

Contents
- Introduzione
- Concetti importanti per un processo di backup Kubernetes
- Perché sono necessari i backup di K8s?
- Il valore dei backup Kubernetes
- I vantaggi delle operazioni di backup di Kubernetes
- Tipi di dati Kubernetes che devono essere sottoposti a backup
- Cosa è necessario sottoporre a backup in un ambiente Kubernetes?
- In che modo GitOps influisce sulla vostra strategia di backup di Kubernetes?
- Best practice per le operazioni di backup di Kubernetes
- Come si dovrebbero progettare le pianificazioni di backup e le politiche di conservazione di Kubernetes?
- Come si proteggono i backup di Kubernetes e si soddisfano i requisiti di conformità?
- Metodologia per la scelta della migliore soluzione di backup Kubernetes possibile
- Mercato delle soluzioni di backup di Kubernetes
- Quale lista di controllo dovrebbero seguire i team per garantire la preparazione al backup di Kubernetes?
- La soluzione di backup K8s di Bacula Enterprise
- Conclusione
- Perché potete fidarvi di noi
- Domande frequenti
Introduzione
Kubernetes (noto anche come K8s) è una piattaforma di orchestrazione dei container che consente di gestire e scalare le applicazioni; spesso rappresenta la scelta preferita dalle aziende in grado di trarre vantaggio dall’architettura delle applicazioni containerizzate. La flessibilità di Kubernetes comporta che molte implementazioni siano molto diverse tra loro. Tuttavia, strutture uniche comportano tipicamente sfide specifiche in termini di ripristino e disponibilità, che fanno tutte parte delle difficoltà legate all’utilizzo di Kubernetes nell’infrastruttura IT aziendale.
Sebbene l’ipotesi secondo cui Kubernetes fosse precedentemente utilizzato principalmente dai team DevOps potesse essere in parte corretta, molte aziende stanno ora implementando attivamente i container in ambienti operativi. Inoltre, si affidano sempre più ai container per l’implementazione delle applicazioni, invece di utilizzare le tradizionali macchine virtuali. Ciò è dovuto ai vari vantaggi in termini di flessibilità, prestazioni e costi che i container sono in grado di offrire. Tuttavia, con l’ingresso dei container nella parte operativa dell’ambiente IT, cresce la preoccupazione riguardo agli aspetti di sicurezza dei container nei sistemi di produzione che devono rimanere disponibili, compresi i loro dati persistenti nel contesto dei processi di backup e ripristino.
In origine, la stragrande maggioranza delle applicazioni containerizzate era stateless, il che consentiva loro di avere un processo di implementazione molto più semplice su un cloud pubblico. Ma la situazione è cambiata nel tempo, con un numero molto maggiore di applicazioni stateful distribuite nei container rispetto al passato. Questo cambiamento è il motivo per cui il backup e il ripristino in Kubernetes sono ora un argomento importante per molte organizzazioni.
Concetti importanti per un processo di backup Kubernetes
- L’importanza dei backup Kubernetes ruota attorno alla sicurezza dei dati, poiché le informazioni sono la risorsa più importante di qualsiasi azienda moderna e richiedono quasi sempre che tali dati siano conservati in modo sicuro, protetto e riservato. Nel contesto di Kubernetes, le informazioni preziose includono solitamente anche le configurazioni, i segreti, il database etcd, i volumi persistenti, ecc.
- Una corretta configurazione della strategia di backup può offrire grande versatilità e funzionalità a un ambiente Kubernetes, inclusi backup a livello di applicazione, backup a livello di namespace, snapshot, convalida dei backup, versioning, politiche di backup e molti altri.
- Una corretta configurazione del ripristino è altrettanto importante, considerando quante diverse parti del processo possono potenzialmente fallire. Test rigorosi dei backup, consulenza sulla documentazione e vigilanza costante durante il ripristino sono parte integrante di ciò che deve essere garantito per processi di ripristino di successo.
- I backup di Kubernetes possono incontrare una serie di sfide – che si tratti di problemi di coerenza dei dati, standard di conformità, sicurezza dei dati e compatibilità delle versioni, tra le altre cose. La buona notizia è che la maggior parte di queste insidie può essere evitata o mitigata con un certo livello di preparazione.
Perché sono necessari i backup di K8s?
Un ambiente Kubernetes è dinamico, distribuito e intrinsecamente più soggetto alla perdita di dati rispetto a un’infrastruttura convenzionale. Questa sezione tratta i vari fattori di guasto che rendono indispensabili i backup, le diverse categorie di guasto, le corrispondenti strategie di ripristino e la necessità che le esigenze di backup siano esplicitamente documentate negli SLA e nei runbook.
Quali rischi corrono i cluster Kubernetes senza backup?
In un ambiente Kubernetes, esistono pericoli che vanno ben oltre i problemi standard dell’infrastruttura.
- Gli attacchi mirati alla catena di approvvigionamento contro immagini container o repository Helm possono facilmente introdurre codice dannoso difficile da rilevare prima che causi danni
- I ruoli IAM cloud configurati in modo improprio possono esporre – o peggio – danneggiare le risorse del cluster su vasta scala
- Gli eventi di auto-scaling possono cogliere rapidamente alla sprovvista i carichi di lavoro stateful, causando un danneggiamento dei dati invisibile ma permanente
Rischi come questi possono moltiplicarsi estremamente rapidamente sui sistemi distribuiti, dove il raggio d’azione di un singolo evento può estendersi a decine di carichi di lavoro in decine di spazi dei nomi.
In che modo differiscono i guasti a livello di applicazione, cluster e dati?
I guasti di Kubernetes si verificano spesso in livelli diversi e hanno strategie di ripristino corrispondentemente diverse. Il guasto potrebbe avere un impatto solo su un singolo carico di lavoro, potrebbe avere un impatto sull’intero cluster, oppure potrebbe avere un impatto sui dati archiviati esternamente rispetto a entrambi. Le sezioni successive tratteranno ciascuno di questi guasti in modo più dettagliato, ma conoscere questa distinzione in anticipo pone anche le basi per comprendere perché una strategia di backup “universale” raramente ha successo.
Quando i backup dovrebbero far parte dei vostri SLA e runbook?
I backup devono essere obbligatori quando un carico di lavoro ha un RTO e/o un RPO definiti. Se vi siete impegnati a rispettare un obiettivo di tempo di ripristino (RTO), tale parametro dovrebbe essere accompagnato da un processo di ripristino documentato e testato, il che significa che la frequenza dei backup, la conservazione e il processo di ripristino dovrebbero essere documentati prima di un incidente, non dopo.
I carichi di lavoro presenti in un runbook di reperibilità devono essere considerati con una responsabilità esplicita e una politica di backup documentata. Gli ambienti regolamentati dalla conformità aggiungono un proprio livello al processo, richiedendo la prova dell’esistenza dei backup, della loro verifica e del rispetto delle necessarie politiche di conservazione documentate.
Il valore dei backup Kubernetes
La natura stessa degli ambienti Kubernetes rende più difficile il corretto funzionamento dei sistemi e delle tecniche di backup più tradizionali nel contesto dei nodi e delle applicazioni Kubernetes. Sia l’RPO che l’RTO possono infatti essere molto più critici, poiché le applicazioni che fanno parte di una distribuzione operativa devono essere costantemente attive e funzionanti, specialmente gli elementi critici dell’infrastruttura.
Questo ci porta a individuare elementi chiave di continuità operativa che sono praticamente necessari per ogni impresa in generale e una chiara necessità quando si tratta delle best practice per il backup di K8s: backup e ripristino, alta disponibilità locale, disaster recovery, protezione dal ransomware, errore umano e così via. In un ambiente Kubernetes, il contesto di questi aspetti del backup può variare leggermente rispetto alla loro definizione standard.
Alta disponibilità locale
L’alta disponibilità locale, in quanto funzionalità, riguarda principalmente la prevenzione dei guasti o la protezione all’interno di un data center specifico o tra zone di disponibilità (se si parla di cloud, ad esempio). Un guasto “locale” si verifica nell’infrastruttura/nodo/app utilizzata per eseguire l’applicazione. In uno scenario ideale, la vostra soluzione di backup Kubernetes dovrebbe essere in grado di reagire a questo guasto mantenendo l’app in funzione, il che significa essenzialmente nessun tempo di inattività per l’utente finale. Uno degli esempi più comuni di guasto locale è un volume cloud bloccato che si verifica a seguito di un guasto del nodo.
In questa prospettiva, l’alta disponibilità locale come funzionalità può essere considerata una parte fondamentale della strategia di protezione dei dati. Innanzitutto, per eseguire tale attività, la vostra soluzione deve offrire una sorta di sistema di replica dei dati a livello locale e deve anche trovarsi per prima nel percorso dei dati. È importante sottolineare che fornire disponibilità locale tramite il ripristino del backup è ancora considerato un’operazione di backup e ripristino e non di alta disponibilità locale, a causa del tempo di ripristino complessivo.
Backup e ripristino
Backup e ripristino è un altro elemento importante di un sistema Kubernetes operativo. Nella maggior parte dei casi d’uso, esegue il backup dell’intera applicazione da un cluster Kubernetes locale a una sede remota. Il contesto di Kubernetes solleva anche un’altra considerazione importante: se il software di backup “comprenda” o meno ciò che è incluso in un’applicazione Kubernetes, ad esempio:
- Configurazione dell’applicazione;
- Risorse Kubernetes;
- Dati
Un backup Kubernetes corretto deve salvare tutte le parti sopra indicate come un’unica unità affinché sia utilizzabile nel sistema Kubernetes dopo il ripristino. Il fatto di puntare a specifiche VM, server o dischi non significa che il software “comprenda” le applicazioni Kubernetes. Idealmente, il software Kubernetes dovrebbe essere in grado di eseguire il backup di applicazioni specifiche, gruppi specifici di applicazioni, nonché dell’intero namespace Kubernetes. Ciò non significa che sia completamente diverso dal normale processo di backup: anche i backup di Kubernetes possono trarre grande vantaggio da alcune delle normali funzionalità di un backup standard, tra cui conservazione, pianificazione, crittografia, tiering e così via.
Disaster recovery
La funzionalità di Disaster Recovery (DR) è essenziale per qualsiasi organizzazione che utilizzi Kubernetes in una situazione mission-critical, proprio come lo è quando si impiega qualsiasi altra tecnologia. In primo luogo, il DR deve “comprendere” il contesto dei backup di Kubernetes, proprio come il backup e il ripristino. Può inoltre avere diversi livelli sia di RTO che di RPO e diversi livelli di protezione in base a tali livelli. Ad esempio, potrebbe esserci un requisito RPO pari a zero che implica un tempo di inattività rigorosamente nullo, oppure potrebbe esserci un RPO di 15 minuti con requisiti leggermente meno rigidi. Non è inoltre raro che app diverse abbiano RTO e RPO completamente diversi all’interno dello stesso database.
Un’altra importante caratteristica distintiva di un sistema di disaster recovery specifico per Kubernetes è che dovrebbe essere in grado di gestire in una certa misura anche i metadati (etichette, repliche delle app, ecc.). L’incapacità di fornire questa funzionalità potrebbe facilmente portare a un ripristino disorganico in generale, nonché a una perdita generale di dati o a tempi di inattività aggiuntivi.
Protezione dal ransomware
L’importanza dei backup dei sistemi Kubernetes (in particolare quelli che generano dati persistenti) è pari a quella dei normali backup dei dati. I dati preziosi devono essere salvaguardati per evitare rischi inaccettabili. Le informazioni hanno un valore inestimabile e Bacula Systems raccomanda vivamente di avere in mente uno o più piani dedicati per le situazioni in cui i dati aziendali vengono danneggiati o compromessi in altro modo.
Molte di queste misure di protezione funzionano efficacemente sia contro eventi accidentali che contro quelli dolosi. Gli attacchi intenzionali che provocano violazioni dei dati tramite ransomware, furti d’identità e altre misure sono diventati fin troppo comuni, ed è del tutto irrealistico pensare che la vostra azienda non sarà mai bersaglio di un evento del genere. Pertanto, prepararsi a queste situazioni può offrire vantaggi in termini di una serie di fattori estremamente importanti, quali il rispetto della conformità, la tutela della reputazione personale e aziendale, la protezione di clienti e dipendenti e, soprattutto, l’evitare in generale gravi danni a un’azienda e/o a un’organizzazione.
Errore umano
La gravità di un singolo errore umano può essere significativa (cancellazioni accidentali, configurazioni errate, implementazione involontaria di aggiornamenti). Sebbene l’automazione di alcune funzioni possa mitigare in parte gli errori umani, nella maggior parte delle aziende è in genere impossibile automatizzare ogni singolo processo.
In questo contesto, i piani di backup e di disaster recovery servono a garantire che un’azienda possa continuare a operare in modo efficace dopo un incidente causato da un comando errato o da un errore di configurazione.
I vantaggi delle operazioni di backup di Kubernetes
I backup di Kubernetes presentano molteplici vantaggi, spesso simili alle normali operazioni di backup su qualsiasi altro tipo di dati. Si tratta di un ottimo modo per mantenere l’affidabilità, la disponibilità e l’integrità delle applicazioni Kubernetes e dei dati delle app. Di seguito sono riportati alcuni dei vantaggi più comuni.
Mitigazione dell’impatto dei guasti hardware
Dal punto di vista tecnico, i guasti hardware sono inevitabili e possono verificarsi praticamente in qualsiasi momento; che si tratti di un guasto di rete, di un’interruzione di corrente, di un malfunzionamento dell’unità di archiviazione o di qualsiasi altro tipo di evento che porti al danneggiamento o alla perdita dei dati. I backup di Kubernetes possono offrire un elevato livello di protezione contro tali eventi, fornendo una copia ridondante delle informazioni che può essere ripristinata in qualsiasi altro ambiente qualora l’hardware originale non fosse più disponibile, riducendo al minimo i tempi di inattività e migliorando la continuità operativa.
Disaster recovery
La maggior parte dei disastri naturali è in grado di spazzare via completamente l’intera infrastruttura fisica di un’azienda, compresi i suoi cluster Kubernetes e forse anche i backup primari di tali cluster. L’esistenza di un backup off-site è quindi uno dei tanti vantaggi che la strategia di disaster recovery offre ai propri utenti, fornendo un modo per ricostruire rapidamente l’intera rete di cluster e riprendere le operazioni entro un periodo di tempo accettabile.
Prevenzione della perdita di dati
Gli errori accidentali e la cattiva gestione sono sorprendentemente comuni ancora oggi, a prescindere dal numero crescente di violazioni dei dati dolose. Ogni essere umano può commettere errori, e l’impossibilità di annullare una determinata azione, cancellazione o modifica aumenta drasticamente la probabilità di una perdita permanente di dati per le informazioni sensibili. I backup regolari di K8s aiutano a garantire che gli incidenti causati involontariamente possano comunque essere recuperati, in un modo o nell’altro.
Difesa contro gli attacchi informatici
Le minacce informatiche sono in significativo aumento ormai da diversi anni e si prevede quasi universalmente che la situazione peggiori ulteriormente. Ogni infrastruttura IT è costantemente esposta al rischio di un attacco informatico e l’esistenza di misure di backup definite e sicure è fondamentale per proteggere l’intera azienda. La mancata adozione di tali misure comporta un rischio significativo per la stessa sopravvivenza dell’azienda.
Supporto per gli ambienti di test e sviluppo
I backup regolari dei cluster Kubernetes hanno spesso un valore aggiunto: possono infatti costituire un valido supporto nei processi di test e sviluppo, semplificando notevolmente la creazione di repliche dei cluster a fini di sviluppo senza influire sui dati originali. In questo modo, la sperimentazione può rivelarsi molto più fruttuosa ed efficiente, offrendo numerose opportunità di sviluppo per l’azienda stessa.
Tipi di dati Kubernetes che devono essere sottoposti a backup
Il motivo per cui solitamente si ricorre alla containerizzazione è quello di creare ed eseguire un ambiente di runtime sicuro, affidabile e leggero per le applicazioni, realizzando un sistema coerente da un host all’altro. In genere, questi sistemi generano dati persistenti e, in tal caso, tali dati sono solitamente di valore e, pertanto, dovrebbero essere sottoposti a backup. Inoltre, l’intero sistema di container dovrebbe essere protetto e sottoposto a backup in modo che, qualora si verifichi una perdita o un danneggiamento, il sistema possa essere rapidamente ripristinato, riducendo al minimo la perdita di sistemi e servizi – e il potenziale impatto sul business – per un’organizzazione.
Kubernetes è la tecnologia di container più diffusa attualmente in uso. Pertanto, il tema dei diversi tipi di dati Kubernetes che devono essere sottoposti a backup richiede un’analisi approfondita.
Come per qualsiasi sistema complesso, Kubernetes e Docker dispongono di una serie di tipi di dati specifici necessari per ricostruire correttamente l’intero database in caso di disastro. Per semplificare, è possibile suddividere tutti i tipi di dati e file di configurazione in due diverse categorie: configurazione e dati persistenti.
La configurazione (e le informazioni sullo stato desiderato) include:
- Database etcd di Kubernetes
- File Docker
- Immagini dai file Docker
I dati persistenti (modificati o creati dai container stessi) sono:
- Database
- Volumi persistenti
Database etcd di Kubernetes
Si tratta di una parte integrante del sistema contenente informazioni sugli stati dei cluster. È possibile eseguire il backup manualmente o automaticamente, a seconda della soluzione di backup utilizzata. Il metodo manuale prevede l’utilizzo del comando etcdctl snapshot save db, che crea un singolo file denominato snapshot.db.
Un altro metodo per ottenere lo stesso risultato consiste nell’eseguire lo stesso comando immediatamente prima di creare un backup della directory in cui si troverebbe questo file. Questo è uno dei modi per integrare questo specifico backup nell’intero ambiente.
File Docker
Poiché i container Docker stessi vengono eseguiti a partire da immagini, queste immagini devono basarsi su qualcosa – e queste, a loro volta, vengono create dai file Docker. Per una corretta configurazione di Docker, si raccomanda di utilizzare un repository come sistema di controllo delle versioni per l’insieme dei propri file Docker (GitHub, ad esempio). Per facilitare il recupero delle versioni precedenti, tutti i file Docker dovrebbero essere archiviati in un repository specifico che consenta agli utenti di recuperare le versioni precedenti di tali file, se necessario.
Si raccomanda inoltre un repository aggiuntivo per i file YAML associati a tutte le distribuzioni Kubernetes; questi esistono sotto forma di file di testo. Anche il backup di questi repository è indispensabile, utilizzando strumenti di terze parti o le funzionalità integrate di servizi come GitHub.
È importante sottolineare che è comunque possibile generare i file Docker da sottoporre a backup, anche se si stanno eseguendo container da immagini prive dei relativi file Docker. Esiste un comando specifico, ovvero docker image history, che consente di creare un file Docker dalla propria immagine corrente. Esistono inoltre diversi strumenti di terze parti in grado di svolgere la stessa funzione.
Immagini dai file Docker
Anche le immagini Docker stesse dovrebbero essere sottoposte a backup in un repository. Sia il repository privato che quello pubblico possono essere utilizzati proprio a questo scopo. Diversi fornitori di servizi cloud tendono a fornire repository privati anche ai propri clienti. Se manca l’immagine da cui viene eseguito il container, un comando specifico, ovvero docker commit, dovrebbe essere in grado di creare tale immagine.
Database
L’integrità è fondamentale anche quando si ha a che fare con i database che i container utilizzano per archiviare i propri dati. In alcuni casi è possibile arrestare il container in questione prima di creare un backup dei dati, ma d’altra parte il tempo di inattività richiesto rischia di causare molti problemi all’azienda in questione.
Un altro metodo per eseguire backup dei database all’interno dei container consiste nel connettersi al motore del database stesso. È necessario utilizzare preventivamente un bind mount per collegare un volume che possa essere sottoposto a backup, dopodiché è possibile utilizzare il comando mysqldump (o simili) per creare un backup. Il file di backup in questione dovrebbe essere a sua volta sottoposto a backup utilizzando il proprio sistema di backup in un secondo momento.
Volumi persistenti
Esistono diversi metodi che consentono ai container di accedere a una sorta di archiviazione persistente. Ad esempio, se si tratta dei tradizionali volumi Docker, questi risiedono in una directory al di sotto della configurazione di Docker. I bind mount, d’altra parte, possono essere qualsiasi directory montata all’interno di un container. Nonostante i volumi tradizionali siano preferiti nella comunità Docker, entrambi sono relativamente simili quando si tratta di eseguire il backup dei dati. Un terzo modo per eseguire la stessa operazione consiste nel montare una directory NFS o un singolo oggetto come volume all’interno di un container.
Tutti e tre questi metodi presentano lo stesso problema quando si tratta di eseguire il backup dei dati: la coerenza di un backup non è completa se i dati all’interno di un container cambiano durante il backup. Naturalmente, è sempre possibile garantire la coerenza spegnendo il volume prima del backup, ma nella maggior parte dei casi i tempi di inattività per tali sistemi non sono realistici ai fini della continuità operativa.
Esistono alcuni modi per eseguire il backup dei dati all’interno dei container che sono specifici per il metodo utilizzato. Ad esempio, i volumi Docker tradizionali potrebbero essere montati su un altro container che non modificherebbe alcun dato fino al completamento del processo di backup. Oppure, se si utilizza un volume montato tramite bind, è possibile creare un’immagine tar dell’intero volume e quindi eseguire il backup dell’immagine.
Purtroppo, tutte queste opzioni possono rivelarsi davvero difficili da attuare quando si tratta di Kubernetes. Proprio per questo motivo, si raccomanda sempre di memorizzare le informazioni stateful nel database e al di fuori del filesystem del container.
Detto questo, se si utilizza una directory montata tramite bind o un file system montato tramite NFS come archiviazione persistente, è anche possibile eseguire il backup di tali dati utilizzando metodi standard, come uno snapshot. Ciò dovrebbe garantire una maggiore coerenza rispetto al tradizionale backup a livello di file dello stesso volume.
Cosa è necessario sottoporre a backup in un ambiente Kubernetes?
In un ambiente Kubernetes sono presenti diversi tipi di dati e ciascuno richiede specifiche considerazioni in materia di ripristino. È facile capire cosa deve essere sottoposto a backup; la difficoltà per la maggior parte dei team risiede piuttosto nel determinare quali componenti debbano essere sottoposti a backup e perché. Capire cosa deve essere sottoposto a backup è la parte facile; tuttavia, la maggior parte dei team ha difficoltà a stabilire quali componenti debbano avere la precedenza e perché.
Cosa recupera effettivamente un backup di etcd e cosa no?
Etcd è l’unica fonte di verità per lo stato dell’intero cluster. In quanto tale, è la cosa più importante da sottoporre a backup e, allo stesso tempo, il componente più frainteso. Uno snapshot di etcd consente di ripristinare lo stato dell’intero cluster a un determinato momento nel tempo, ma se il cluster attivo si è allontanato troppo dallo snapshot, si finirà per avere incongruenze tra ciò che etcd segnala come in esecuzione e ciò che è effettivamente presente.
Uno snapshot di etcd di per sé è insufficiente per ripristinare completamente il cluster in uno scenario di emergenza, poiché, pur contenendo lo stato del cluster, non contiene alcun dato dell’applicazione (che è memorizzato nei Persistent Volume) e non garantisce che lo stato ripristinato corrisponda a quello del cluster che avete ricostruito. I backup a livello di applicazione forniscono le informazioni mancanti ed è importante considerare gli snapshot di etcd come complementari ai backup a livello di applicazione piuttosto che come loro sostituti.
È necessario eseguire il backup dei volumi persistenti (PV) e delle richieste di volume persistente (PVC)?
Sì, è necessario eseguire il backup sia dei PV che dei PVC, ma la loro priorità dipende da cosa contengono esattamente. Alcuni PV contengono dati molto più preziosi di altri: un PV che garantisce la persistenza di un database con stato non presenta lo stesso fattore di rischio di un PV che contiene contenuti memorizzati nella cache.
Prima di scegliere la frequenza di backup, è opportuno classificare i PV in base alla criticità del ripristino per garantire che la pianificazione dei backup rifletta le esigenze aziendali e non attribuisca la stessa importanza a tutti i volumi.
Quali metadati del cluster (manifest, RBAC, CRD, configmap, secret) sono essenziali?
Tutti questi metadati sono importanti, ma non allo stesso livello quando si tratta di scenari di ripristino in cui il tempo è un fattore critico.
La perdita della configurazione RBAC e dei CRD è l’opzione più dirompente in questo caso, poiché definiscono ciò che è consentito fare e ciò che il resto del cluster utilizza come definizioni delle risorse. Senza queste informazioni, è altamente probabile che le applicazioni ripristinate tornino in uno stato inaccessibile o danneggiato.
ConfigMap e secret definiscono anch’essi il funzionamento delle applicazioni e sono spesso gli elementi più trascurati in una strategia di backup manuale. Anche i manifest sono estremamente importanti, ma se si dispone di un sistema GitOps, dovrebbe essere relativamente semplice recuperarli dal controllo del codice sorgente, il che li rende un po’ meno prioritari.
Come si dovrebbero trattare i dati effimeri e i log?
Dati effimeri – tutto ciò che esiste solo per la durata di un pod – in genere non dovrebbe essere sottoposto a backup, e tentare di farlo aggiunge complessità senza un valore significativo in termini di ripristino.
I log si trovano solitamente in una posizione simile: non dovrebbero essere sottoposti a backup come parte di una strategia di backup Kubernetes. L’opzione di gran lunga migliore è disporre di una pipeline di osservabilità dedicata che invii questi log a uno storage esterno indipendentemente dal processo di backup.
Una domanda più appropriata in questo contesto sarebbe se i dati che attualmente considerate effimeri debbano essere conservati. In caso affermativo, dovrebbero essere trasferiti su un volume persistente anziché essere inclusi nell’ambito del backup.
In che modo GitOps influisce sulla vostra strategia di backup di Kubernetes?
GitOps è un modello operativo in cui il repository Git memorizza l’intero stato di un ambiente Kubernetes, con tutti i manifest, le definizioni delle risorse e le configurazioni. Le informazioni in questione vengono inoltre continuamente riconciliate con il cluster attivo tramite uno strumento dedicato. Anziché applicare le modifiche direttamente al cluster, queste passano prima attraverso Git, rendendo il repository in questione l’unica fonte di verità su come il cluster dovrebbe apparire in qualsiasi momento.
È diventato rapidamente un modello diffuso negli ambienti Kubernetes, modificando l’equazione del backup in modi specifici – e le implicazioni di ciò non sono sempre immediate. È essenziale sapere dove questo approccio è utile e dove ha i suoi limiti prima di decidere quale livello di copertura di backup aggiungere.
In che modo GitOps cambia il vostro approccio al backup delle configurazioni?
Se i vostri manifesti Kubernetes, le configurazioni RBAC e le definizioni delle risorse sono memorizzati in Git e continuamente sincronizzati da uno strumento come ArgoCD o Flux, disponete già di una forma di backup delle configurazioni con controllo delle versioni.
Qualsiasi risorsa dichiarativa presente nel vostro repository Git può essere riapplicata a un cluster nuovo o ripristinato senza bisogno di un backup separato di quella risorsa. Si tratta di una semplificazione significativa del processo di configurazione del backup, poiché i manifesti e le descrizioni delle risorse del cluster già gestiti con GitOps possono diventare elementi di priorità inferiore nella vostra strategia di backup dedicata.
Cosa non copre GitOps e dove si applicano ancora i backup dedicati?
GitOps gestisce lo stato desiderato, non lo stato di runtime o i dati. Pertanto, i volumi persistenti, i segreti non committati su Git, i contenuti dei database e gli stati che esistono solo all’interno di un cluster in esecuzione sono tutti invisibili a GitOps.
Un cluster interamente gestito da GitOps può comunque subire una massiccia perdita di dati se i volumi persistenti non vengono sottoposti a backup in modo indipendente. I segreti sono solitamente esclusi esplicitamente dai repository per motivi di sicurezza, quindi richiedono anch’essi una copertura di backup indipendente.
GitOps non è un’alternativa a una strategia di backup; al contrario, sono complementari, e riconoscere il confine tra loro aiuta a evitare supposizioni errate su ciò che è coperto.
Best practice per le operazioni di backup di Kubernetes
Esistono numerose best practice che possono essere utilizzate per migliorare lo stato generale dei backup di K8s, tra cui la resilienza del cluster, la sicurezza dei dati e l’affidabilità del ripristino.
Eseguire il backup dei dati persistenti e dello stato del cluster
Lo stato del cluster include componenti chiave per un ambiente Kubernetes, tra cui segreti, ConfigMap, etcd e altro ancora. I volumi di dati persistenti costituiscono la maggior parte della dimensione dei dati, con file regolari, database, dati utente, log, ecc.
Configurare l’automazione del backup
L’automazione del backup riduce la probabilità di errore umano e introduce un elemento di coerenza e prevedibilità nel processo di backup. Numerose soluzioni di backup di terze parti offrono funzionalità di automazione avanzate, come la possibilità di pianificare le operazioni di backup tenendo conto di RTO e RPO specifici.
Utilizzare diversi tipi di backup quando possibile
I dati Kubernetes possono essere sottoposti a backup utilizzando diversi approcci, se il software lo consente. Ad esempio, i backup incrementali possono offrire una significativa riduzione dello spazio di archiviazione totale occupato, acquisendo solo le informazioni che sono state modificate in qualche modo dall’ultimo backup.
Verifichi i dati di backup
I backup non diventano invulnerabili non appena vengono creati, ed esiste la possibilità che le informazioni siano state in qualche modo danneggiate o perse durante il processo. Eseguire regolarmente processi di ripristino di prova rende più facile individuare tali errori e risolverli prima che si verifichi qualsiasi tipo di disastro.
Implementi la crittografia dei backup
La crittografia dei backup dovrebbe essere implementata, quando necessario, per le informazioni in transito e inattive, al fine di garantire il massimo livello possibile di sicurezza. La crittografia aiuta a proteggere i dati da violazioni e accessi non autorizzati. Esistono numerosi algoritmi di crittografia tra cui scegliere, se la soluzione di backup li supporta.
Valutare l’utilizzo di uno storage immutabile
L’utilizzo di strategie di immutabilità dei dati può essere una componente importante di una strategia di backup. Alcune soluzioni di backup offrono immutabilità software, mentre altre forniscono opzioni hardware dedicate come WORM (write-once-read-many) per proteggere le informazioni dalle minacce informatiche.
Ricordate le politiche di conservazione e il versioning
Il versioning è il processo di archiviazione delle copie precedenti delle vostre informazioni per motivi di conformità o praticità. Una politica di conservazione correttamente configurata dovrebbe specificare la durata del periodo di conservazione, al fine di trovare l’equilibrio tra il consumo di spazio di archiviazione e il soddisfacimento di tutti i requisiti necessari.
Verificate le funzionalità di backup multi-cluster
Se il vostro ambiente attuale utilizza più cluster Kubernetes, assicurarsi che la vostra soluzione di backup possa offrire un backup centralizzato può essere fondamentale. La capacità di gestire più ambienti contemporaneamente può semplificare notevolmente il processo di backup e migliorare la praticità complessiva del lavoro in un ambiente di questo tipo.
Implementare un software di backup cloud-native
La compatibilità con le infrastrutture cloud dinamiche è una caratteristica importante per qualsiasi soluzione di backup Kubernetes competente. Uno dei motivi è che i servizi in continua evoluzione offerti dal cloud computing possono apportare ulteriori vantaggi in termini di sicurezza a un’organizzazione. Assicurarsi che il software di backup scelto sia cloud-native e in grado di integrarsi con diversi servizi di archiviazione cloud può essere fondamentale.
Valutate attentamente la vostra intera strategia di disaster recovery
Le strategie di backup sono spesso migliori se progettate tenendo conto del disaster recovery, e Kubernetes non fa eccezione. Ad esempio, assicurarsi che i backup possano essere ripristinati su cluster diversi coprirebbe situazioni quali la migrazione o il guasto completo di un cluster. In alternativa, il supporto per i backup cross-cloud e cross-region rende possibile risolvere problemi legati al cloud o interruzioni a livello regionale.
Garantisca la sicurezza dei segreti di Kubernetes
I segreti di Kubernetes includono molte informazioni sensibili che vale la pena proteggere: password, chiavi API, certificati, ecc. Questo tipo di informazioni dovrebbe ricevere la massima priorità possibile in materia di sicurezza dei dati, con crittografia completa, immutabilità dei dati e così via.
Ceri di ottimizzare il costo dello storage di backup
Se possibile, è in genere importante implementare varie tecniche di gestione dello storage per ridurre la dimensione totale dei backup nel Suo ambiente di archiviazione. La compressione e la deduplicazione sono ugualmente efficaci a tal fine, ma entrambe presentano i propri svantaggi. Lo stesso vale anche per la maggior parte delle strategie di risparmio di spazio di archiviazione specifiche per il cloud.
Monitorare regolarmente i processi di backup
È forse irragionevole aspettarsi che qualcuno tenga d’occhio i processi di backup automatizzati 24 ore su 24, 7 giorni su 7. Pertanto, è necessario implementare sistemi dedicati di monitoraggio e notifica per assicurarsi che tutto funzioni senza intoppi. La maggior parte delle soluzioni offre persino l’opzione di inviare una notifica dedicata a una persona specifica qualora venisse rilevata un’irregolarità durante il processo di backup.
Implementare backup a livello di namespace per i cluster multi-tenant
Gli ambienti multi-tenant sopra menzionati possono essere supportati con l’ausilio di backup a livello di namespace. In questo modo, le informazioni di ciascun tenant avrebbero un file di backup separato, limitando la potenziale esposizione dei dati tra i tenant e offrendo al contempo ampia flessibilità per i processi di ripristino.
Fornire la documentazione per l’intera pipeline di backup e ripristino
L’intero processo di backup e ripristino dovrebbe essere ben documentato, incluse istruzioni dettagliate su come configurare, monitorare e verificare un backup, e così via. La stessa logica si applica ai processi di ripristino. Tale documentazione dovrebbe inoltre coprire i ruoli e le responsabilità dei dipendenti incaricati delle attività di amministrazione dei backup.
Come si dovrebbero progettare le pianificazioni di backup e le politiche di conservazione di Kubernetes?
Sapere cosa sottoporre a backup è solo metà dell’opera. L’altra metà consiste nel decidere con quale frequenza eseguire il backup e per quanto tempo conservare i dati sottoposti a backup. Le pianificazioni di backup e le politiche di conservazione non collegate a un obiettivo di ripristino tangibile diventano inevitabilmente o troppo aggressive (con conseguente spreco di risorse di archiviazione e di calcolo) o troppo sporadiche (con conseguenti periodi non recuperabili a seguito di un guasto).
Con quale frequenza è opportuno eseguire il backup di etcd, PV e dati delle applicazioni?
Non è necessario eseguire il backup di ogni componente con la stessa frequenza, come invece spesso si crede erroneamente. Etcd cambia costantemente insieme allo stato del cluster, quindi uno snapshot orario è sufficiente nella maggior parte degli ambienti di produzione. Tuttavia, un cluster in rapida evoluzione con un elevato turnover nelle distribuzioni o nelle configurazioni potrebbe richiedere snapshot più frequenti.
I volumi persistenti che contengono dati transazionali o generati dagli utenti dovrebbero essere sottoposti a snapshot almeno con la frequenza consentita dal proprio RPO, poiché è lì che risiedono i dati più significativi dal punto di vista operativo. I backup a livello di applicazione possono essere meno frequenti nella maggior parte dei casi, purché l’applicazione stessa abbia un certo grado di tolleranza per la riproduzione degli eventi o la ricostruzione dello stato. Tuttavia, tale tolleranza deve essere accuratamente convalidata rispetto all’RPO attuale prima di essere integrata nella propria pianificazione, anziché essere considerata un presupposto sicuro.
Quali finestre di conservazione sono in linea con i requisiti di RPO e RTO?
Due domande dovrebbero guidare la conservazione:
- Fino a quando è realmente necessario risalire nel tempo per il ripristino?
- Con quale rapidità è necessario poter effettuare il ripristino?
Un RPO basso non implica una conservazione prolungata, quindi conservare 30 giorni di snapshot orari è raramente pratico e spesso costoso. Una pratica migliore sarebbe quella di utilizzare una conservazione a più livelli: backup di durata più breve e altamente frequenti per il ripristino operativo, combinati con backup di durata più lunga ma meno frequenti a fini di audit o conformità. La chiave è che le finestre di conservazione debbano essere approvate esplicitamente da chiunque sia responsabile dello SLA di ripristino, non decise unilateralmente dal team che esegue i backup.
In che modo il ciclo di vita e la stratificazione possono ridurre i costi di backup?
I costi di archiviazione dei backup per i cluster Kubernetes possono aumentare rapidamente, specialmente quando si lavora con grandi volumi persistenti o si eseguono snapshot frequenti. L’implementazione di una politica di ciclo di vita aiuta a ridurre drasticamente i costi senza compromettere la capacità di ripristino.
Le politiche di ciclo di vita archiviano automaticamente i backup in livelli di storage più economici man mano che invecchiano – passando, ad esempio, dallo storage a blocchi ad alte prestazioni allo storage a oggetti dopo un certo periodo. Ciò comporta tuttavia un compromesso, poiché i livelli di storage più economici sono solitamente associati a tempi di ripristino più lunghi.
Prima di implementare le politiche di ciclo di vita è importante verificare i tempi di recupero per ciascuno dei livelli più economici e verificare se questi sono in linea con il proprio RTO per i punti di ripristino più datati. La maggior parte dei principali fornitori di servizi cloud include il supporto nativo per le politiche di ciclo di vita all’interno delle proprie soluzioni di archiviazione a oggetti, quindi l’implementazione di tali politiche dovrebbe presentare difficoltà minime o nulle nella maggior parte dei casi, una volta determinato il periodo di conservazione.
Come si proteggono i backup di Kubernetes e si soddisfano i requisiti di conformità?
La pianificazione dei backup è solo un tassello del puzzle operativo. La protezione effettiva dei backup stessi e la dimostrazione della conformità alla legislazione di governance pertinente sono entrambe sfide distinte che spesso vengono affrontate troppo tardi nel ciclo di vita. Il valore intrinseco dei dati di backup – in quanto quadro completo dell’infrastruttura – li rende un bersaglio allettante, e vi è una crescente attenzione ai requisiti di governance che li riguardano.
Come dovrebbero essere crittografati i dati di backup sia a riposo che in transito?
La decisione architettonica fondamentale in questo contesto non riguarda tanto quale algoritmo di crittografia utilizzare (poiché la maggior parte degli attuali prodotti di backup ha un’impostazione predefinita a cui è comunque consigliabile attenersi), quanto piuttosto assicurarsi che la crittografia sia applicata su base end-to-end.
Se i dati a riposo sono crittografati ma il transito tra il cluster e la destinazione di archiviazione non lo è, i dati non saranno al sicuro durante il trasferimento. Se le chiavi di crittografia sono archiviate in stretta vicinanza ai dati di backup che stanno crittografando, è probabile che anche queste siano insicure.
Le chiavi di crittografia devono essere archiviate separatamente dalla destinazione di backup, sia con l’ausilio di un servizio di gestione delle chiavi sia tramite un modulo di sicurezza hardware. L’accesso a tali chiavi dovrebbe inoltre essere gestito esclusivamente da un’entità autorizzata ad accedere al backup stesso.
Chi dovrebbe avere accesso alle funzionalità di backup e ripristino?
L’accesso al ripristino viene spesso equiparato all’accesso al backup, ma le implicazioni in termini di rischio sono completamente diverse. La capacità di ripristinare un backup su un cluster o uno spazio dei nomi potenzialmente separato equivale alla possibilità di trasferire dati sensibili e, pertanto, richiede un livello di controllo più elevato rispetto alla semplice creazione del backup stesso.
In pratica, la creazione dei backup può essere ragionevolmente automatizzata e ampiamente consentita, mentre le operazioni di ripristino dovrebbero richiedere un’autorizzazione esplicita – idealmente con un secondo approvatore per gli ambienti di produzione. Tale distinzione dovrebbe riflettersi nella configurazione RBAC ed essere documentata in modo sufficientemente chiaro da resistere ai cambiamenti di personale.
Quali funzionalità di audit, registrazione e immutabilità sono necessarie per la conformità?
Oltre a garantire l’esistenza dei backup, i framework di conformità richiederanno anche che un’azienda sia in grado di dimostrarne l’esistenza. Ogni operazione di backup, tentativo di accesso e richiesta di ripristino dovrà essere verificabile e conservata in base alle esigenze del vostro framework – il che significa che i log devono essere scritti in modo da essere a prova di manomissione.
L’archiviazione immutabile, che impedisce la cancellazione o la modifica dei dati di backup per un determinato periodo di tempo, sta rapidamente diventando obbligatoria anziché facoltativa negli ambienti che gestiscono informazioni private o finanziarie – e HIPAA e SOC 2 ne menzionano specificamente la necessità.
Ciò significa anche che sia alla traccia di audit che ai dati sottoposti a backup deve essere attribuita uguale importanza: i dati di cui non è possibile dimostrare la conformità offrono meno valore quando gli auditor vengono a controllare.
Metodologia per la scelta della migliore soluzione di backup Kubernetes possibile
Esiste un buon numero di soluzioni di terze parti che offrono funzionalità di backup Kubernetes in un modo o nell’altro. Il backup di K8s è un’attività molto importante, pertanto la scelta di una soluzione di backup riveste la stessa importanza. Di conseguenza, siamo in grado di offrire una metodologia approfondita su come scegliere la migliore soluzione di backup Kubernetes possibile per la vostra specifica organizzazione.
Tipi di dati coperti dalla soluzione
Verificare se la soluzione di backup offre la possibilità di supportare un tipo di dati richiesto è una priorità per qualsiasi azienda o attività commerciale alla ricerca di una soluzione di backup per Kubernetes. Pertanto, abbiamo aggiunto informazioni sui tipi di dati di cui ogni singola soluzione del nostro elenco è in grado di creare un backup. Il risultato complessivo di questo confronto è presentato di seguito in una tabella (la tabella in questione è divisa in due parti per una maggiore facilità di consultazione).
Tabella #1
| Software | Kasten | Portworx | Cohesity | OpenEBS | Veritas |
| Deployments | Sì | Sì | Sì | Sì | Sì |
| StatefulSets | Sì | Sì | Sì | Sì | Sì |
| DaemonSets | Sì | Sì | Sì | Sì | Sì |
| Pods | Sì | Sì | Sì | Sì | Sì |
| Servizi | Sì | Sì | Sì | Sì | Sì |
| Segreti e/o ConfigMaps | Sì | Sì | Sì | Sì | Sì |
| Volumi persistenti | Sì | Sì | Sì | Nessun dato | Sì |
| Namespaces | Sì | Sì | Sì | Nessun dato | Sì |
| Applicazioni | Sì (Integrazioni) | Nessun dato | Sì (messaggistica + database) | Nessun dato | Nessun dato |
| Infrastruttura di storage | Nessun dato | Nessun dato | Sì | Nessun dato | Nessun dato |
Tabella #2
| Software | Stash | Rubrik | Druva | Zerto | Longhorn |
| Deployments | Sì | Sì | Sì | Sì | Sì |
| StatefulSets | Sì | Sì | Sì | Sì | Sì |
| DaemonSets | Sì | Sì | Sì | Sì | Sì |
| Pods | Sì | Sì | Sì | Sì | Sì |
| Servizi | Sì | Sì | Sì | Sì | Sì |
| Segreti e/o ConfigMaps | Sì | Sì | Sì | Sì | Sì |
| Volumi persistenti | Sì | Sì | Sì | Sì | Sì |
| Namespaces | Sì | Sì | Sì | Sì | Nessun dato |
| Applicazioni | Nessun dato | Sì (Database) | Sì (Banche dati) | Nessun dato | Nessun dato |
| Infrastruttura di storage | Nessun dato | Sì | Nessun dato | Nessun dato | Nessun dato |
Va notato che il supporto per i diversi tipi di dati è un fattore importante, ma nella maggior parte dei casi non è un fattore di rottura, quindi si consiglia di considerarlo come uno dei diversi fattori in questo confronto.
Valutazioni dei clienti
Queste valutazioni possono essere interpretate in molti modi diversi: quanto è brava la soluzione a svolgere il suo lavoro, quanto è competente nei confronti dei feedback dei clienti, come può (o non può) evolvere nel tempo e così via. Nel nostro caso, le valutazioni dei clienti provenienti da siti web di terze parti esistono per mostrare la competenza complessiva della soluzione utilizzando vari siti web di raccolta di recensioni come Capterra, TrustRadius e G2.
Capterra è una piattaforma di aggregazione di recensioni che offre recensioni verificate, indicazioni, approfondimenti e confronti tra soluzioni. I clienti vengono controllati accuratamente per verificare che siano effettivamente clienti reali della soluzione in questione e i venditori non hanno la possibilità di rimuovere le recensioni dei clienti. Capterra ha oltre 2 milioni di recensioni verificate in quasi mille categorie diverse, il che lo rende un’ottima opzione per trovare tutti i tipi di recensioni su un prodotto specifico.
TrustRadius è una piattaforma di recensioni che proclama il suo impegno per la verità. Utilizza un processo in più fasi per garantire l’autenticità delle recensioni e ogni singola recensione viene verificata in modo dettagliato, approfondito e completo dal team di ricerca dell’azienda. Non c’è modo per i venditori di nascondere o cancellare le recensioni degli utenti in un modo o nell’altro.
G2 è un altro buon esempio di piattaforma aggregatrice di recensioni che vanta oltre 2,4 milioni di recensioni verificate ad oggi con oltre 100.000 fornitori diversi presentati. G2 dispone di un proprio sistema di convalida delle recensioni degli utenti che si afferma essere estremamente efficace nel dimostrare che ogni singola recensione è autentica e genuina. G2 offre anche servizi separati per scopi di marketing, investimenti, monitoraggio e altro ancora.
Caratteristiche principali (nonché vantaggi/svantaggi)
L’elenco dei fattori importanti che una soluzione di backup Kubernetes competente deve avere include i seguenti:
- Alta disponibilità dei dati per un migliore disaster recovery e una maggiore tolleranza a vari problemi con cluster e container.
- Diversi tipi di backup, tra cui backup incrementali e app-aware.
- Granularità del backup, con la possibilità di creare backup di oggetti specifici e non solo di interi namestate (volumi, pod, PV, ecc.).
- Schedulazione dei backup per semplificare le operazioni quotidiane.
- Integrazione con i provider di cloud storage (Azure Blob, GCP, S3, ecc.) per semplificare il processo di backup e offrire una maggiore varietà in termini di storage di backup.
- Cifratura dei dati per una migliore protezione delle informazioni.
- Il supporto per carichi di lavoro personalizzati consente di estendere le funzionalità di backup tramite plugin e integrazioni.
Questo è rappresentato anche dalla categoria “vantaggi/svantaggi” (se applicabile), che mostra sia gli aspetti positivi che quelli negativi della soluzione raccolti da una moltitudine di recensioni degli utenti.
Prezzi
Le caratteristiche di una soluzione sono importanti per l’utente finale, ma il tema del prezzo è altrettanto importante. Alcune aziende hanno un budget molto limitato, mentre altre hanno bisogno di una serie di funzionalità specifiche nonostante il prezzo potenzialmente elevato. Tuttavia, la maggior parte dei potenziali clienti si colloca a metà tra questi due esempi. È consigliabile verificare sia il prezzo che il set di funzionalità della soluzione, valutando anche le une rispetto alle altre: anche se la soluzione rientra nel vostro budget, potrebbe non essere un buon affare in termini di funzionalità rispetto alla concorrenza.
Un’opinione personale dell’autore
L’unica parte completamente soggettiva di questa metodologia è l’opinione dell’autore sull’argomento (soluzione di backup Kubernetes, nel nostro caso). Ci sono molti casi d’uso diversi per questa particolare categoria, comprese informazioni interessanti sulla soluzione che non rientrano in nessuna delle categorie precedenti o semplicemente l’opinione personale dell’autore su questo argomento specifico.
Mercato delle soluzioni di backup di Kubernetes
Alla luce di questi tre importanti fattori/caratteristiche, esaminiamo alcuni ulteriori esempi di soluzioni di backup e ripristino per K8s.
Kasten K10

Kasten K10 (recentemente acquisito da Veeam) è una soluzione di backup e ripristino che è anche orgogliosa dei suoi sistemi di mobilità e disaster recovery. Il processo di backup con Kasten è semplificato grazie alla sua capacità di rilevare automaticamente le applicazioni, oltre a molte altre funzionalità, come la crittografia dei dati, il controllo degli accessi basato sui ruoli e un’interfaccia user-friendly. Allo stesso tempo, può funzionare con molti servizi di dati diversi, come MySQL, PostgreSQL, MongoDB, Cassandra, AWS e così via.
L’alta disponibilità locale non è disponibile, poiché Kasten non supporta direttamente la replica all’interno di un singolo cluster e si affida invece ai sistemi di archiviazione dati sottostanti. Anche il disaster recovery è solo parzialmente “presente”, poiché Kasten non può raggiungere casi di RPO pari a zero a causa della mancanza di un componente di percorso dei dati. Da notare anche il fatto che i backup di Kasten sono solo asincroni, il che comporta in genere un tempo di inattività aggiuntivo tra le operazioni.
Tipi di dati coperti da Kasten K10:
Kasten K10 è in grado di creare backup di tutti i dati generati da Kubernetes, compresi servizi, distribuzioni, PV, spazi dei nomi e così via. Ci sono solo due eccezioni: la copertura delle applicazioni di Kasten può essere estesa e migliorata tramite integrazioni con altre soluzioni di backup e ripristino.
Valutazioni dei clienti:
- (Kasten) G2 – 4,7/5 stelle sulla base di 10 recensioni di clienti
- (Veeam) Capterra – 4,8/5 stelle sulla base di 69 recensioni dei clienti
- (Veeam) TrustRadius – 8,8/10 stelle sulla base di 1.237 recensioni dei clienti
- (Veeam) G2 – 4,6/5 stelle sulla base di 387 recensioni dei clienti
Caratteristiche principali:
- Scalabilità ed efficienza impressionanti
- Protezione ransomware altamente efficace
- Creato utilizzando i principi architettonici cloud-nativi
Prezzi (al momento della stesura del presente documento):
- La pagina dei prezzi di Kasten K10 afferma che ci sono tre edizioni del software (anche se c’è solo un’edizione effettiva, e le altre due sono rispettivamente la versione gratuita e la versione di prova).
- “Free” è una versione molto limitata di Kasten K10 con funzionalità di backup Kubernetes minime, che includono fino a 5 nodi al massimo, oltre a operazioni di backup/ripristino, disaster recovery, protezione da ransomware e la maggior parte delle altre funzionalità di Kasten.
- “Enterprise Trial” è la versione di Kasten di una prova gratuita a tempo, che offre l’intero set di funzionalità di Kasten, un limite massimo di 50 nodi, oltre all’assistenza clienti, alla distribuzione assistita da Kasten e alla valutazione della protezione dei dati.
- “Enterprise” è l’unico livello di abbonamento effettivo di Kasten K10; elimina completamente la limitazione del “numero di nodi” e offre la serie completa di funzioni di backup e ripristino di Kasten.
- Vale la pena notare che sul sito ufficiale di Kasten non sono disponibili informazioni sui prezzi, il che significa che l’unico modo per riceverle è richiedere un preventivo personalizzato all’azienda in questione.
La mia opinione personale su Kasten K10:
Kasten K10 è una soluzione di backup piuttosto valida che funziona con diversi tipi di ambienti, tra cui Kubernetes, Cassandra, PostgreSQL, MySQL e altri ancora. Recentemente è stata acquisita da Veeam, una delle soluzioni di backup di livello aziendale più note sul mercato. Finora Kasten è riuscita a mantenere il proprio nome, presentandosi nella maggior parte dei casi come «Kasten by Veeam». Non è una soluzione negativa di per sé, ma le sue funzionalità relative a Kubernetes sono piuttosto basilari e limitate. Traspone la maggior parte delle sue funzionalità generali nei backup di Kubernetes, come la crittografia dei dati e l’RBAC, ma la creazione di questi backup non è un processo semplice. Kasten non offre alta disponibilità locale per Kubernetes, la sua implementazione del disaster recovery è solo parziale (RPO non pari a zero) e tutti i backup sono rigorosamente asincroni.
Portworx

Portworx PX-Backup è una società di gestione dei dati che sviluppa una piattaforma di archiviazione basata sul cloud per gestire e accedere al database dei progetti Kubernetes. È un altro esempio di soluzione di gestione dei dati e, nonostante i suoi limiti in quanto tale, uno dei vantaggi principali dell’utilizzo di Portworx è l’elevata disponibilità dei dati.
Le operazioni di backup e ripristino, la comprensione delle app Kubernetes, l’alta disponibilità locale e il disaster recovery, tra le altre caratteristiche, rendono Portworx una buona soluzione per il backup di Kubernetes. Considerando come fanno le varie soluzioni di backup Kubernetes di terze parti, Portworx potrebbe anche essere interessante per un utente che cerca specificamente funzionalità di backup Kubernetes.
Un altro aspetto significativo di PX-Backup è la sua scalabilità, che consente di eseguire backup on-demand o programmati di centinaia di applicazioni contemporaneamente. La soluzione supporta anche le configurazioni multi-database e può ripristinare le applicazioni direttamente sui servizi cloud, come Amazon, Google, Microsoft, ecc.
Tipi di dati coperti da Portworx:
Portworx supporta la creazione di backup per Namespace, PV, DaemonSet, Deployment e altro ancora. T-I non è riuscito a trovare informazioni sulla possibilità o meno di supportare il backup delle applicazioni o dell’infrastruttura di storage.
Valutazioni dei clienti:
- G2 – 4,4/5 stelle sulla base di 16 recensioni di clienti
Svantaggi:
- Soluzione di backup affidabile e ad alte prestazioni
- Infrastruttura scalabile e affidabile
- Crittografia dei dati e controllo dettagliato degli accessi
Carenze:
- La configurazione del software nel suo complesso può essere piuttosto complicata
- L’esperienza del supporto clienti è incoerente
- Le funzionalità di sicurezza sono limitate nel contesto di grandi distribuzioni aziendali
Prezzi (al momento della stesura del presente documento):
- Il modello di prezzo di Portworx è piuttosto semplice: esiste una versione gratuita disponibile per tutti gli utenti che creano un account Portworx; questa versione è limitata a 1 cluster e a un massimo di 1 TB di dati applicativi.
- Esiste anche una versione a pagamento del software con un set completo di funzionalità, tra cui i backup app-aware, il ripristino con un solo clic, la protezione da ransomware e così via. Purtroppo, sul sito web di Portworx non sono disponibili prezzi ufficiali, che possono essere ottenuti solo contattando direttamente l’azienda per un preventivo personalizzato.
La mia opinione personale su Portworx:
Portworx si promuove come una piattaforma di servizi per i dati, offrendo molte funzionalità che sono per lo più incentrate su Kubernetes e i suoi container. La piattaforma Portworx può offrire numerosi servizi, tra cui backup, disaster recovery, storage, DevOps e database. I backup di Portworx offrono alta disponibilità, consapevolezza dell’applicazione e molte funzioni che di solito non sono disponibili nelle offerte di backup Kubernetes. È una soluzione veloce e scalabile, ma ha anche dei lati negativi. Un esempio di tale aspetto negativo è la presenza piuttosto limitata sul mercato, che crea molti fattori di disagio, come la mancanza di tutorial dettagliati su Internet. La soluzione in questione può anche essere piuttosto complicata, il che la rende difficile da utilizzare per i neofiti del settore.
Cohesity

Cohesity è un concorrente relativamente popolare nel campo del backup e del ripristino in generale, ma le sue funzionalità relative a Kubernetes hanno ancora spazio per crescere. Innanzitutto, Kubernetes è un’aggiunta relativamente nuova per loro, in quanto ha aggiunto la comprensione delle app Kubernetes. Tuttavia, funziona solo per tutte le applicazioni all’interno dello stesso spazio dei nomi e non è possibile proteggere applicazioni specifiche all’interno dello stesso spazio dei nomi.
D’altro canto, sono disponibili anche funzionalità di ripristino rapido, backup incrementali app-tier basati su policy, consolidamento dello stato dei dati e molte altre funzionalità.
Tipi di dati coperti da Cohesity:
La soluzione di Cohesity supporta backup di Namespace, backup di servizi, backup di deployment e altro ancora. È presente il supporto per il backup dell’infrastruttura di storage e l’unico fattore degno di nota per questa categoria è che il backup delle applicazioni di Cohesity può coprire anche i database in cui lavorano le applicazioni e i sistemi di messaggistica distribuiti in Kubernetes.
Valutazione dei clienti:
- Capterra – 4,6/5 stelle sulla base di 48 recensioni dei clienti
- TrustRadius – 8,9/10 stelle sulla base di 59 recensioni dei clienti
- G2 – 4,4/5 stelle sulla base di 45 recensioni dei clienti
Svantaggi:
- Gestione del backup e del ripristino semplice e conveniente
- Processo di installazione e configurazione iniziale semplice e senza problemi
- La facile pianificazione con l’aiuto della creazione di profili consente una maggiore automazione
- Backup incrementali consapevoli delle applicazioni, funzionalità di ripristino rapido per le app Kubernetes e altro ancora
Carenze:
- Alcuni aggiornamenti devono essere installati manualmente tramite riga di comando, in netto contrasto con la consueta installazione automatica degli aggiornamenti basata su GUI.
- I “backup immutabili” di Cohesity possono ancora essere modificati o cancellati da un utente con credenziali di livello amministratore.
- L’assistenza clienti si basa molto sulle risposte standard e può essere poco disponibile.
- La funzione di backup di Kubernetes è relativamente nuova per Cohesity e può essere un po’ approssimativa.
Prezzi (al momento della stesura del presente documento):
- Le informazioni sui prezzi di Cohesity non sono pubblicamente disponibili sul sito web ufficiale e l’unico modo per ottenerle è contattare direttamente l’azienda per una prova gratuita o una demo guidata.
- Le informazioni non ufficiali sui prezzi di Cohesity affermano che le sole apparecchiature hardware hanno un prezzo di partenza di 110.000 dollari USA.
La mia opinione personale su Cohesity:
Cohesity è una solida soluzione di backup e ripristino che supporta una serie di tipi di storage diversi e offre anche molte funzioni con cui lavorare. L’intera soluzione è costruita utilizzando un’insolita struttura a nodi che rende Cohesity estremamente facile da scalare in entrambi i sensi. È veloce, versatile e rappresenta un’ottima opzione per la creazione di backup delle infrastrutture applicative. Per quanto riguarda in particolare le funzionalità legate a Kubernetes, queste potrebbero richiedere un po’ di lavoro in futuro, dato che il supporto a Kubernetes è un’aggiunta relativamente recente a Cohesity e alcune sfumature sono ancora in via di definizione su base regolare. È in grado di proteggere solo i dati delle applicazioni dello stesso namespace e non esiste un’opzione per proteggere anche applicazioni specifiche, ma solo l’intero namespace. Allo stesso tempo, Cohesity è in grado di offrire molte delle proprie funzionalità che ora sono applicabili ai backup Kubernetes, tra cui il consolidamento dello stato dei dati, il supporto del backup incrementale e altro ancora.
OpenEBS

OpenEBS è un altro esempio di soluzione che è riuscita a ottenere dei risultati con una sola delle tre caratteristiche del nostro elenco, e in questo caso si tratta dell’alta disponibilità locale.
Allo stesso tempo, OpenEBS può integrarsi con Velero, creando una soluzione Kubernetes combinata che eccelle nella migrazione dei dati Kubernetes. Da solo, OpenEBS è in grado di eseguire il backup solo di singole applicazioni (esattamente l’opposto di quanto fa Cohesity). Sono inoltre disponibili funzionalità quali lo storage multi-cloud, la natura open-source e un ampio elenco di piattaforme Kubernetes supportate, da AWS e Digital Ocean a Minikube, Packet, Vagrant, GCP e altre ancora.
Tuttavia, questo potrebbe non coprire le esigenze di un utente, poiché alcuni utenti potrebbero aver bisogno di backup dello spazio dei nomi in casi specifici.
Tipi di dati coperti da OpenEBS:
OpenEBS è una soluzione abbastanza versatile; può creare backup di intere distribuzioni, così come di Pod, ConfigMaps, StatefulSets, ecc. Tuttavia, è piuttosto limitata rispetto ad altre, tra cui la mancanza di backup dell’infrastruttura di storage, l’assenza di backup delle applicazioni e l’assenza di backup a livello di Namespace e PV.
Caratteristiche principali:
- Utilizza i modelli di Container Attached Storage per una migliore efficienza di backup.
- Consente alle applicazioni stateful di accedere in modo rapido e semplice sia ai PV replicati che ai PV locali dinamici.
- Semplifica la gestione delle applicazioni cross-cloud, compresa la replica dello storage e il provisioning automatico.
Prezzi (al momento della stesura del presente documento):
- OpenEBS è una soluzione gratuita e open-source, ma ci sono anche individui e aziende di terze parti che possono fornire servizi o prodotti correlati a OpenEBS in qualche modo, forma o modo.
La mia opinione personale su OpenEBS:
OpenEBS rappresenta in questo caso un netto contrasto rispetto a Cohesity: si tratta di una soluzione di gestione dei dati relativamente compatta, incentrata specificatamente sugli ambienti Kubernetes, che pone al contempo l’accento principalmente sull’elevata disponibilità dei dati a livello locale come caratteristica principale. Il software in questione può essere facilmente integrato con Velero, un altro software gratuito e open source su piccola scala che offre molto di più in termini di backup Kubernetes. Questo tipo di integrazione crea un’offerta di backup e gestione dei dati piuttosto potente (e gratuita) che funziona con una varietà di piattaforme Kubernetes, offre supporto per lo storage multi-cloud, fornisce funzionalità di migrazione dei dati e così via. Come praticamente per qualsiasi soluzione gratuita di quella portata, il problema principale di OpenEBS (e Velero) è una curva di apprendimento piuttosto ripida che rende difficile l’approccio iniziale e aumenta drasticamente il tempo necessario per padroneggiare tutte le funzionalità della soluzione.
Veritas

Veritas è un fornitore di software di backup ben consolidato e presente sul mercato da diversi decenni; è ampiamente preferito dalle aziende più grandi e più antiche proprio per questo motivo. È in grado di offrire un gran numero di funzionalità e capacità diverse, oltre a supportare una varietà di tipi di storage di destinazione che vanno dallo storage fisico alle macchine virtuali, ai database, allo storage in-the-cloud e altro ancora. Per quanto riguarda le funzionalità di Kubernetes, Veritas offre ampie capacità di registrazione, un’amministrazione semplice ma efficace, supporto RBAC, elevata disponibilità dei dati, replica dei dati e molto altro. Si tratta di un’ottima opzione per le attività di backup e ripristino nel loro complesso, che offre protezione dei dati e ricchezza di funzionalità in un unico pacchetto.
Tipi di dati coperti da Veritas:
Le capacità di Veritas nel campo dei backup Kubernetes sono piuttosto impressionanti e comprendono la copertura di Namespace, Deployments, Secrets, Pods e così via. Tuttavia, non è in grado di eseguire backup delle applicazioni e lo stesso vale per i backup dell’infrastruttura di storage.
Valutazioni dei clienti:
- Capterra – 4.0/5 stelle sulla base di 7 recensioni dei clienti
- TrustRadius – 6,8/10 stelle sulla base di 150 recensioni dei clienti
- G2 – 4,1/5 stelle sulla base di 230 recensioni dei clienti
Svantaggi:
- Una serie di funzionalità estremamente ampia e variegata, spesso considerata una delle più grandi centrali di funzionalità sul mercato.
- Lo stato visivo relativamente datato dell’interfaccia non cambia il fatto che sia facile da usare per tutti i tipi di clienti, compresi i neofiti del settore.
- L’esperienza del supporto clienti ha raccolto molte recensioni positive nel corso degli anni, con il team di supporto che fornisce risposte rapide e concise a un’ampia varietà di problemi.
Carenze:
- Una gamma di funzionalità estremamente ampia e variegata, spesso considerata una delle più complete sul mercato.
- L’integrazione con le librerie a nastro LTO è disponibile in una certa misura, ma per ora funziona con una serie di gravi difetti.
- L’esportazione dei report nel suo complesso è piuttosto impegnativa da eseguire.
Prezzi (al momento della stesura del presente documento):
- Non ci sono informazioni ufficiali sui prezzi sul sito web di Veritas, l’unico modo per ottenerle è contattare direttamente l’azienda.
La mia opinione personale su Veritas:
Veritas viene spesso elogiata come una delle soluzioni di backup e ripristino più vecchie sul mercato, ancora in forma e in competizione con altre soluzioni di rilievo. Questo non significa che l’età sia l’unico vantaggio che Veritas può offrire: ha anche un set di funzionalità estremamente ampio, un’interfaccia incredibilmente facile da usare e un team di assistenza clienti estremamente disponibile. Veritas riesce anche a semplificare e migliorare notevolmente vari aspetti della gestione dei container Kubernetes, tra cui le funzionalità di backup e ripristino dei dati dei container, il failover e il failback automatici, la distribuzione del traffico tra le istanze, la scoperta automatica degli spazi dei nomi e altro ancora. Veritas offre operazioni di backup e ripristino delle applicazioni containerizzate semplici e accessibili, rendendola una soluzione di backup Kubernetes piuttosto conveniente. Veritas ha qualche problema con il suo sistema di reporting nel suo complesso e l’integrazione con i nastri LTO è piuttosto problematica, ma nessuno di questi problemi influisce sulle funzionalità relative a Kubernetes tanto da costituire un vero problema per gli utenti attuali e futuri. Nel complesso, il prezzo può essere un ostacolo.
Stash

Stash è una soluzione di backup e disaster recovery costruita appositamente per Kubernetes. È in grado di ripristinare i dati di Kubernetes a diversi livelli, compresi i database (MongoDB, MySQL, PostgreSQL), i volumi (set statici, distribuzioni, volumi autonomi) e persino le normali risorse di Kubernetes (segreti, configurazioni YAML, ecc.). Supporta una serie di opzioni di automazione, può essere integrato con diversi fornitori di cloud storage, supporta carichi di lavoro personalizzati e altro ancora. È anche una soluzione relativamente nuova in questo campo, quindi presenta alcuni problemi di crescita.
Tipi di dati coperti da Stash:
Stash è una soluzione di backup relativamente piccola, ma la sua copertura di Kubernetes è comunque notevole, con il supporto di Deployments, Services, Pods, DaemonSets e persino backup dell’infrastruttura di storage. Tuttavia, non è in grado di creare copie di Kubernetes a livello di spazio dei nomi e non supporta nemmeno il backup delle applicazioni.
Caratteristiche principali:
- Il supporto della funzionalità CSI VolumeSnapshotter consente di ampliare in modo significativo le opzioni di backup di Kubernetes di Stash.
- La capacità di integrarsi con lo strumento Restic offre funzionalità quali deduplicazione, crittografia, backup incrementali e altro ancora.
- Stash può lavorare con diversi fornitori di cloud storage come archivio di backup: Azure Blob, GCP, AWS S3, ecc.
- Sono disponibili numerose opzioni di pianificazione, tutte personalizzabili in vari modi.
Prezzi (al momento della stesura del presente documento):
- Non ci sono informazioni ufficiali sui prezzi disponibili sul sito web di Stash, ma c’è una richiesta di “contattaci”, il che significa che tutte le informazioni sui prezzi sono altamente personalizzate e non sono ottenibili tramite mezzi pubblici.
La mia opinione personale su Stash:
Stash potrebbe essere la soluzione di backup meno conosciuta di questo elenco. Si tratta di una soluzione di backup e disaster recovery su scala molto ridotta per Kubernetes e nient’altro. Stash può lavorare con risorse Kubernetes, volumi e persino database, offrendo la possibilità di creare backup di molti ambienti e tipi di dati, da MongoDB e PostgreSQL alle configurazioni YAML delle implementazioni. Si tratta di una soluzione veloce con molte funzionalità incentrate su Kubernetes che sono una rarità in altre soluzioni di backup. Ad esempio, Stash supporta la funzionalità CSI VolumeSnapshotter e può essere integrato con lo strumento Restic per operazioni di protezione dei dati migliori e più versatili. È ancora in fase di sviluppo, ma promette molto bene per il futuro e la complessità generale della soluzione è probabilmente il problema più grande al momento, un problema che può essere risolto con il tempo e l’impegno.
Rubrik

Molti altri operatori più importanti nel campo del backup e del ripristino hanno iniziato a offrire i propri servizi in termini di backup e ripristino di Kubernetes – Rubrik ne è un buon esempio: consente agli utenti di implementare il vasto set di funzionalità di gestione di Rubrik nel campo delle implementazioni Kubernetes.
Consente una flessibilità in termini di destinazione del ripristino, nonché la protezione degli oggetti Kubernetes e una piattaforma unificata che fornisce approfondimenti e una panoramica dell’intero sistema. Ci sono anche funzioni come l’automatizzazione dei backup, il ripristino granulare, la replica degli snapshot e altro ancora. Rubrik può anche lavorare con i Persistent Volumes ed è in grado di replicare gli spazi dei nomi, offrendo una variazione quando si tratta di sviluppo e test prima della distribuzione.
Tipi di dati coperti da Rubrik:
Rubrik è una delle migliori opzioni di questo elenco per quanto riguarda tutti i tipi di dati Kubernetes di cui può creare un backup. Questo include deployment, spazi dei nomi, infrastrutture di storage, servizi, pod, statefulset e praticamente tutto il resto. L’unico fattore degno di nota è che Druva può coprire sia le applicazioni che i database utilizzati.
Valutazioni dei clienti:
- Capterra – 4,7/5 stelle sulla base di 45 recensioni di clienti
- TrustRadius – 9,1/10 stelle sulla base di 198 recensioni dei clienti
- G2 – 4,6/5 stelle sulla base di 59 recensioni dei clienti
Vantaggi:
- Una soluzione versatile per il backup e il ripristino con prestazioni elevate.
- Varie integrazioni con altri servizi e tecnologie, come SQL Server, VMware, M365, ecc.
- Capacità di protezione dei dati affidabili con buona crittografia, forte sicurezza e ransomware
- Supporta numerose funzionalità per le applicazioni Kubernetes, tra cui la replica degli snapshot, l’automazione del backup, il ripristino granulare e molte altre ancora.
Carenze:
- L’implementazione di RBAC è alquanto basilare e manca di molte delle funzionalità necessarie che la concorrenza possiede.
- La personalizzazione di audit/report è molto limitata e i report non sono abbastanza dettagliati, in generale.
- Il costo complessivo della soluzione potrebbe essere eccessivo per le aziende e le imprese di piccole o medie dimensioni
- Scalabilità limitata
Prezzi (al momento della stesura del presente documento):
- Le informazioni sui prezzi di Rubrik non sono disponibili pubblicamente sul sito web ufficiale e l’unico modo per ottenerle è contattare direttamente l’azienda per una demo personalizzata o per uno dei tour guidati.
- Le informazioni non ufficiali affermano che ci sono diversi dispositivi hardware che Rubrik può offrire, come:
- Nodo Rubrik R334 – a partire da 100.000 dollari per un 3-nodi con processi Intel a 8 core, 36 TB di storage, ecc.
- Rubrik R344 Node – a partire da 200.000$ per un 4-nodi con parametri simili a quelli dell’R334, 48 TB di storage, ecc.
- Nodo Rubrik R500 Series – a partire da 115.000$ per un 4-nodi con processori Intel 8-Core, 8×16 DIMM di memoria, ecc.
La mia opinione personale su Rubrik:
Le capacità di Rubrik in termini specifici di Kubernetes possono non essere particolarmente estese, ma la soluzione in sé è ben nota e rispettata nel settore, in quanto fornisce una sofisticata piattaforma di backup e ripristino con un numero enorme di funzionalità. Rubrik è in grado di offrire protezione, migrazione dei dati e supporto generale per le istanze Kubernetes, soprattutto ampliando le proprie funzionalità esistenti per coprire gli ambienti Kubernetes. Rubrik è in grado di replicare i namespace e di lavorare con i Persistent Volumes, il che lo rende un’offerta interessante da prendere in considerazione per le aziende più grandi. Tuttavia, sarebbe giusto menzionare che Rubrik ha la sua parte di svantaggi che devono ancora essere risolti, tra cui una scalabilità piuttosto elementare, un sistema di reporting/audit rigido e un prezzo piuttosto elevato nel complesso.
Druva

Un’altra variante di questa soluzione è presentata da Druva, che fornisce una soluzione di backup e ripristino di Kubernetes piuttosto semplice ma efficace, con tutte le caratteristiche di base previste: snapshot, backup e ripristino, automatizzazione e alcune funzionalità aggiuntive. Druva può anche ripristinare intere applicazioni all’interno di Kubernetes, con una grande mobilità per quanto riguarda la destinazione del ripristino.
Inoltre, Druva supporta più ruoli di amministrazione, può creare copie dei carichi di lavoro per la risoluzione dei problemi e può eseguire il backup di aree specifiche come namespace o gruppi di app. Sono disponibili anche diverse opzioni di conservazione, una protezione completa dei dati Kubernetes e il supporto per Amazon EC2 e EKS (carichi di lavoro container personalizzati).
Tipi di dati coperti da Druva:
Non ci sono informazioni sul fatto che Druva supporti i backup dell’infrastruttura di archiviazione Kubernetes. A parte questo, supporta praticamente tutto il resto: Namespaces, Pods, DaemonSets, StatefulSets, ConfigMaps e persino Persistent Volumes. Può anche coprire le applicazioni e i database associati a tali applicazioni.
Valutazioni dei clienti:
- Capterra – 4,7/5 stelle sulla base di 17 recensioni dei clienti
- TrustRadius – 9,3/10 stelle sulla base di 419 recensioni dei clienti
- G2 – 4.6/5 stelle sulla base di 416 recensioni dei clienti
Svantaggi:
- La GUI, nel suo complesso, riceve molti elogi.
- L’immutabilità del backup e la crittografia dei dati sono solo esempi di come Druva faccia sul serio quando si tratta di sicurezza dei dati.
- Il supporto ai clienti è rapido e utile.
- Protezione dei dati, snapshot, backup automatici e altre funzionalità per le app Kubernetes.
Carenze:
- La prima configurazione non è facile da eseguire da soli.
- Gli snapshot di Windows e i backup del cluster SQL sono semplicistici e poco personalizzabili.
- Velocità di ripristino lenta dal cloud.
- La scalabilità può essere limitata.
Prezzi (al momento della stesura del presente documento):
- I prezzi di Druva sono abbastanza sofisticati e offrono diversi piani tariffari a seconda del tipo di dispositivo o applicazione che viene coperto.
- Carichi di lavoro ibridi:
- “Hybrid business” – $210 al mese per Terabyte di dati dopo la deduplicazione, che offre un semplice backup aziendale con numerose funzionalità come la deduplicazione globale, il ripristino a livello di file VM, il supporto per lo storage NAS, ecc.
- “Hybrid enterprise” – 240$ al mese per Terabyte di dati dopo la deduplicazione, un’estensione dell’offerta precedente con funzioni LTR (conservazione a lungo termine), approfondimenti/raccomandazioni sullo storage, cache nel cloud, ecc.
- “Hybrid elite” – 300$ al mese per Terabyte di dati dopo la deduplicazione, aggiunge il disaster recovery nel cloud al pacchetto precedente, creando la soluzione definitiva per la gestione dei dati e il disaster recovery.
- Ci sono anche funzionalità che Druva vende separatamente, come il recupero accelerato da ransomware, il disaster recovery nel cloud (disponibile per gli utenti di Hybrid elite), la postura di sicurezza e l’osservabilità e la distribuzione per il cloud governativo degli Stati Uniti.
- Applicazioni SaaS:
- “Business” – 2,5 $ al mese per utente, il pacchetto più basilare di copertura delle applicazioni SaaS (Microsoft 365 e Google Workspace, il prezzo è calcolato per singola app), può offrire 5 regioni di archiviazione, 10 GB di archiviazione per utente, oltre alla protezione dei dati di base
- “Enterprise” – 4$ al mese per utente per la copertura di Microsoft 365 o Google Workspace con funzionalità quali gruppi e cartelle pubbliche, nonché la copertura di Salesforce.com per 3,5$ al mese per utente (include il ripristino dei metadati, backup automatici, strumenti di confronto, ecc.)
- “Elite” – 7$ al mese per utente per Microsoft 365/Google Workspace, 5,25$ per Salesforce, include la verifica della conformità GDPR, l’abilitazione dell’eDiscovery, la ricerca federata, il supporto GCC High e molte altre funzionalità.
- Alcune funzionalità possono essere acquistate anche separatamente, come ad esempio Sandbox seeding (Salesforce), governance dei dati sensibili (Google Workspace e Microsoft 365), supporto GovCloud (Microsoft 365), ecc..
- Endpoints:
- “Enterprise” – 8$ al mese per utente, può offrire supporto SSO, CloudCache, supporto DLP, protezione dei dati per origine dati e 50 GB di storage per utente con amministrazione delegata.
- “Elite” – 10 dollari al mese per utente, aggiunge funzionalità come la ricerca federata, la raccolta di dati aggiuntivi, la cancellazione difendibile, le funzionalità di distribuzione avanzate e altro ancora.
- Ci sono anche molte funzionalità che possono essere acquistate separatamente, tra cui funzionalità di distribuzione avanzate (disponibili nel livello di sottoscrizione Elite), recupero/risposta ai ransomware, governance dei dati sensibili e supporto GovCloud.
- Carichi di lavoro AWS:
- “Freemium” è un’offerta gratuita di Druva per la copertura dei carichi di lavoro AWS; può coprire fino a 20 risorse AWS contemporaneamente (non più di 2 account) e offre funzionalità come la clonazione VPC, il DR cross-region e cross-account, il ripristino a livello di file, l’integrazione delle organizzazioni AWS, l’accesso API, ecc.
- “Enterprise” – 7$ al mese per risorsa, a partire da 20 risorse, ha un limite massimo di 25 account e amplia le funzionalità della versione precedente con caratteristiche quali il blocco dei dati, la ricerca a livello di file, la possibilità di importare i backup esistenti, la possibilità di impedire l’eliminazione manuale, il supporto 24/7 con un tempo di risposta massimo di 4 ore, ecc.
- “Elite” – 9$ al mese per risorsa, non ha limitazioni sulle risorse o sugli account gestiti, aggiunge l’autoprotezione per VPC, account AWS, nonché il supporto GovCloud e un tempo di risposta al supporto inferiore a 1 ora garantito da SLA.
- Gli utenti dei piani tariffari Enterprise ed Elite possono anche acquistare la capacità di Druva di salvare i backup EC2 air-gapped in Druva Cloud a un prezzo aggiuntivo.
- È facile capire come ci si possa confondere con lo schema dei prezzi di Druva nel suo complesso. Fortunatamente, Druva stessa ha una pagina web dedicata con l’unico scopo di creare una stima personalizzata del TCO di un’azienda in pochi minuti (un calcolatore di prezzi).
Il mio parere personale su Druva:
Druva offre una soluzione di backup e ripristino cloud-native e app-aware che risolve uno dei problemi più comuni di Kubernetes: il fatto che il cluster fallito viene sempre ripristinato in uno stato vuoto dopo essere fallito per qualche motivo. Il software stesso viene fornito utilizzando un modello di Storage-as-a-Service ed è abbastanza competente nel proteggere gli ambienti Kubernetes (così come molti altri tipi di storage). Druva è in grado di eseguire il backup dei dati, il ripristino dei dati, l’automazione di una serie di attività, la creazione di backup di applicazioni specifiche e il backup di aree specifiche (gruppi di app o namespace, ad esempio). La soluzione supporta anche EKS e Amazon EC2, il che la rende un’eccezione in questo elenco e nel mercato generale. Druva presenta alcuni problemi, tra cui un processo di configurazione piuttosto complicato per la prima volta e prestazioni piuttosto lente quando si tratta di recuperare i backup dal cloud storage, ma nel complesso la soluzione è abbastanza capace, soprattutto per gli ambienti Kubernetes.
Zerto

Anche Zerto è una buona scelta se cercate una piattaforma di gestione dei backup multifunzionale con supporto nativo per Kubernetes. Offre tutto ciò che si può desiderare da una moderna soluzione di backup e ripristino di Kubernetes: CDP (protezione continua dei dati), replica dei dati tramite snapshot e un vendor lock-in minimo grazie al supporto di Zerto per tutte le piattaforme Kubernetes in ambito aziendale.
Zerto offre inoltre la protezione dei dati come una delle strategie principali fin dal primo giorno, offrendo alle applicazioni la possibilità di essere generate con protezione fin dall’inizio. Zerto dispone inoltre di numerose funzionalità di automazione, è in grado di fornire approfondimenti estesi e può lavorare con diversi storage cloud contemporaneamente.
Tipi di dati coperti da Zerto:
La posizione di Zerto in termini di copertura dei dati Kubernetes è semplice: non può lavorare con le applicazioni o le infrastrutture di storage, ma tutto il resto può essere sottoposto a backup senza alcun problema, che si tratti di implementazioni, namespace, servizi, pod, ecc.
Valutazioni dei clienti:
- Capterra – 4,8/5 stelle sulla base di 25 recensioni di clienti
- TrustRadius – 8,6/10 stelle sulla base di 113 recensioni dei clienti
- G2 – 4,6/5 stelle sulla base di 73 recensioni dei clienti
Svantaggi:
- Semplicità di gestione per le attività di disaster recovery
- Facilità di integrazione con le infrastrutture esistenti, sia on-premise che nel cloud
- Capacità di migrazione del carico di lavoro e molte altre funzionalità
- Anche le funzionalità Kubernetes di Zerto sono molto vaste e varie, tra cui la protezione continua dei dati, la replica degli snapshot e molto altro ancora.
Carenze:
- Può essere distribuito solo su sistemi operativi Windows
- Le funzionalità di reporting sono un po’ rigide.
- Può essere piuttosto costoso per le imprese e le aziende più grandi
Prezzi (al momento della stesura del presente documento):
- Il sito ufficiale di Zerto offre tre diverse categorie di licenze: Zerto for VMs, Zerto for SaaS e Zerto for Kubernetes.
- La licenza di Zerto per Kubernetes, nello specifico, può essere acquistata in due forme diverse
- “Zerto Data Protection” è un software di protezione dei dati che offre funzionalità di backup e ripristino continuo per l’intero ciclo di vita dell’implementazione delle applicazioni; include conservazione a lungo termine, clonazione, replica locale, backup orchestrati e altro ancora.
- “Enterprise Cloud Edition” è una versione basata su cloud dell’offerta precedente che offre anch’essa backup e ripristino continui durante l’intero ciclo di vita dello sviluppo dell’applicazione, ampliando il set di funzionalità esistenti con funzioni quali il disaster recovery orchestrato e la replica remota sempre attiva.
- Non sono disponibili informazioni ufficiali sui prezzi della soluzione di Zerto, che può essere acquisita solo tramite un preventivo personalizzato o acquistata attraverso uno dei partner commerciali di Zerto.
La mia opinione personale su Zerto:
Zerto come soluzione di backup è una buona opzione per più casi d’uso contemporaneamente: è una piattaforma completa che supporta una varietà di tipi di storage diversi. Zerto può lavorare con Azure, AWS e Google Cloud come provider di cloud storage; supporta la copertura delle macchine virtuali, dei container e molti altri casi d’uso. La protezione dei dati è una delle sue caratteristiche più importanti e complete, e ci sono molte opzioni per gli ambienti Kubernetes in particolare, sia che si tratti di un vendor lock-in minimo, di funzionalità di replica dei dati, di supporto CDP e altro ancora. Alcune funzionalità di Zerto sono applicabili anche a tutti i diversi tipi di storage, come l’analisi dei dati con approfondimenti, numerose opzioni di automazione, ecc.
Longhorn

Longhorn è probabilmente la soluzione meno conosciuta tra quelle discusse in questo blog. La sua comunità è relativamente piccola per una soluzione open-source e non consente di eseguire backup Kubernetes completi con metadati e risorse per il ripristino consapevole delle app. Tuttavia, c’è una caratteristica unica che spicca, ed è chiamata DR Volume. Il DR Volume può essere impostato sia come sorgente che come destinazione, rendendo il volume attivo in un nuovo cluster basato sugli ultimi dati di backup.
Le capacità di Longhorn di lavorare con diversi tipi di piattaforme container e di consentire diversi metodi di backup sono ciò che lo differenzia dal resto, e c’è già la possibilità di supportare Kubernetes Engine, distribuzioni Docker e distribuzioni K3. I contenitori Docker, ad esempio, devono creare un tarball che può fungere da backup per Longhorn.
Tipi di dati coperti da Longhorn:
Per essere una soluzione gratuita, Longhorn è in grado di offrire ai suoi utenti un pacchetto di copertura dei tipi di dati che comprende backup per Deployments, StatefulSets, Services, Secrets, Pods e altro ancora. Non è in grado di eseguire il backup di Namespace, Applicazioni o Infrastruttura di archiviazione.
Valutazione dei clienti:
- Capterra – 4,3/5 stelle sulla base di 6 recensioni di clienti
- G2 – 4,8/5 stelle in base a 3 recensioni dei clienti
Caratteristiche principali:
- Soluzione indipendente dall’infrastruttura
- Facile processo di distribuzione
- Dashboard comodo e utile
- Semplice personalizzazione dei criteri di backup e disaster recovery
Prezzi (al momento della stesura del presente documento):
- Longhorn è una soluzione di backup Kubernetes gratuita e open-source, originariamente sviluppata da Rancher Labs, ma successivamente donata alla CNCF (Cloud Native Computing Foundation) e ora considerata un progetto sandbox autonomo.
- Rancher stesso ha un livello di prezzo premium separato, chiamato Rancher Prime, che offre una serie di caratteristiche per espandere e migliorare le funzionalità di Rancher originale, ma il suo prezzo non è pubblicamente disponibile sul sito ufficiale.
La mia opinione personale su Longhorn:
Come alcuni esempi precedenti, Longhorn non offre una copertura completa di Kubernetes, il che significa che non ci saranno backup consapevoli delle app. Allo stesso tempo, è un’opzione interessante per le piccole imprese e le aziende con un budget limitato, considerando che Longhorn è gratuito, supporta diverse varianti di container e anche diversi metodi di backup. Longhorn può anche offrire una sua caratteristica insolita, chiamata DR Volume: un volume che può essere impostato sia come destinazione che come sorgente, rendendolo immediatamente attivo nel cluster appena creato utilizzando i dati di backup esistenti. È anche relativamente semplice per una soluzione gratuita e open-source, anche se ci si deve aspettare un certo grado di curva di apprendimento.
Velero.io

Velero è una soluzione open-source per il backup e il ripristino di Kubernetes con funzionalità di migrazione. Supporta snapshot per i volumi persistenti e gli stati del cluster, rendendo possibile sia la migrazione che il ripristino in ambienti diversi. Si tratta di una soluzione ben nota nell’ambito del backup di Kubernetes, che offre funzionalità affidabili di disaster recovery per i cluster Kubernetes insieme alla migrazione dei cluster, alla conservazione a lungo termine per scopi di conformità e altro ancora.
Caratteristiche principali:
- Migrazione del cluster con diverse configurazioni.
- Protezione a livello di cluster e granularità nei processi di backup.
- Capacità estese di disaster recovery per scopi di continuità aziendale.
- Schedulazione del backup con numerose opzioni tra cui scegliere.
- Integrazione con l’API per creare snapshot di volumi persistenti per grandi insiemi di dati.
- Supporto per diversi fornitori di cloud storage, tra cui Azure Blob, Google Cloud, AWS S3, ecc.
Prezzi (al momento della stesura del presente documento):
- Velero.io è uno strumento completamente gratuito e open-source senza alcun prezzo legato al software.
La mia opinione personale su Velero.io:
Velero è un’opzione interessante per le attività di backup e ripristino in ambienti Kubernetes, considerando che è gratuito e può offrire un’ampia granularità nelle sue capacità. Supporta diversi fornitori di storage, può essere integrato con l’API della piattaforma per snapshot persistenti e, in generale, è una soluzione sorprendentemente conveniente per molte situazioni. Non è particolarmente utilizzabile nella maggior parte dei casi d’uso di livello aziendale, a causa della portata delle operazioni necessarie, e la mancanza delle funzioni di sicurezza più diffuse, come la crittografia, la renderebbe difficile da utilizzare per le aziende che trattano informazioni sensibili, ma nel complesso la soluzione vale comunque la pena di essere esaminata, come minimo.
Quale lista di controllo dovrebbero seguire i team per garantire la preparazione al backup di Kubernetes?
Avere una strategia di ripristino sulla carta non equivale ad averla pronta per essere messa in pratica. Lasciate che questa lista di controllo vi aiuti a garantire che le decisioni e le configurazioni definite in questo documento vengano implementate in modo concreto e verificabile.
Ha effettuato l’inventario dei carichi di lavoro critici e degli ambiti dei dati?
Prima di ogni altra cosa, è necessario sapere esattamente cosa si sta proteggendo. Senza un inventario chiaro, le politiche di backup tendono ad essere troppo generiche o piene di lacune.
- Tutti i namespace e i carichi di lavoro sono documentati e classificati in base alla criticità
- I volumi persistenti sono categorizzati in base alla priorità di ripristino
- Le risorse personalizzate e i CRD associati a ciascun carico di lavoro sono identificati
- Le applicazioni con stato sono distinte da quelle senza stato nel Suo inventario
- La proprietà dei dati è assegnata per ogni carico di lavoro critico
Le politiche RPO, RTO e di conservazione sono documentate e approvate?
I requisiti di ripristino che non sono stati formalmente concordati tendono a cambiare sotto pressione. Questi dovrebbero essere definiti prima di un incidente, non negoziati durante lo stesso.
- Gli obiettivi RPO e RTO sono definiti per ogni livello di carico di lavoro
- La frequenza di backup per etcd, PV e dati delle applicazioni riflette tali obiettivi
- Le finestre di conservazione sono documentate e approvate da chiunque sia responsabile dello SLA di ripristino
- Sono in vigore politiche di ciclo di vita e di tiering per i dati di backup più vecchi
- Le politiche vengono riviste e riapprovate dopo ogni cambiamento significativo dell’infrastruttura
Sono in atto monitoraggio, avvisi e controllo degli accessi per i backup?
Un processo di backup che viene eseguito in modo silenzioso e fallisce in modo silenzioso offre una falsa sicurezza. I controlli operativi devono essere robusti quanto il processo di backup stesso.
- I processi di backup sono monitorati e gli errori attivano avvisi alle persone giuste
- L’accesso al backup e al ripristino è separato nella configurazione RBAC
- Le operazioni di ripristino richiedono un’autorizzazione esplicita per gli ambienti di produzione
- La crittografia viene applicata in modo coerente lungo l’intera pipeline di backup
- La gestione delle chiavi è gestita indipendentemente dallo storage di backup
Dispone di runbook collaudati per gli scenari di ripristino più comuni?
La documentazione che non è stata testata è un’ipotesi, non un runbook. I test regolari sono ciò che trasforma un piano di ripristino in una capacità di ripristino.
- Esistono runbook almeno per gli scenari di ripristino più comuni: namespace singolo, cluster completo e ripristino di etcd
- Le procedure di ripristino sono state testate end-to-end in un ambiente non di produzione
- Il tempo di ripristino per ciascuno scenario è stato misurato rispetto al vostro RTO
- I runbook sono sottoposti a controllo di versione e revisionati dopo ogni test o incidente
- La responsabilità di ciascun runbook è assegnata e aggiornata
La soluzione di backup K8s di Bacula Enterprise
La natura stessa degli ambienti Kubernetes li rende al tempo stesso molto dinamici e potenzialmente complessi. Il backup di un cluster Kubernetes non dovrebbe aggiungere ulteriore complessità. E, naturalmente, è solitamente importante – se non fondamentale – che gli amministratori di sistema e il resto del personale IT abbiano un controllo centralizzato sull’intero sistema di backup e ripristino dell’intera organizzazione, compresi eventuali ambienti Kubernetes. In questo modo, fattori quali conformità, gestibilità, velocità, efficienza e continuità operativa diventano molto più realistici. Allo stesso tempo, l’approccio agile dei team di sviluppo non dovrebbe essere in alcun modo compromesso.
Bacula Enterprise è unica in questo ambito perché è una soluzione aziendale completa per ambienti IT integrali (non solo Kubernetes) che offre anche backup e ripristino di Kubernetes integrati in modo nativo, inclusi cluster multipli, indipendentemente dal fatto che le applicazioni o i dati risiedano all’esterno o all’interno di un cluster specifico. Bacula apporta ulteriori vantaggi, in quanto è particolarmente sicura, protetta e stabile. Queste qualità diventano fondamentali nel contesto di organizzazioni che devono garantire i massimi livelli possibili di sicurezza.
Ripristino del cluster
Il reparto operativo di ogni azienda riconosce la necessità di disporre di una strategia di ripristino adeguata quando si tratta di ripristino del cluster, aggiornamenti e altre situazioni. Un cluster che si trova in uno stato irrecuperabile può essere riportato allo stato stabile con Bacula se sia i file di configurazione che i volumi persistenti del cluster sono stati correttamente sottoposti a backup in precedenza.
Un altro modo per mostrare i metodi di lavoro di Bacula è l’immagine seguente:
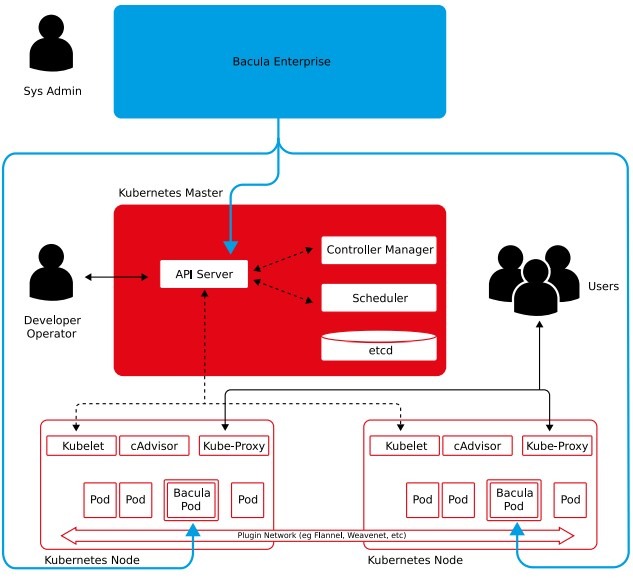
Uno dei principali vantaggi del modulo Kubernetes di Bacula è la possibilità di eseguire il backup di varie risorse Kubernetes, tra cui:
- Pods;
- Servizi;
- Deployments;
- Volumi persistenti.
Caratteristiche del modulo Kubernetes di Bacula Enterprise
Il modo in cui funziona questo modulo è che la soluzione stessa non fa parte dell’ambiente Kubernetes, ma accede ai dati rilevanti all’interno del cluster tramite pod Bacula collegati a singoli nodi Kubernetes in un cluster. La distribuzione di questi pod è automatica e funziona in base alle necessità.
Tra le altre funzionalità offerte dal modulo di backup K8s figurano anche le seguenti:
- Backup e ripristino di Kubernetes per volumi persistenti;
- Ripristino di una singola risorsa di configurazione Kubernetes;
- La possibilità di ripristinare file di configurazione e/o dati da volumi persistenti alla directory locale;
- La possibilità di eseguire il backup della configurazione delle risorse dei cluster Kubernetes.
Vale anche la pena di notare che Bacula supporta facilmente più piattaforme di cloud storage contemporaneamente, tra cui AWS, Google, Glacier, Oracle Cloud, Azure e molte altre, a livello di integrazione nativa. Le funzionalità di cloud ibrido sono quindi integrate, compresa la gestione avanzata del cloud e le funzionalità di caching automatizzato del cloud, consentendo una facile integrazione dei servizi di cloud pubblico o privato per supportare varie attività.
La flessibilità delle soluzioni è particolarmente importante al giorno d’oggi, quando molte aziende e imprese stanno diventando sempre più complesse in termini di famiglie di hypervisor e container diversi. Allo stesso tempo, questo aumenta in modo significativo la richiesta di flessibilità dei vendor per tutti i vendor di database. Le capacità di Bacula in questo senso sono sostanzialmente elevate, in quanto combina la sua ampia lista di compatibilità con varie tecnologie per raggiungere standard di flessibilità particolarmente elevati senza vincolarsi a un unico fornitore.
La complessità sempre crescente dei diversi aspetti del lavoro di un’organizzazione è in continuo aumento, e spesso è più facile ed economico utilizzare un’unica soluzione per l’intero ambiente IT, e non diverse soluzioni contemporaneamente. Bacula è stato progettato per fare esattamente questo, ed è anche in grado di fornire sia un’interfaccia tradizionale basata sul web per le vostre esigenze di configurazione, sia il classico controllo a riga di comando. Queste due interfacce possono essere utilizzate anche contemporaneamente.
Il plugin di backup Kubernetes di Bacula consente due tipi principali di destinazione per le operazioni di ripristino:
- Ripristino in una directory locale;
- Ripristino in un cluster…
I backup regolari e/o automatizzati sono altamente raccomandati per garantire il miglior ambiente di backup e ripristino possibile per i container. Anche la verifica dei backup di tanto in tanto dovrebbe essere obbligatoria per l’amministratore di sistema. Nella prossima immagine, si vedrà una parte del processo di ripristino, ovvero la parte di selezione del ripristino, in cui si può scegliere quali file e/o directory si desidera ripristinare:
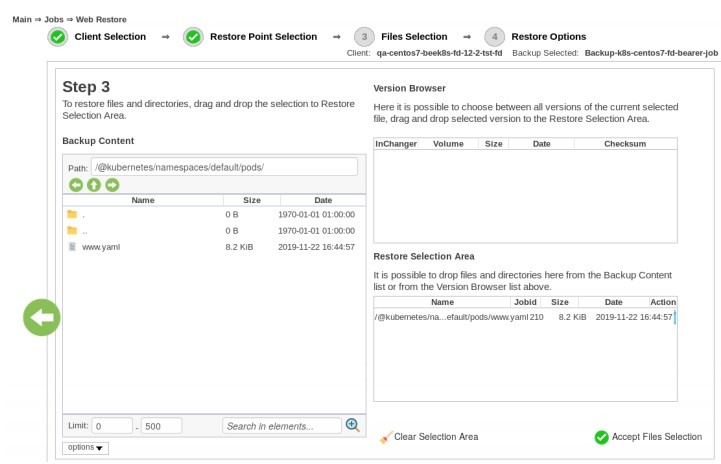
Un’altra parte del processo di ripristino che si incontra è la pagina delle opzioni di ripristino avanzate, che si presenta così:
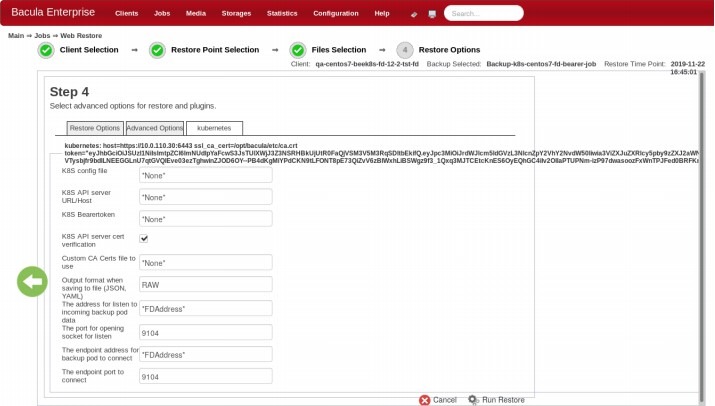
Qui è possibile specificare diverse opzioni, come il formato di output, il percorso del file di configurazione KBS, la porta dell’endpoint e altro ancora.
È anche facile controllare l’intero processo di ripristino al termine della personalizzazione, grazie alla pagina di registro del lavoro di ripristino che riporta ogni azione una per una:
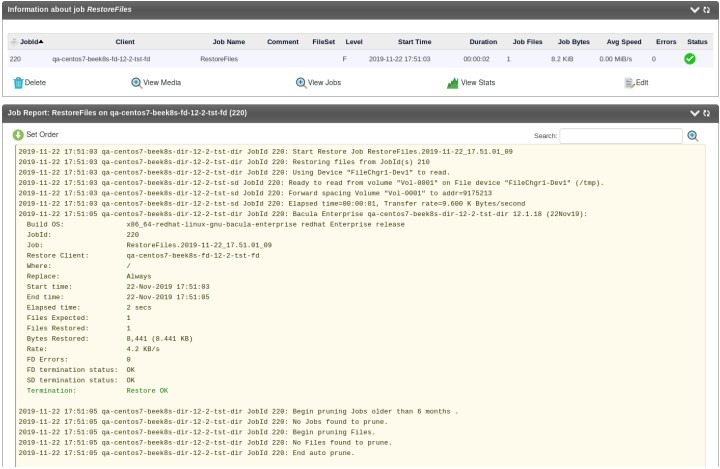
Un’altra importante funzionalità del modulo Kubernetes è la funzione Plugin Listing, che offre molte informazioni utili sulle risorse Kubernetes disponibili, compresi gli spazi dei nomi, i volumi persistenti e così via. Per farlo, il modulo utilizza uno speciale comando .ls con uno specifico parametro plugin=<plugin>.
Il modulo Kubernetes di Bacula offre una serie di funzionalità, alcune delle quali sono:
- Ridistribuzione rapida ed efficiente delle risorse del cluster;
- Salvataggio dello stato del cluster Kubernetes;
- Salvataggio delle configurazioni da utilizzare in altre operazioni;
- Mantenimento delle configurazioni modificate nel modo più sicuro possibile e ripristino dello stesso identico stato precedente.
Sebbene ciò accada spesso, si raccomanda vivamente di evitare di pagare il proprio fornitore in base al volume dei dati. Non ha alcun senso essere tenuti in ostaggio, ora o in futuro, da un fornitore pronto ad approfittare della vostra organizzazione in questo modo. Esamini invece attentamente i modelli di licenza di Bacula Systems, che proteggono i clienti dall’esposizione a costi legati alla crescita dei dati, rendendo al contempo molto più semplice per i reparti acquisti dei clienti prevedere i costi futuri. Questo approccio più ragionevole da parte di Bacula deriva dalle sue origini open source e potrebbe risultare interessante per i team che operano intensamente in ambienti DevOps.
Conclusione
In fin dei conti, gli utenti di Kubernetes hanno a disposizione molte scelte diverse quando si tratta di software di backup e ripristino. Alcuni di essi sono stati creati solo per gestire i dati Kubernetes, mentre altre soluzioni aggiungono Kubernetes al loro elenco di funzionalità esistenti.
Le piccole imprese alla ricerca di una soluzione in grado di eseguire esclusivamente backup di Kubernetes potrebbero preferire Longhorn o OpenEBS rispetto agli altri esempi presenti nel nostro elenco. In alternativa, le aziende più grandi con numerosi tipi di storage diversi nella propria infrastruttura potrebbero aver bisogno di una soluzione di backup completa e altamente sicura che copra l’intero sistema IT aziendale senza frammentazione e che sia in grado di visualizzare il backup e il ripristino complessivi da un’interfaccia di gestione centralizzata – qualcosa per cui sono state progettate soluzioni come Bacula Enterprise. La scelta finale dipenderà in gran parte dalle esigenze e dalle priorità del singolo cliente, tra cui le dimensioni dell’azienda, le funzionalità necessarie e così via.
Perché potete fidarvi di noi
Bacula Systems punta tutto sull’accuratezza e sulla coerenza: i nostri materiali cercano sempre di fornire il punto di vista più obiettivo su tecnologie, prodotti e aziende diverse. Nelle nostre recensioni utilizziamo molti metodi diversi, come le informazioni sui prodotti e gli approfondimenti degli esperti, per generare il contenuto più informativo possibile.
I nostri materiali offrono tutti i tipi di fattori su ogni singola soluzione presentata, che si tratti di caratteristiche, prezzi, recensioni dei clienti, ecc. La strategia di prodotto di Bacula è supervisionata e controllata da Jorge Gea, CTO di Bacula Systems, e da Rob Morrison, Direttore Marketing di Bacula Systems.
Prima di entrare in Bacula Systems, Jorge è stato per molti anni CTO di Whitebearsolutions SL, dove ha guidato l’area Backup e Storage e la soluzione WBSAirback. Ora Jorge fornisce leadership e guida le tendenze tecnologiche attuali, le competenze tecniche, i processi, le metodologie e gli strumenti per lo sviluppo rapido ed entusiasmante dei prodotti Bacula. Responsabile della roadmap dei prodotti, Jorge è attivamente coinvolto nell’architettura, nell’ingegneria e nel processo di sviluppo dei componenti Bacula. Jorge ha conseguito una laurea in ingegneria informatica presso l’Università di Alicante, un dottorato in tecnologie di calcolo e un master in amministrazione di rete.
Rob ha iniziato la sua carriera nel marketing IT con Silicon Graphics in Svizzera, ricoprendo per quasi 10 anni diversi ruoli di gestione del marketing. Nei 10 anni successivi, Rob ha ricoperto anche diverse posizioni di marketing management in JBoss, Red Hat e Pentaho, assicurando la crescita della quota di mercato di queste note aziende. Si è laureato all’Università di Plymouth e ha conseguito una laurea con lode in Digital Media and Communications.
Bacula Systems punta all’accuratezza e alla coerenza: le nostre informazioni cercano sempre di fornire il punto di vista più obiettivo su tecnologie, prodotti e aziende diverse. Nelle nostre recensioni utilizziamo diversi metodi, come le informazioni sui prodotti e gli approfondimenti degli esperti, per generare il contenuto più informativo possibile.
I nostri materiali offrono tutti i tipi di fattori su ogni singola soluzione presentata, che si tratti di caratteristiche, prezzi, recensioni dei clienti, ecc. La strategia di prodotto di Bacula è supervisionata e controllata da Jorge Gea, CTO di Bacula Systems, e da Rob Morrison, direttore marketing di Bacula Systems.
Prima di entrare in Bacula Systems, Jorge è stato per molti anni CTO di Whitebearsolutions SL, dove ha guidato l’area Backup e Storage e la soluzione WBSAirback. Ora Jorge fornisce leadership e guida le tendenze tecnologiche attuali, le competenze tecniche, i processi, le metodologie e gli strumenti per lo sviluppo rapido ed entusiasmante dei prodotti Bacula. Responsabile della roadmap dei prodotti, Jorge partecipa attivamente all’architettura, all’ingegneria e al processo di sviluppo dei componenti Bacula. Jorge ha conseguito una laurea in ingegneria informatica presso l’Università di Alicante, un dottorato in tecnologie di calcolo e un master in amministrazione di rete.
Rob ha iniziato la sua carriera nel marketing IT con Silicon Graphics in Svizzera, ricoprendo per quasi 10 anni diversi ruoli di gestione del marketing. Nei 10 anni successivi, Rob ha ricoperto anche diverse posizioni di marketing management in JBoss, Red Hat e Pentaho, assicurando la crescita della quota di mercato di queste note aziende. Si è laureato all’Università di Plymouth e ha conseguito una laurea con lode in Digital Media and Communications.
Domande frequenti
Qual è lo scopo principale dei backup di Kubernetes?
Lo scopo di un backup di Kubernetes è simile a quello della maggior parte dei backup: creare copie sicure delle informazioni da recuperare in caso di disastro, accidentale o intenzionale. Un pacchetto di backup adeguato può essere la soluzione a guasti del sistema, perdita di dati, corruzione dei dati, furto di dati e molte altre situazioni in cui l’esistenza dell’intera azienda dipende dalla possibilità di ripristinare o meno i dati.
Quanto sono complessi i backup di Kubernetes rispetto ai tradizionali backup di macchine virtuali?
La natura containerizzata dei carichi di lavoro Kubernetes è il motivo principale per cui questi backup sono considerati più impegnativi e sofisticati dei normali backup delle macchine virtuali. Ogni applicazione Kubernetes comprende diversi microservizi, con la necessità di eseguire il backup sia dello stato del cluster sia dello stato dell’applicazione per il corretto funzionamento, rendendo il ripristino corretto senza perdere la continuità molto impegnativo. Inoltre, la natura in continua evoluzione dei cluster Kubernetes aggiunge un ulteriore livello di difficoltà, rendendo i processi di backup e ripristino ancora più complessi.
Quale software di backup è la migliore opzione possibile per i backup di Kubernetes?
È difficile affermare che una singola soluzione rappresenti l’opzione migliore in assoluto per un caso d’uso specifico, considerando che ogni azienda presenta una serie di circostanze e requisiti propri. La maggior parte delle aziende dispone inoltre di un budget limitato per quanto riguarda il software di backup, il che significa che la gamma completa di funzionalità avrebbe una priorità inferiore rispetto al prezzo della soluzione. In definitiva, la soluzione più utile in questo elenco sarà quella adatta al maggior numero e alla più ampia gamma di potenziali casi d’uso: in tale situazione, Bacula Enterprise risulterebbe il vincitore indiscusso di questa lista.
Cosa può offrire Bacula per gli ambienti Kubernetes multi-cloud?
Bacula offre la flessibilità del ripristino dei dati e del disaster recovery consentendo l’archiviazione dei backup in diversi ambienti di storage cloud. È inoltre possibile ripristinare le informazioni su qualsiasi cluster compatibile invece che sul cluster da cui sono stati copiati i dati. In questo modo, la resilienza e la ridondanza di un ambiente Kubernetes aumentano drasticamente, soprattutto in caso di interruzioni specifiche del cloud. Bacula consente inoltre agli utenti di ripristinare sia i namespace che gli interi cluster in diversi ambienti di cloud storage, garantendo un’ampia continuità senza vincolare gli utenti allo stesso cloud storage. Un aspetto critico che spesso viene un po’ trascurato dagli architetti Kubernetes è la necessità della loro organizzazione di ottenere i massimi livelli di sicurezza possibili. Rispetto a praticamente tutti gli altri fornitori di backup, Bacula ha livelli di sicurezza più elevati incorporati nella sua architettura, nelle sue metodologie, nei suoi processi e nelle sue singole funzionalità.
Quali tipi di ambienti supporta Bacula?
Bacula non solo è in grado di funzionare con cluster Kubernetes on-premises e cloud-based, ma supporta anche ambienti ibridi, rendendo possibile mescolare e combinare entrambe le opzioni di distribuzione per ottenere il massimo livello possibile di flessibilità, efficienza e sicurezza in ambienti diversi.

