

Contents
- Introduction
- Concepts importants pour un processus de sauvegarde Kubernetes
- Pourquoi les sauvegardes K8s sont-elles nécessaires ?
- L’intérêt des sauvegardes Kubernetes
- Les avantages des opérations de sauvegarde Kubernetes
- Types de données Kubernetes à sauvegarder
- Que devez-vous sauvegarder dans un environnement Kubernetes ?
- Quel est l’impact de GitOps sur votre stratégie de sauvegarde Kubernetes ?
- Meilleures pratiques pour les opérations de sauvegarde Kubernetes
- Comment concevoir les calendriers de sauvegarde et les politiques de conservation de Kubernetes ?
- Comment sécuriser les sauvegardes Kubernetes et respecter les exigences de conformité ?
- Méthodologie pour choisir la meilleure solution de sauvegarde Kubernetes possible
- Marché des solutions de sauvegarde Kubernetes
- Quelle liste de contrôle les équipes doivent-elles suivre pour s’assurer que leur environnement Kubernetes est prêt pour la sauvegarde ?
- La solution de sauvegarde K8s de Bacula Enterprise
- Conclusion
- Pourquoi vous pouvez nous faire confiance
- Questions fréquemment posées
Introduction
Kubernetes (également appelé K8s) est une plateforme d’orchestration de conteneurs qui facilite la gestion et la mise à l’échelle des applications ; elle constitue souvent le choix privilégié des entreprises qui peuvent tirer parti de l’architecture d’applications conteneurisées. La flexibilité de Kubernetes fait que de nombreux déploiements se distinguent considérablement les uns des autres. Cependant, ces structures uniques s’accompagnent généralement de défis spécifiques en matière de reprise et de disponibilité, qui font tous partie des défis liés à l’utilisation de Kubernetes au sein de votre infrastructure informatique d’entreprise.
Si l’hypothèse selon laquelle Kubernetes était auparavant principalement utilisé par les équipes DevOps était peut-être en partie correcte, de nombreuses entreprises déploient désormais activement des conteneurs dans des environnements opérationnels. Elles s’appuient également de plus en plus sur les conteneurs pour déployer des applications, au lieu d’utiliser des machines virtuelles traditionnelles. Cela s’explique par les divers avantages que les conteneurs peuvent offrir en termes de flexibilité, de performances et de coûts. Cependant, à mesure que les conteneurs s’intègrent dans la partie opérationnelle de l’environnement informatique, les aspects de sécurité des conteneurs dans les systèmes de production qui doivent rester disponibles suscitent de plus en plus d’inquiétudes, notamment en ce qui concerne leurs données persistantes dans le cadre des processus de sauvegarde et de restauration.
À l’origine, la grande majorité des applications conteneurisées étaient sans état, ce qui leur permettait d’être déployées beaucoup plus facilement sur un cloud public. Mais cela a changé avec le temps, et l’on déploie désormais beaucoup plus d’applications avec état dans des conteneurs qu’auparavant. C’est cette évolution qui explique pourquoi la sauvegarde et la restauration dans Kubernetes constituent désormais un sujet important pour de nombreuses organisations.
Concepts importants pour un processus de sauvegarde Kubernetes
- L’importance des sauvegardes Kubernetes repose sur la sécurité des données, car l’information est la ressource la plus importante de toute entreprise moderne et exige presque toujours que ces données soient conservées en toute sécurité et confidentialité. Dans le contexte de Kubernetes, les informations précieuses comprennent généralement aussi ses configurations, ses secrets, la base de données etcd, les volumes persistants, etc.
- Une configuration adéquate de la stratégie de sauvegarde peut offrir une grande polyvalence et de nombreuses fonctionnalités à un environnement Kubernetes, notamment des sauvegardes au niveau des applications, des sauvegardes au niveau des espaces de noms, des instantanés, la validation des sauvegardes, la gestion des versions, les politiques de sauvegarde, et bien d’autres encore.
- Une configuration correcte de la restauration est tout aussi importante, compte tenu du nombre de maillons du processus susceptibles de défaillir. Des tests de sauvegarde rigoureux, la consultation de la documentation et une vigilance constante pendant la restauration font partie des éléments à maintenir pour garantir le succès des processus de restauration.
- Les sauvegardes Kubernetes peuvent rencontrer toute une série de défis – qu’il s’agisse de problèmes de cohérence des données, de normes de conformité, de sécurité des données ou de compatibilité des versions, entre autres. La bonne nouvelle, c’est que la plupart de ces écueils peuvent être évités ou atténués grâce à un certain niveau de préparation.
Pourquoi les sauvegardes K8s sont-elles nécessaires ?
Un environnement Kubernetes est dynamique, distribué et intrinsèquement plus exposé à la perte de données qu’une infrastructure conventionnelle. Cette section traite des divers facteurs de défaillance qui rendent les sauvegardes indispensables, des différentes catégories de défaillance, des stratégies de récupération correspondantes, ainsi que de la nécessité de documenter explicitement les besoins en matière de sauvegarde dans les SLA et les runbooks.
Quels risques les clusters Kubernetes encourent-ils sans sauvegardes ?
Dans un environnement Kubernetes, il existe des dangers qui vont bien au-delà des problèmes d’infrastructure standard.
- Les attaques ciblées de la chaîne d’approvisionnement contre des images de conteneurs ou des référentiels Helm peuvent facilement introduire du code malveillant difficile à détecter avant qu’il ne cause des dommages
- Les rôles IAM dans le cloud qui ont été mal configurés peuvent exposer – ou pire – endommager les ressources du cluster à grande échelle
- Les événements d’auto-scaling peuvent rapidement prendre au dépourvu les charges de travail avec état, provoquant une corruption des données invisible mais permanente
De tels risques peuvent se multiplier extrêmement rapidement sur les systèmes distribués, où la portée d’un seul événement peut s’étendre à des dizaines de charges de travail dans des dizaines d’espaces de noms.
En quoi les pannes d’application, de cluster et de données diffèrent-elles ?
Les pannes de Kubernetes surviennent souvent à différents niveaux et nécessitent donc des stratégies de reprise différentes. La panne peut n’affecter qu’une seule charge de travail, elle peut affecter l’ensemble du cluster, ou encore les données stockées en externe par rapport aux deux. Les sections suivantes aborderont chacune de ces pannes plus en détail, mais connaître cette distinction à l’avance permet également de comprendre pourquoi une stratégie de sauvegarde unique pour tous les cas de figure est rarement couronnée de succès.
Quand les sauvegardes doivent-elles faire partie de vos SLA et de vos runbooks ?
Les sauvegardes doivent être obligatoires lorsqu’une charge de travail a un RTO et/ou un RPO défini. Si vous vous êtes engagé à respecter un objectif de temps de récupération, cet indicateur doit s’accompagner d’un processus de restauration documenté et testé, ce qui signifie que la fréquence des sauvegardes, la durée de conservation et le processus de restauration doivent être documentés avant un incident, et non après.
Les charges de travail figurant dans un guide d’intervention d’astreinte doivent être prises en compte avec une responsabilité clairement définie et une politique de sauvegarde documentée. Les environnements soumis à des réglementations de conformité ajoutent leur propre couche au processus, exigeant la preuve que les sauvegardes existent, sont testées et respectent les politiques de conservation documentées nécessaires.
L’intérêt des sauvegardes Kubernetes
La nature même des environnements Kubernetes rend plus difficile le bon fonctionnement des systèmes et techniques de sauvegarde plus traditionnels dans le contexte des nœuds et des applications Kubernetes. Le RPO et le RTO peuvent en effet s’avérer bien plus critiques, car les applications faisant partie d’un déploiement opérationnel doivent être constamment opérationnelles, en particulier les éléments d’infrastructure critiques.
Cela nous amène à identifier les éléments clés de la continuité des activités qui sont pratiquement indispensables pour toute entreprise en général et constituent une nécessité évidente en matière de bonnes pratiques de sauvegarde K8s : sauvegarde et restauration, haute disponibilité locale, reprise après sinistre, protection contre les ransomwares, erreur humaine, etc. Dans un environnement Kubernetes, le contexte de ces aspects de la sauvegarde peut légèrement s’écarter de leur définition habituelle.
Haute disponibilité locale
La haute disponibilité locale, en tant que fonctionnalité, concerne davantage la prévention des pannes ou la protection au sein d’un centre de données spécifique ou entre zones de disponibilité (si l’on parle du cloud, par exemple). Une défaillance « locale » survient au niveau de l’infrastructure, du nœud ou de l’application utilisée pour exécuter l’application. Dans un scénario idéal, votre solution de sauvegarde Kubernetes devrait être capable de réagir à cette défaillance en maintenant l’application opérationnelle, ce qui signifie essentiellement aucune interruption de service pour l’utilisateur final. L’un des exemples les plus courants de défaillance locale est un volume cloud bloqué qui survient après la défaillance d’un nœud.
Dans cette perspective, la haute disponibilité locale en tant que fonctionnalité peut être considérée comme un élément central de la stratégie de protection des données. D’une part, pour accomplir une telle tâche, votre solution doit offrir une sorte de système de réplication des données au niveau local, et elle doit également se trouver en premier lieu sur le chemin des données. Il est important de mentionner que la mise à disposition d’une disponibilité locale via la restauration de sauvegarde est toujours considérée comme une opération de sauvegarde et de restauration, et non comme une haute disponibilité locale, en raison du temps de récupération global.
Sauvegarde et restauration
La sauvegarde et la restauration constituent un autre élément important d’un système Kubernetes opérationnel. Dans la plupart des cas d’utilisation, elles permettent de sauvegarder l’intégralité de l’application depuis un cluster Kubernetes local vers un emplacement hors site. Le contexte de Kubernetes soulève également une autre considération importante : le logiciel de sauvegarde « comprend-il » ce que contient une application Kubernetes, notamment :
- La configuration de l’application ;
- Les ressources Kubernetes ;
- Données
Une sauvegarde Kubernetes correcte doit enregistrer tous les éléments ci-dessus en une seule unité pour qu’elle soit utile dans le système Kubernetes après sa restauration. Cibler des machines virtuelles, des serveurs ou des disques spécifiques ne signifie pas que le logiciel « comprend » les applications Kubernetes. Idéalement, un logiciel Kubernetes devrait être capable de sauvegarder des applications spécifiques, des groupes spécifiques d’applications, ainsi que l’ensemble de l’espace de noms Kubernetes. Cela ne signifie pas pour autant qu’il s’agit d’un processus totalement différent de la sauvegarde classique : les sauvegardes Kubernetes peuvent également tirer un grand bénéfice de certaines fonctionnalités courantes d’une sauvegarde classique, notamment la conservation, la planification, le chiffrement, la hiérarchisation, etc.
Reprise après sinistre
La capacité de Reprise après sinistre (DR) est essentielle pour toute organisation utilisant Kubernetes dans un contexte critique, tout comme c’est le cas pour l’utilisation de toute autre technologie. Tout d’abord, la reprise après sinistre doit « comprendre » le contexte des sauvegardes Kubernetes, tout comme la sauvegarde et la restauration. Elle peut également présenter différents niveaux de RTO et de RPO, ainsi que différents niveaux de protection en fonction de ces niveaux. Par exemple, il pourrait y avoir une exigence stricte de RPO nul, impliquant un temps d’arrêt strictement nul, ou bien un RPO de 15 minutes avec des exigences un peu moins strictes. Il n’est pas rare non plus que différentes applications aient des RTO et des RPO complètement différents au sein d’une même base de données.
Une autre distinction importante d’un système de reprise après sinistre spécifique à Kubernetes est qu’il doit également être capable de fonctionner avec des métadonnées dans une certaine mesure (étiquettes, répliques d’applications, etc.). L’incapacité à fournir cette fonctionnalité pourrait facilement conduire à une reprise incohérente en général, ainsi qu’à une perte générale de données ou à des temps d’arrêt supplémentaires.
Protection contre les ransomwares
L’importance des sauvegardes des systèmes Kubernetes (en particulier ceux générant des données persistantes) rivalise avec celle des sauvegardes de données classiques. Les données précieuses doivent être protégées afin d’éviter tout risque inacceptable. L’information est inestimable, et Bacula Systems recommande vivement de disposer d’un plan dédié (ou de plusieurs) pour les situations où les données de l’entreprise seraient corrompues ou compromises d’une autre manière.
Bon nombre de ces mesures de protection sont également efficaces contre les incidents accidentels et malveillants. Les attaques intentionnelles entraînant des violations de données par le biais de ransomwares, d’usurpation d’identité et d’autres moyens sont devenues monnaie courante, et il est tout à fait irréaliste de penser que votre entreprise ne sera jamais la cible d’un tel événement. À ce titre, se préparer à ces situations peut offrir des avantages en termes de nombreux facteurs extrêmement importants, tels que le respect de la conformité, la protection de la réputation personnelle et de l’entreprise, la protection des clients et des employés, et surtout, le fait d’éviter de manière générale des dommages graves à une entreprise et/ou à une organisation.
Erreur humaine
La gravité d’une simple erreur humaine peut être considérable (suppressions accidentelles, configurations incorrectes, déploiement involontaire de mises à jour). Si l’automatisation de certaines fonctions peut atténuer quelque peu les erreurs humaines, il est généralement impossible d’automatiser chaque processus dans la plupart des entreprises.
Dans ce contexte, les plans de sauvegarde et de reprise après sinistre permettent de garantir qu’une entreprise puisse poursuivre ses activités de manière efficace après un incident impliquant une commande incorrecte ou une erreur de configuration.
Les avantages des opérations de sauvegarde Kubernetes
Les sauvegardes Kubernetes présentent de multiples avantages, souvent similaires à ceux des opérations de sauvegarde classiques sur tout autre type de données. Il s’agit d’un excellent moyen de maintenir la fiabilité, la disponibilité et l’intégrité des applications Kubernetes et des données associées. Certains des avantages les plus courants sont présentés ci-dessous.
Atténuation de l’impact des pannes matérielles
D’un point de vue technique, les pannes matérielles sont inévitables et peuvent survenir à tout moment ; qu’il s’agisse d’une panne de réseau, d’une coupure de courant, d’un dysfonctionnement d’une unité de stockage ou de tout autre type d’événement entraînant une corruption ou une perte de données. Les sauvegardes Kubernetes offrent un niveau élevé de protection contre de tels incidents en fournissant une copie redondante des informations pouvant être restaurée dans n’importe quel autre environnement si le matériel d’origine n’est plus disponible, ce qui minimise les temps d’arrêt et améliore la continuité des activités.
Reprise après sinistre
La plupart des catastrophes naturelles sont susceptibles de détruire complètement l’ensemble de l’infrastructure physique d’une entreprise, y compris ses clusters Kubernetes et peut-être même les sauvegardes principales de ces clusters. L’existence d’une sauvegarde hors site est donc l’un des nombreux avantages que la stratégie de reprise après sinistre offre à ses utilisateurs, en permettant de reconstruire rapidement l’ensemble du réseau de clusters afin de reprendre les opérations dans un délai acceptable.
Prévention des pertes de données
Les erreurs accidentelles et les mauvaises pratiques de gestion sont étonnamment courantes à ce jour, indépendamment du nombre croissant de violations de données malveillantes. Tout être humain peut commettre des erreurs, et l’impossibilité d’annuler une action, une suppression ou une modification donnée augmente considérablement le risque de perte définitive de données sensibles. Des sauvegardes régulières de K8s permettent de garantir que les accidents causés involontairement puissent encore être corrigés, d’une manière ou d’une autre.
Protection contre les cyberattaques
Les cybermenaces ne cessent de croître depuis plusieurs années déjà, et l’on s’attend presque unanimement à ce que la situation continue de se détériorer. Toute infrastructure informatique est constamment exposée au risque d’une cyberattaque, et l’existence de mesures de sauvegarde bien définies et sécurisées est essentielle pour protéger l’ensemble des entreprises. Ne pas le faire représente un risque significatif pour la pérennité même de l’entreprise.
Assistance pour les environnements de test et de développement
Les sauvegardes régulières des clusters Kubernetes présentent souvent une valeur ajoutée : elles peuvent également constituer une aide précieuse dans les processus de test et de développement, en simplifiant considérablement la création de répliques de clusters à des fins de développement sans affecter les données d’origine. De cette manière, l’expérimentation peut s’avérer beaucoup plus fructueuse et efficace, offrant de nombreuses opportunités de développement pour l’entreprise elle-même.
Types de données Kubernetes à sauvegarder
La conteneurisation est généralement utilisée pour créer et exécuter un environnement d’exécution sécurisé, fiable et léger pour les applications, afin de disposer d’un système cohérent d’un hôte à l’autre. En règle générale, ces systèmes génèrent des données persistantes ; lorsque c’est le cas, ces données ont généralement de la valeur et doivent donc être sauvegardées. De plus, l’ensemble du système de conteneurs lui-même doit être protégé et sauvegardé afin que, en cas de perte ou de corruption, le système puisse être rapidement restauré, minimisant ainsi la perte de systèmes et de services — et l’impact potentiel sur l’activité — pour une organisation.
Kubernetes est la technologie de conteneurs la plus populaire actuellement utilisée. À ce titre, la question des différents types de données Kubernetes devant être sauvegardés nécessite un examen approfondi.
Comme pour tout système complexe, Kubernetes et Docker disposent d’un certain nombre de types de données spécifiques dont ils auront besoin pour reconstruire correctement l’ensemble de la base de données en cas de sinistre. Pour simplifier, il est possible de classer tous les types de données et de fichiers de configuration en deux catégories distinctes : les données de configuration et les données persistantes.
La configuration (et les informations sur l’état souhaité) comprend :
- La base de données etcd de Kubernetes
- Les fichiers Docker
- Les images issues des fichiers Docker
Les données persistantes (modifiées ou créées par les conteneurs eux-mêmes) sont :
- Bases de données
- Volumes persistants
Base de données etcd de Kubernetes
Elle fait partie intégrante du système et contient des informations sur l’état des clusters. Elle peut être sauvegardée manuellement ou automatiquement, selon votre solution de sauvegarde. La méthode manuelle s’effectue via la commande etcdctl snapshot save db, qui crée un fichier unique nommé snapshot.db.
Une autre méthode pour obtenir le même résultat consiste à déclencher cette même commande juste avant de créer une sauvegarde du répertoire dans lequel ce fichier apparaîtrait. C’est l’une des façons d’intégrer cette sauvegarde spécifique à l’ensemble de l’environnement.
Fichiers Docker
Étant donné que les conteneurs Docker eux-mêmes sont exécutés à partir d’images, ces images doivent reposer sur quelque chose – et celles-ci sont, à leur tour, créées à partir de fichiers Docker. Pour une configuration Docker correcte, il est recommandé d’utiliser un référentiel comme système de contrôle de version pour l’ensemble de vos fichiers Docker (GitHub, par exemple). Afin de faciliter la récupération des versions antérieures, tous les fichiers Docker doivent être stockés dans un référentiel spécifique permettant aux utilisateurs de récupérer les anciennes versions de ces fichiers si nécessaire.
Un dépôt supplémentaire est également recommandé pour les fichiers YAML associés à tous les déploiements Kubernetes ; ceux-ci se présentent sous la forme de fichiers texte. La sauvegarde de ces dépôts est également indispensable, que ce soit à l’aide d’outils tiers ou des fonctionnalités intégrées d’un service tel que GitHub.
Il est important de mentionner que vous pouvez toujours générer les fichiers Docker à sauvegarder, même si vous exécutez des conteneurs à partir d’images sans leurs fichiers Docker. Il existe une commande spécifique, docker image history, qui vous permet de créer un fichier Docker à partir de votre image actuelle. Plusieurs outils tiers permettent également d’effectuer cette opération.
Images à partir de fichiers Docker
Les images Docker elles-mêmes doivent également être sauvegardées dans un référentiel. Les référentiels privés et publics peuvent tous deux être utilisés à cette fin. Divers fournisseurs de cloud ont également tendance à proposer des référentiels privés à leurs clients. Si l’image à partir de laquelle votre conteneur s’exécute vous manque, une commande spécifique, à savoir docker commit, devrait permettre de créer cette image.
Bases de données
L’intégrité est également cruciale lorsqu’il s’agit des bases de données que les conteneurs utilisent pour stocker leurs données. Dans certains cas, il est possible d’arrêter le conteneur en question avant de créer une sauvegarde des données, mais là encore, le temps d’indisponibilité requis est susceptible d’entraîner de nombreux problèmes pour l’entreprise concernée.
Une autre méthode pour effectuer des sauvegardes de bases de données à l’intérieur des conteneurs consiste à se connecter au moteur de base de données lui-même. Il convient d’utiliser au préalable un montage lié (bind mount) pour attacher un volume pouvant être sauvegardé, puis vous pouvez utiliser la commande mysqldump (ou similaire) pour créer une sauvegarde. Le fichier de sauvegarde en question doit également être sauvegardé par la suite à l’aide de votre système de sauvegarde.
Volumes persistants
Il existe différentes méthodes permettant aux conteneurs d’accéder à une forme de stockage persistant. Par exemple, s’il s’agit de volumes Docker traditionnels, ceux-ci résident dans un répertoire situé sous la configuration Docker. Les montages liés, en revanche, peuvent correspondre à n’importe quel répertoire monté à l’intérieur d’un conteneur. Bien que les volumes traditionnels soient préférés au sein de la communauté Docker, ces deux types de stockage sont relativement similaires en matière de sauvegarde des données. Une troisième façon d’effectuer la même opération consiste à monter un répertoire NFS ou un objet unique en tant que volume à l’intérieur d’un conteneur.
Ces trois méthodes présentent le même problème en matière de sauvegarde des données : la cohérence d’une sauvegarde n’est pas totale si les données à l’intérieur d’un conteneur changent en cours de sauvegarde. Bien sûr, il est toujours possible d’assurer la cohérence en désactivant le volume avant la sauvegarde, mais dans la plupart des cas, le temps d’arrêt de ces systèmes n’est pas envisageable pour des raisons de continuité des activités.
Il existe certaines méthodes spécifiques pour sauvegarder les données au sein des conteneurs. Par exemple, les volumes Docker traditionnels pourraient être montés sur un autre conteneur qui ne modifierait aucune donnée tant que le processus de sauvegarde n’est pas terminé. Ou si vous utilisez un volume monté en bind, il est possible de créer une image tar de l’intégralité du volume, puis de sauvegarder cette image.
Malheureusement, toutes ces options peuvent s’avérer très difficiles à mettre en œuvre lorsqu’il s’agit de Kubernetes. C’est précisément pour cette raison qu’il est toujours recommandé de stocker les informations d’état dans la base de données et en dehors du système de fichiers du conteneur.
Cela dit, si vous utilisez un répertoire monté en bind ou un système de fichiers monté via NFS comme stockage persistant, il est également possible de sauvegarder ces données à l’aide de méthodes classiques, comme un instantané. Cela devrait vous offrir une bien meilleure cohérence que la sauvegarde traditionnelle au niveau des fichiers du même volume.
Que devez-vous sauvegarder dans un environnement Kubernetes ?
Il existe différents types de données dans un environnement Kubernetes, et chaque type nécessite des considérations de restauration qui lui sont propres. Il est facile de comprendre ce qui doit être sauvegardé ; là où la plupart des équipes rencontrent des difficultés, c’est de déterminer quels composants doivent être sauvegardés et pourquoi. Comprendre ce qui doit être sauvegardé est la partie la plus simple ; cependant, la plupart des équipes ont du mal à déterminer quels composants doivent être prioritaires, et pourquoi.
Que permet réellement de restaurer une sauvegarde etcd, et que ne permet-elle pas de restaurer ?
Etcd est la source unique de vérité pour l’état de l’ensemble de votre cluster. À ce titre, c’est à la fois l’élément le plus important à sauvegarder et le composant le plus mal compris. Un instantané etcd vous permet de rétablir l’état de l’ensemble de votre cluster à un moment donné, mais si votre cluster en production a trop évolué par rapport à votre instantané, vous vous retrouverez avec des incohérences entre ce qu’etcd signale comme étant en cours d’exécution et ce qui est réellement présent.
Un instantané etcd ne suffit pas à lui seul à restaurer complètement votre cluster en cas de sinistre, car, bien qu’il contienne l’état du cluster, il ne contient aucune donnée d’application (qui sont stockées dans des volumes persistants) et ne garantit pas que l’état restauré correspondra à celui du cluster que vous avez reconstruit. Ce sont les sauvegardes au niveau des applications qui fournissent ces informations manquantes, et il est important de considérer les instantanés etcd comme complémentaires aux sauvegardes au niveau des applications plutôt que comme un substitut à celles-ci.
Faut-il sauvegarder les volumes persistants (PV) et les revendications de volumes persistants (PVC) ?
Oui, il est nécessaire de sauvegarder à la fois les PV et les PVC, mais leur priorité dépend de ce qu’ils contiennent exactement. Certains PV contiennent des données bien plus précieuses que d’autres : un PV assurant la persistance d’une base de données avec état ne présente pas le même facteur de risque qu’un PV contenant du contenu mis en cache.
Avant de choisir votre fréquence de sauvegarde, il est judicieux de classer vos PV par niveau de criticité de récupération afin de vous assurer que votre calendrier de sauvegarde reflète les besoins de l’entreprise et n’accorde pas la même importance à tous les volumes.
Quelles métadonnées de cluster (manifestes, RBAC, CRD, configmaps, secrets) sont essentielles ?
Toutes ces métadonnées sont importantes, mais pas au même niveau lorsqu’il s’agit de scénarios de restauration urgents.
La perte de la configuration RBAC et des CRD est la situation la plus perturbatrice dans ce contexte, car elles définissent ce que vous êtes autorisé à faire, ainsi que les définitions de ressources utilisées par le reste du cluster. Sans ces informations, les applications que vous restaurez risquent fort de se retrouver dans un état inaccessible ou défectueux.
Les ConfigMaps et les secrets définissent également le fonctionnement de vos applications, et sont souvent les éléments les plus négligés dans une stratégie de sauvegarde manuelle. Les manifestes sont également très importants, mais si vous disposez d’un système GitOps, il devrait être relativement simple de les récupérer à partir du contrôle de source, ce qui les place un peu plus bas dans la liste des priorités.
Comment traiter les données éphémères et les journaux ?
Les données éphémères – tout ce qui n’existe que pendant la durée de vie d’un pod – ne devraient généralement pas être sauvegardées, et tenter de le faire ajoute de la complexité sans apporter de valeur significative en matière de restauration.
Les journaux se trouvent généralement dans une situation similaire : ils ne sont pas censés être sauvegardés dans le cadre d’une stratégie de sauvegarde Kubernetes. Une bien meilleure option consiste à disposer d’un pipeline d’observabilité dédié qui envoie ces journaux vers un stockage externe indépendamment du processus de sauvegarde.
Une question plus pertinente ici serait de savoir si les données que vous considérez actuellement comme éphémères doivent être conservées. Si tel est le cas, elles devraient être transférées vers un volume persistant plutôt que d’être incluses dans une sauvegarde.
Quel est l’impact de GitOps sur votre stratégie de sauvegarde Kubernetes ?
GitOps est un modèle opérationnel dans lequel le dépôt Git stocke l’état complet d’un environnement Kubernetes – avec tous les manifestes, les définitions de ressources et les configurations. Les informations en question sont également continuellement réconciliées avec le cluster en production à l’aide d’un outil dédié. Au lieu d’appliquer les modifications directement à votre cluster, celles-ci passent d’abord par Git, faisant du dépôt en question une source unique de vérité quant à l’état du cluster à tout moment.
Ce modèle s’est rapidement généralisé dans les environnements Kubernetes, modifiant la donne en matière de sauvegarde de manière spécifique – et les implications de ce changement ne sont pas toujours évidentes non plus. Il est essentiel de savoir où cela aide et où cela s’arrête avant de décider du niveau de couverture de sauvegarde à superposer.
En quoi GitOps modifie-t-il votre approche de la sauvegarde de configuration ?
Si vos manifestes Kubernetes, vos configurations RBAC et vos définitions de ressources sont stockés dans Git et continuellement synchronisés par un outil tel qu’ArgoCD ou Flux, vous disposez déjà d’une forme de sauvegarde de configuration sous contrôle de version.
Toute ressource déclarative présente dans votre dépôt Git peut être réappliquée à un cluster nouveau ou restauré sans nécessiter de sauvegarde distincte de cette ressource. Cela simplifie considérablement le processus de configuration des sauvegardes, car les manifestes et les descriptions de ressources de cluster déjà gérés par GitOps peuvent devenir des éléments de moindre priorité dans votre stratégie de sauvegarde dédiée.
Qu’est-ce que GitOps ne couvre pas, et dans quels cas les sauvegardes dédiées restent-elles nécessaires ?
GitOps gère l‘état souhaité, et non l’état d’exécution ou les données. Ainsi, les volumes persistants, les secrets non validés dans Git, le contenu des bases de données et les états qui n’existent qu’au sein d’un cluster en cours d’exécution lui sont tous invisibles.
Un cluster entièrement géré par GitOps peut tout de même subir une perte massive de données si les volumes persistants ne sont pas sauvegardés de manière indépendante. Les secrets sont généralement exclus explicitement des dépôts pour des raisons de sécurité ; ils nécessitent donc également une couverture de sauvegarde indépendante.
GitOps ne constitue pas une alternative à une stratégie de sauvegarde ; il s’agit plutôt de deux approches complémentaires, et le fait de reconnaître la frontière entre elles permet d’éviter les hypothèses erronées quant à ce qui est couvert.
Meilleures pratiques pour les opérations de sauvegarde Kubernetes
Il existe un certain nombre de meilleures pratiques pouvant être utilisées pour améliorer l’état général des sauvegardes K8s, notamment la résilience du cluster, la sécurité des données et la fiabilité de la restauration.
Sauvegardez les données persistantes et l’état du cluster
L’état du cluster comprend des composants clés d’un environnement Kubernetes, notamment les secrets, les ConfigMaps, etcd, etc. Les volumes de données persistantes constituent la majeure partie de la taille des données, avec des fichiers classiques, des bases de données, des données utilisateur, des journaux, etc.
Mettez en place l’automatisation des sauvegardes
L’automatisation des sauvegardes réduit le risque d’erreur humaine et apporte cohérence et prévisibilité au processus de sauvegarde. De nombreuses solutions de sauvegarde tierces offrent des capacités d’automatisation avancées, telles que la possibilité de planifier des calendriers de sauvegarde en tenant compte de RTO et de RPO spécifiques.
Utilisez différents types de sauvegarde lorsque cela est possible
Les données Kubernetes peuvent être sauvegardées à l’aide de différentes approches de sauvegarde, si le logiciel le permet. Par exemple, les sauvegardes incrémentielles peuvent permettre une réduction significative de l’espace de stockage total utilisé en ne capturant que les informations qui ont été modifiées d’une manière ou d’une autre depuis la dernière sauvegarde.
Testez les données sauvegardées
Les sauvegardes ne sont pas invulnérables dès leur création, et il est possible que les informations aient été corrompues ou perdues d’une manière ou d’une autre au cours du processus. Effectuer régulièrement des tests de restauration permet de détecter plus facilement ces erreurs et de les résoudre avant toute catastrophe.
Mettez en place le chiffrement des sauvegardes
Le chiffrement des sauvegardes doit être mis en place, si nécessaire, pour les informations en transit et au repos afin de garantir le niveau de sécurité le plus élevé possible. Le chiffrement contribue à protéger les données contre les violations de données et les accès non autorisés. Il existe de nombreux algorithmes de chiffrement parmi lesquels choisir, si la solution de sauvegarde les prend en charge.
Envisagez d’utiliser un stockage immuable
Le recours à des stratégies d’immuabilité des données peut constituer un élément important d’une stratégie de sauvegarde. Certaines solutions de sauvegarde offrent une immuabilité logicielle, tandis que d’autres proposent des options matérielles dédiées telles que le WORM (write-once-read-many) pour protéger les informations contre les cybermenaces.
N’oubliez pas les politiques de conservation et la gestion des versions
La gestion des versions consiste à stocker des copies antérieures de vos informations pour des raisons de conformité ou de commodité. Une politique de conservation correctement configurée doit préciser la durée de conservation afin de trouver le juste équilibre entre la consommation de stockage et le respect de toutes les exigences nécessaires.
Vérifiez les capacités de sauvegarde multi-clusters
Si votre environnement actuel utilise plusieurs clusters Kubernetes, il peut être primordial de vous assurer que votre solution de sauvegarde offre une sauvegarde centralisée. La capacité à gérer plusieurs environnements à la fois peut considérablement simplifier le processus de sauvegarde et améliorer le confort général de travail dans un tel environnement.
Mettez en œuvre un logiciel de sauvegarde natif du cloud
La compatibilité avec les infrastructures cloud dynamiques est une caractéristique importante pour toute solution de sauvegarde Kubernetes performante. L’une des raisons à cela est que l’évolution des services offerts par le cloud computing peut apporter des avantages supplémentaires en matière de sécurité à une organisation. Il peut être essentiel de vous assurer que le logiciel de sauvegarde de votre choix est natif du cloud et peut s’intégrer à différents services de stockage cloud.
Réfléchissez à l’ensemble de votre stratégie de reprise après sinistre
Les stratégies de sauvegarde sont souvent plus efficaces lorsqu’elles sont conçues en tenant compte de la reprise après sinistre, et Kubernetes ne fait pas exception. Par exemple, s’assurer que les sauvegardes peuvent être restaurées sur différents clusters permettrait de couvrir des situations telles que la migration ou la défaillance complète d’un cluster. Par ailleurs, la prise en charge des sauvegardes inter-clouds et inter-régions permet de résoudre les problèmes liés au cloud ou les pannes régionales.
Assurez la sécurité des secrets Kubernetes
Les secrets Kubernetes contiennent de nombreuses informations sensibles qui méritent d’être protégées : mots de passe, clés API, certificats, etc. Ce type d’informations doit bénéficier de la plus haute priorité en matière de sécurité des données, avec un chiffrement complet, l’immuabilité des données, etc.
Essayez d’optimiser le coût du stockage de sauvegarde
Si possible, il est généralement important de mettre en œuvre diverses techniques de gestion du stockage afin de réduire la taille totale des sauvegardes dans votre environnement de stockage. La compression et la déduplication sont tout aussi efficaces à cet égard, mais chacune présente ses propres inconvénients. Il en va de même pour la plupart des stratégies d’économie de stockage spécifiques au cloud.
Surveillez régulièrement les processus de sauvegarde
Il est peut-être déraisonnable d’attendre de quelqu’un qu’il surveille les processus de sauvegarde automatisés 24 heures sur 24, 7 jours sur 7. C’est pourquoi des systèmes de surveillance et de notification dédiés doivent être mis en place pour s’assurer que tout fonctionne correctement. La plupart des solutions offrent même la possibilité d’envoyer une notification spécifique à une personne désignée si une anomalie est détectée pendant le processus de sauvegarde.
Mettez en place des sauvegardes au niveau de l’espace de noms pour les clusters multi-locataires
Les environnements multi-locataires mentionnés ci-dessus peuvent être pris en charge à l’aide de sauvegardes au niveau de l’espace de noms. De cette manière, les informations de chaque locataire disposeraient d’un fichier de sauvegarde distinct, ce qui limiterait l’exposition potentielle des données entre les locataires tout en offrant une grande flexibilité pour les processus de restauration.
Fournir une documentation pour l’ensemble du pipeline de sauvegarde et de restauration
L’ensemble du processus de sauvegarde et de restauration doit être bien documenté, y compris les instructions détaillées sur la manière dont une sauvegarde est configurée, surveillée, vérifiée, etc. La même logique s’applique aux processus de restauration. Cette documentation doit également couvrir les rôles et les responsabilités des employés chargés des tâches d’administration des sauvegardes.
Comment concevoir les calendriers de sauvegarde et les politiques de conservation de Kubernetes ?
Savoir ce qu’il faut sauvegarder n’est que la moitié du chemin. L’autre moitié consiste à décider de la fréquence des sauvegardes et de la durée de conservation des données sauvegardées. Les calendriers de sauvegarde et les politiques de conservation qui ne sont pas liés à un objectif de restauration concret deviennent invariablement soit trop agressifs (entraînant un gaspillage de ressources de stockage et de calcul), soit trop peu fréquents (entraînant des périodes irrécupérables après une panne).
À quelle fréquence devez-vous sauvegarder etcd, les PV et les données d’application ?
Il n’est pas nécessaire de sauvegarder chaque composant à la même fréquence, comme on le croit souvent à tort. Etcd évolue constamment en fonction de l’état du cluster ; ainsi, un instantané toutes les heures suffit dans la plupart des environnements de production. Cependant, un cluster en évolution rapide, avec un taux de rotation élevé des déploiements ou des configurations, peut nécessiter des instantanés plus fréquents.
Les volumes persistants contenant des données transactionnelles ou générées par les utilisateurs doivent faire l’objet d’un instantané au moins aussi fréquemment que votre RPO le permet, car c’est là que résident les données les plus importantes sur le plan opérationnel. Les sauvegardes au niveau de l’application peuvent être moins fréquentes dans la plupart des cas, à condition que l’application elle-même présente un certain degré de tolérance pour la relecture d’événements ou la reconstruction d’état. Toutefois, cette tolérance doit être minutieusement validée par rapport au RPO actuel avant d’être intégrée à votre calendrier, plutôt que d’être considérée comme une hypothèse sûre.
Quelles fenêtres de conservation correspondent aux exigences RPO et RTO ?
Deux questions doivent guider la conservation :
- Jusqu’à quand devez-vous réellement pouvoir remonter pour effectuer une restauration ?
- À quelle vitesse devez-vous être en mesure de restaurer les données ?
Un RPO faible n’implique pas une longue durée de conservation ; par conséquent, conserver 30 jours de snapshots horaires est rarement pratique et s’avère souvent coûteux. Une meilleure pratique consisterait à utiliser une conservation par niveaux : des sauvegardes de courte durée et très fréquentes pour la reprise opérationnelle, combinées à des sauvegardes de plus longue durée mais moins fréquentes à des fins d’audit ou de conformité. L’essentiel est que les fenêtres de conservation soient explicitement approuvées par le responsable du SLA de reprise, et non décidées unilatéralement par l’équipe chargée des sauvegardes.
Comment le cycle de vie et la hiérarchisation peuvent-ils réduire les coûts de sauvegarde ?
Les coûts de stockage des sauvegardes pour les clusters Kubernetes peuvent grimper en flèche, en particulier lorsque l’on travaille avec des volumes persistants volumineux ou des instantanés fréquents. La mise en œuvre d’une politique de cycle de vie permet de réduire considérablement les coûts sans diminuer votre capacité de restauration.
Les politiques de cycle de vie archivent automatiquement les sauvegardes vers des niveaux de stockage moins coûteux à mesure qu’elles vieillissent – en passant, par exemple, d’un stockage en blocs haute performance à un stockage objet après une certaine période. Cela s’accompagne toutefois d’un compromis, car les niveaux de stockage moins coûteux sont généralement associés à des délais de restauration plus longs.
Avant de mettre en œuvre des politiques de cycle de vie, il est important de vérifier les délais de récupération pour chacun des niveaux moins coûteux et de voir si cela correspond à votre RTO pour les points de restauration plus anciens. La plupart des grands fournisseurs de cloud intègrent une prise en charge native des politiques de cycle de vie dans leurs solutions de stockage objet ; la mise en œuvre de telles politiques ne devrait donc poser que peu ou pas de difficulté dans la plupart des cas, une fois que vous avez déterminé votre période de conservation.
Comment sécuriser les sauvegardes Kubernetes et respecter les exigences de conformité ?
La planification des sauvegardes n’est qu’une pièce du puzzle opérationnel. La protection effective des sauvegardes elles-mêmes et la démonstration de la conformité aux législations de gouvernance applicables constituent deux défis distincts qui sont souvent abordés trop tard dans le cycle de vie. La valeur intrinsèque des données de sauvegarde – en tant que reflet complet de l’infrastructure – en fait une cible attrayante, et l’on accorde de plus en plus d’importance aux exigences de gouvernance qui s’y rapportent.
Comment les données de sauvegarde doivent-elles être chiffrées au repos et en transit ?
La décision architecturale cruciale dans ce contexte ne porte pas vraiment sur le choix de l’algorithme de chiffrement à utiliser (puisque la plupart des produits de sauvegarde actuels ont un paramètre par défaut que vous devriez de toute façon conserver), mais plutôt sur la garantie que le chiffrement est appliqué de bout en bout.
Si les données au repos sont chiffrées mais que le transfert entre le cluster et la cible de stockage n’est pas chiffré, les données ne seront pas sécurisées pendant le transfert. Si les clés de chiffrement sont stockées à proximité immédiate des données de sauvegarde qu’elles chiffrent, elles risquent également de ne pas être sécurisées.
Les clés de chiffrement doivent être stockées séparément de la cible de sauvegarde, que ce soit à l’aide d’un service de gestion des clés ou d’un module de sécurité matériel. L’accès à ces clés ne doit également être géré que par une entité autorisée à accéder à la sauvegarde elle-même.
Qui doit avoir accès aux fonctionnalités de sauvegarde et de restauration ?
L’accès à la restauration est souvent assimilé à l’accès à la sauvegarde, mais ces deux opérations ont des implications en matière de risque totalement différentes. La capacité de restaurer une sauvegarde vers un cluster ou un espace de noms potentiellement distinct équivaut à pouvoir déplacer des données sensibles, et implique donc des exigences de contrôle plus strictes que celles requises pour la simple création de la sauvegarde elle-même.
Dans la pratique, la création de sauvegardes peut raisonnablement être automatisée et largement autorisée, tandis que les opérations de restauration devraient nécessiter une autorisation explicite – idéalement avec un deuxième approbateur pour les environnements de production. Cette distinction doit se refléter dans votre configuration RBAC et être documentée de manière suffisamment claire pour résister aux changements d’équipe.
Quelles fonctionnalités d’audit, de journalisation et d’immuabilité sont nécessaires pour la conformité ?
Outre la garantie de l’existence des sauvegardes, les cadres de conformité exigeront également qu’une entreprise puisse prouver leur existence. Chaque opération de sauvegarde, tentative d’accès et demande de restauration devra être vérifiable et conservée conformément aux exigences de votre cadre – ce qui signifie que les journaux doivent être rédigés de manière inviolable.
Le stockage immuable, qui empêche la suppression ou la modification des données de sauvegarde pendant une durée déterminée, devient rapidement une obligation plutôt qu’une option dans les environnements gérant des informations privées ou financières – et les normes HIPAA et SOC 2 mentionnent spécifiquement sa nécessité.
Cela signifie également qu’il faut accorder une importance égale à la fois à la piste d’audit et aux données sauvegardées : les données dont vous ne pouvez pas prouver la conformité ont moins de valeur lorsque les auditeurs se présentent.
Méthodologie pour choisir la meilleure solution de sauvegarde Kubernetes possible
Il existe un grand nombre de solutions tierces différentes offrant, d’une manière ou d’une autre, des capacités de sauvegarde Kubernetes. La sauvegarde K8s est une tâche très importante, de sorte que le choix d’une solution de sauvegarde revêt une importance tout aussi grande. En conséquence, nous pouvons vous proposer une méthodologie approfondie sur la manière de choisir la meilleure solution de sauvegarde Kubernetes possible pour votre organisation spécifique.
Types de données pris en charge par la solution
Vérifier si la solution de sauvegarde offre la prise en charge d’un type de données requis est une priorité pour toute entreprise ou organisation à la recherche d’une solution de sauvegarde Kubernetes. À ce titre, nous avons ajouté des informations sur les types de données dont chaque solution de notre liste peut créer une sauvegarde. Le résultat global de cette comparaison est présenté ci-dessous dans un tableau (le tableau en question est divisé en deux parties pour faciliter la lecture).
Tableau #1
| Les logiciels | Kasten | Portworx | Cohésité | OpenEBS | Veritas |
| Déploiements | Oui | Oui | Oui | Oui | Oui |
| StatefulSets | Oui | Oui | Oui | Oui | Oui |
| DaemonSets | Oui | Oui | Oui | Oui | Oui |
| Pods | Oui | Oui | Oui | Oui | Oui |
| Services | Oui | Oui | Oui | Oui | Oui |
| Secrets et/ou ConfigMaps | Oui | Oui | Oui | Oui | Oui |
| Volumes persistants | Oui | Oui | Oui | Pas de données | Oui |
| Espaces de noms | Oui | Oui | Oui | Pas de données | Oui |
| Applications | Oui (Intégrations) | Pas de données | Oui (Messagerie + Bases de données) | Pas de données | Pas de données |
| Infrastructure de stockage | Pas de données | Pas de données | Oui | Pas de données | Pas de données |
Tableau #2
| Les logiciels | Stash | Rubrik | Druva | Zerto | Longhorn |
| Déploiements | Oui | Oui | Oui | Oui | Oui |
| StatefulSets | Oui | Oui | Oui | Oui | Oui |
| DaemonSets | Oui | Oui | Oui | Oui | Oui |
| Pods | Oui | Oui | Oui | Oui | Oui |
| Services | Oui | Oui | Oui | Oui | Oui |
| Secrets et/ou ConfigMaps | Oui | Oui | Oui | Oui | Oui |
| Volumes persistants | Oui | Oui | Oui | Oui | Oui |
| Espaces de noms | Oui | Oui | Oui | Oui | Pas de données |
| Applications | Pas de données | Oui (Bases de données) | Oui (Bases de données) | Pas de données | Pas de données |
| Infrastructure de stockage | Pas de données | Oui | Pas de données | Pas de données | Pas de données |
Il convient de noter que la prise en charge de différents types de données est un facteur important, mais qu’il n’est pas rédhibitoire la plupart du temps. Il est donc fortement recommandé de considérer ce facteur comme un élément parmi d’autres dans cette comparaison.
Évaluations des clients
Ces évaluations peuvent être interprétées de différentes manières : la qualité de la solution dans son travail, sa capacité à prendre en compte les commentaires des clients, sa capacité (ou son incapacité) à évoluer dans le temps, etc. Dans notre cas, les évaluations des clients provenant de sites web tiers existent pour montrer la compétence globale de la solution en utilisant divers sites web de collecte d’avis tels que Capterra, TrustRadius et G2.
Capterra est une plateforme d’agrégation d’avis qui propose des avis vérifiés, des conseils, des points de vue et des comparaisons de solutions. Les clients de Capterra font l’objet d’une vérification minutieuse afin de s’assurer qu’ils sont bien de vrais clients de la solution en question, et les fournisseurs n’ont pas la possibilité de supprimer les avis de leurs clients. Capterra contient plus de 2 millions d’avis vérifiés dans près d’un millier de catégories différentes, ce qui en fait une excellente option pour trouver toutes sortes d’avis sur un produit spécifique.
TrustRadius est une plateforme d’avis qui proclame son engagement en faveur de la vérité. Elle utilise un processus en plusieurs étapes pour garantir l’authenticité des avis, et chaque avis est également vérifié pour être détaillé, approfondi et complet par l’équipe de recherche de l’entreprise. Les fournisseurs n’ont aucun moyen de cacher ou de supprimer les avis des utilisateurs d’une manière ou d’une autre.
G2 est un autre bon exemple de plateforme d’agrégation d’avis qui s’enorgueillit de plus de 2,4 millions d’avis vérifiés à ce jour avec plus de 100 000 vendeurs différents présentés. G2 dispose de son propre système de validation des avis d’utilisateurs, qui s’avère extrêmement efficace pour prouver que chaque avis est authentique. G2 propose également des services distincts à des fins de marketing, d’investissement, de suivi, etc.
Caractéristiques clés (et avantages/inconvénients)
La liste des facteurs importants qu’une solution de sauvegarde Kubernetes compétente doit posséder comprend les éléments suivants :
- Une grande disponibilité des données pour une meilleure reprise après sinistre et une plus grande tolérance aux divers problèmes liés aux clusters et aux conteneurs.
- Différents types de sauvegarde, y compris les sauvegardes incrémentielles et app-aware.
- Granularité de la sauvegarde, avec la possibilité de créer des sauvegardes d’objets spécifiques, et pas seulement des namestates entiers (volumes, pods, PV, etc.).
- Planification des sauvegardes pour des opérations quotidiennes plus simples.
- Intégration avec les fournisseurs de stockage dans le cloud (Azure Blob, GCP, S3, etc.) pour un processus de sauvegarde plus simple et une plus grande variété en termes de stockage de sauvegarde.
- Capacités de chiffrement des données pour une meilleure protection des informations.
- La prise en charge des charges de travail personnalisées offre la possibilité d’étendre les fonctionnalités de sauvegarde via des plugins et des intégrations.
Ceci est également représenté par la catégorie « avantages/inconvénients » (le cas échéant), présentant à la fois les points positifs et négatifs de la solution recueillis à partir d’une multitude d’avis d’utilisateurs.
Prix
Les fonctionnalités d’une solution sont importantes pour l’utilisateur final, mais le prix l’est tout autant. Certaines entreprises disposent d’un budget très limité, tandis que d’autres ont besoin d’un ensemble de fonctionnalités spécifiques malgré un prix potentiellement élevé. Toutefois, la plupart des clients potentiels se situent entre ces deux exemples. Il est fortement recommandé de vérifier à la fois le prix et l’ensemble des fonctionnalités de la solution tout en les comparant les unes aux autres – même si la solution est dans votre budget, il se peut qu’elle ne soit pas aussi avantageuse que ses concurrents en termes de fonctionnalités.
Une opinion personnelle de l’auteur
La seule partie complètement subjective de cette méthodologie est l’opinion de l’auteur sur le sujet (solution de sauvegarde Kubernetes, dans notre cas). Il existe de nombreux cas d’utilisation différents pour cette catégorie particulière, y compris des informations intéressantes sur la solution qui ne correspondaient à aucune des catégories précédentes ou simplement l’opinion personnelle de l’auteur sur ce sujet spécifique.
Marché des solutions de sauvegarde Kubernetes
Dans le contexte de ces trois facteurs/caractéristiques importants, examinons quelques autres exemples de solution de sauvegarde et de restauration Kubernetes.
Kasten K10

Kasten K10 (récemment acquis par Veeam) est une solution de sauvegarde et de restauration qui s’enorgueillit également de ses systèmes de mobilité et de reprise après sinistre. Avec Kasten, le processus de sauvegarde est simplifié grâce à sa capacité à découvrir automatiquement les applications, ainsi qu’à de nombreuses autres fonctionnalités, telles que le chiffrement des données, le contrôle d’accès basé sur les rôles et une interface conviviale. En même temps, il peut fonctionner avec de nombreux services de données différents, tels que MySQL, PostgreSQL, MongoDB, Cassandra, AWS, etc.
La haute disponibilité locale n’est pas disponible, car Kasten ne prend pas directement en charge la réplication au sein d’un cluster unique et s’appuie plutôt sur les systèmes de stockage de données sous-jacents. La reprise après sinistre n’est que partiellement assurée, car Kasten ne peut pas atteindre un RPO nul en raison de l’absence d’un composant de chemin d’accès aux données. Il convient également de noter que les sauvegardes de Kasten sont uniquement asynchrones, ce qui représente généralement un temps d’arrêt supplémentaire entre les opérations.
Types de données couverts par Kasten K10:
Kasten K10 peut créer des sauvegardes de -usuellement- toutes les données que Kubernetes génère, y compris les Services, les Déploiements, les PV, les Namespaces, et ainsi de suite. Il n’y a que deux exceptions ici – la couverture des Applications de Kasten peut également être étendue et améliorée via des Intégrations avec d’autres solutions de sauvegarde et de récupération.
Cotes des clients:
- (Kasten) G2 – 4.7/5 étoiles basées sur 10 évaluations de clients.
- (Veeam) Capterra – 4.8/5 étoiles basées sur 69 évaluations de clients.
- (Veeam) TrustRadius – 8.8/10 étoiles basées sur 1,237 avis clients.
- (Veeam) G2 – 4.6/5 étoiles basées sur 387 évaluations de clients
Caractéristiques principales:
- Une évolutivité et une efficacité impressionnantes
- Protection très efficace contre les ransomwares
- Créé selon les principes de l’architecture cloud-native
Tarification (au moment de la rédaction):
- La page de tarification de Kasten K10 prétend qu’il existe trois éditions du logiciel (bien qu’il n’y ait qu’une seule édition réelle, les deux autres étant respectivement la version gratuite et la version d’essai).
- « Free » est une version très limitée de Kasten K10 avec des capacités de sauvegarde Kubernetes minimales, y compris jusqu’à 5 nœuds au maximum, ainsi que des opérations de sauvegarde/restauration, la reprise après sinistre, la protection contre les ransomwares et la plupart des autres capacités de Kasten.
- « Enterprise Trial » est la version de Kasten d’un essai gratuit chronométré, offrant l’ensemble des fonctionnalités de Kasten, une limite supérieure de 50 nœuds, ainsi que le support client, le déploiement assisté par Kasten et l’évaluation de la protection des données.
- « Enterprise » est le seul niveau d’abonnement réel de Kasten K10 ; il supprime complètement la limitation du « nombre de nœuds » et offre l’ensemble complet des fonctionnalités de Kasten en matière de sauvegarde et de restauration.
- Il convient de noter qu’aucune information sur les prix n’est disponible sur le site officiel de Kasten, ce qui signifie que la seule façon d’obtenir de telles informations est de demander un devis personnalisé à l’entreprise en question.
Mon opinion personnelle sur Kasten K10:
Kasten K10 est une solution de sauvegarde plutôt performante qui prend en charge divers types d’environnements, notamment Kubernetes, Cassandra, PostgreSQL, MySQL et bien d’autres encore. Elle a par ailleurs été récemment rachetée par Veeam, l’une des solutions de sauvegarde d’entreprise les plus connues du marché. Kasten a réussi à conserver son nom jusqu’à présent, se présentant la plupart du temps sous le nom de « Kasten by Veeam ». Ce n’est pas une mauvaise solution en soi, mais ses capacités liées à Kubernetes sont plutôt basiques et limitées. Elle transpose la plupart de ses fonctionnalités générales aux sauvegardes Kubernetes, telles que le chiffrement des données et le RBAC, mais la création de ces sauvegardes n’est pas un processus simple. Kasten n’offre pas de haute disponibilité locale pour Kubernetes, sa mise en œuvre de la reprise après sinistre n’est que partielle (RPO non nuls), et toutes les sauvegardes sont strictement asynchrones.
Portworx

Portworx PX-Backup est une entreprise de gestion de données qui développe une plateforme de stockage basée sur le cloud pour gérer et accéder à la base de données pour les projets Kubernetes. C’est un autre exemple de solution de gestion de données et, malgré ses limites en tant que telle, l’un des principaux avantages de l’utilisation de Portworx est la haute disponibilité des données.
Opérations de sauvegarde et de récupération, compréhension des apps Kubernetes, haute disponibilité locale et reprise après sinistre, entre autres fonctionnalités – tout cela fait de Portworx une bonne solution pour la sauvegarde Kubernetes. Compte tenu de la diversité des solutions tierces de sauvegarde Kubernetes, Portworx peut également être intéressant pour un utilisateur qui recherche spécifiquement des fonctionnalités de sauvegarde Kubernetes.
Une autre partie importante de PX-Backup est son évolutivité, permettant des sauvegardes à la demande / des sauvegardes planifiées de centaines d’applications à la fois. La solution prend également en charge les configurations multi-bases de données et peut restaurer les applications directement sur les services cloud, tels qu’Amazon, Google, Microsoft, etc.
Types de données couverts par Portworx:
Portworx prend en charge la création de sauvegardes pour les Namespaces, les PV, les DaemonSets, les Deployments, et plus encore. T-I n’a pas pu trouver d’informations indiquant s’il peut ou non prendre en charge la sauvegarde des applications ou la sauvegarde de l’infrastructure de stockage.
Cotes des clients:
- G2 – 4.4/5 étoiles sur la base de 16 avis de clients.
Avantages:
- Solution de sauvegarde performante et fiable.
- Infrastructure évolutive et fiable
- Cryptage des données et contrôle d’accès détaillé
Points faibles :
- La configuration du logiciel dans son ensemble peut être quelque peu compliquée.
- L’expérience de l’assistance à la clientèle n’est pas homogène.
- Les capacités de sécurité sont limitées dans le contexte des déploiements de grandes entreprises.
Tarification (au moment de la rédaction):
- Le modèle de tarification de Portworx est assez simple – il existe une version gratuite disponible pour tous les utilisateurs qui créent un compte Portworx ; cette version est limitée à 1 cluster et jusqu’à 1 TB de données d’application
- Il existe également une version payante du logiciel avec un ensemble complet de fonctionnalités, y compris les sauvegardes app-aware, la restauration en un seul clic, la protection contre les ransomwares, etc. Malheureusement, aucun prix officiel n’est disponible sur le site web de Portworx ; il ne peut être obtenu qu’en contactant directement l’entreprise pour un devis personnalisé.
Mon avis personnel sur Portworx :
Portworx se présente comme une plateforme de services de données, offrant de nombreuses capacités qui sont principalement centrées sur Kubernetes et ses conteneurs. La plateforme Portworx peut offrir de nombreux services, notamment la sauvegarde, la reprise après sinistre, le stockage, DevOps et la base de données. Les sauvegardes Portworx offrent une haute disponibilité, une sensibilisation aux applications et de nombreuses fonctionnalités qui ne sont généralement pas disponibles dans les offres de sauvegarde Kubernetes. Il s’agit d’une solution rapide et évolutive, mais elle a aussi ses inconvénients. Un exemple de ces inconvénients est une présence globale plutôt limitée sur le marché, ce qui crée de nombreux facteurs d’inconfort, tels que le manque de tutoriels détaillés sur Internet. La solution en question peut également être assez compliquée, ce qui rend son utilisation difficile pour les nouveaux venus dans ce domaine.
Cohesity

Cohesity est un concurrent relativement populaire dans le domaine de la sauvegarde et de la restauration générales, mais ses capacités liées à Kubernetes ont encore une certaine marge de progression. Tout d’abord, Kubernetes est un ajout relativement nouveau pour eux, en ce sens qu’ils ont ajouté la compréhension des applications Kubernetes. Cependant, cela ne fonctionne que pour toutes les applications au sein du même espace de noms, et il n’est pas possible de protéger des applications spécifiques au sein de cet espace de noms.
D’autre part, il existe également des capacités de récupération rapide, des sauvegardes incrémentielles app-tier basées sur des politiques, la consolidation de l’état des données, et bien d’autres capacités.
Types de données couverts par Cohesity :
La solution de Cohesity prend en charge les sauvegardes de Namespace, les sauvegardes de service, les sauvegardes de déploiement, et plus encore. Il y a un support pour la sauvegarde de l’infrastructure de stockage, et le seul facteur notable pour cette catégorie est que la sauvegarde des applications de Cohesity peut également couvrir les bases de données dans lesquelles les apps travaillent, ainsi que les systèmes de messagerie déployés dans Kubernetes.
Notes des clients :
- Capterra – 4,6/5 étoiles sur la base de 48 avis de clients.
- TrustRadius – 8,9/10 étoiles basées sur 59 examens clients.
- G2 – 4,4/5 étoiles sur la base de 45 examens clients.
Avantages:
- Gestion simple et pratique de la sauvegarde et de la récupération.
- Processus d’installation et de configuration initiaux simples et indolores
- li>La planification facile à l’aide de la création de profils permet une plus grande automatisation.
- Sauvegardes incrémentielles adaptées aux applications, capacités de récupération rapide pour les apps Kubernetes, etc.
Points faibles :
- Certaines mises à jour doivent être installées manuellement à l’aide d’une ligne de commande, ce qui contraste fortement avec l’installation automatique habituelle des mises à jour basée sur l’interface graphique.
- Les « sauvegardes immuables » de Cohesity peuvent encore être modifiées ou supprimées par un utilisateur disposant d’informations d’identification de niveau administrateur.
- L’assistance à la clientèle repose en grande partie sur des réponses standard et peut s’avérer peu utile.
- La fonctionnalité de sauvegarde Kubernetes est relativement nouvelle pour Cohesity, et elle peut être un peu rugueuse sur les bords.
Tarification (au moment de la rédaction):
- Les informations sur les prix de Cohesity ne sont pas disponibles publiquement sur leur site Web officiel et la seule façon d’obtenir de telles informations est de contacter directement la société pour un essai gratuit ou une démo guidée.
- Les informations non officielles sur la tarification de Cohesity indiquent que ses appliances matérielles seules ont un prix de départ de 110 000 USD.
Mon opinion personnelle sur Cohesity:
Cohesity est une solution de sauvegarde et de récupération solide qui prend en charge un certain nombre de types de stockage différents tout en offrant de nombreuses fonctionnalités à travailler. L’ensemble de la solution est construit à l’aide d’une structure inhabituelle de type nœud qui rend Cohesity extrêmement facile à mettre à l’échelle dans les deux sens. Elle est rapide, polyvalente et constitue une excellente option pour créer des sauvegardes d’infrastructures applicatives. En ce qui concerne les capacités liées à Kubernetes en particulier, elles pourraient certainement être améliorées à l’avenir, car la prise en charge de Kubernetes est un ajout relativement nouveau à Cohesity, et certaines nuances sont encore en cours d’aplanissement sur une base régulière. Il ne peut protéger que les données d’application du même espace de noms, et il n’y a pas d’option pour protéger des applications spécifiques, mais seulement l’espace de noms entier. Dans le même temps, Cohesity peut offrir un assez grand nombre de ses propres capacités qui sont maintenant applicables aux sauvegardes Kubernetes, y compris la consolidation de l’état des données, la prise en charge des sauvegardes incrémentielles, et plus encore.
OpenEBS

OpenEBS est un autre exemple de solution qui a réussi à obtenir des résultats avec une seule des trois fonctionnalités de notre liste, et dans ce cas, il s’agit de la haute disponibilité locale.
Par ailleurs, OpenEBS peut également s’intégrer à Velero, créant ainsi une solution Kubernetes combinée particulièrement performante en matière de migration de données Kubernetes. À lui seul, OpenEBS ne permet de sauvegarder que des applications individuelles (ce qui est tout le contraire de ce que fait Cohesity). Il offre également des fonctionnalités telles que le stockage multicloud, son caractère open source et une longue liste de plateformes Kubernetes prises en charge, allant d’AWS et Digital Ocean à Minikube, Packet, Vagrant, GCP, et bien d’autres encore.
Cependant, cela peut ne pas couvrir les besoins d’un utilisateur puisque certains utilisateurs pourraient avoir besoin de ces sauvegardes d’espace de noms dans des cas d’utilisation spécifiques.
Types de données couverts par OpenEBS:
OpenEBS est une solution assez polyvalente ; elle peut créer des sauvegardes de déploiements entiers, ainsi que de Pods, ConfigMaps, StatefulSets, etc. Cependant, elle est plutôt limitée par rapport à d’autres, notamment l’absence de sauvegarde de l’infrastructure de stockage, l’absence de sauvegarde des applications, et l’absence de sauvegardes au niveau Namespace et au niveau PV.
Caractéristiques principales:
- Uses Container Attached Storage patterns for better backup efficiency
- Allows stateful applications to have quick and easy access to both Replicated PVs and Dynamic Local PVs
- Simplifies cross-cloud application management, including storage replication and automated provisioning
Tarification (au moment de la rédaction):
- OpenEBS est une solution gratuite et open-source, mais il existe également des individus et des entreprises tiers qui peuvent fournir des services ou des produits liés à OpenEBS d’une manière ou d’une autre.
Mon opinion personnelle sur OpenEBS:
OpenEBS offre ici un contraste saisissant avec Cohesity : il s’agit d’une solution de gestion des données relativement modeste qui se concentre spécifiquement sur les environnements Kubernetes, tout en axant l’essentiel de ses fonctionnalités sur la haute disponibilité locale des données, qui constitue sa principale caractéristique. Ce logiciel s’intègre facilement à Velero, un autre logiciel open source gratuit à petite échelle qui offre bien plus en matière de sauvegardes Kubernetes. Ce type d’intégration donne naissance à une solution de sauvegarde et de gestion des données assez puissante (et gratuite) qui fonctionne avec diverses plateformes Kubernetes, prend en charge le stockage multicloud, offre des capacités de migration des données, etc. Comme pour pratiquement toute solution gratuite de cette envergure, le principal problème d’OpenEBS (et de Velero) réside dans une courbe d’apprentissage assez raide qui rend la prise en main difficile au début et augmente considérablement le temps nécessaire pour maîtriser toutes les fonctionnalités de la solution.
Veritas

Veritas est un fournisseur de logiciels de sauvegarde bien établi sur le marché depuis plusieurs décennies ; il est largement préféré par les entreprises plus anciennes et plus grandes pour cette raison précise. Il peut offrir de nombreuses fonctionnalités et capacités différentes tout en prenant en charge une variété de types de stockage cible allant du stockage physique aux VM, aux bases de données, au stockage dans le cloud, et plus encore. En ce qui concerne ses capacités Kubernetes – Veritas peut offrir des capacités de journalisation étendues, une administration simple mais efficace, une prise en charge RBAC, une haute disponibilité des données, une réplication des données, et bien d’autres. C’est une excellente option pour les tâches de sauvegarde et de récupération dans leur ensemble, apportant protection des données et richesse des fonctionnalités dans un seul package.
Types de données couverts par Veritas :
Les capacités de Veritas dans le domaine des sauvegardes Kubernetes sont plutôt impressionnantes, y compris la couverture des espaces de noms, des déploiements, des secrets, des pods, etc. Cependant, il n’a pas la capacité d’effectuer des sauvegardes d’applications, et on pourrait dire la même chose pour les sauvegardes de l’infrastructure de stockage.
Cotes des clients:
- Capterra – 4,0/5 étoiles sur la base de 7 avis de clients.
- TrustRadius – 6,8/10 étoiles sur la base de 150 avis de clients.
- G2 – 4.1/5 étoiles basées sur 230 avis de clients
Avantages:
- Une gamme de fonctionnalités extrêmement vaste et variée, souvent considérée comme l’une des plus complètes du marché.
- L’état visuel relativement dépassé de l’interface ne change rien au fait qu’elle est facile à utiliser pour tous les types de clients, y compris les nouveaux venus dans ce domaine.
- L’expérience de l’assistance clientèle a recueilli de nombreuses critiques positives au fil des ans, l’équipe d’assistance fournissant des réponses rapides et concises à une grande variété de problèmes.
Points faibles :
- Le système de gestion des rapports est quelque peu rigide, il n’y a aucun moyen de personnaliser le chemin d’accès au fichier cible pour les rapports créés automatiquement.
- L’intégration des bibliothèques de bandes LTO est disponible dans une certaine mesure, mais elle présente jusqu’à présent un certain nombre de défauts graves.
- L’exportation de rapports dans son ensemble est plutôt difficile à réaliser.
Tarification (au moment de la rédaction):
- Il n’y a pas d’informations officielles sur les prix sur le site Web de Veritas, le seul moyen d’obtenir de telles informations est de contacter directement la société.
Mon opinion personnelle sur Veritas:
Veritas est souvent loué comme l’une des solutions de sauvegarde et de récupération les plus anciennes du marché, qui est toujours en forme et en concurrence avec d’autres solutions de premier plan. Cela ne veut pas dire que l’âge est le seul avantage que Veritas peut offrir – il dispose également d’un ensemble de fonctionnalités extrêmement large, d’une interface conviviale impressionnante et d’une équipe de support client extrêmement serviable. Veritas parvient également à simplifier et à améliorer considérablement divers aspects de la gestion des conteneurs Kubernetes – notamment les fonctionnalités de sauvegarde et de récupération des données des conteneurs, le basculement automatique et le failback, la répartition du trafic entre les instances, la découverte automatique des espaces de noms, et bien plus encore. Veritas offre des opérations de sauvegarde et de récupération faciles et accessibles aux applications conteneurisées, ce qui en fait une solution de sauvegarde Kubernetes plutôt pratique. Veritas a quelques problèmes avec son système de reporting dans son ensemble, et son intégration de bande LTO est plutôt problématique, mais aucun de ces problèmes n’affecte suffisamment les capacités liées à Kubernetes pour constituer un véritable problème pour les utilisateurs actuels et futurs. Dans l’ensemble, le prix peut être un obstacle.
Stash

Stash est une solution de sauvegarde et de reprise après sinistre qui a été construite spécifiquement pour Kubernetes en premier lieu. Elle peut restaurer les données Kubernetes à plusieurs niveaux différents, y compris les bases de données (MongoDB, MySQL, PostgreSQL), les volumes (ensembles avec état, déploiements, volumes autonomes) et même les ressources Kubernetes ordinaires (secrets, configs YAML, etc.). Il prend en charge un certain nombre d’options d’automatisation, peut être intégré à plusieurs fournisseurs de stockage dans le cloud, prend en charge des charges de travail personnalisées, et plus encore. Il s’agit également d’une solution relativement nouvelle dans ce domaine, qui présente donc quelques problèmes de croissance ici et là.
Types de données couverts par Stash:
Stash est une solution de sauvegarde relativement petite, mais sa couverture Kubernetes est tout de même assez impressionnante – avec un support pour les déploiements, les services, les Pods, les DaemonSets, et même les sauvegardes de l’infrastructure de stockage. Cependant, il ne peut pas créer de copies de Kubernetes au niveau de l’espace de nommage, et il n’y a pas non plus de prise en charge de la sauvegarde des applications.
Caractéristiques principales :
- La prise en charge de la fonctionnalité VolumeSnapshotter de CSI permet d’élargir de manière assez significative les options de sauvegarde Kubernetes de Stash.
- La capacité d’être intégré avec l’outil Restic apporte des fonctionnalités telles que la déduplication, le chiffrement, les sauvegardes incrémentielles, et plus encore.
- Stash peut fonctionner avec un certain nombre de fournisseurs de stockage dans le cloud comme stockage de sauvegarde – Azure Blob, GCP, AWS S3, etc.
- Il existe de nombreuses options de planification disponibles, qui peuvent toutes être personnalisées de multiples façons.
Tarification (au moment de la rédaction):
- Il n’y a pas d’informations officielles sur les prix disponibles sur le site Web de Stash, mais il y a une invite « contactez-nous », ce qui signifie que toutes les informations sur les prix sont hautement personnalisées et ne peuvent pas être obtenues par des moyens publics.
Mon opinion personnelle sur Stash:
Stash pourrait bien être la solution de sauvegarde la moins connue de cette liste. C’est une solution de sauvegarde et de reprise après sinistre à très petite échelle pour Kubernetes spécifiquement et rien d’autre. Stash peut fonctionner avec les ressources Kubernetes, les volumes et même les bases de données, offrant la possibilité de créer des sauvegardes de nombreux environnements et types de données – de MongoDB et PostgreSQL aux configurations YAML des déploiements. Il s’agit d’une solution rapide avec de nombreuses capacités centrées sur Kubernetes qui sont rares dans d’autres solutions de sauvegarde. Par exemple, Stash prend en charge la fonctionnalité CSI VolumeSnapshotter, et il peut également être intégré à l’outil Restic pour des opérations de protection des données meilleures et plus polyvalentes. Stash est encore en cours de développement, mais il est très prometteur pour l’avenir, et la complexité globale de la solution est probablement le plus gros problème actuel – un problème qui peut être résolu avec du temps et des efforts.
Rubrik

Pas mal d’autres acteurs plus importants dans le domaine de la sauvegarde et de la restauration ont commencé à offrir leurs propres services en termes de sauvegarde et de restauration Kubernetes – Rubrik en est un bon exemple : il permet aux utilisateurs de mettre en œuvre le vaste ensemble de fonctionnalités de gestion de Rubrik dans le domaine des déploiements Kubernetes.
Il permet une flexibilité en termes de destination de restauration, ainsi que la protection des objets Kubernetes et une plateforme unifiée qui fournit des informations et une vue d’ensemble de l’ensemble du système. Il existe également des fonctionnalités telles que l’automatisation des sauvegardes, la restauration granulaire, la réplication des snapshots, et plus encore. Rubrik peut également travailler avec Persistent Volumes et est capable de répliquer les espaces de noms – vous offrant une variation lorsqu’il s’agit de développement et de test avant le déploiement.
Types de données couverts par Rubrik:
Rubrik est l’une des meilleures options de cette liste quand il s’agit de tous les types de données Kubernetes dont il peut créer une sauvegarde. Cela inclut les déploiements, les espaces de noms, l’infrastructure de stockage, les services, les pods, les StatefulSets et pratiquement tout le reste. Le seul facteur qui mérite d’être noté ici est que Druva peut couvrir à la fois les applications et les bases de données qu’elles utilisent.
Cotes des clients:
- Capterra – 4,7/5 étoiles sur la base de 45 avis de clients.
- TrustRadius – 9.1/10 étoiles basées sur 198 avis clients
- G2 – 4.6/5 étoiles basées sur 59 évaluations de clients.
Avantages:
- Une solution de sauvegarde et de récupération polyvalente et performante.
- Une variété d’intégrations avec d’autres services et technologies, tels que SQL Server, VMware, M365, etc.
- Capacités de protection des données fiables avec un bon chiffrement, une sécurité forte et un ransomware.
- Prise en charge de nombreuses fonctionnalités pour les applications Kubernetes, y compris la réplication de clichés, l’automatisation de la sauvegarde, la récupération granulaire, et bien d’autres.
Carences:
- L’implémentation de RBAC est quelque peu basique et manque de nombreuses fonctionnalités nécessaires que les concurrents possèdent.
- La personnalisation de l’audit/des rapports est très limitée et les rapports ne sont pas assez détaillés, en général.
- Le coût global de la solution peut être trop élevé pour les petites et moyennes entreprises.
- Extensibilité limitée
Tarification (au moment de la rédaction):
- Les informations sur les prix de Rubrik ne sont pas disponibles sur leur site officiel et le seul moyen d’obtenir de telles informations est de contacter l’entreprise directement pour une démonstration personnalisée ou une des visites guidées.
- Les informations non officielles indiquent qu’il existe plusieurs appliances matérielles différentes que Rubrik peut proposer, telles que :
- Rubrik R334 Node – à partir de 100 000 $ pour un 3-nœuds avec des processus Intel à 8 cœurs, 36 To de stockage, etc.
- Rubrik R344 Node – à partir de 200 000 $ pour un 4-nœuds avec des paramètres similaires au R334, 48 TB de stockage, etc.
- Rubrik R500 Series Node – à partir de 115 000 $ pour un 4-nœuds avec des processeurs Intel 8-Core, 8×16 DIMM de mémoire, etc.
Mon opinion personnelle sur Rubrik:
Les capacités de Rubrik en termes de Kubernetes spécifiquement ne sont peut-être pas particulièrement étendues, mais la solution elle-même est bien connue et respectée dans l’industrie, fournissant une plate-forme de sauvegarde et de récupération sophistiquée avec un nombre massif de capacités. Rubrik peut offrir une protection, une migration de données et un support général pour les instances Kubernetes, principalement en étendant ses propres fonctionnalités existantes pour couvrir les environnements Kubernetes. Rubrik peut répliquer les espaces de noms et travailler avec Persistent Volumes, ce qui en fait une offre plutôt intéressante à considérer pour les grandes entreprises. Cependant, il serait juste de mentionner que Rubrik a sa propre part d’inconvénients qui doivent encore être corrigés, y compris une évolutivité quelque peu basique, un système de rapport/audit rigide, et une étiquette de prix assez élevée dans l’ensemble.
Druva

Une autre variante d’une telle solution est présentée par Druva, fournissant une solution de sauvegarde et de restauration Kubernetes plutôt simple mais efficace avec toutes les fonctionnalités de base attendues – snapshots, sauvegarde et restauration, automatisation, et quelques fonctionnalités supplémentaires. Druva peut également restaurer des applications entières dans Kubernetes, avec une grande mobilité en ce qui concerne la destination de la restauration.
En outre, Druva prend en charge plusieurs rôles d’administrateur, peut créer des copies des charges de travail à des fins de dépannage et peut sauvegarder des zones spécifiques telles que les espaces de noms ou les groupes d’applications. Il existe également une variété d’options de rétention, une protection complète des données Kubernetes, et un support pour Amazon EC2 et EKS (charges de travail de conteneur personnalisées).
Types de données couverts par Druva :
Aucune information ne permet de savoir si Druva prend en charge les sauvegardes de l’infrastructure de stockage Kubernetes. À part cela, il prend en charge pratiquement tout le reste – Namespaces, Pods, DaemonSets, StatefulSets, ConfigMaps, et même Persistent Volumes. Il peut également couvrir les applications et les bases de données qui sont associées à ces applications.
Cotes des clients:
- Capterra – 4,7/5 étoiles sur la base de 17 avis de clients.
- TrustRadius – 9,3/10 étoiles basées sur 419 avis de clients.
- G2 – 4.6/5 étoiles basées sur 416 avis de clients.
Avantages:
- L’interface utilisateur, dans son ensemble, reçoit beaucoup d’éloges.
- L’immutabilité des sauvegardes et le chiffrement des données ne sont que des exemples du sérieux de Druva en matière de sécurité des données.
- Le support client est rapide et utile.
- Protection des données, snapshots, sauvegardes automatisées et autres fonctionnalités pour les apps Kubernetes.
Points faibles :
- La première installation n’est pas facile à réaliser par soi-même.
- Les instantanés Windows et les sauvegardes de clusters SQL sont simplistes et à peine personnalisables.
- Vitesse de restauration lente à partir du nuage.
- L’évolutivité peut être limitée.
Prix (au moment de la rédaction):
- La tarification de Druva est assez sophistiquée et offre différents plans de tarification en fonction du type d’appareil ou d’application couvert.
- Charges de travail hybrides:
- « Hybrid business » – 210 $ par mois par téraoctet de données après déduplication, offrant une sauvegarde d’entreprise facile avec de nombreuses fonctionnalités telles que la déduplication globale, la récupération au niveau des fichiers VM, la prise en charge du stockage NAS, etc.
- « Hybrid enterprise » – 240 $ par mois par téraoctet de données après déduplication, une extension de l’offre précédente avec des fonctionnalités LTR (conservation à long terme), des aperçus/recommandations de stockage, un cache dans le cloud, etc.
- « Hybrid elite » – 300 $par mois par Téraoctet de données après déduplication, ajoute la reprise après sinistre dans le cloud à l’offre précédente, créant ainsi la solution ultime pour la gestion des données et la reprise après sinistre.
- Il existe également des fonctionnalités que Druva vend séparément, telles que la récupération accélérée des ransomwares, la reprise après sinistre dans le cloud (disponible pour les utilisateurs de Hybrid elite), la posture de sécurité & ; l’observabilité, et le déploiement pour le cloud du gouvernement américain
- Applications SaaS:
- « Business » – 2,5 $ par mois et par utilisateur, le package le plus basique de couverture des applis SaaS (Microsoft 365 et Google Workspace, le prix est calculé par applis unique), peut offrir 5 régions de stockage, 10 Go de stockage par utilisateur, ainsi qu’une protection des données de base.
- « Enterprise » – 4 $ par mois et par utilisateur pour une couverture soit de Microsoft 365 soit de Google Workspace avec des fonctionnalités telles que les groupes et les dossiers publics, ainsi qu’une couverture de Salesforce.com pour 3,5 $ par mois et par utilisateur (comprend la restauration des métadonnées, les sauvegardes automatisées, les outils de comparaison, etc.)
- « Elite » – 7 $ par mois et par utilisateur pour Microsoft 365/Google Workspace, 5,25 $ pour Salesforce, comprend la vérification de la conformité GDPR, l’activation de l’eDiscovery, la recherche fédérée, la prise en charge de GCC High, et de nombreuses autres fonctionnalités.
- Certaines fonctionnalités ici peuvent également être achetées séparément, telles que Sandbox seeding (Salesforce), Sensitive data governance (Google Workspace & ; Microsoft 365), GovCloud support (Microsoft 365), etc.
- Endpoints:
- « Enterprise » – 8 $ par mois et par utilisateur, peut offrir la prise en charge du SSO, CloudCache, la prise en charge du DLP, la protection des données par source de données et 50 Go de stockage par utilisateur avec une administration déléguée.
- « Elite » – 10 $ par mois et par utilisateur, ajoute des fonctionnalités telles que la recherche fédérée, la collecte de données supplémentaires, la suppression défendable, des capacités de déploiement avancées, et plus encore.
- Il existe également de nombreuses fonctionnalités qui pourraient être achetées séparément ici, notamment des capacités de déploiement avancées (disponibles dans le niveau d’abonnement Elite), la récupération/réponse aux ransomwares, la gouvernance des données sensibles et la prise en charge de GovCloud.
- Les charges de travail AWS:
- « Freemium » est une offre gratuite de Druva pour la couverture des charges de travail AWS ; elle peut couvrir jusqu’à 20 ressources AWS à la fois (pas plus de 2 comptes) tout en offrant des fonctionnalités telles que le clonage VPC, la DR inter-régions et inter-comptes, la récupération au niveau des fichiers, l’intégration des organisations AWS, l’accès API, etc.
- « Enterprise » – 7 $ par mois par ressource, à partir de 20 ressources, a une limite supérieure de 25 comptes et étend les capacités de la version précédente avec des fonctionnalités telles que le verrouillage des données, la recherche au niveau des fichiers, la possibilité d’importer des sauvegardes existantes, la possibilité d’empêcher la suppression manuelle, le support 24/7 avec 4 heures de temps de réponse au maximum, etc.
- « Elite » – 9$ par mois et par ressource, n’a pas de limites sur les ressources gérées ou les comptes, ajoute l’autoprotection par VPC, compte AWS, ainsi que le support GovCloud, et moins d’une heure de temps de réponse du support garanti par SLA.
- Les utilisateurs des plans tarifaires Enterprise et Elite peuvent également acheter la capacité de Druva à sauvegarder les sauvegardes EC2 air-gapped vers Druva Cloud pour un prix supplémentaire.
- Il est facile de voir comment on peut être confus avec le système de tarification de Druva dans son ensemble. Heureusement, Druva dispose d’une page web dédiée dont le seul but est de créer une estimation personnalisée du TCO d’une entreprise avec Druva en seulement quelques minutes (un calculateur de prix).
Mon opinion personnelle sur Druva:
Druva propose une solution de sauvegarde et de restauration cloud-native et app-aware qui résout l’un des problèmes les plus courants de Kubernetes – le fait que le cluster défaillant est toujours restauré dans un état vierge après avoir échoué pour une raison quelconque. Le logiciel lui-même est fourni à l’aide d’un modèle Storage-as-a-Service, et il est tout à fait compétent pour protéger les environnements Kubernetes (ainsi que de nombreux autres types de stockage). Druva peut sauvegarder des données, restaurer des données, automatiser un certain nombre de tâches, créer des sauvegardes d’applications spécifiques et sauvegarder des zones spécifiques (groupes d’applications ou espaces de noms, par exemple). La solution prend également en charge EKS et Amazon EC2, ce qui en fait un cas à part dans cette liste – et sur le marché général. Druva a quelques problèmes avec elle, y compris un processus de configuration assez compliqué pour la première fois et une performance plutôt lente quand il s’agit de récupérer des sauvegardes à partir du stockage dans le cloud, mais la solution globale est tout à fait capable, en particulier pour les environnements Kubernetes.
Zerto

Zerto est également un bon choix si vous recherchez une plateforme de gestion des sauvegardes multifonctionnelle avec une prise en charge native de Kubernetes. Elle offre tout ce que vous attendez d’une solution moderne de sauvegarde et de restauration Kubernetes – CDP (protection continue des données), réplication des données via des snapshots, et verrouillage minimal des fournisseurs grâce à Zerto qui prend en charge toutes les plateformes Kubernetes dans le domaine de l’entreprise.
Zerto propose également la protection des données comme l’une des stratégies de base dès le premier jour, offrant aux applications la possibilité d’être générées avec une protection dès le départ. Zerto dispose également de nombreuses capacités d’automatisation, est capable de fournir des informations approfondies et peut travailler avec différents stockages cloud à la fois.
Types de données couverts par Zerto :
La position de Zerto en termes de couverture des données Kubernetes est simple – il ne peut pas travailler avec les applications ou les infrastructures de stockage, mais tout le reste peut être sauvegardé sans le moindre problème – qu’il s’agisse de déploiements, d’espaces de noms, de services, de pods, etc.
Notes des clients:
- Capterra – 4,8/5 étoiles basées sur 25 avis de clients.
- TrustRadius – 8.6/10 étoiles basées sur 113 avis clients
- G2 – 4.6/5 étoiles sur la base de 73 examens de clients.
Avantages:
- Simplicité de gestion des tâches de reprise après sinistre
- Facilité d’intégration avec les infrastructures existantes, à la fois sur site et dans le nuage
- Capacités de migration de la charge de travail et de nombreuses autres fonctionnalités.
- Les capacités Kubernetes de Zerto sont également assez vastes et variées, y compris la protection continue des données, la réplication des instantanés, et plus encore
Points faibles :
- Ne peut être déployé que sur les systèmes d’exploitation Windows.
- Les fonctions de reporting sont quelque peu rigides.
- Peut être assez coûteux pour les grandes entreprises.
Tarification (au moment de la rédaction):
- Le site web officiel de Zerto propose trois catégories de licences différentes – Zerto pour VM, Zerto pour SaaS et Zerto pour Kubernetes.
- La licence de Zerto pour Kubernetes spécifiquement peut être acquise sous deux formes différentes.
- « Zerto Data Protection » est un logiciel de protection des données qui offre des fonctionnalités de sauvegarde et de restauration continues tout au long du cycle de vie du déploiement des applications, il comprend la rétention à long terme, le clonage, la réplication locale, les sauvegardes orchestrées, etc.
- « Enterprise Cloud Edition » est une version basée sur le cloud de l’offre précédente qui propose également des fonctionnalités de sauvegarde et de récupération continues tout au long du cycle de vie du développement des applications, elle étend l’ensemble des fonctionnalités existantes avec des fonctionnalités telles que la reprise après sinistre orchestrée et la réplication à distance toujours active.
- Il n’y a pas d’information officielle sur les prix disponibles pour la solution de Zerto, elle ne peut être acquise que par le biais d’un devis personnalisé ou achetée par l’un des partenaires commerciaux de Zerto.
Mon opinion personnelle sur Zerto:
Zerto en tant que solution de sauvegarde est une bonne option pour plusieurs cas d’utilisation à la fois – c’est une plateforme complète qui prend en charge une variété de types de stockage différents. Zerto peut fonctionner avec Azure, AWS et Google Cloud en tant que fournisseurs de stockage en nuage ; il prend en charge la couverture des VM, la couverture des conteneurs et de nombreux autres cas d’utilisation. Il peut offrir la protection des données comme l’une de ses fonctionnalités les plus importantes et les plus complètes, et il existe de nombreuses options pour les environnements Kubernetes spécifiquement – qu’il s’agisse d’un verrouillage minimal du fournisseur, de capacités de réplication des données, de la prise en charge CDP, et plus encore. Certaines fonctionnalités de Zerto sont également applicables à tous les différents types de stockage en même temps, qu’il s’agisse de l’analyse des données avec des aperçus étendus, de nombreuses options d’automatisation, etc.
Longhorn

Longhorn est probablement la moins connue des solutions présentées sur ce blog. Sa communauté est relativement petite pour une solution open-source, et elle ne permet pas de sauvegardes Kubernetes complètes avec des métadonnées et des ressources pour que la récupération app-aware se produise. Cependant, il existe une fonctionnalité unique qui sort du lot et qui s’appelle DR Volume. Le volume DR peut être configuré à la fois comme source et comme destination, rendant le volume actif dans un nouveau cluster basé sur les dernières données sauvegardées.
Les capacités de Longhorn à fonctionner avec de nombreux types de plateformes de conteneurs et à permettre différentes méthodes de sauvegarde sont ce qui le différencie des autres, et il existe déjà une capacité à prendre en charge Kubernetes Engine, les déploiements Docker et les distributions K3. Les conteneurs Docker, par exemple, doivent créer un tarball qui pourrait servir de sauvegarde pour Longhorn.
Types de données couverts par Longhorn :
Pour une solution gratuite, Longhorn peut offrir un sacré paquet de couverture de types de données à ses utilisateurs – y compris des sauvegardes pour les déploiements, les StatefulSets, les services, les secrets, les Pods, et plus encore. Il n’a pas la capacité de sauvegarder les espaces de noms, les applications ou l’infrastructure de stockage.
Notations des clients:
- Capterra – 4,3/5 étoiles sur la base de 6 avis de clients.
- G2 – 4,8/5 étoiles basées sur 3 examens de clients.
Caractéristiques principales:
- Solution indépendante de l’infrastructure
- Processus de déploiement facile
- Tableau de bord pratique et utile
- Personnalisation simple pour les politiques de sauvegarde et de reprise après sinistre.
Tarification (au moment de la rédaction):
- Longhorn est une solution de sauvegarde Kubernetes gratuite et open-source qui a été développée à l’origine par Rancher Labs, mais qui a ensuite été donnée à la CNCF (Cloud Native Computing Foundation) et est maintenant considérée comme un projet de bac à sable autonome.
- Rancher lui-même a un niveau de prix premium séparé appelé Rancher Prime – il offre une variété de fonctionnalités pour étendre et améliorer la fonctionnalité originale de Rancher, mais son prix n’est pas publiquement disponible sur le site officiel.
Mon opinion personnelle sur Longhorn:
Semblable à un certain nombre d’exemples précédents, Longhorn n’offre pas une couverture complète de Kubernetes – ce qui signifie qu’il n’y aurait pas de sauvegardes app-aware. Dans le même temps, il s’agit d’une option intéressante pour les petites entreprises et les entreprises à budget limité – compte tenu du fait que Longhorn est gratuit, prend en charge un certain nombre de variantes de conteneurs et même plusieurs méthodes de sauvegarde. Longhorn peut également offrir sa propre fonctionnalité inhabituelle appelée DR Volume – un volume qui peut être défini à la fois comme destination et comme source, ce qui le rend immédiatement actif dans le cluster nouvellement créé à l’aide des données de sauvegarde existantes. Il s’agit également d’une solution relativement simple pour une solution libre et gratuite, bien qu’une certaine courbe d’apprentissage soit toujours à prévoir.
Velero.io

Velero est une solution open-source de sauvegarde et de restauration Kubernetes avec des capacités de migration. Elle prend en charge les instantanés pour les volumes persistants et les états des clusters, ce qui rend la migration et la restauration possibles dans différents environnements. C’est une solution bien connue dans la sphère de la sauvegarde Kubernetes, offrant des capacités de reprise après sinistre fiables pour les clusters Kubernetes en même temps que la migration des clusters, la conservation à long terme à des fins de conformité, et plus encore.
Caractéristiques principales :
- Migration de cluster avec différentes configurations.
- Protection à l’échelle du cluster et granularité dans les processus de sauvegarde.
- Capacités étendues de reprise après sinistre à des fins de continuité de l’activité.
- Planification des sauvegardes avec de nombreuses options au choix.
- Intégration avec l’API pour créer des instantanés de volumes persistants pour les grands ensembles de données.
- Prise en charge d’un certain nombre de fournisseurs de stockage en nuage, notamment Azure Blob, Google Cloud, AWS S3, etc.
Tarification (au moment de la rédaction):
- Velero.io est un outil entièrement gratuit et open-source, sans aucun prix lié au logiciel.
Mon avis personnel sur Velero.io :
Velero est une option intéressante pour les tâches de sauvegarde et de récupération dans les environnements Kubernetes, compte tenu du fait qu’il est gratuit et peut offrir une granularité étendue dans ses capacités. Il prend en charge différents fournisseurs de stockage, peut être intégré à l’API de la plateforme pour les instantanés persistants et constitue généralement une solution étonnamment pratique dans de nombreuses situations. Il n’est pas particulièrement utilisable dans la plupart des cas d’utilisation de niveau entreprise en raison de l’ampleur des opérations nécessaires, et l’absence des fonctions de sécurité les plus populaires telles que le chiffrement le rendrait difficile à travailler pour les entreprises qui traitent des informations sensibles, mais la solution dans son ensemble vaut toujours la peine d’être examinée, à tout le moins.
Quelle liste de contrôle les équipes doivent-elles suivre pour s’assurer que leur environnement Kubernetes est prêt pour la sauvegarde ?
Le simple fait d’avoir une stratégie de reprise sur papier ne signifie pas qu’elle est prête à être mise en œuvre. Laissez cette liste de contrôle vous aider à vous assurer que les décisions et les configurations décrites dans ce document sont mises en œuvre de manière concrète et vérifiable.
Avez-vous répertorié les charges de travail critiques et les périmètres de données ?
Avant toute chose, vous devez savoir exactement ce que vous protégez. Sans inventaire clair, les politiques de sauvegarde ont tendance à être soit trop générales, soit pleines de lacunes.
- Tous les espaces de noms et toutes les charges de travail sont documentés et classés par niveau de criticité
- Les volumes persistants sont classés par priorité de reprise
- Les ressources personnalisées et les CRD associés à chaque charge de travail sont identifiés
- Les applications avec état sont distinguées des applications sans état dans votre inventaire
- La propriété des données est attribuée pour chaque charge de travail critique
Les politiques de RPO, RTO et de conservation sont-elles documentées et approuvées ?
Les exigences de reprise qui n’ont pas fait l’objet d’un accord formel ont tendance à évoluer sous la pression. Celles-ci doivent être fixées avant un incident, et non négociées pendant celui-ci.
- Les objectifs RPO et RTO sont définis pour chaque niveau de charge de travail
- La fréquence de sauvegarde pour etcd, les PV et les données d’application reflète ces objectifs
- Les fenêtres de rétention sont documentées et approuvées par le responsable du SLA de reprise
- Des politiques de cycle de vie et de hiérarchisation sont en place pour les données de sauvegarde plus anciennes
- Les politiques sont révisées et réapprouvées après tout changement significatif de l’infrastructure
La surveillance, les alertes et le contrôle d’accès pour les sauvegardes sont-ils en place ?
Un processus de sauvegarde qui s’exécute et échoue en silence donne une fausse impression de sécurité. Les contrôles opérationnels doivent être aussi robustes que le processus de sauvegarde lui-même.
- Les tâches de sauvegarde sont surveillées et les échecs déclenchent des alertes auprès des personnes concernées
- L’accès à la sauvegarde et à la restauration est séparé dans la configuration RBAC
- Les opérations de restauration nécessitent une autorisation explicite pour les environnements de production
- Le chiffrement est appliqué de manière cohérente sur l’ensemble du pipeline de sauvegarde
- La gestion des clés est gérée indépendamment du stockage de sauvegarde
Disposez-vous de runbooks éprouvés pour les scénarios de restauration courants ?
Une documentation qui n’a pas été testée est une hypothèse, pas un guide d’intervention. Ce sont les tests réguliers qui transforment un plan de reprise en une capacité de reprise.
- Des guides d’intervention existent au moins pour les scénarios de restauration les plus courants : espace de noms unique, cluster complet et restauration d’etcd
- Les procédures de restauration ont été testées de bout en bout dans un environnement hors production
- Le temps de reprise pour chaque scénario a été mesuré par rapport à votre RTO
- Les runbooks sont soumis à un contrôle de version et révisés après chaque test ou incident
- La responsabilité de chaque runbook est attribuée et à jour
La solution de sauvegarde K8s de Bacula Enterprise
La nature même des environnements Kubernetes les rend à la fois très dynamiques et potentiellement complexes. La sauvegarde d’un cluster Kubernetes ne doit pas ajouter inutilement à cette complexité. Et, bien sûr, il est généralement important – voire essentiel – que les administrateurs système et autres membres du personnel informatique disposent d’un contrôle centralisé sur l’ensemble du système de sauvegarde et de restauration de toute l’organisation, y compris les environnements Kubernetes. De cette manière, des facteurs tels que la conformité, la facilité de gestion, la rapidité, l’efficacité et la continuité des activités deviennent beaucoup plus réalistes. Dans le même temps, l’approche agile des équipes de développement ne doit en aucun cas être compromise.
Bacula Enterprise est unique dans ce domaine car il s’agit d’une solution d’entreprise complète pour des environnements informatiques complets (et pas seulement Kubernetes) qui offre également une sauvegarde et une restauration Kubernetes intégrées en natif, y compris pour plusieurs clusters, que les applications ou les données se trouvent à l’extérieur ou à l’intérieur d’un cluster spécifique. Bacula apporte d’autres avantages, en ce sens qu’il est particulièrement sécurisé, protégé et stable. Ces qualités deviennent essentielles dans le contexte d’organisations qui doivent garantir les niveaux de sécurité les plus élevés possibles.
Restauration de cluster
Le service des opérations de toute entreprise reconnaît la nécessité de disposer d’une stratégie de restauration adéquate en matière de restauration de cluster, de mises à niveau et d’autres situations. Un cluster se trouvant dans un état irrécupérable peut être ramené à un état stable grâce à Bacula si les fichiers de configuration et les volumes persistants du cluster ont été correctement sauvegardés au préalable.
Une autre façon d’illustrer les méthodes de travail de Bacula est d’utiliser l’image ci-dessous :
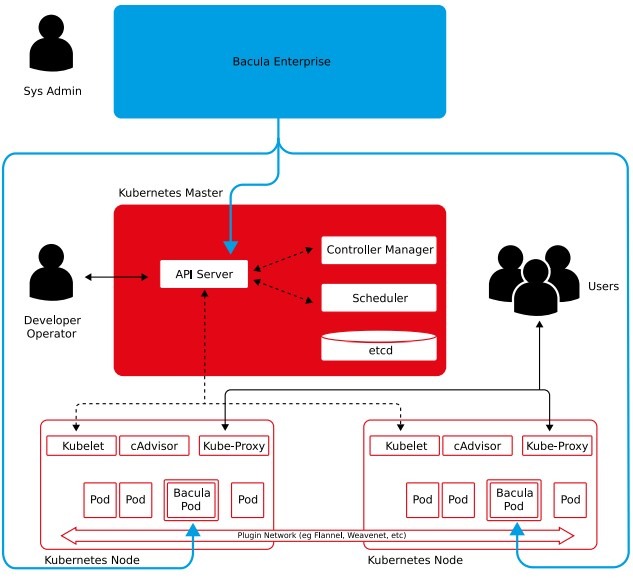
L’un des premiers avantages du module Kubernetes de Bacula est la possibilité de sauvegarder diverses ressources Kubernetes, notamment :
- Pods ;
- Services ;
- Déploiements ;
- Volumes persistants.
Caractéristiques du module Kubernetes de Bacula Enterprise
La façon dont ce module fonctionne est que la solution elle-même ne fait pas partie de l’environnement Kubernetes mais accède plutôt aux données pertinentes à l’intérieur du cluster via des pods Bacula qui sont attachés à des nœuds Kubernetes uniques dans un cluster. Le déploiement de ces pods est automatique et fonctionne selon les besoins.
Parmi les autres fonctionnalités que le module de sauvegarde Kubernetes fournit également, on peut citer les suivantes :
- Sauvegarde et restauration Kubernetes pour les volumes persistants ;
- Restauration d’une seule ressource de configuration Kubernetes ;
- La possibilité de restaurer les fichiers de configuration et/ou les données des volumes persistants vers le répertoire local ;
- La possibilité de sauvegarder la configuration des ressources des clusters Kubernetes.
Il convient également de noter que Bacula prend facilement en charge simultanément plusieurs plateformes de stockage en nuage, notamment AWS, Google, Glacier, Oracle Cloud, Azure et bien d’autres, au niveau de l’intégration native. Les capacités de cloud hybride sont donc intégrées, y compris la gestion avancée du cloud et les fonctions automatisées de mise en cache du cloud, ce qui permet d’intégrer facilement des services de cloud public ou privé pour prendre en charge diverses tâches.
La flexibilité de la solution est particulièrement importante de nos jours, car de nombreuses sociétés et entreprises deviennent de plus en plus complexes en termes de familles d’hyperviseurs et de conteneurs différents. Dans le même temps, cela augmente considérablement la demande de flexibilité pour tous les fournisseurs de bases de données. Les capacités de Bacula à cet égard sont substantiellement élevées, combinant sa large liste de compatibilité avec diverses technologies pour atteindre des normes de flexibilité particulièrement élevées sans s’enfermer dans un seul fournisseur.
La complexité des différents aspects du travail d’une organisation ne cesse de croître, et il est le plus souvent plus facile et plus rentable d’utiliser une seule solution pour l’ensemble de l’environnement informatique, et non plusieurs solutions à la fois. Bacula est conçu exactement pour cela, et est également capable de fournir à la fois une interface web traditionnelle pour vos besoins de configuration, ainsi que le type de contrôle classique en ligne de commande. Ces deux interfaces peuvent même être utilisées simultanément.
Le plugin de sauvegarde Kubernetes de Bacula permet deux types de cibles principales pour les opérations de restauration :
- Restauration vers un répertoire local ;
- Restauration vers un cluster.
Des sauvegardes régulières et/ou automatisées sont fortement recommandées pour assurer le meilleur environnement de sauvegarde et de restauration possible pour les conteneurs. Tester vos sauvegardes de temps en temps devrait être obligatoire pour votre administrateur système également. Dans l’image suivante, vous verrez une partie du processus de restauration, à savoir la partie « Restore Selection », dans laquelle vous pouvez choisir les fichiers et/ou les répertoires que vous souhaitez restaurer :
Une autre partie du processus de restauration que vous rencontrerez est la page des options de restauration avancées, qui se présente comme suit :
Vous pouvez y spécifier plusieurs options différentes, telles que le format de sortie, le chemin d’accès au fichier de configuration KBS, le port d’extrémité, etc.
Il est également facile de surveiller l’ensemble du processus de restauration une fois la personnalisation terminée, grâce à la page de journal de la tâche de restauration qui enregistre chaque action une par une :
Une autre capacité importante du module Kubernetes est la fonctionnalité Plugin Listing, qui offre de nombreuses informations utiles sur vos ressources Kubernetes disponibles, y compris les espaces de noms, les volumes persistants, etc. Pour ce faire, le module utilise une commande .ls spéciale avec un paramètre plugin=<plugin> spécifique.
Le module de sauvegarde K8s offre également les fonctionnalités suivantes :
- Redéploiement rapide et efficace des ressources du cluster ;
- Sauvegarde de l’état du cluster Kubernetes ;
- Sauvegarde des configurations pour les utiliser dans d’autres opérations ;
- Le module Bacula Kubernetes offre une variété de fonctionnalités, parmi lesquelles : le redéploiement rapide et efficace des ressources du cluster ; la sauvegarde de l’état du cluster Kubernetes ; la sauvegarde des configurations pour les utiliser dans d’autres opérations ; le maintien des configurations modifiées aussi sûres que possible et la restauration de l’état précédent.
Même si cela arrive souvent, il est vivement recommandé d’éviter de rémunérer votre fournisseur en fonction du volume de données. Il n’y a aucune raison de se laisser tenir en otage, aujourd’hui ou à l’avenir, par un prestataire prêt à profiter ainsi de votre organisation. Examinez plutôt de près les modèles de licence de Bacula Systems, qui protègent ses clients contre les frais liés à la croissance des données tout en facilitant considérablement la prévision des coûts futurs pour les services achats de ses clients. Cette approche plus raisonnable de Bacula trouve son origine dans ses racines open source et pourrait séduire les équipes qui travaillent intensivement dans des environnements DevOps.
Conclusion
En fin de compte, les utilisateurs de Kubernetes ont beaucoup de choix différents en matière de logiciels de sauvegarde et de restauration. Certains sont uniquement créés pour gérer les données Kubernetes, tandis que d’autres solutions ajoutent Kubernetes à leur liste de fonctionnalités existantes.
Les petites entreprises à la recherche d’une solution capable d’effectuer uniquement des sauvegardes Kubernetes pourraient trouver que Longhorn ou OpenEBS constituent un choix plus approprié que les autres solutions de notre liste. À l’inverse, les grandes entreprises disposant de nombreux types de stockage différents au sein de leur propre infrastructure peuvent avoir besoin d’une solution de sauvegarde complète et hautement sécurisée, couvrant l’ensemble des systèmes informatiques de leur entreprise sans fragmentation et permettant de visualiser l’ensemble des opérations de sauvegarde et de restauration à partir d’une interface de gestion centralisée – ce à quoi sont précisément destinées des solutions telles que Bacula Enterprise. Le choix final dépendra largement des besoins et des priorités de chaque client, notamment de la taille de l’entreprise, des fonctionnalités requises, etc.
Pourquoi vous pouvez nous faire confiance
Bacula Systems s’efforce de fournir un point de vue objectif sur les technologies, les produits et les entreprises. Dans nos analyses, nous utilisons de nombreuses méthodes différentes, telles que des informations sur les produits et des avis d’experts, afin de générer le contenu le plus informatif possible.
Nos documents offrent toutes sortes de facteurs sur chaque solution présentée, qu’il s’agisse d’ensembles de fonctionnalités, de prix, d’avis de clients, etc. La stratégie produit de Bacula est supervisée et contrôlée par Jorge Gea, le directeur technique de Bacula Systems, et Rob Morrison, le directeur marketing de Bacula Systems.
Avant de rejoindre Bacula Systems, Jorge a été pendant de nombreuses années le directeur technique de Whitebearsolutions SL, où il a dirigé le secteur de la sauvegarde et du stockage et la solution WBSAirback. Aujourd’hui, Jorge assure la direction et l’orientation des tendances technologiques actuelles, des compétences techniques, des processus, des méthodologies et des outils pour le développement rapide et passionnant des produits Bacula. Responsable de la feuille de route des produits, Jorge est activement impliqué dans l’architecture, l’ingénierie et le processus de développement des composants Bacula. Jorge est titulaire d’une licence en ingénierie informatique de l’université d’Alicante, d’un doctorat en technologies informatiques et d’une maîtrise en administration de réseaux.
Rob a commencé sa carrière dans le domaine du marketing informatique chez Silicon Graphics en Suisse, où il a occupé pendant près de dix ans diverses fonctions de gestion du marketing. Au cours des dix années suivantes, Rob a également occupé divers postes de gestion du marketing chez JBoss, Red Hat et Pentaho, assurant la croissance de la part de marché de ces entreprises renommées. Il est diplômé de l’université de Plymouth et titulaire d’un diplôme spécialisé dans les médias numériques et la communication.
Bacula Systems s’attache à la précision et à la cohérence, nos informations tentent toujours de fournir le point de vue le plus objectif sur les différentes technologies, les produits et les entreprises. Dans nos analyses, nous utilisons de nombreuses méthodes différentes, telles que des informations sur les produits et des avis d’experts, afin de générer le contenu le plus informatif possible.
Nos documents offrent toutes sortes de facteurs sur chaque solution présentée, qu’il s’agisse d’ensembles de fonctionnalités, de prix, d’avis de clients, etc. La stratégie produit de Bacula est supervisée et contrôlée par Jorge Gea, le directeur technique de Bacula Systems, et Rob Morrison, le directeur marketing de Bacula Systems.
Avant de rejoindre Bacula Systems, Jorge a été pendant de nombreuses années le directeur technique de Whitebearsolutions SL, où il a dirigé le secteur de la sauvegarde et du stockage et la solution WBSAirback. Aujourd’hui, Jorge assure la direction et l’orientation des tendances technologiques actuelles, des compétences techniques, des processus, des méthodologies et des outils pour le développement rapide et passionnant des produits Bacula. Responsable de la feuille de route des produits, Jorge est activement impliqué dans l’architecture, l’ingénierie et le processus de développement des composants Bacula. Jorge est titulaire d’une licence en ingénierie informatique de l’université d’Alicante, d’un doctorat en technologies informatiques et d’une maîtrise en administration de réseaux.
Rob a commencé sa carrière dans le domaine du marketing informatique chez Silicon Graphics en Suisse, où il a occupé pendant près de dix ans diverses fonctions de gestion du marketing. Au cours des dix années suivantes, Rob a également occupé divers postes de gestion du marketing chez JBoss, Red Hat et Pentaho, assurant la croissance des parts de marché de ces entreprises réputées. Il est diplômé de l’université de Plymouth et titulaire d’un diplôme spécialisé en communication et médias numériques.
Questions fréquemment posées
Quel est l’objectif principal des sauvegardes Kubernetes?
L’objectif d’une sauvegarde Kubernetes est similaire à la raison pour laquelle la plupart des sauvegardes sont effectuées – pour créer des copies sécurisées des informations à récupérer en cas de catastrophe, accidentelle ou intentionnelle. Un ensemble de sauvegardes approprié peut être la solution aux pannes de système, à la perte de données, à la corruption de données, au vol de données et à de nombreuses autres situations où l’existence de toute l’entreprise repose sur le fait que les données peuvent être restaurées ou non.
Quelle est la complexité des sauvegardes Kubernetes par rapport aux sauvegardes traditionnelles de VM?
La nature conteneurisée des charges de travail Kubernetes est la principale raison pour laquelle ces sauvegardes sont considérées comme plus difficiles et plus sophistiquées que les sauvegardes VM ordinaires. Chaque application Kubernetes comprend plusieurs microservices, avec la nécessité de sauvegarder à la fois l’état du cluster et l’état de l’application pour un fonctionnement correct, ce qui rend très difficile une restauration correcte sans perte de continuité. En outre, la nature en constante évolution des clusters Kubernetes ajoute une couche de difficulté supplémentaire à tout le reste, ce qui rend les processus de sauvegarde et de restauration encore plus complexes.
Quel logiciel de sauvegarde est la meilleure option possible pour les sauvegardes Kubernetes?
Il est difficile d’affirmer qu’une solution unique constitue la meilleure option possible pour un cas d’utilisation spécifique, étant donné que chaque entreprise a ses propres circonstances et exigences. La plupart des entreprises disposent également d’un budget strict en matière de logiciels de sauvegarde, ce qui signifie que l’éventail complet des fonctionnalités serait moins prioritaire que le prix de la solution. En fin de compte, la solution la plus utile de cette liste sera celle qui convient au plus grand nombre et à la plus large gamme de cas d’utilisation potentiels – dans ce cas, Bacula Enterprise serait le vainqueur incontesté de cette liste.
Que peut offrir Bacula pour les environnements Kubernetes multi-cloud?
Bacula offre la flexibilité de la restauration des données et de la reprise après sinistre en permettant le stockage des sauvegardes sur différents environnements de stockage cloud. La restauration des informations vers n’importe quel cluster compatible au lieu du cluster à partir duquel les données ont été copiées est également une option ici. La résilience et la redondance d’un environnement Kubernetes sont ainsi drastiquement augmentées, en particulier lorsqu’il s’agit de diverses pannes spécifiques au cloud. Bacula permet également à ses utilisateurs de restaurer à la fois des espaces de noms et des clusters entiers dans différents environnements de stockage en nuage, offrant ainsi une continuité étendue sans lier les utilisateurs au même stockage en nuage. Un aspect critique qui est souvent quelque peu négligé par les architectes Kubernetes est la nécessité pour leur organisation d’obtenir les niveaux de sécurité les plus élevés possibles. Comparé à pratiquement tous les autres fournisseurs de sauvegarde, Bacula a des niveaux de sécurité plus élevés intégrés dans son architecture, ses méthodologies, ses processus et ses fonctionnalités individuelles.
Quel type d’environnement Bacula supporte-t-il ?
Non seulement Bacula peut fonctionner avec des clusters Kubernetes sur site et dans le cloud, mais il prend également en charge les environnements hybrides, ce qui permet de mélanger les deux options de déploiement pour obtenir le plus haut niveau possible de flexibilité, d’efficacité et de sécurité dans différents environnements.

