Enterprise-grade AWS S3 backup software solution with minimal restore costs.
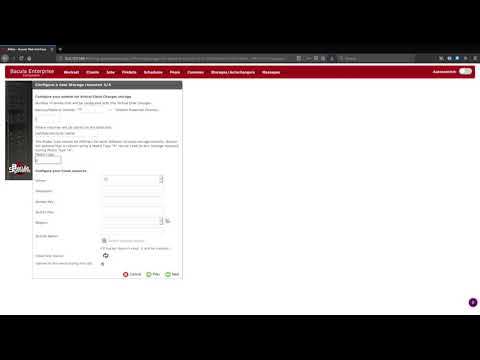
Bacula delivers natively integrated AWS S3 backup solution for the enterprise cloud-based backup and recovery. It delivers native integration with public and private clouds via the Amazon S3 interface, with transparent support for S3-IA. AWS S3 backup is available for Linux, Windows and other platforms. But there’s something else your company needs to know about Amazon S3 backup with Bacula Enterprise: the ability to bring significant cloud cost reduction for AWS backup solutions.