser bem documentado, incluindo instruções detalhadas sobre como um backup é configurado, monitorado, verificado e assim por diante. A mesma lógica se aplica aos processos de restauração. Essa documentação também deve abranger as funções e responsabilidades dos funcionários encarregados das tarefas de administração de backup.
Como você deve projetar agendas de backup e políticas de retenção do Kubernetes?
Saber o que fazer backup é apenas metade da batalha. A outra metade é decidir com que frequência fazer backup e por quanto tempo manter os dados armazenados. Agendas de backup e políticas de retenção não vinculadas a um objetivo de recuperação tangível invariavelmente se tornam ou muito agressivas (resultando em desperdício de recursos de armazenamento e computação) ou muito infrequentes (resultando em períodos irrecuperáveis após uma falha).
Com que frequência deve-se fazer backup do etcd, dos PVs e dos dados de aplicativos?
Não é necessário fazer backup de cada componente com a mesma frequência, pois esse é um erro comum. O etcd muda constantemente junto com o estado do cluster, portanto, um snapshot de hora em hora é suficiente na maioria dos ambientes de produção. No entanto, um cluster em rápida mudança, com alta rotatividade nas implantações ou configurações, pode exigir snapshots mais frequentes.
Volumes persistentes que contêm dados transacionais ou gerados pelo usuário devem ter snapshots com frequência pelo menos igual à permitida pelo seu RPO, já que é neles que residem os dados mais significativos do ponto de vista operacional. Backups no nível da aplicação podem ser menos frequentes na maioria dos casos, desde que a própria aplicação tenha um certo grau de tolerância para repetição de eventos ou reconstrução de estado. No entanto, essa tolerância deve ser cuidadosamente validada em relação ao RPO atual antes de ser incorporada à sua programação, em vez de ser tratada como uma suposição segura.
Quais janelas de retenção se alinham aos requisitos de RPO e RTO?
Duas perguntas devem orientar a retenção:
- Até quando no passado você realmente precisa recuperar?
- Com que rapidez você precisa ser capaz de recuperar?
Um RPO baixo não implica retenção longa, portanto, manter 30 dias de snapshots de hora em hora raramente é prático e costuma ser caro. Uma prática recomendada seria usar a retenção em camadas: backups de curta duração e alta frequência para recuperação operacional, combinados com backups de longa duração, mas menos frequentes, para fins de auditoria ou conformidade. O ponto-chave é que as janelas de retenção devem ser explicitamente aprovadas por quem detém o SLA de recuperação, e não decididas unilateralmente pela equipe responsável pelos backups.
Como o ciclo de vida e a hierarquização podem reduzir os custos de backup?
O custo de armazenamento de backup para clusters do Kubernetes pode disparar rapidamente, especialmente ao trabalhar com grandes volumes persistentes ou snapshots frequentes. A implementação de uma política de ciclo de vida ajuda a reduzir drasticamente os custos sem diminuir sua capacidade de recuperação.
As políticas de ciclo de vida arquivam automaticamente os backups em camadas de armazenamento mais baratas à medida que envelhecem — passando do armazenamento em bloco de alto desempenho para o armazenamento de objetos após um determinado período, por exemplo. Isso, no entanto, traz uma desvantagem, já que camadas de armazenamento mais baratas geralmente estão associadas a tempos de recuperação mais longos.
Antes de implementar políticas de ciclo de vida, é importante analisar os tempos de recuperação para cada uma das camadas mais baratas e verificar se isso se alinha ao seu RTO para pontos de recuperação mais antigos. A maioria dos principais provedores de nuvem inclui suporte nativo para políticas de ciclo de vida em suas soluções de armazenamento de objetos; portanto, a implementação dessas políticas deve apresentar pouca ou nenhuma dificuldade na maioria dos casos – uma vez que você tenha determinado seu período de retenção.
Como proteger backups do Kubernetes e atender aos requisitos de conformidade?
Agendar backups é apenas uma peça do quebra-cabeça operacional. Proteger os próprios backups e demonstrar conformidade com a legislação de governança relevante são desafios distintos que muitas vezes são abordados tarde demais no ciclo de vida. O valor intrínseco dos dados de backup — como um panorama completo da infraestrutura — torna-os um alvo atraente, e há um foco crescente nos requisitos de governança sobre eles.
Como os dados de backup devem ser criptografados em repouso e em trânsito?
A decisão arquitetônica crítica neste contexto não se refere realmente a qual algoritmo de criptografia usar (já que a maioria dos produtos de backup atuais tem uma configuração padrão que você deve manter de qualquer maneira), mas sim a garantir que a criptografia seja aplicada de ponta a ponta.
Se os dados em repouso estiverem criptografados, mas o trânsito entre o cluster e o destino de armazenamento não estiver – os dados não estarão seguros durante a transferência. Se as chaves de criptografia forem armazenadas nas proximidades dos dados de backup que estão criptografando – elas provavelmente também estarão inseguras.
As chaves de criptografia devem ser armazenadas separadamente do destino de backup, seja com a ajuda de um serviço de gerenciamento de chaves ou de um módulo de segurança de hardware. O acesso a essas chaves também deve ser administrado apenas por uma entidade que tenha permissão para acessar o próprio backup.
Quem deve ter acesso aos recursos de backup e restauração?
O acesso à restauração é frequentemente equiparado ao acesso ao backup, mas eles têm implicações de risco completamente diferentes. A capacidade de restaurar um backup para um cluster ou namespace potencialmente separado é equivalente a poder realocar dados confidenciais e, portanto, tem um requisito de controle mais elevado do que o necessário para simplesmente criar o próprio backup.
Na prática, a criação de backup pode ser razoavelmente automatizada e amplamente permitida, enquanto as operações de restauração devem exigir autorização explícita – idealmente com um segundo aprovador para ambientes de produção. Essa distinção deve se refletir em sua configuração de RBAC e ser documentada com clareza suficiente para sobreviver a mudanças na equipe.
Quais recursos de auditoria, registro e imutabilidade são necessários para a conformidade?
Além de garantir que os backups existam, as estruturas de conformidade também exigirão que uma empresa possa comprovar sua existência. Cada operação de backup, tentativa de acesso e solicitação de restauração precisará ser auditável e retida de acordo com as necessidades de sua estrutura — o que significa que os registros devem ser gravados de maneira inviolável.
Armazenamento imutável, que impede a exclusão ou modificação de dados de backup por um período específico, está rapidamente se tornando obrigatório, em vez de opcional, em ambientes que gerenciam informações privadas ou financeiras – e a HIPAA e a SOC 2 mencionam especificamente sua necessidade.
Isso também significa que tanto a trilha de auditoria quanto os dados que estão sendo copiados para backup precisam receber a mesma importância: dados cuja conformidade você não pode comprovar oferecem menos valor quando os auditores vierem fazer a verificação.
Metodologia para escolher a melhor solução de backup para Kubernetes
Há um bom número de soluções de terceiros diferentes que oferecem recursos de backup para Kubernetes de uma forma ou de outra. O backup do K8s é uma tarefa muito importante, portanto, a escolha de uma solução de backup é igualmente importante. Assim, podemos oferecer uma metodologia detalhada sobre como escolher a melhor solução de backup para Kubernetes para sua organização específica.
Tipos de dados cobertos pela solução
Verificar se a solução de backup oferece suporte ao tipo de dados necessário é uma prioridade para qualquer empresa ou negócio que busque uma solução de backup para o Kubernetes. Por isso, adicionamos informações sobre os tipos de dados dos quais cada solução da nossa lista pode criar um backup. O resultado geral dessa comparação é apresentado abaixo em uma tabela (a tabela em questão foi dividida em duas partes para facilitar a visualização).
Tabela nº 1
| Software | Kasten | Portworx | Cohesity | OpenEBS | Veritas |
| Desdobramentos | Sim | Sim | Sim | Sim | Sim |
| StatefulSets | Yes | Sim | Sim | Sim | Sim |
| DaemonSets | Sim | Sim | Sim | Sim | Sim |
| Pods | Sim | Sim | Sim | Sim | Sim |
| Serviços | Sim | Sim | Sim | Sim | Sim |
| Secrets e/ou ConfigMaps | Sim | Sim | Sim | Sim | Sim |
| Volumes persistentes | Sim | Sim | Sim | Sem dados | Sim |
| Namespaces | Sim | Sim | Sim | Sem dados | Sim |
| Aplicações | Sim (Integrações) | Sem dados | Sim (Mensagens + Bancos de dados) | Sem dados | Sem dados |
| Infraestrutura de armazenamento | Sem dados | Sem dados | Sim | Sem dados | Sem dados |
Tabela #2
| Software | Stash | Rubrik | Druva | Zerto | Longhorn |
| Desdobramentos | Sim | Sim | Sim | Sim | Sim |
| StatefulSets | Yes | Sim | Sim | Sim | Sim |
| DaemonSets | Sim | Sim | Sim | Sim | Sim |
| Pods | Sim | Sim | Sim | Sim | Sim |
| Serviços | Sim | Sim | Sim | Sim | Sim |
| Secrets e/ou ConfigMaps | Sim | Sim | Sim | Sim | Sim |
| Volumes persistentes | Sim | Sim | Sim | Sim | Sim |
| Namespaces | Sim | Sim | Sim | Sim | Sem dados |
| Aplicações | Sem dados | Sim (Bases de dados) | Sim (Bases de dados) | Sem dados | Sem dados |
| Infraestrutura de armazenamento | Sem dados | Sim | Sem dados | Sem dados | Sem dados |
Note-se que o suporte para diferentes tipos de dados é um fator importante, mas não é um fator decisivo na maioria das vezes, pelo que se recomenda vivamente que o considere como um dos vários factores nesta comparação.
Classificações dos clientes
Estas classificações podem ser interpretadas de muitas formas diferentes – até que ponto a solução é boa no seu trabalho, até que ponto é competente com o feedback dos clientes, até que ponto pode (ou não) evoluir ao longo do tempo, etc. No nosso caso, as classificações dos clientes de sítios Web de terceiros existem para mostrar a competência geral da solução, utilizando vários sítios Web de recolha de avaliações, como o Capterra, o TrustRadius e o G2.
Capterra é uma plataforma agregadora de avaliações que oferece avaliações verificadas, orientações, insights e comparações de soluções. Os seus clientes são cuidadosamente verificados quanto ao facto de serem, de facto, clientes reais da solução em questão, e não existe qualquer opção para os fornecedores removerem as avaliações dos clientes. A Capterra possui mais de 2 milhões de avaliações verificadas em quase mil categorias diferentes, o que a torna uma ótima opção para encontrar todos os tipos de avaliações sobre um produto específico.
TrustRadius é uma plataforma de avaliação que proclama seu compromisso com a verdade. Utiliza um processo de várias etapas para garantir a autenticidade da avaliação, e cada avaliação é também verificada para ser detalhada, profunda e minuciosa pela equipa de investigação da própria empresa. Os fornecedores não têm qualquer possibilidade de ocultar ou eliminar as avaliações dos utilizadores de uma forma ou de outra.
O G2 é outro bom exemplo de uma plataforma agregadora de avaliações que possui mais de 2,4 milhões de avaliações verificadas até o momento, com mais de 100.000 fornecedores diferentes apresentados. O G2 tem o seu próprio sistema de validação para as avaliações dos utilizadores, que se afirma ser extremamente eficaz para provar que cada avaliação é autêntica e genuína. O G2 também oferece serviços separados para fins de marketing, bem como investimento, rastreamento e muito mais.
Caraterísticas principais (bem como vantagens/desvantagens)
A lista de fatores importantes que uma solução de backup Kubernetes competente deve ter inclui o seguinte:
- Alta disponibilidade de dados para melhor recuperação de desastres e maior tolerância a vários problemas com clusters e contêineres.
- Diferentes tipos de backup, incluindo backups incrementais e com reconhecimento de aplicativos.
- Granularidade de backup, com a capacidade de criar backups de objetos específicos, e não apenas de namestates inteiros (volumes, pods, PVs, etc.).
- Programação de backup para operações diárias mais simplistas.
- Integração com fornecedores de armazenamento na nuvem (Azure Blob, GCP, S3, etc.) para um processo de backup mais fácil e mais variedade em termos de armazenamento de backup.
- Capacidades de encriptação de dados para uma melhor proteção das informações.
- O suporte para cargas de trabalho personalizadas permite a possibilidade de ampliar a funcionalidade de backup por meio de plug-ins e integrações.
Isto também é representado pela categoria “vantagens/desvantagens” (se aplicável), que apresenta tanto os aspectos positivos como os negativos da solução, recolhidos a partir de uma grande quantidade de comentários de utilizadores.
Preços
As caraterísticas de uma solução são importantes para o utilizador final, mas a questão do preço é igualmente importante. Algumas empresas têm um orçamento muito limitado e outras necessitam de um conjunto específico de funcionalidades, apesar de um preço potencialmente elevado. No entanto, a maioria dos potenciais clientes situa-se algures entre estes dois exemplos. Recomenda-se vivamente que verifique tanto o preço como o conjunto de funcionalidades da solução, ponderando-os uns contra os outros – mesmo que a solução esteja dentro do seu orçamento, pode não ser um bom negócio por funcionalidade como a concorrência.
Uma opinião pessoal do autor
A única parte completamente subjectiva desta metodologia é a opinião do autor sobre o assunto (solução de backup Kubernetes, no nosso caso). Há muitos casos de uso diferentes para esta categoria em particular, incluindo informações interessantes sobre a solução que não se encaixam em nenhuma das categorias anteriores ou apenas a opinião pessoal do autor sobre este tópico específico.
Mercado de soluções de backup do Kubernetes
No contexto desses três fatores/características importantes, vamos examinar mais alguns exemplos de uma solução de backup e recuperação para o K8s.
Kasten K10

O Kasten K10 (recentemente adquirido pela Veeam) é uma solução de backup e restauração que também se orgulha de seus sistemas de mobilidade e recuperação de desastres. O processo de cópia de segurança com o Kasten é simplificado graças à sua capacidade de descobrir automaticamente aplicações, bem como a muitas outras funcionalidades, como a encriptação de dados, o controlo de acesso baseado em funções e uma interface de fácil utilização. Ao mesmo tempo, pode funcionar com muitos serviços de dados diferentes, como MySQL, PostgreSQL, MongoDB, Cassandra, AWS, etc.
A alta disponibilidade local não está disponível, uma vez que o Kasten não suporta diretamente a replicação dentro de um único cluster e depende dos sistemas de armazenamento de dados subjacentes. A recuperação de desastres também está apenas parcialmente disponível, pois o Kasten não consegue atingir casos de RPO zero devido à falta de um componente de caminho de dados. Também é de salientar o facto de as cópias de segurança da Kasten serem apenas assíncronas, o que normalmente representa um tempo de inatividade adicional entre operações.
Tipos de dados cobertos pelo Kasten K10:
O Kasten K10 pode criar backups de – normalmente – todos os dados que o Kubernetes gera, incluindo Serviços, Implantações, PVs, Namespaces e assim por diante. Existem apenas duas excepções – a cobertura de aplicações do Kasten também pode ser alargada e melhorada através de integrações com outras soluções de cópia de segurança e recuperação.
Classificações dos clientes:
- (Kasten) G2 – 4,7/5 estrelas com base em 10 avaliações de clientes
- (Veeam) Capterra – 4,8/5 estrelas com base em 69avaliações de clientes
- (Veeam) TrustRadius – 8,8/10 estrelas com base em 1.237avaliações de clientes
- (Veeam) G2 – 4,6/5 estrelas com base em 387avaliações de clientes
Principais recursos:
- Escalabilidade e eficiência impressionantes
- Proteção altamente eficaz contra ransomware
- Criado usando princípios de arquitetura nativos da nuvem
Preços (no momento da escrita):
- A página de preços do Kasten K10 afirma que existem três edições do software (embora exista apenas uma edição real, e as outras duas são a versão gratuita e a versão de avaliação, respetivamente)
- “Free” é uma versão muito limitada do Kasten K10 com recursos mínimos de backup do Kubernetes, incluindo até 5 nós no máximo, bem como operações de backup/restauração, recuperação de desastres, proteção contra ransomware e a maioria dos outros recursos do Kasten
- “Enterprise Trial” é a versão da Kasten de um teste gratuito cronometrado, oferecendo o conjunto completo de recursos da Kasten, um limite superior de 50 nós, bem como suporte ao cliente, implantação assistida pela Kasten e avaliação de proteção de dados.
- “Enterprise” é o único nível de assinatura real que o Kasten K10 tem; ele remove completamente a limitação do “número de nós” e oferece o conjunto completo de recursos de backup e recuperação da Kasten.
- É importante notar que não há informações sobre preços disponíveis no site oficial da Kasten, o que significa que a única maneira de receber essas informações é solicitar uma cotação personalizada da empresa em questão.
Minha opinião pessoal sobre o Kasten K10:
O Kasten K10 é uma solução de backup bastante competente que funciona com diversos tipos de ambientes – incluindo Kubernetes, Cassandra, PostgreSQL, MySQL e outros. Recentemente, foi adquirido pela Veeam – uma das soluções de backup de nível empresarial mais conhecidas do mercado. Até o momento, o Kasten conseguiu manter seu nome, apresentando-se como “Kasten by Veeam” na maioria dos casos. Não é uma solução ruim em si, mas seus recursos relacionados ao Kubernetes são bastante básicos e limitados. Ela aplica a maioria de seus recursos gerais aos backups do Kubernetes, como criptografia de dados e RBAC, mas a criação desses backups não é um processo simples. O Kasten não oferece alta disponibilidade local para o Kubernetes, sua implementação de recuperação de desastres é apenas parcial (RPOs diferentes de zero) e todos os backups são estritamente assíncronos.
Portworx

Portworx PX-Backup é uma empresa de gerenciamento de dados que desenvolve uma plataforma de armazenamento baseada em nuvem para gerenciar e acessar o banco de dados para projetos Kubernetes. É outro exemplo de uma solução de gestão de dados e, apesar das suas limitações enquanto tal, um dos principais benefícios da utilização da Portworx é a elevada disponibilidade dos dados.
Operações de backup e recuperação, compreensão de aplicativos Kubernetes, alta disponibilidade local e recuperação de desastres, entre outros recursos – tudo isso torna a Portworx uma boa solução para backup do Kubernetes. Considerando a variedade de soluções de backup do Kubernetes de terceiros, a Portworx também pode ser interessante para um usuário que está procurando especificamente por recursos de backup do Kubernetes.
Outra parte significativa do PX-Backup é sua escalabilidade, permitindo backups sob demanda / backups agendados de centenas de aplicativos ao mesmo tempo. A solução também suporta configurações de vários bancos de dados e pode restaurar aplicativos diretamente para os serviços de nuvem, como Amazon, Google, Microsoft, etc.
Tipos de dados cobertos pela Portworx:
A Portworx suporta a criação de backups para Namespaces, PVs, DaemonSets, Deployments e muito mais. No entanto, não consegui encontrar informações sobre se ela pode ou não suportar backup de aplicativos ou backup de infraestrutura de armazenamento.
Classificações dos clientes:
- G2 – 4.4/5 estrelas com base em 16 avaliações de clientes
Vantagens:
- Solução de backup fiável e de elevado desempenho
- Infraestrutura escalável e fiável
- Criptografia de dados e controlo de acesso detalhado
Cujas deficiências:
- A configuração do software como um todo pode ser um pouco complicada
- A experiência de apoio ao cliente é inconsistente
- As capacidades de segurança são limitadas no contexto de implantações em grandes empresas
Preços (no momento da redação):
- O modelo de preços da Portworx é bastante simples – há uma versão gratuita disponível para todos os usuários que criam uma conta Portworx; essa versão é limitada a 1 cluster e até 1 TB de dados de aplicativos
- Há também uma versão paga do software com um conjunto completo de recursos, incluindo backups com reconhecimento de aplicativos, restauração com um único clique, proteção contra ransomware e assim por diante. Infelizmente, não há preços oficiais disponíveis no site da Portworx; eles só podem ser obtidos entrando em contato diretamente com a empresa para obter uma cotação personalizada.
Minha opinião pessoal sobre a Portworx:
A Portworx promove-se como uma Plataforma de Serviços de Dados, oferecendo muitas capacidades que estão maioritariamente centradas no Kubernetes e nos seus contentores. A plataforma Portworx pode oferecer muitos serviços, incluindo backup, recuperação de desastres, armazenamento, DevOps e banco de dados. Os backups da Portworx oferecem alta disponibilidade, reconhecimento de aplicativos e muitos recursos que geralmente não estão disponíveis nas ofertas de backup do Kubernetes. É uma solução rápida e escalável, mas também tem suas desvantagens. Um exemplo de tal desvantagem é uma presença geral bastante limitada no mercado, o que cria muitos fatores desconfortáveis, como a falta de tutoriais detalhados na Internet. A solução em questão pode também ser bastante complicada, o que torna difícil trabalhar com ela para os recém-chegados a este domínio.
Cohesity

Cohesity é um concorrente relativamente popular no campo de backup e recuperação geral, mas seus recursos relacionados ao Kubernetes ainda têm algum espaço para crescer. Em primeiro lugar, o Kubernetes é uma adição relativamente nova para eles, pois adicionou o entendimento para aplicativos Kubernetes. No entanto, só funciona para todas as aplicações dentro do mesmo namespace, e não é possível proteger aplicações específicas dentro desse mesmo namespace.
Por outro lado, há também recursos de recuperação rápida, backups incrementais de camada de aplicativo com base em políticas, consolidação de estado de dados e muitos outros recursos.
Tipos de dados cobertos pelo Cohesity:
A solução da Cohesity suporta cópias de segurança do Namespace, cópias de segurança do Serviço, cópias de segurança da Implementação e muito mais. Há suporte para backup de Infraestrutura de Armazenamento, e o único fator notável para esta categoria é que o backup de Aplicações da Cohesity também pode cobrir Bases de Dados em que as aplicações estão a trabalhar, bem como sistemas de Mensagens implantados em Kubernetes.
Classificações dos clientes:
- Capterra – 4,6/5 estrelas com base em 48avaliações de clientes
- TrustRadius – 8,9/10 estrelas com base em 59avaliações de clientes
- G2 – 4,4/5 estrelas com base em 45avaliações de clientes
Vantagens:
- Gestão simples e conveniente de backup e recuperação
- Processo de instalação e configuração inicial simples e fácil
- O agendamento fácil com a ajuda da criação de perfis permite mais automação
- Backups incrementais com reconhecimento de aplicativos, recursos de recuperação rápida para aplicativos Kubernetes e muito mais
Cujas deficiências:
- Algumas das atualizações precisam ser instaladas manualmente usando uma linha de comando, o que é um forte contraste com a instalação de atualização automática baseada em GUI
- Os “backups imutáveis” da Cohesity ainda podem ser modificados ou excluídos por um usuário com credenciais de nível de administrador
- O suporte ao cliente depende muito de respostas padrão e pode ser menos do que útil
- O recurso de backup do Kubernetes é relativamente novo para o Cohesity, e pode ser um pouco áspero nas bordas
Preços (no momento da escrita):
- As informações de preços da Cohesity não estão disponíveis publicamente em seu site oficial e a única maneira de obter essas informações é entrando em contato diretamente com a empresa para uma avaliação gratuita ou uma demonstração guiada.
- As informações não oficiais sobre os preços da Cohesity afirmam que apenas os seus aparelhos de hardware têm um preço inicial de $ 110.000 USD
Minha opinião pessoal sobre o Cohesity:
O Cohesity é uma solução sólida de cópia de segurança e recuperação que suporta uma série de tipos de armazenamento diferentes, ao mesmo tempo que oferece muitas funcionalidades. Toda a solução é construída utilizando uma estrutura invulgar semelhante a um nó que torna o Cohesity extremamente fácil de escalar em ambos os sentidos. É rápido, versátil e uma ótima opção para criar backups de infraestruturas de aplicativos. Quanto aos seus recursos relacionados ao Kubernetes especificamente – eles definitivamente poderiam usar algum trabalho no futuro, já que o suporte ao Kubernetes é uma adição relativamente nova ao Cohesity, e algumas nuances ainda estão sendo resolvidas regularmente. Ele só pode proteger dados de aplicativos do mesmo namespace e não há opção para proteger aplicativos específicos, apenas todo o namespace. Ao mesmo tempo, o Cohesity pode oferecer muitos de seus próprios recursos que agora são aplicáveis aos backups do Kubernetes, incluindo consolidação de estado de dados, suporte a backup incremental e muito mais.
OpenEBS

O OpenEBS é outro exemplo de uma solução que conseguiu alcançar alguns resultados com apenas um dos três recursos da nossa lista e, neste caso, trata-se de alta disponibilidade local.
Ao mesmo tempo, o OpenEBS também pode se integrar ao Velero, criando uma solução combinada de Kubernetes que se destaca na migração de dados do Kubernetes. Por si só, o OpenEBS só consegue fazer backup de aplicações individuais (exatamente o oposto do que a Cohesity faz). Há também recursos como armazenamento multicloud, sua natureza de código aberto e uma ampla lista de plataformas Kubernetes compatíveis, desde AWS e Digital Ocean até Minikube, Packet, Vagrant, GCP e muito mais.
No entanto, isso pode não cobrir as necessidades de um usuário, pois alguns usuários podem precisar desses backups de namespace em casos de uso específicos.
Tipos de dados cobertos pelo OpenEBS:
O OpenEBS é uma solução bastante versátil; ele pode criar backups de implantações inteiras, bem como de Pods, ConfigMaps, StatefulSets, etc. No entanto, é bastante limitado em comparação com outros, incluindo a falta de backup da Infraestrutura de Armazenamento, nenhum backup de Aplicativo e a ausência de backups em nível de Namespace e PV.
Caraterísticas principais:
- Usa padrões de Container Attached Storage para melhor eficiência de backup
- Permite que aplicativos com estado tenham acesso rápido e fácil a PVs replicados e PVs locais dinâmicos
- Simplifica o gerenciamento de aplicativos entre nuvens, incluindo replicação de armazenamento e provisionamento automatizado
Preços (no momento da redação):
- O OpenEBS é uma solução gratuita e de código aberto, mas também existem indivíduos e empresas de terceiros que podem fornecer serviços ou produtos relacionados ao OpenEBS de alguma forma.
Minha opinião pessoal sobre o OpenEBS:
O OpenEBS contrasta fortemente com o Cohesity neste aspecto – trata-se de uma solução de gerenciamento de dados relativamente pequena, que se concentra especificamente em ambientes Kubernetes, ao mesmo tempo em que dedica a maior parte de seus recursos à alta disponibilidade de dados local como principal característica. O software em questão pode ser facilmente integrado ao Velero – outro software gratuito e de código aberto de pequena escala que oferece muito mais em termos de backups do Kubernetes. Esse tipo de integração cria uma oferta bastante poderosa (e gratuita) de backup e gerenciamento de dados, totalmente gratuita, que funciona com uma variedade de plataformas Kubernetes, oferece suporte a armazenamento multicloud, fornece recursos de migração de dados e assim por diante. Tal como acontece com praticamente qualquer solução gratuita dessa envergadura, o maior problema do OpenEBS (e do Velero) é uma curva de aprendizagem bastante íngreme, que dificulta a familiarização inicial e aumenta drasticamente o tempo necessário para dominar todas as capacidades da solução.
Veritas

A Veritas é um fornecedor de software de cópia de segurança bem estabelecido que está no mercado há várias décadas; é amplamente preferido por empresas maiores e mais antigas exatamente por essa razão. Ele pode oferecer muitos recursos e capacidades diferentes, ao mesmo tempo que oferece suporte a uma variedade de tipos de armazenamento de destino, desde armazenamento físico a VMs, bancos de dados, armazenamento em nuvem e muito mais. Quanto aos recursos do Kubernetes, a Veritas pode oferecer amplos recursos de registro, administração simples e eficaz, suporte a RBAC, alta disponibilidade de dados, replicação de dados e muitos outros. É uma excelente opção para tarefas de backup e recuperação como um todo, trazendo proteção de dados e riqueza de recursos em um único pacote.
Tipos de dados cobertos pelo Veritas:
Os recursos da Veritas no domínio dos backups do Kubernetes são bastante impressionantes, incluindo cobertura para Namespaces, Implantações, Segredos, Pods e assim por diante. No entanto, ele não tem a capacidade de realizar backups de aplicativos, e o mesmo pode ser dito para backups de infraestrutura de armazenamento.
Classificações dos clientes:
- Capterra – 4,0/5 estrelas com base em 7avaliações de clientes
- TrustRadius – 6,8/10 estrelas com base em 150avaliações de clientes
- G2 – 4,1/5 estrelas com base em 230avaliações de clientes
Vantagens:
- Um conjunto de recursos extremamente amplo e variado, frequentemente considerado um dos maiores pacotes de recursos do mercado.
- Um estado visual relativamente desatualizado da interface não altera o facto de ser fácil de trabalhar para todos os tipos de clientes, incluindo os recém-chegados a este campo.
- A experiência de apoio ao cliente reuniu muitas críticas positivas ao longo dos anos, com a equipa de apoio a fornecer respostas rápidas e concisas a uma grande variedade de questões.
Deficiências:
- O sistema de gestão de relatórios é algo rígido, não há forma de personalizar o caminho do ficheiro de destino para os relatórios criados automaticamente.
- A integração da biblioteca de fitas LTO está disponível até certo ponto, mas funciona com várias falhas graves até o momento.
- A exportação de relatórios como um todo é bastante difícil de executar.
Preços (no momento da escrita):
- Não há informações oficiais sobre preços que possam ser encontradas no site da Veritas, a única maneira de obter essas informações é entrar em contato diretamente com a própria empresa.
Minha opinião pessoal sobre a Veritas:
A Veritas é frequentemente elogiada como uma das soluções de cópia de segurança e recuperação mais antigas do mercado, que ainda está em forma e a competir com outras soluções importantes. Isso não quer dizer que a idade seja a única vantagem que a Veritas pode oferecer – tem também um conjunto de funcionalidades extremamente vasto, uma interface impressionantemente fácil de utilizar e uma equipa de apoio ao cliente extremamente prestável. A Veritas também consegue simplificar e melhorar muito vários aspectos do gerenciamento de contêineres Kubernetes – incluindo recursos de backup e recuperação de dados de contêineres, failover e failback automáticos, distribuição de tráfego entre instâncias, descoberta automática de namespace e muito mais. A Veritas oferece operações de backup e recuperação fáceis e acessíveis para aplicativos em contêineres, tornando-a uma solução de backup do Kubernetes bastante conveniente. A Veritas tem alguns problemas com seu sistema de relatórios como um todo, e sua integração de fita LTO é bastante problemática, mas nenhum desses problemas afeta os recursos relacionados ao Kubernetes o suficiente para ser um problema real para usuários existentes e futuros. No geral, o preço pode ser uma barreira.
Stash

Stash é uma solução de backup e recuperação de desastres que foi construída especificamente para o Kubernetes em primeiro lugar. Ele pode restaurar dados do Kubernetes em vários níveis diferentes, incluindo bancos de dados (MongoDB, MySQL, PostgreSQL), volumes (conjuntos com estado, implantações, volumes autônomos) e até mesmo recursos regulares do Kubernetes (segredos, configurações YAML, etc.). Ele suporta uma série de opções de automação, pode ser integrado a vários provedores de armazenamento em nuvem, suporta cargas de trabalho personalizadas e muito mais. É também uma solução relativamente nova neste campo, por isso tem algumas dores de crescimento aqui e ali.
Tipos de dados cobertos pelo Stash:
Stash é uma solução de backup relativamente pequena, mas sua cobertura Kubernetes ainda é bastante impressionante – com suporte para implantações, serviços, pods, DaemonSets e até mesmo backups de infraestrutura de armazenamento. No entanto, ele não pode criar cópias do Kubernetes no nível do namespace, e também não há suporte para backup de aplicativos.
Caraterísticas principais:
- O suporte para a funcionalidade CSI VolumeSnapshotter permite que as opções de backup do Kubernetes do Stash sejam expandidas de forma bastante significativa.
- A capacidade de ser integrado com a ferramenta Restic traz recursos como deduplicação, criptografia, backups incrementais e muito mais.
- Stash pode trabalhar com vários provedores de armazenamento em nuvem como armazenamento de backup – Azure Blob, GCP, AWS S3, etc.
- Existem muitas opções de agendamento disponíveis, todas as quais podem ser personalizadas de várias maneiras.
Preços (no momento da escrita):
- Não há informações oficiais sobre preços disponíveis no site do Stash, mas há um prompt “entre em contato conosco”, o que significa que todas as informações sobre preços são altamente personalizadas e não podem ser obtidas por meios públicos.
Minha opinião pessoal sobre Stash:
O Stash talvez seja a solução de backup menos conhecida desta lista. É uma solução de backup e recuperação de desastres em escala muito pequena para o Kubernetes especificamente e nada mais. O Stash pode trabalhar com recursos, volumes e até bancos de dados do Kubernetes, oferecendo a capacidade de criar backups de muitos ambientes e tipos de dados – de MongoDB e PostgreSQL a configurações YAML de implantações. É uma solução rápida com muitos recursos centrados no Kubernetes que são uma raridade em outras soluções de backup. Por exemplo, o Stash suporta a funcionalidade CSI VolumeSnapshotter, e também pode ser integrado com a ferramenta Restic para operações de proteção de dados melhores e mais versáteis. Ainda está em desenvolvimento, mas mostra-se bastante promissor para o futuro, e a complexidade geral da solução é provavelmente o maior problema neste momento – um problema que pode ser corrigido com tempo e esforço.
Rubrik

Muitos outros intervenientes maiores no campo do backup e da recuperação começaram a oferecer os seus próprios serviços em termos de backup e restauro do Kubernetes – o Rubrik é um bom exemplo: permite aos utilizadores implementar o vasto conjunto de funcionalidades de gestão do Rubrik no campo das implementações do Kubernetes.
Permite flexibilidade em termos de destino de restauro, bem como a proteção de objectos Kubernetes e uma plataforma unificada que fornece informações e uma visão geral de todo o sistema. Há também recursos como automatização de backup, recuperação granular, replicação de snapshot e muito mais. O Rubrik também pode trabalhar com Volumes Persistentes e é capaz de replicar namespaces – oferecendo-lhe variação quando se trata de desenvolvimento e teste antes da implementação.
Tipos de dados cobertos pelo Rubrik:
Rubrik é uma das melhores opções nesta lista quando se trata de todos os tipos de dados do Kubernetes, ele pode criar um backup. Isso inclui implantações, namespaces, infraestrutura de armazenamento, serviços, pods, statefulSets e praticamente tudo o mais. O único fator que vale a pena referir aqui é que o Druva pode abranger tanto as Aplicações como as Bases de Dados em que são utilizadas.
Classificações dos clientes:
- Capterra – 4,7/5 estrelas com base em 45avaliações de clientes
- TrustRadius – 9.1/10 estrelas com base em 198avaliações de clientes
- G2 – 4,6/5 estrelas com base em 59avaliações de clientes
Vantagens:
- Uma solução versátil de backup e recuperação com alto desempenho
- Uma variedade de integrações com outros serviços e tecnologias, como SQL Server, VMware, M365, etc.
- Capacidades confiáveis de proteção de dados com boa criptografia, segurança forte e ransomware
- Suporta muitos recursos para aplicativos Kubernetes, incluindo replicação de instantâneos, automação de backup, recuperação granular e muitos outros
Cujas deficiências:
- A implementação do RBAC é um tanto básica e carece de muitos dos recursos necessários que os concorrentes têm
- Personalização de auditoria/relatórios muito limitada e não há detalhes suficientes nos relatórios, em geral
- O custo global da solução pode ser demasiado elevado para empresas e negócios de pequena ou média dimensão
- Escalabilidade limitada
Preços (no momento da redação):
- As informações de preços da Rubrik não estão disponíveis publicamente no seu site oficial e a única forma de obter essas informações é contactando diretamente a empresa para uma demonstração personalizada ou uma das visitas guiadas.
- A informações não oficiais afirmam que existem vários dispositivos de hardware diferentes que a Rubrik pode oferecer, como:
- Nó Rubrik R334 – a partir de US$ 100.000para um nó de 3 nós com processos Intel de 8 núcleos, 36 TB de armazenamento, etc.
- Nó Rubrik R344 – a partir de $200.000 para um nó de 4 nós com parâmetros semelhantes ao R334, 48 TB de armazenamento, etc.
- Nó da série Rubrik R500 – a partir de $ 115.000 para um nó de 4 nós com processadores Intel de 8 núcleos, memória DIMM 8×16, etc.
Minha opinião pessoal sobre o Rubrik:
Os recursos do Rubrik em termos de Kubernetes especificamente podem não ser particularmente extensos, mas a solução em si é bem conhecida e respeitada no setor, fornecendo uma plataforma sofisticada de backup e recuperação com um grande número de recursos. O Rubrik pode oferecer proteção, migração de dados e suporte geral para instâncias do Kubernetes, principalmente expandindo seus próprios recursos existentes para cobrir ambientes do Kubernetes. O Rubrik pode replicar namespaces e trabalhar com Volumes Persistentes, tornando-o uma oferta bastante interessante a ser considerada por empresas maiores. No entanto, seria justo mencionar que o Rubrik tem a sua quota-parte de desvantagens que ainda não foram corrigidas, incluindo uma escalabilidade algo básica, um sistema de relatórios/auditoria rígido e um preço bastante elevado no seu todo.
Druva

Outra variação de tal solução é apresentada pelo Druva, fornecendo uma solução de backup e restauração Kubernetes bastante simples, mas eficaz, com todos os recursos básicos esperados – instantâneos, backup e restauração, automatização e algumas funcionalidades adicionais. O Druva também pode restaurar aplicações inteiras dentro do Kubernetes, com muita mobilidade quando se trata do destino da restauração.
Além disso, o Druva suporta várias funções de administrador, pode criar cópias de cargas de trabalho para fins de solução de problemas e pode fazer backup de áreas específicas, como namespaces ou grupos de aplicativos. Há também uma variedade de opções de retenção, proteção de dados Kubernetes abrangente e suporte para Amazon EC2 e EKS (cargas de trabalho de contentores personalizadas).
Tipos de dados cobertos pelo Druva:
Não há informações sobre se o Druva suporta backups da Infraestrutura de Armazenamento do Kubernetes. Para além disso, suporta praticamente tudo o resto – Namespaces, Pods, DaemonSets, StatefulSets, ConfigMaps e até Volumes Persistentes. Também pode abranger aplicações e bases de dados associadas a essas aplicações.
Classificações dos clientes:
- Capterra – 4,7/5 estrelas com base em 17avaliações de clientes
- TrustRadius – 9,3/10 estrelas com base em 419avaliações de clientes
- G2 – 4,6/5 estrelas com base em 416avaliações de clientes
Vantagens:
- A GUI, como um todo, recebe muitos elogios.
- A imutabilidade do backup e a encriptação de dados são apenas exemplos de como o Druva leva a sério a segurança dos dados.
- O suporte ao cliente é rápido e útil.
- Proteção de dados, snapshots, backups automatizados e outros recursos para aplicativos Kubernetes.
Cujas deficiências:
- A primeira configuração não é fácil de ser realizada por você mesmo.
- Os instantâneos do Windows e os backups de cluster SQL são simplistas e pouco personalizáveis.
- Lenta velocidade de restauração a partir da nuvem.
- A escalabilidade pode ser limitada.
Preços (no momento da redação):
- Os preços da Druva são bastante sofisticados e oferecem planos de preços diferentes, dependendo do tipo de dispositivo ou aplicativo que é coberto.
- Cargas de trabalho híbridas:
- “Hybrid business” – $210 por mês por Terabyte de dados após a desduplicação, oferecendo um backup empresarial fácil com muitos recursos, como desduplicação global, recuperação em nível de arquivo VM, suporte de armazenamento NAS, etc.
- “Hybrid enterprise” – $240 por mês por Terabyte de dados após a desduplicação, uma extensão da oferta anterior com funcionalidades LTR (retenção a longo prazo), informações/recomendações de armazenamento, cache na nuvem, etc.
- “Hybrid elite” – $300 por mês por Terabyte de dados após a desduplicação, adiciona a recuperação de desastres na nuvem ao pacote anterior, criando a solução definitiva para gestão de dados e recuperação de desastres
- Existem também funcionalidades que a Druva vende separadamente, como a recuperação acelerada de ransomware, a recuperação de desastres na nuvem (disponível para utilizadores Hybrid elite), postura de segurança & observabilidade e implementação para a nuvem do governo dos EUA
- Aplicações SaaS:
- “Business” – $2,5por mês por utilizador, o pacote mais básico de cobertura de aplicações SaaS (Microsoft 365 e Google Workspace, o preço é calculado por aplicação única), pode oferecer 5 regiões de armazenamento, 10 GB de armazenamento por utilizador, bem como proteção de dados básica
- “Enterprise” – $4por mês por utilizador para cobertura do Microsoft 365 ou do Google Workspace com funcionalidades como grupos e pastas públicas, bem como cobertura do Salesforce.com por $3,5 por mês por utilizador (inclui restauro de metadados, cópias de segurança automatizadas, ferramentas de comparação, etc.)
- “Elite” – US$ 7por mês por usuário para Microsoft 365/Google Workspace, US$ 5,25 para Salesforce, inclui verificação de conformidade com GDPR, habilitação de eDiscovery, pesquisa federada, suporte GCC High e muitos outros recursos
- Alguns recursos aqui também podem ser adquiridos separadamente, como propagação de Sandbox (Salesforce), governança de dados confidenciais (Google Workspace & Microsoft 365), suporte GovCloud (Microsoft 365), etc.
- Endpoints:
- “Enterprise” – $ 8por mês por usuário, pode oferecer suporte a SSO, CloudCache, suporte a DLP, proteção de dados por fonte de dados e 50 GB de armazenamento por usuário com administração delegada.
- “Elite” – $10por mês por usuário, adiciona recursos como pesquisa federada, coleta adicional de dados, exclusão defensável, recursos avançados de implantação e muito mais.
- Também há muitos recursos que podem ser adquiridos separadamente aqui, incluindo recursos avançados de implantação (disponíveis na camada de assinatura Elite), recuperação/resposta a ransomware, governança de dados confidenciais e suporte ao GovCloud.
- Cargas de trabalho do AWS:
- “Freemium” é uma oferta gratuita da Druva para cobertura de carga de trabalho da AWS; pode cobrir até 20 recursos da AWS de uma só vez (não mais do que 2 contas), oferecendo recursos como clonagem de VPC, DR entre regiões e entre contas, recuperação em nível de arquivo, integração de organizações da AWS, acesso à API, etc.
- “Enterprise” – $ 7por mês por recurso, a partir de 20 recursos, tem um limite superior de 25 contas e amplia os recursos da versão anterior com recursos como bloqueio de dados, pesquisa em nível de arquivo, capacidade de importar backups existentes, capacidade de impedir a exclusão manual, suporte 24 horas por dia, 7 dias por semana, com tempo máximo de resposta de 4 horas, etc.
- “Elite” – $ 9 por mês por recurso, não tem limitações de recursos ou contas gerenciadas, adiciona autoproteção por VPC, conta AWS, bem como suporte GovCloud, e menos de 1 hora de tempo de resposta de suporte garantido por SLA.
- Os utilizadores dos planos de preços Enterprise e Elite também podem adquirir a capacidade do Druva para guardar backups EC2 air-gapped no Druva Cloud por um preço adicional.
- É fácil ver como alguém pode ficar confuso com o esquema de preços do Druva como um todo. Felizmente, o próprio Druva tem uma página web dedicada com o único objetivo de criar uma estimativa personalizada do TCO de uma empresa com o Druva em apenas alguns minutos (uma calculadora de preços).
Minha opinião pessoal sobre o Druva:
O Druva oferece uma solução de backup e recuperação nativa da nuvem e sensível a aplicativos que resolve um dos problemas mais comuns do Kubernetes – o fato de que o cluster com falha é sempre restaurado em um estado em branco após falhar por algum motivo. O software em si é fornecido usando um modelo Storage-as-a-Service e é bastante competente na proteção de ambientes Kubernetes (bem como de muitos outros tipos de armazenamento). O Druva pode fazer backup de dados, restaurar dados, automatizar uma série de tarefas, criar backups de aplicativos específicos e fazer backup de áreas específicas (grupos de aplicativos ou namespaces, por exemplo). A solução também suporta EKS e Amazon EC2, o que a torna bastante diferente nesta lista – e no mercado em geral. Druva tem alguns problemas com ele, incluindo um processo de configuração inicial bastante complicado e um desempenho bastante lento quando se trata de recuperar backups do armazenamento em nuvem, mas a solução geral é bastante capaz, especialmente para ambientes Kubernetes.
Zerto

Zerto também é uma boa escolha se você estiver procurando por uma plataforma de gerenciamento de backup multifuncional com suporte nativo para Kubernetes. Ele oferece tudo o que você deseja de uma solução moderna de backup e restauração do Kubernetes – CDP (proteção contínua de dados), replicação de dados por meio de instantâneos e bloqueio mínimo de fornecedor, graças ao suporte do Zerto a todas as plataformas Kubernetes no campo empresarial.
A Zerto também oferece proteção de dados como uma das principais estratégias desde o primeiro dia, oferecendo às aplicações a capacidade de serem geradas com proteção desde o início. A Zerto também possui muitos recursos de automação, é capaz de fornecer informações abrangentes e pode trabalhar com diferentes armazenamentos em nuvem ao mesmo tempo.
Tipos de dados cobertos pela Zerto:
A posição da Zerto em termos de cobertura de dados Kubernetes é simples – não pode trabalhar com Aplicações ou Infra-estruturas de Armazenamento, mas tudo o resto pode ser copiado sem qualquer problema – sejam Implementações, Namespaces, Serviços, Pods, etc.
Classificações dos clientes:
- Capterra – 4,8/5 estrelas com base em 25avaliações de clientes
- TrustRadius – 8,6/10 estrelas com base em 113avaliações de clientes
- G2 – 4,6/5 estrelas com base em 73avaliações de clientes
Vantagens:
- Simplicidade de gerenciamento para tarefas de recuperação de desastres
- Facilidade de integração com infraestruturas existentes, tanto no local como na nuvem
- Capacidades de migração de carga de trabalho e muitos outros recursos
- Os recursos do Kubernetes da Zerto também são bastante vastos e variados, incluindo proteção contínua de dados, replicação de instantâneos e muito mais
Cujas deficiências:
- Só pode ser implantado em sistemas operacionais Windows
- Os recursos de relatório são um pouco rígidos
- Pode ser bastante dispendioso para grandes empresas e negócios
Preços (no momento da redação):
- O site oficial da Zerto oferece três categorias de licenciamento diferentes – Zerto para VMs, Zerto para SaaS e Zerto para Kubernetes
- O licenciamento da Zerto para Kubernetes especificamente pode ser adquirido de duas formas diferentes
- “Zerto Data Protection” é um software de proteção de dados que oferece recursos de backup e recuperação contínuos em todo o ciclo de vida de implantação de aplicativos, inclui retenção de longo prazo, clonagem, replicação local, backups orquestrados e muito mais
- “Enterprise Cloud Edition” é uma versão baseada na nuvem da oferta anterior que também oferece backup e recuperação contínuos durante todo o ciclo de vida de desenvolvimento de aplicativos, expande o conjunto de recursos existentes com recursos como recuperação de desastres orquestrada e replicação remota sempre ativa
- Não há informações oficiais sobre preços disponíveis para a solução da Zerto, ela só pode ser adquirida por meio de uma cotação personalizada ou comprada por meio de um dos parceiros de vendas da Zerto
Minha opinião pessoal sobre a Zerto:
A Zerto como solução de backup é uma boa opção para vários casos de uso ao mesmo tempo – é uma plataforma abrangente que suporta uma variedade de tipos de armazenamento diferentes. A Zerto pode trabalhar com Azure, AWS e Google Cloud como fornecedores de armazenamento na nuvem; suporta cobertura de VM, cobertura de contentores e muitos outros casos de utilização. Ele pode oferecer proteção de dados como um de seus maiores e mais abrangentes recursos, e há muitas opções para ambientes Kubernetes especificamente – seja um bloqueio mínimo de fornecedor, recursos de replicação de dados, suporte a CDP e muito mais. Alguns recursos do Zerto também são aplicáveis a todos os diferentes tipos de armazenamento ao mesmo tempo, seja a análise de dados com insights abrangentes, muitas opções de automação, etc.
Longhorn

O Longhorn é provavelmente a menos conhecida das soluções discutidas neste blogue. Sua comunidade é relativamente pequena para uma solução de código aberto e não permite backups completos do Kubernetes com metadados e recursos para fazer a recuperação com reconhecimento de aplicativos. No entanto, há um recurso exclusivo sobre ele que se destaca e é chamado DR Volume. O DR Volume pode ser configurado como uma fonte e um destino, tornando o volume ativo em um novo cluster que é baseado nos dados de backup mais recentes.
Os recursos do Longhorn para trabalhar com muitos tipos diferentes de plataformas de contêineres e permitir diferentes métodos de backup são o que o diferencia do resto, e já existe uma capacidade de oferecer suporte ao Kubernetes Engine, implantações do Docker e distribuições K3. Os contentores Docker, por exemplo, têm de criar um tarball que pode funcionar como uma cópia de segurança para o Longhorn.
Tipos de dados cobertos pelo Longhorn:
Para uma solução gratuita, o Longhorn pode oferecer um grande pacote de cobertura de tipos de dados aos seus utilizadores – incluindo backups para Deployments, StatefulSets, Services, Secrets, Pods e muito mais. Ele não tem a capacidade de fazer backup de Namespaces, Aplicativos ou Infraestrutura de Armazenamento.
Classificações dos clientes:
- Capterra – 4,3/5 estrelas com base em 6avaliações de clientes
- G2 – 4,8/5 estrelas com base em 3 avaliações de clientes
Caraterísticas principais:
- Solução independente de infraestrutura
- Processo de implantação fácil
- Painel de controlo conveniente e útil
- Personalização simples para políticas de backup e recuperação de desastres
Preços (no momento da redação):
- Longhorn é uma solução de backup Kubernetes gratuita e de código aberto que foi originalmente desenvolvida pela Rancher Labs, mas foi posteriormente doada à CNCF (Cloud Native Computing Foundation) e agora é considerada um projeto sandbox independente.
- O próprio Rancher tem um nível de preço premium separado chamado Rancher Prime – ele oferece uma variedade de recursos para expandir e melhorar a funcionalidade do Rancher original, mas seu preço não está disponível publicamente no site oficial.
Minha opinião pessoal sobre o Longhorn:
Semelhante a uma série de exemplos anteriores, o Longhorn não oferece cobertura completa do Kubernetes – o que significa que não haveria backups com reconhecimento de aplicativos. Ao mesmo tempo, é uma opção interessante para empresas de pequena escala e empresas com um orçamento limitado – considerando que o Longhorn é gratuito, suporta uma série de variantes de contentores e até mesmo vários métodos de backup. O Longhorn também pode oferecer a sua própria funcionalidade invulgar chamada Volume DR – um volume que pode ser definido como destino e origem, tornando-o imediatamente ativo no cluster que foi recentemente criado utilizando os dados de cópia de segurança existentes. É também relativamente simples para uma solução gratuita e de código aberto, embora seja de esperar algum grau de curva de aprendizagem.
Velero.io

Velero é uma solução de backup e recuperação de Kubernetes de código aberto com recursos de migração. Ele suporta snapshots para volumes persistentes e estados de cluster, tornando possível a migração e a restauração em diferentes ambientes. É uma solução bem conhecida na esfera de backup do Kubernetes, oferecendo recursos confiáveis de recuperação de desastres para clusters do Kubernetes, juntamente com migração de cluster, retenção de longo prazo para fins de conformidade e muito mais.
Caraterísticas principais:
- Migração de cluster com diferentes configurações.
- Proteção em todo o cluster e granularidade nos processos de backup.
- Capacidades extensivas de recuperação de desastres para fins de continuidade dos negócios.
- Programação de backup com muitas opções de escolha.
- Integração com a API para criar instantâneos de volume persistentes para grandes conjuntos de dados.
- Suporte para vários provedores de armazenamento em nuvem, incluindo Azure Blob, Google Cloud, AWS S3, etc.
Preços (no momento da escrita):
- Velero.io é uma ferramenta totalmente gratuita e de código aberto, sem preço associado ao software.
Minha opinião pessoal sobre o Velero.io:
O Velero é uma opção interessante para tarefas de backup e recuperação em ambientes Kubernetes, considerando que é gratuito e pode oferecer ampla granularidade em seus recursos. Ele suporta diferentes provedores de armazenamento, pode ser integrado à API da plataforma para snapshots persistentes e, em geral, é uma solução surpreendentemente conveniente para muitas situações. Não é particularmente utilizável na maioria dos casos de uso de nível empresarial devido ao grande escopo das operações necessárias, e a falta dos recursos de segurança mais populares, como criptografia, tornaria difícil trabalhar com empresas que lidam com informações confidenciais, mas a solução geral ainda vale a pena olhar, no mínimo.
Que lista de verificação as equipes devem seguir para garantir a prontidão do backup do Kubernetes?
Ter a estratégia de recuperação no papel não é o mesmo que tê-la pronta para ser executada. Deixe que esta lista de verificação o ajude a garantir que as decisões e configurações estabelecidas neste documento sejam implementadas de forma concreta e verificável.
O senhor já inventariou as cargas de trabalho críticas e os escopos de dados?
Antes de mais nada, o senhor precisa saber exatamente o que está protegendo. Sem um inventário claro, as políticas de backup tendem a ser muito amplas ou cheias de lacunas.
- Todos os namespaces e cargas de trabalho estão documentados e classificados por criticidade
- Os volumes persistentes estão categorizados por prioridade de recuperação
- Os recursos personalizados e CRDs associados a cada carga de trabalho estão identificados
- As aplicações com estado são diferenciadas das sem estado no seu inventário
- A propriedade dos dados é atribuída para cada carga de trabalho crítica
As políticas de RPO, RTO e retenção estão documentadas e aprovadas?
Requisitos de recuperação que não foram formalmente acordados tendem a mudar sob pressão. Estes devem ser definidos antes de um incidente, não negociados durante ele.
- As metas de RPO e RTO estão definidas para cada camada de carga de trabalho
- A frequência de backup para etcd, PVs e dados de aplicativos reflete essas metas
- As janelas de retenção estão documentadas e aprovadas por quem detém o SLA de recuperação
- Políticas de ciclo de vida e hierarquização estão em vigor para dados de backup mais antigos
- As políticas são revisadas e reaprovadas após qualquer mudança significativa na infraestrutura
O monitoramento, os alertas e o controle de acesso para backups estão em vigor?
Um processo de backup que é executado silenciosamente e falha silenciosamente oferece falsa confiança. Os controles operacionais precisam ser tão robustos quanto o próprio processo de backup.
- As tarefas de backup são monitoradas e as falhas acionam alertas para as pessoas certas
- O acesso ao backup e à restauração é separado na configuração RBAC
- As operações de restauração exigem autorização explícita para ambientes de produção
- A criptografia é aplicada de forma consistente em todo o pipeline de backup
- O gerenciamento de chaves é tratado independentemente do armazenamento de backup
Você possui manuais de procedimentos testados e comprovados para cenários comuns de restauração?
Documentação que não foi testada é uma hipótese, não um runbook. Testes regulares são o que transformam um plano de recuperação em uma capacidade de recuperação.
- Existem runbooks pelo menos para os cenários de restauração mais comuns: namespace único, cluster completo e recuperação do etcd
- Os procedimentos de restauração foram testados de ponta a ponta em um ambiente que não seja de produção
- O tempo de recuperação de cada cenário foi medido em relação ao seu RTO
- Os runbooks são controlados por versão e revisados após cada teste ou incidente
- A responsabilidade por cada runbook é atribuída e está atualizada
A solução de backup para K8s da Bacula Enterprise
A própria natureza dos ambientes Kubernetes os torna ao mesmo tempo muito dinâmicos e potencialmente complexos. Fazer backup de um cluster Kubernetes não deve aumentar desnecessariamente a complexidade. E, é claro, geralmente é importante — se não essencial — que os administradores de sistemas e outros profissionais de TI tenham controle centralizado sobre todo o sistema de backup e recuperação da organização, incluindo quaisquer ambientes Kubernetes. Dessa forma, fatores como conformidade, gerenciabilidade, velocidade, eficiência e continuidade dos negócios tornam-se muito mais viáveis. Ao mesmo tempo, a abordagem ágil das equipes de desenvolvimento não deve ser comprometida de forma alguma.
O Bacula Enterprise é único neste contexto porque é uma solução empresarial abrangente para ambientes de TI completos (não apenas Kubernetes) que também oferece backup e recuperação do Kubernetes integrados nativamente, incluindo múltiplos clusters, independentemente de as aplicações ou os dados residirem fora ou dentro de um cluster específico. O Bacula traz consigo outras vantagens, na medida em que é especialmente seguro, protegido e estável. Essas qualidades tornam-se críticas no contexto de organizações que precisam garantir os mais altos níveis possíveis de segurança.
Recuperação de Clusters
O Departamento de Operações de toda empresa reconhece a necessidade de ter uma estratégia de recuperação adequada quando se trata de recuperação de clusters, atualizações e outras situações. Um cluster que se encontra em um estado irrecuperável pode ser revertido para o estado estável com o Bacula, desde que tanto os arquivos de configuração quanto os volumes persistentes do cluster tenham sido corretamente copiados de segurança com antecedência.
Outra forma de mostrar os métodos de trabalho do Bacula é através da figura abaixo:
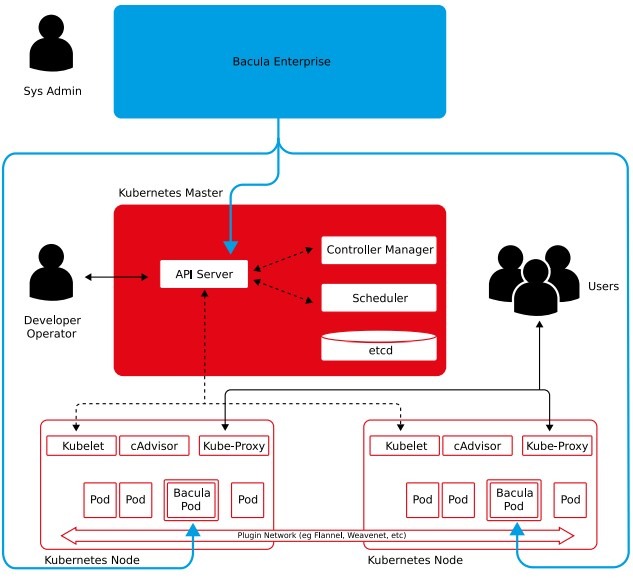
Uma das principais vantagens do módulo Kubernetes do Bacula é a capacidade de fazer backup de vários recursos do Kubernetes, incluindo:
- Pods;
- Serviços;
- Desdobramentos;
- Volumes persistentes.
Caraterísticas do módulo Kubernetes do Bacula Enterprise
A maneira como este módulo funciona é que a solução em si não faz parte do ambiente Kubernetes, mas acessa os dados relevantes dentro do cluster por meio de pods Bacula que são anexados a nós Kubernetes únicos em um cluster. A implantação desses pods é automática e funciona em uma base “conforme necessário”.
Outras funcionalidades oferecidas pelo módulo de backup do K8s incluem ainda o seguinte:
- Backup e restauração do Kubernetes para volumes persistentes;
- Restauração de um único recurso de configuração do Kubernetes;
- A capacidade de restaurar arquivos de configuração e/ou dados de volumes persistentes para o diretório local;
- A capacidade de fazer backup da configuração de recursos de clusters do Kubernetes.
Também vale a pena notar que o Bacula suporta prontamente várias plataformas de armazenamento em nuvem simultaneamente, incluindo AWS, Google, Glacier, Oracle Cloud, Azure e muitos outros, no nível de integração nativa. Os recursos de nuvem híbrida são, portanto, incorporados, incluindo gerenciamento avançado de nuvem e recursos de cache de nuvem automatizados, permitindo a fácil integração de serviços de nuvem pública ou privada para suportar várias tarefas.
A flexibilidade da solução é particularmente importante hoje em dia, com muitas empresas e empresas a tornarem-se cada vez mais complexas em termos de diferentes famílias de hipervisores e contentores. Ao mesmo tempo, isso aumenta significativamente a demanda por flexibilidade de fornecedores para todos os fornecedores de banco de dados. As capacidades do Bacula nesse sentido são substancialmente altas, combinando sua ampla lista de compatibilidade com várias tecnologias para atingir padrões de flexibilidade especialmente altos sem se prender a um único fornecedor.
A complexidade cada vez maior dos diferentes aspectos do trabalho de qualquer organização está sempre a aumentar, e na maioria das vezes é mais fácil e mais rentável usar uma solução para todo o ambiente de TI, e não várias soluções ao mesmo tempo. O Bacula foi concebido para fazer exatamente isso, e também é capaz de fornecer tanto uma interface tradicional baseada na web para as suas necessidades de configuração, bem como o tipo de controlo clássico de linha de comando. Essas duas interfaces podem até ser usadas simultaneamente.
O plugin de backup Kubernetes do Bacula permite dois tipos principais de destino para operações de restauração:
- Restore para um diretório local;
- Restore para um cluster.
Backups regulares e / ou automatizados são altamente recomendados para garantir o melhor ambiente de backup e recuperação possível para contêineres. Testar os backups de tempos em tempos também deve ser obrigatório para o administrador do sistema. Na imagem seguinte, verá uma parte do processo de restauro, nomeadamente a parte Restore Selection (Seleção de restauro), na qual pode escolher os ficheiros e/ou diretórios que pretende restaurar:
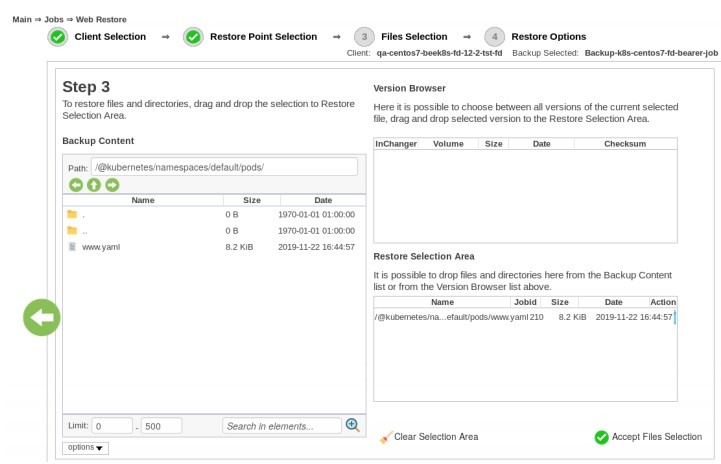
Outra parte do processo de restauro que irá encontrar é a página de opções avançadas de restauro, que tem o seguinte aspeto:
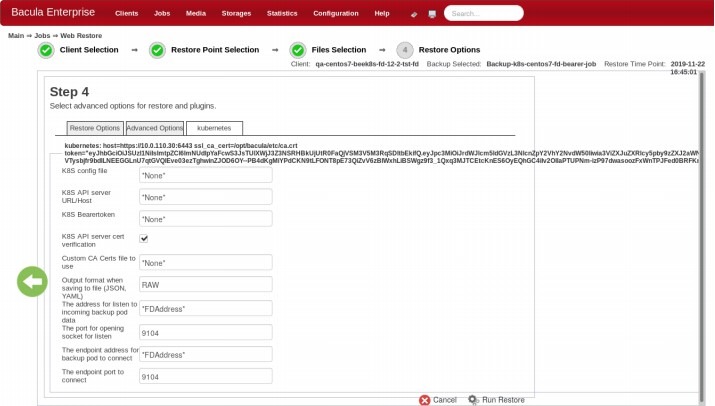
Aqui pode especificar várias opções diferentes, como o formato de saída, o caminho do ficheiro de configuração do SBC, a porta do ponto final e muito mais.
Também é fácil observar todo o processo de restauro após a conclusão da personalização, graças à página de registo de tarefas de restauro que escreve cada ação uma a uma:
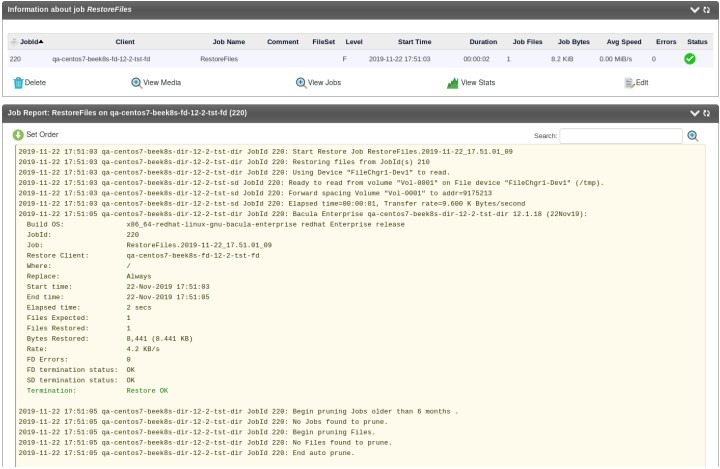
Outro recurso importante do módulo Kubernetes é o recurso Plugin Listing, que oferece muitas informações úteis sobre os recursos disponíveis do Kubernetes, incluindo namespaces, volumes persistentes e assim por diante. Para fazer isso, o módulo está usando um comando especial .ls com um parâmetro específico plugin=<plugin>.
O módulo Kubernetes do Bacula oferece uma variedade de recursos, alguns dos quais são:
- Reimplantação rápida e eficiente de recursos do cluster;
- Salvaguarda do estado do cluster Kubernetes;
- Salvando configurações para serem usadas em outras operações;
- Manter as configurações alteradas tão seguras quanto possível e restaurar exatamente o mesmo estado de antes.
Embora isso ocorra com frequência, é altamente recomendável evitar pagar ao seu fornecedor com base no volume de dados. Não faz sentido ficar à mercê, agora ou no futuro, de um provedor disposto a tirar proveito da sua organização dessa forma. Em vez disso, analise atentamente os modelos de licenciamento da Bacula Systems, que protegem seus clientes contra cobranças relacionadas ao crescimento de dados, ao mesmo tempo em que facilitam muito a previsão de custos futuros pelos departamentos de compras dos clientes. Essa abordagem mais razoável da Bacula tem origem em suas raízes de código aberto e pode ser atraente para equipes que trabalham extensivamente em ambientes DevOps.
Conclusão
No final do dia, os usuários do Kubernetes têm muitas opções diferentes quando se trata de software de backup e recuperação. Alguns deles são criados apenas para gerenciar dados do Kubernetes, enquanto outras soluções adicionam o Kubernetes à sua lista existente de recursos.
As empresas de menor porte que buscam uma solução capaz de realizar exclusivamente backups do Kubernetes podem considerar o Longhorn ou o OpenEBS mais adequados do que os demais exemplos da nossa lista. Por outro lado, empresas de maior porte, com diversos tipos de armazenamento em sua própria infraestrutura, podem necessitar de uma solução de backup abrangente e altamente segura que cubra todos os sistemas de TI da empresa sem fragmentação e seja capaz de monitorar o backup e a recuperação de forma global a partir de uma interface de gerenciamento centralizada — algo para o qual soluções como o Bacula Enterprise foram projetadas. A escolha final dependerá em grande parte das necessidades e prioridades de cada cliente, incluindo o porte da empresa, os recursos necessários e assim por diante.
Por que você pode confiar em nós
Bacula Systems é tudo sobre precisão e consistência, nossos materiais sempre tentam fornecer o ponto de vista mais objetivo sobre diferentes tecnologias, produtos e empresas. Em nossas análises, usamos muitos métodos diferentes, como informações sobre produtos e percepções de especialistas para gerar o conteúdo mais informativo possível.
Os nossos materiais oferecem todos os tipos de factores sobre cada solução apresentada, quer se trate de conjuntos de caraterísticas, preços, opiniões de clientes, etc. A estratégia de produto do Bacula é supervisionada e controlada por Jorge Gea – o CTO da Bacula Systems, e Rob Morrison – o Diretor de Marketing da Bacula Systems.
Antes de se juntar à Bacula Systems, Jorge foi durante muitos anos o CTO da Whitebearsolutions SL, onde liderou a área de Backup e Storage e a solução WBSAirback. Jorge agora fornece liderança e orientação nas tendências tecnológicas actuais, habilidades técnicas, processos, metodologias e ferramentas para o desenvolvimento rápido e emocionante de produtos Bacula. Responsável pelo roadmap do produto, Jorge está ativamente envolvido na arquitetura, engenharia e processo de desenvolvimento de componentes Bacula. Jorge tem uma licenciatura em engenharia informática pela Universidade de Alicante, um doutoramento em tecnologias de computação e um mestrado em administração de redes.
Rob iniciou a sua carreira em marketing de TI na Silicon Graphics, na Suíça, desempenhando um forte papel em várias funções de gestão de marketing durante quase 10 anos. Nos 10 anos seguintes, Rob também ocupou vários cargos de gestão de marketing na JBoss, Red Hat e Pentaho, assegurando o crescimento da quota de mercado destas empresas de renome. É licenciado pela Universidade de Plymouth e possui um diploma de Honra em Meios Digitais e Comunicações.
A Bacula Systems tem tudo a ver com precisão e consistência, a nossa informação tenta sempre fornecer o ponto de vista mais objetivo sobre diferentes tecnologias, produtos e empresas. Em nossas análises, usamos muitos métodos diferentes, como informações sobre produtos e percepções de especialistas, para gerar o conteúdo mais informativo possível.
Os nossos materiais oferecem todos os tipos de factores sobre cada solução apresentada, quer se trate de conjuntos de caraterísticas, preços, opiniões de clientes, etc. A estratégia de produto do Bacula é supervisionada e controlada por Jorge Gea – o CTO da Bacula Systems, e Rob Morrison – o Diretor de Marketing da Bacula Systems.
Antes de se juntar à Bacula Systems, Jorge foi durante muitos anos o CTO da Whitebearsolutions SL, onde liderou a área de Backup e Storage e a solução WBSAirback. Jorge agora fornece liderança e orientação nas tendências tecnológicas actuais, habilidades técnicas, processos, metodologias e ferramentas para o desenvolvimento rápido e emocionante de produtos Bacula. Responsável pelo roadmap do produto, Jorge está ativamente envolvido na arquitetura, engenharia e processo de desenvolvimento de componentes Bacula. Jorge tem uma licenciatura em engenharia informática pela Universidade de Alicante, um doutoramento em tecnologias de computação e um mestrado em administração de redes.
Rob iniciou a sua carreira em marketing de TI na Silicon Graphics, na Suíça, desempenhando um forte papel em várias funções de gestão de marketing durante quase 10 anos. Nos 10 anos seguintes, Rob também ocupou vários cargos de gestão de marketing na JBoss, Red Hat e Pentaho, assegurando o crescimento da quota de mercado destas empresas de renome. É licenciado pela Universidade de Plymouth e possui um diploma de Honra em Meios Digitais e Comunicações.
Perguntas frequentes
Qual é o objetivo principal dos backups do Kubernetes?
O objetivo de uma cópia de segurança da Kubernetes é semelhante ao da maioria das cópias de segurança: criar cópias seguras de informações a recuperar em caso de desastre, acidental ou intencional. Um pacote de backup adequado pode ser a solução para falhas do sistema, perda de dados, corrupção de dados, roubo de dados e muitas outras situações em que a existência de toda a empresa depende do facto de os dados poderem ser restaurados ou não.
Quão complexos são os backups do Kubernetes em comparação com os backups tradicionais de VMs?
A natureza em contentor das cargas de trabalho do Kubernetes é a principal razão pela qual estes backups são considerados mais desafiantes e sofisticados do que os backups normais de VM. Cada aplicação Kubernetes inclui vários microsserviços, com o requisito de fazer backup de um estado de cluster e de um estado de aplicação para o funcionamento adequado, tornando a restauração adequada sem perder a continuidade muito desafiadora. Além disso, a natureza em constante mudança dos clusters Kubernetes adiciona outra camada de dificuldade, tornando os processos de backup e recuperação ainda mais complexos.
Qual software de backup é a melhor opção possível para backups do Kubernetes?
É difícil afirmar que uma única solução seja a melhor opção possível para um caso de uso específico, tendo em conta que cada empresa possui um conjunto específico de circunstâncias e requisitos. A maioria das empresas também opera com um orçamento restrito no que diz respeito a software de backup, o que significa que o conjunto total de recursos teria uma prioridade menor do que o preço da solução. No fim das contas, a solução mais útil desta lista será aquela que for adequada para o maior número e a mais ampla variedade de casos de uso potenciais — nessa situação, o Bacula Enterprise seria o vencedor indiscutível desta lista.
O que o Bacula pode oferecer para ambientes Kubernetes multi-nuvem?
O Bacula fornece a flexibilidade de restauração de dados e recuperação de desastres, permitindo o armazenamento de backup em diferentes ambientes de armazenamento em nuvem. Restaurar informações para qualquer cluster compatível em vez do cluster do qual os dados foram copiados também é uma opção aqui. A resiliência e a redundância de um ambiente Kubernetes são drasticamente aumentadas dessa forma, especialmente quando se trata de várias interrupções específicas da nuvem. O Bacula também permite que seus usuários restaurem namespaces e clusters inteiros em diferentes ambientes de armazenamento em nuvem, fornecendo ampla continuidade sem amarrar os usuários ao mesmo armazenamento em nuvem. Um aspeto crítico que muitas vezes é um pouco negligenciado pelos arquitetos do Kubernetes é a necessidade de sua organização obter os mais altos níveis de segurança possíveis. Em comparação com praticamente todos os outros provedores de backup, o Bacula tem níveis mais altos de segurança incorporados em sua arquitetura, suas metodologias, seus processos e seus recursos individuais.
Que tipos de ambiente o Bacula suporta?
O Bacula não só pode trabalhar com clusters Kubernetes locais e baseados em nuvem, mas também oferece suporte a ambientes híbridos, tornando possível misturar e combinar ambas as opções de implantação para o nível mais alto possível de flexibilidade, eficiência e segurança em diferentes ambientes.

