Contents
- AWS Backup zum Erstellen von Backups verwenden
- AWS Backup und seine Interaktion mit anderen AWS-basierten Services
- AWS-Sicherung und EC2
- Update 2022
- Grundlegende Operationen mit der Amazon S3-Konsole
- Andere Methoden zur Sicherung Ihres Amazon S3-Buckets
- Versionierung und Bucket-Replikation
- Unternehmenstaugliche AWS S3-Sicherungslösungen mit minimalen Wiederherstellungskosten.
- AWS S3-Sicherung mit Bacula Enterprise
- Hinzufügen eines neuen S3-Speichers in Bacula Enterprise
- Konfigurieren der AWS S3-Speicher-Sicherung mit Bacula Enterprise
- Abschluss der Einrichtung des S3-Speichers
- Speichern Ihrer neuen S3-Sicherungseinstellungen
- Testen der AWS-Sicherungseinstellungen
- Fazit
AWS Backup zum Erstellen von Backups verwenden
Die Sicherung Ihrer Informationen – Daten – ist vielleicht der wichtigste Teil des Schutzes vor Schaden und der Gewährleistung der Compliance. Selbst die robustesten Server und Speicher sind anfällig für Bugs, menschliche Fehler und andere mögliche Gründe für eine Katastrophe. Die Erstellung und Verwaltung aller Ihrer Sicherungsabläufe kann jedoch eine entmutigende Aufgabe sein. Daher gibt es eine Reihe von Methoden, die Sie verwenden können, um den gesamten Prozess der Erstellung von Sicherungskopien unter Verwendung von AWS S3 zu vereinfachen.
Eine beliebte Wahl ist Amazons eigene Backup-Lösung – AWS Backup. Mit AWS Backup können Sie Ihre Backups sowohl in der AWS-Cloud als auch vor Ort verwalten und eine Vielzahl anderer Amazon-Anwendungen unterstützen.
Der Backup-Prozess selbst ist recht einfach. Ein Benutzer muss eine Sicherungsrichtlinie – seinen Sicherungsplan – erstellen, in der er eine Reihe von Parametern festlegt, wie z. B. die Sicherungshäufigkeit, den Zeitraum, in dem diese Sicherungen aufbewahrt werden sollen, usw. Sobald die Richtlinie eingerichtet ist, sollte AWS Backup automatisch mit der Sicherung Ihrer Daten beginnen. Danach können Sie die Konsole von AWS Backup verwenden, um Ihre gesicherten Ressourcen anzuzeigen, eine bestimmte Sicherung wiederherzustellen oder einfach nur Ihre Sicherungs- und Wiederherstellungsaktivitäten zu überwachen.
AWS Backup und seine Interaktion mit anderen AWS-basierten Services
Es gibt viele verschiedene AWS-Services, die verschiedene nützliche Funktionen bieten und mit dem AWS Backup-Service zusammenarbeiten können. Zu diesen Services gehören zum Beispiel, aber nicht ausschließlich:
- Amazon EBS (Elastic Block Store);
- Amazon RDS (Relationaler Datenbankdienst);
- Amazon DynamoDB-Sicherungen;
- AWS-Speicher-Gateway-Snapshots, usw.
Natürlich müssen Sie den spezifischen Service, den Sie in Ihrem Sicherungsprozess verwenden möchten, aktivieren, bevor Sie ihn überhaupt verwenden. Wenn Sie versuchen, die Sicherung mit bestimmten Ressourcen eines Dienstes zu initiieren oder zu erstellen, den Sie noch nicht aktiviert haben, erhalten Sie stattdessen wahrscheinlich eine Fehlermeldung und können den Erstellungsprozess nicht durchführen.
Um die Liste der Dienste zu finden, die Sie ein- oder ausschalten können, müssen Sie eine Reihe von Schritten durchführen:
- Öffnen Sie die AWS-Backup-Konsole.
- Gehen Sie in das Menü „Einstellungen“.
- Gehen Sie zur Seite „Service opt-in“ und klicken Sie auf „Configure resources“.
Dadurch gelangen Sie auf die Seite mit einer Reihe von Servicenamen und Schaltflächen, mit denen Sie die einzelnen Services einfach ein- oder ausschalten können. Wenn Sie auf „Bestätigen“ klicken, nachdem Sie die Änderungen vorgenommen haben, werden Ihre Vorgänge gespeichert.
AWS-Sicherung und EC2
AWS-Backup ist in der Lage, viele der vorhandenen AWS-Service-Funktionen in den Prozess der Erstellung einer Sicherung zu implementieren. Ein gutes Beispiel dafür ist die EBS-Snapshot-Funktion, mit der Sicherungen gemäß dem von Ihnen erstellten Sicherungsplan erstellt werden können. Die Erstellung von EBS-Snapshots hingegen kann über die EC2-API (Elastic Compute Cloud) erfolgen. Auf diese Weise können Sie Ihre Sicherungen von einer zentralen AWS-Sicherungskonsole aus verwalten, sie überwachen, verschiedene Vorgänge planen usw.
AWS-Backup kann Sicherungsaufträge für ganze EC2-Instanzen ausführen, so dass Sie weniger mit der Speicherebene selbst interagieren müssen. Die Funktionsweise ist ebenfalls recht einfach: AWS Backup erstellt einen Snapshot des Root-EBS-Speicher-Volumes sowie der zugehörigen Volumes und Startkonfigurationen. Alle Daten werden in einem speziellen Image-Format gespeichert, dem Volume-Backed AMI (Amazon Machine Image).
EC2 AMI-Sicherungsdateien können während des Sicherungsvorgangs verschlüsselt werden, so wie AWS Backup dies bei EBS-Snapshots tut. Sie können entweder den Standard-KMS-Schlüssel verwenden, wenn Sie keinen haben, oder Sie können Ihren eigenen Schlüssel verwenden, um ihn auf die Sicherung anzuwenden.
Dieser Prozess ist weitaus besser und einfacher anzupassen als die integrierte Methode von AWS EC2 zur Sicherung und Wiederherstellung von Daten. Beispielsweise erstellt der Sicherungsprozess für EC2 ursprünglich einen Snapshot des Volumes, der wenig oder gar keine Konfiguration erfordert, und das war’s. Dies kann in der Amazon EC2-Konsole unter „Snapshots > Create Snapshot > *Wählen Sie das betreffende Volume* > Create“ erfolgen.
Der Wiederherstellungsprozess für EC2-Ressourcen kann auf verschiedene Arten durchgeführt werden: AWS-Backup-Konsole, Befehlszeile oder nur die API. Im Vergleich zu den beiden anderen Methoden hat die Backup-Konsole viele Funktionseinschränkungen für den Wiederherstellungsprozess und kann verschiedene Parameter wie ipv6-Adressen, einige spezifische IDs usw. nicht wiederherstellen. Die beiden anderen Methoden hingegen sind in der Lage, eine vollständige Wiederherstellung auf die eine oder andere Weise durchzuführen.
Es ist auch möglich, EBS-Volumes aus einem Snapshot wiederherzustellen. Dieser Prozess ist jedoch etwas komplizierter und besteht aus zwei Teilen – der Wiederherstellung eines Volumes aus einem Snapshot und dem Anhängen eines neuen Volumes an eine Instanz.
Die Wiederherstellung eines Volumes ist recht einfach und kann auf der EC2-Seite unter ELASTIC BLOCK STORE, Snapshots > *Wählen Sie das betreffende Snapshot* > Volume erstellen durchgeführt werden. Das Anhängen eines neu wiederhergestellten Volumes an eine Instanz ist dagegen ein etwas anderer Prozess, den Sie unter Volumes > Aktionen > Volume anhängen > *Wählen Sie das Volumen nach Name oder ID* > Anhängen durchführen können. Es wird auch empfohlen, den vorgeschlagenen Gerätenamen während dieses Vorgangs beizubehalten.
Update 2022
Mit Beginn des Jahres 2022 hat AWS Backup einen weiteren seiner Dienste hinzugefügt, mit dem es arbeiten kann – Amazon Simple Storage Service (S3). Die moderne Welt hat viele Anforderungen und Möglichkeiten, wenn es um Speicheroptionen geht, und es ist ganz normal, sich auf mehrere verschiedene Speicherorte oder Dienste gleichzeitig zu verlassen.
Diese Art der Integration ermöglicht es AWS Backup, S3-Daten zu schützen und zu verwalten, so wie es auch bei anderen Amazon-Diensten der Fall ist. Die Integration zwischen AWS Backup und Amazon S3 bietet drei wesentliche Vorteile:
- Bessere Compliance mit den integrierten Dashboards;
- Einfacherer Wiederherstellungsprozess mit Point-in-Time-Wiederherstellungsprozessen;
- Komfortableres, zentralisiertes Backup-Management, das die Kontrolle des Backup-Lebenszyklus deutlich vereinfacht.
Zum Zeitpunkt der Erstellung dieses Artikels handelt es sich bei AWS Backup for S3 um eine Vorschau, aber es kann bereits grundlegende Sicherungsfunktionen bieten – punktuelle Sicherungen, regelmäßige Sicherungen, Wiederherstellungen usw. Außerdem kann es mithilfe von AWS Organizations vollständig automatisiert werden.
Grundlegende Operationen mit der Amazon S3-Konsole
Amazons eigenes S3-Toolkit ermöglicht einige grundlegende Operationen, wenn es darum geht, eine bestimmte Datei aus dem Bucket abzurufen oder zu speichern. Es ist möglich, vier verschiedene Operationen aufzuzeigen, die nur mit der Amazon S3-Backup-Software durchgeführt werden können – aber wir müssen zuerst zur Amazon S3-Konsole gehen.
Dazu müssen Sie die AWS-Services-Seite über diesen Link aufrufen und Ihre Anmeldeinformationen eingeben, um auf den ersten Bildschirm des AWS-Services-Toolkits zuzugreifen. Danach können Sie die S3-Konsole finden, indem Sie entweder das Menü „Services“ aufrufen und dort S3 finden oder indem Sie „S3“ in die Suchleiste im oberen Teil der Seite eingeben.
- S3 Bucket erstellen.
- Ein Bucket ist eine Art Container, den Amazon S3 zum Speichern Ihrer Dateien verwendet. Ein Bucket kann in der AWS S3-Schnittstelle durch Klicken auf die Schaltfläche „Bucket erstellen“ im Titelbildschirm erstellt werden.
- Es ist zu beachten, dass die Webseite anders aussieht, je nachdem, ob Sie bereits einen Bucket in diesem Konto erstellt haben oder nicht. Wenn bereits andere Buckets vorhanden sind, wird Ihnen ein Bildschirm angezeigt, auf dem Sie die Buckets verwalten können, einschließlich Umbenennung oder Löschen der Buckets.
- Wenn Sie hingegen zum ersten Mal einen Bucket in diesem AWS S3-Backup-Konto erstellen, wird ein entsprechender Bildschirm angezeigt, in dem beschrieben wird, wie Sie einen Bucket überhaupt erstellen können. In diesem Fall können Sie entweder die Schaltfläche „Create bucket“ (Bucket erstellen) oder die Schaltfläche „Get started“ (Loslegen) verwenden, die beide zur gleichen Stelle führen sollten – dem Bildschirm zur Bucket-Erstellung.
- Die erste Aufforderung des Bildschirms sollte sich auf die Erstellung eines Namens für Ihren neuen Bucket beziehen, und das Feld würde Sie auch benachrichtigen, wenn der Name des Buckets nicht einigen von Amazons eigenen Bucket-Namensvorschriften entspricht. Sie müssen auch eine geeignete Region für Ihren zukünftigen Bucket auswählen. Klicken Sie anschließend auf „Weiter“, um fortzufahren.
- Auf dem zweiten Bildschirm zur Bucket-Erstellung können Sie eine der Eigenschaften für Ihren Amazon S3-Backup-Bucket aktivieren, z. B. Tags, Versionierung, Verschlüsselung, Protokollierung des Serverzugriffs und Protokollierung auf Objektebene. Um diese Erklärung einfach zu halten, werden wir keine dieser Eigenschaften aktivieren. Klicken Sie auf „Weiter“, um fortzufahren.
- Auf dem nächsten Bildschirm können Sie die Berechtigungen anpassen, und zwar sowohl die System- als auch die Benutzerberechtigungen. Sie können auch Ihre eigenen Berechtigungsstufen ändern und bestimmte Personen hinzufügen, die Zugriff auf diesen Bereich haben. In unserem Beispiel werden alle standardmäßigen Berechtigungsstufen beibehalten – der Ersteller hat Zugriff auf alles, was sich in diesem Bucket befindet. Klicken Sie auf „Weiter“, wenn Sie fertig sind.
- Der letzte Teil des Vorgangs ist der Bestätigungsbildschirm, in dem Sie alle Einstellungen, die Sie zuvor konfiguriert haben, überprüfen können. Dazu gehören Berechtigungen, Eigenschaften und Namen. Wenn Sie nach Abschluss des Überprüfungsprozesses auf die Schaltfläche „Bucket erstellen“ klicken, wird genau das getan, was sie sagt – ein Bucket mit Ihren spezifischen Einstellungen erstellt.
- Hochladen einer Datei.
- Das Hochladen einer Datei in Ihren neuen AWS S3-Bucket ist ebenfalls relativ einfach, wenn Sie von der Amazon S3-Konsole aus starten. Wenn Sie auf den Namen Ihres neuen AWS-Buckets klicken, können Sie auf diesen Bucket und seinen Inhalt zugreifen.
- Sobald Sie sich auf der Landing Page Ihres Buckets befinden, können Sie den Upload-Prozess starten, indem Sie auf die Schaltfläche „Upload“ im linken Teil der Seite klicken.
- Im folgenden Fenster gibt es zwei Möglichkeiten, eine Datei hochzuladen – entweder durch Ziehen einer Datei auf die Seite oder durch Klicken auf die Schaltfläche „Dateien hinzufügen“ und anschließendes Auswählen der betreffenden Datei. Nachdem Sie die hochzuladende Datei ausgewählt haben, können Sie auf „Weiter“ klicken, um fortzufahren.
- Wie bei der Erstellung des Backup-S3-Buckets können Sie die Berechtigungen der Datei vor dem Hochladen ändern, einschließlich Ihrer eigenen Berechtigungen, der Konten, die Zugriff auf diese Datei haben, und der öffentlichen Berechtigungen. Klicken Sie auf die Schaltfläche „Weiter“, um fortzufahren.
- Auf der nächsten Seite geht es um spezifische Eigenschaften für Ihre Datei, wie z. B. die Speicherklasse (Standard, Standard-IA und reduzierte Redundanz), die Verschlüsselung (Keine, S3-Hauptschlüssel und KMS-Hauptschlüssel) und die Metadaten. Wenn Sie sich für eine der Optionen entschieden haben, können Sie über die Schaltfläche „Weiter“ fortfahren.
- Auf dem letzten Bildschirm dieser Sequenz geht es darum, alle Ihre Änderungen vor dem Hochladen zu bestätigen. Hier werden Ihre Eigenschaften, Berechtigungen und die Anzahl der ausgewählten Dateien festgelegt. Wenn Sie auf die Schaltfläche „Hochladen“ klicken, nachdem Sie die Details überprüft haben, sollte der Hochladevorgang beginnen.
- Abrufen einer Datei.
- Das Herunterladen einer Datei aus Ihrem AWS S3-Bucket kann in zwei einfachen Schritten erfolgen. Zunächst müssen Sie sich auf der Landing Page Ihres Buckets befinden, auf der Sie alle Dateien sehen, die in diesem Bucket gespeichert sind. Der erste Schritt besteht darin, auf das Feld mit dem Häkchen links neben der Datei zu klicken, die Sie herunterladen möchten
- Wenn Sie mindestens eine Datei in der Liste auswählen, erscheint ein Popup-Fenster mit einer Beschreibung und zwei Schaltflächen: „Herunterladen“ und „Pfad kopieren“. Verwenden Sie die Schaltfläche „Herunterladen“, um die betreffende Datei zu erhalten.
- Löschen einer Datei oder eines Eimers.
- Das Löschen nicht benötigter Dateien oder sogar Buckets ist nicht nur einfach, sondern wird auch von Amazon selbst dringend empfohlen, um eine übermäßige Verschmutzung Ihrer Dateien zu vermeiden. Zunächst zum Löschvorgang der Dateien.
- Sobald Sie auf der Landing Page eines Buckets angekommen sind, müssen Sie als Erstes das Kontrollkästchen links neben der Datei anklicken, die Sie löschen möchten.
- Nachdem Sie die zu löschende(n) Datei(en) ausgewählt haben, können Sie auf die Schaltfläche „Mehr“ neben den Schaltflächen „Hochladen“ und „Ordner erstellen“ klicken und die Option „Löschen“ aus der Dropdown-Liste auswählen.
- Sie erhalten einen Bestätigungsbildschirm, der Ihnen anzeigt, welche Dateien gelöscht werden sollen, und Sie müssen noch einmal auf „Löschen“ klicken, um den Löschvorgang einzuleiten.
- Der Vorgang zum Löschen eines ganzen Buckets ist etwas anders. Zunächst müssen Sie Ihre Bucket-Landingpage verlassen und zur Hauptkonsole von Amazon S3 zurückkehren, in der alle Ihre Buckets aufgelistet sind.
- Wenn Sie auf das leere Feld rechts neben dem Bucket, den Sie löschen möchten, klicken, wählen Sie den Bucket aus, und durch Klicken auf die Schaltfläche „Bucket löschen“ wird der Löschvorgang eingeleitet.
Es ist erwähnenswert, dass alle diese grundlegenden Vorgänge nur mit Amazons eigenem System und ohne zusätzliche AWS-Sicherungslösungen durchgeführt werden können.
Andere Methoden zur Sicherung Ihres Amazon S3-Buckets
Die Verwendung von AWS Backup ist nicht die einzige Option, wenn es um S3-Backups geht. Es gibt eine Vielzahl verschiedener Optionen, die sowohl von einer Anwendung innerhalb des Amazon-Ökosystems als auch von Lösungen Dritter durchgeführt werden können.
Hier finden Sie zum Beispiel mehrere Möglichkeiten, eine S3-Sicherung zu erstellen, ohne die Anwendung AWS Backup zu verwenden:
- Erstellen von Sicherungen mit Amazon Glacier;
- Verwenden Sie AWS SDK, um einen S3-Bucket in einen anderen zu kopieren;
- Kopieren von Informationen auf den Produktionsserver, der selbst gesichert wird;
- Versionierung als Sicherungsdienst verwenden.
Es ist erwähnenswert, dass die meisten dieser Methoden nicht gerade schnell oder bequem sind. Amazon Glacier wäre zum Beispiel eine gute Backup-Lösung, wenn sie nicht viel langsamer wäre als Ihr regulärer Backup-Prozess, da es bei Glacier mehr um die Datenarchivierung und weniger um die laufende Datensicherung geht.
Versionierung und Bucket-Replikation
Die Versionierung ist ein Thema, das eine genauere Betrachtung verdient. Die Versionierung von Objekten ist eine Funktion von Amazon S3, die den Schutz von Daten gegen eine Vielzahl von unerwünschten Änderungen, wie z. B. Löschung, Beschädigung usw., ermöglicht – sie funktioniert durch die Erstellung einer neuen Kopie einer Datei jedes Mal, wenn diese Datei in irgendeiner Weise geändert wird (wenn sie in S3 gespeichert wird).
Der S3-Bucket speichert all diese verschiedenen Versionen derselben Datei, so dass Sie auf jede dieser früheren Versionen zugreifen und sie wiederherstellen können. Dies kann manchmal sogar einer Löschung entgegenwirken, da das Löschen einer aktuellen Version der Datei normalerweise keine Auswirkungen auf die früheren Versionen hat.
Es ist zu bedenken, dass die Verwendung der Versionskontrolle als Backup-Lösung die Speicherkosten aufgrund der zu speichernden Datenmengen erheblich erhöhen kann. In diesem Fall sollten Sie Ihre Lebenszyklus-Richtlinie für frühere Dateiversionen so konfigurieren, dass neuere Kopien ältere ersetzen können, wodurch die Versionierung insgesamt eine kostengünstigere Lösung darstellt.
Die S3-Versionierung kann über die AWS Management Console aktiviert werden, indem Sie zu Services > S3 (in der Kategorie „Storage“) > Buckets > bucket_name gehen. Jeder Bucket verfügt über viele verschiedene anpassbare Optionen, die in mehrere Registerkarten unterteilt sind. Wir suchen nach einer Registerkarte namens „Eigenschaften“.
Die Bucket-Versionierung ist eine der ersten Optionen, die auf der Registerkarte „Eigenschaften“ angezeigt wird. Sie ist zwar standardmäßig deaktiviert, aber um sie zu aktivieren, müssen Sie nur „Bearbeiten“ unter der Option „Bucket Versioning“ auswählen und im nächsten Fenster „Bucket Versioning“ von „Suspend“ auf „Enable“ umstellen.
Sie werden feststellen, dass bei der Aktivierung der Bucket-Versionierung ein hilfreicher Hinweis angezeigt wird, der Sie auffordert, Ihre Lebenszyklusregeln zu aktualisieren, um die Versionierung als Prozess richtig einzurichten. Die Lebenszyklusregeln können auf der Registerkarte „Verwaltung“ im gleichen Menü „Bucket-Details“ geändert werden.
Zunächst müssen Sie eine Lebenszyklusregel erstellen (Schaltfläche „Lebenszyklusregel erstellen“) – Sie müssen einen Namen eingeben und den Geltungsbereich der Rolle auswählen (kann auf den gesamten Bucket oder auf bestimmte, mit Filtern ausgewählte Dateien angewendet werden).
Sie können auch die Art und Weise, wie sich diese Regel verhält, anpassen, indem Sie den Teil „Lebenszyklusregel-Aktionen“ dieses Menüs verwenden. Hier können Sie eine Reihe von Regeln einrichten, die sich auf aktuelle und frühere Versionen von Dateien beziehen, sowie die Voraussetzungen für den Ablauf der Version (mit anschließender Löschung). Nachdem Sie alles eingerichtet haben, müssen Sie nur noch auf „Regel erstellen“ klicken, damit die Lebenszyklusregel erstellt und angewendet wird.
Während die Versionierung für die Arbeit mit bestimmten Dateien hervorragend geeignet ist, ist sie möglicherweise nicht die richtige Wahl, wenn es zu viele Dateien gibt, von denen Sie frühere Versionen aufbewahren möchten. Glücklicherweise ist die Versionierung hier nicht die einzige Alternative, denn es gibt auch die Bucket-Replikation.
Diese Option finden Sie im gleichen Menü wie zuvor; eine weitere Kategorie unter den „Lebenszyklusregeln“ mit dem Namen „Replikationsregeln“. Wenn Sie auf „Replikationsregel erstellen“ klicken, öffnet sich eine neue Seite, auf der Sie eine Reihe von Einstellungen für die künftige Eimer-Replikationsregel vornehmen können.
Sie können hier den Namen einer Regel ändern, den Status der Regel zum Zeitpunkt der Erstellung festlegen (ob sie von Anfang an aktiviert oder deaktiviert sein soll), einen zu replizierenden Ziel-Bucket und einen Ziel-Bucket zum Speichern der Kopie des Originals auswählen. Zu den zusätzlichen Optionen auf dieser Seite gehören die Steuerung der Replikationszeit, die Synchronisierung von Replikationsänderungen, verschiedene Replikationsmetriken und mehr.
Auch diese Option ist nicht perfekt, da sie das Kopieren eines ganzen Buckets beinhaltet, was den verbrauchten Speicherplatz massiv erhöht. Da die meisten dieser Optionen ihre eigenen Probleme und Unzulänglichkeiten haben, sollten Sie eine Lösung eines Drittanbieters für Ihre S3-Sicherungs- und Wiederherstellungsanforderungen in Betracht ziehen.
Apropos Lösungen von Drittanbietern: Es gibt zwar viele verschiedene auf dem Markt, aber wir werden uns eine der vielversprechendsten ansehen – die Lösung von Bacula Enterprise.
Unternehmenstaugliche AWS S3-Sicherungslösungen mit minimalen Wiederherstellungskosten.
Bacula bietet nativ integrierte AWS S3-Backup-Lösungen als Teil seiner umfassenden Cloud-basierten Backup- und Recovery-Optionen für Unternehmen. Es bietet native Integration mit öffentlichen und privaten Clouds über die Amazon S3-Schnittstelle, mit transparenter Unterstützung für S3-IA. AWS S3-Backup ist für Linux, Windows und andere Plattformen verfügbar. Es gibt jedoch noch etwas, was Ihr Unternehmen über Amazon S3 Backup mit Bacula Enterprise wissen sollte: die Möglichkeit, eine einzigartige Kontrolle über Ihr Cloud-Backup zu haben – und gleichzeitig eine signifikante Reduzierung der Cloud-Kosten für AWS-Backup-Lösungen.
AWS S3-Sicherung mit Bacula Enterprise
Um den AWS-Backup-Prozess mit Bacula zu starten, müssen Sie zunächst den Konfigurationsmodus aufrufen. Danach stehen Ihnen mehrere neue Optionen zur Verfügung. Sie benötigen die Option „Add a New Storage Resource“.
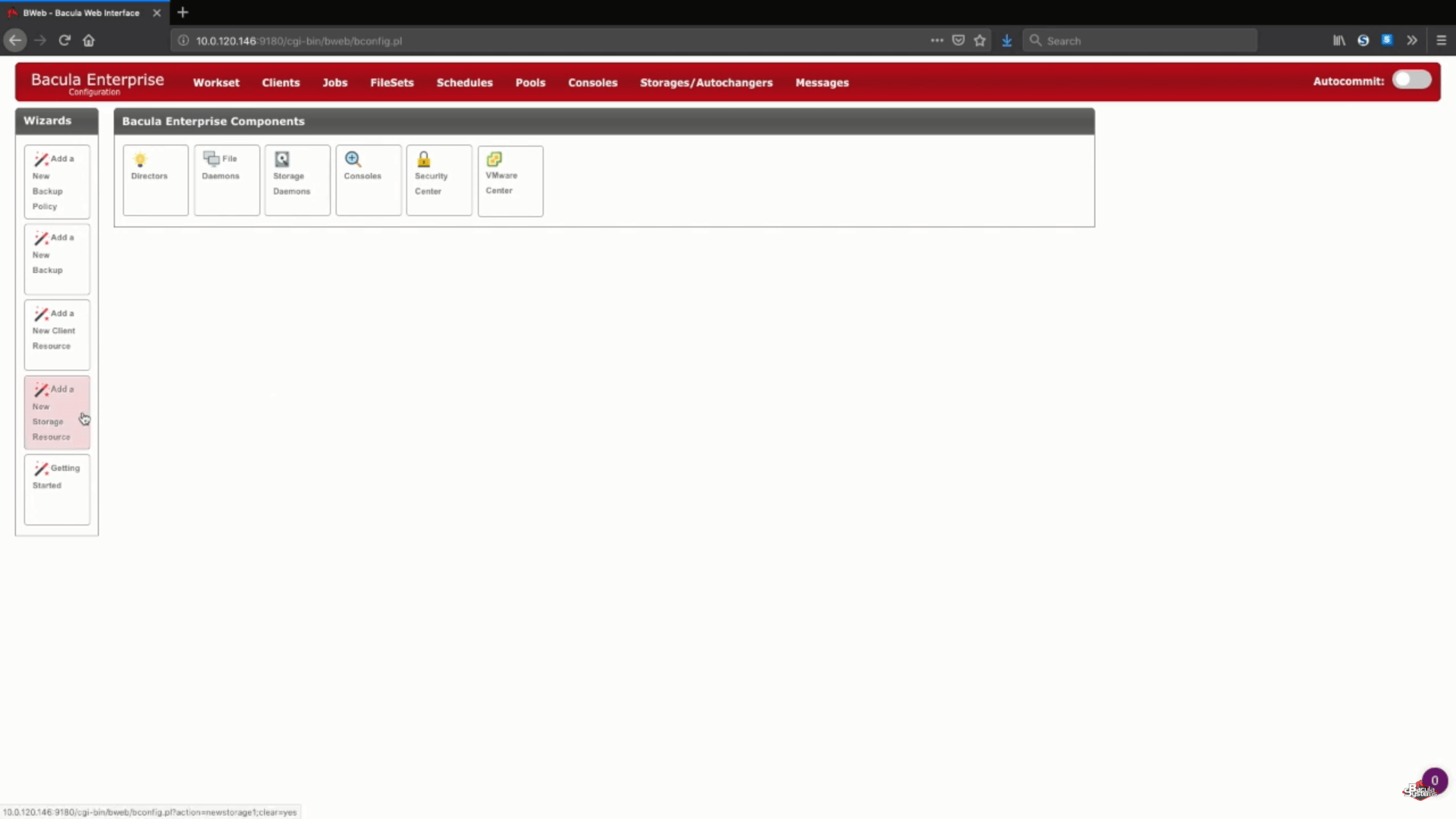
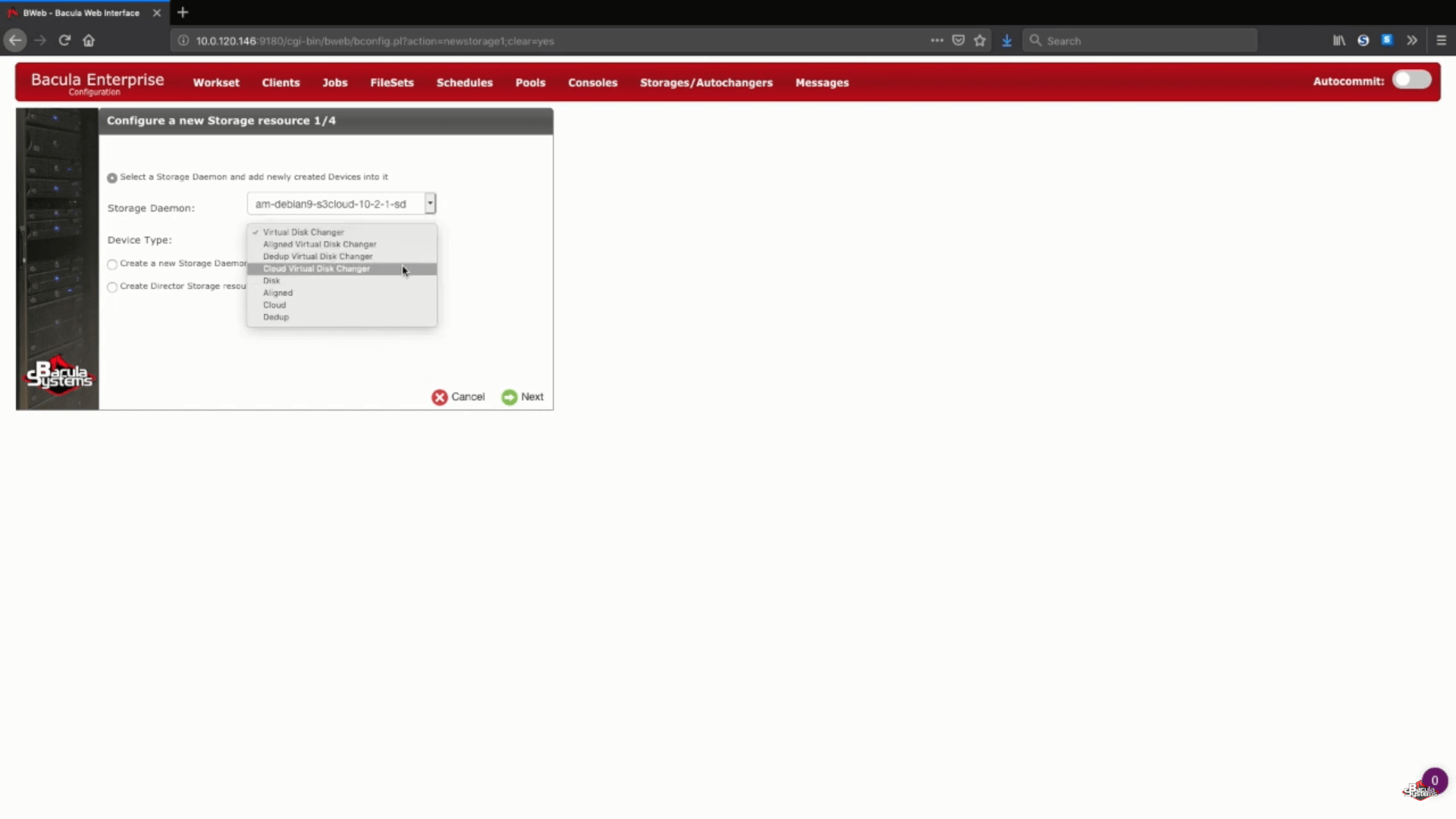
Hinzufügen eines neuen S3-Speichers in Bacula Enterprise
In diesem konkreten Beispiel fügen wir einen neuen Amazon S3-Speicher zu einem bestehenden Speicher-Daemon hinzu. Außerdem wählen wir unter „Gerätetyp“ den „Cloud Virtual Disk Changer“ – dieser Gerätetyp ermöglicht mehrere gleichzeitige Backups auf denselben Cloud-Speicher.
Da unser Speicher-Daemon bereits existiert, können alle Informationen in Schritt 2 (Konfigurieren einer neuen Speicherressource) von den zuvor erstellten Geräten übernommen werden.
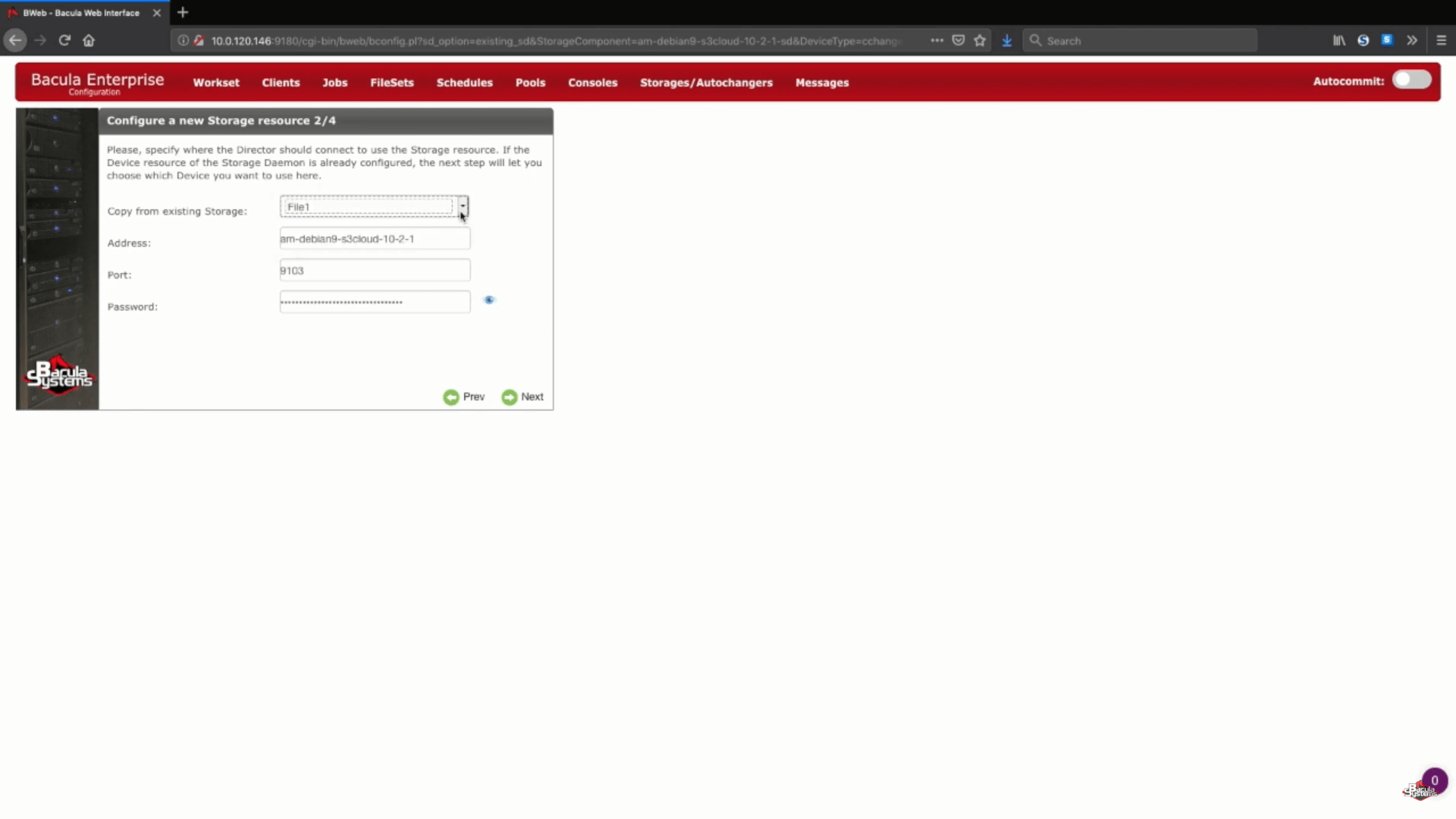
Konfigurieren der AWS S3-Speicher-Sicherung mit Bacula Enterprise
Der nächste Schritt des AWS-Sicherungsprozesses ist die Konfiguration der Cloud-Speicherinformationen. In diesem Beispiel werden wir unsere Backup-Volumes im Cloud-Cache speichern, der normalerweise als kleiner temporärer Bereich zwischen dem Laden eines Backups in eine Cloud verwendet wird, aber dennoch den Wert der Daten einer Woche oder mehr aufnehmen kann, um lokale Backups für diesen Zeitraum zu ermöglichen, und Cloud-Backups, wenn der Zeitraum länger als eine Woche ist. Sie können sich jederzeit an die Experten des Bacula-Supports wenden, um mehr über die Speichergröße des Cloud-Cache, die Aufbewahrungspolitik des Cache und das Verhalten beim Hochladen in die Cloud zu erfahren.
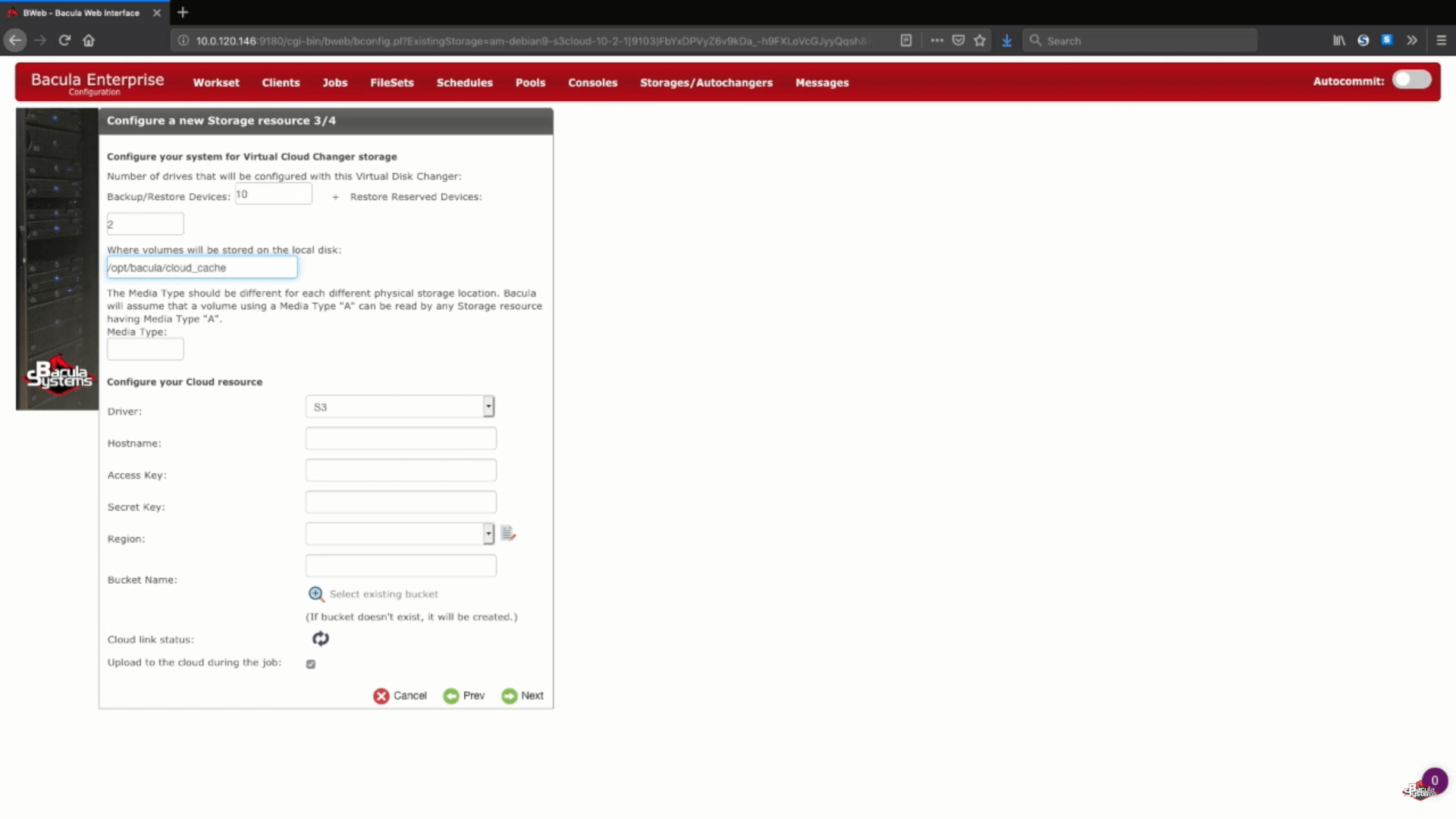
Als Nächstes wählen wir einen eindeutigen Medientyp für unser neues Speichergerät, damit Bacula die Dateien dieses speziellen Speichergeräts leichter erkennen kann.
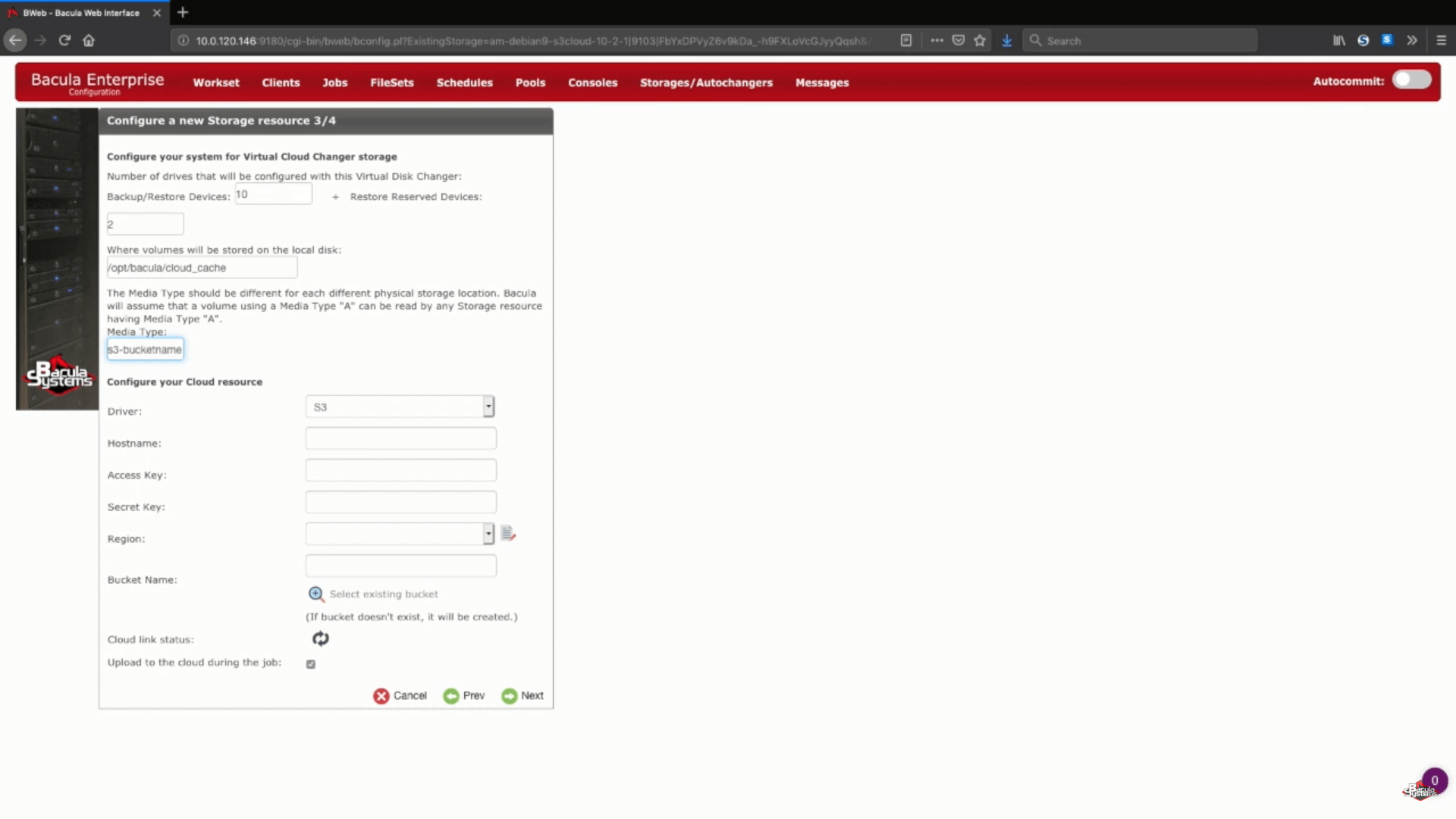
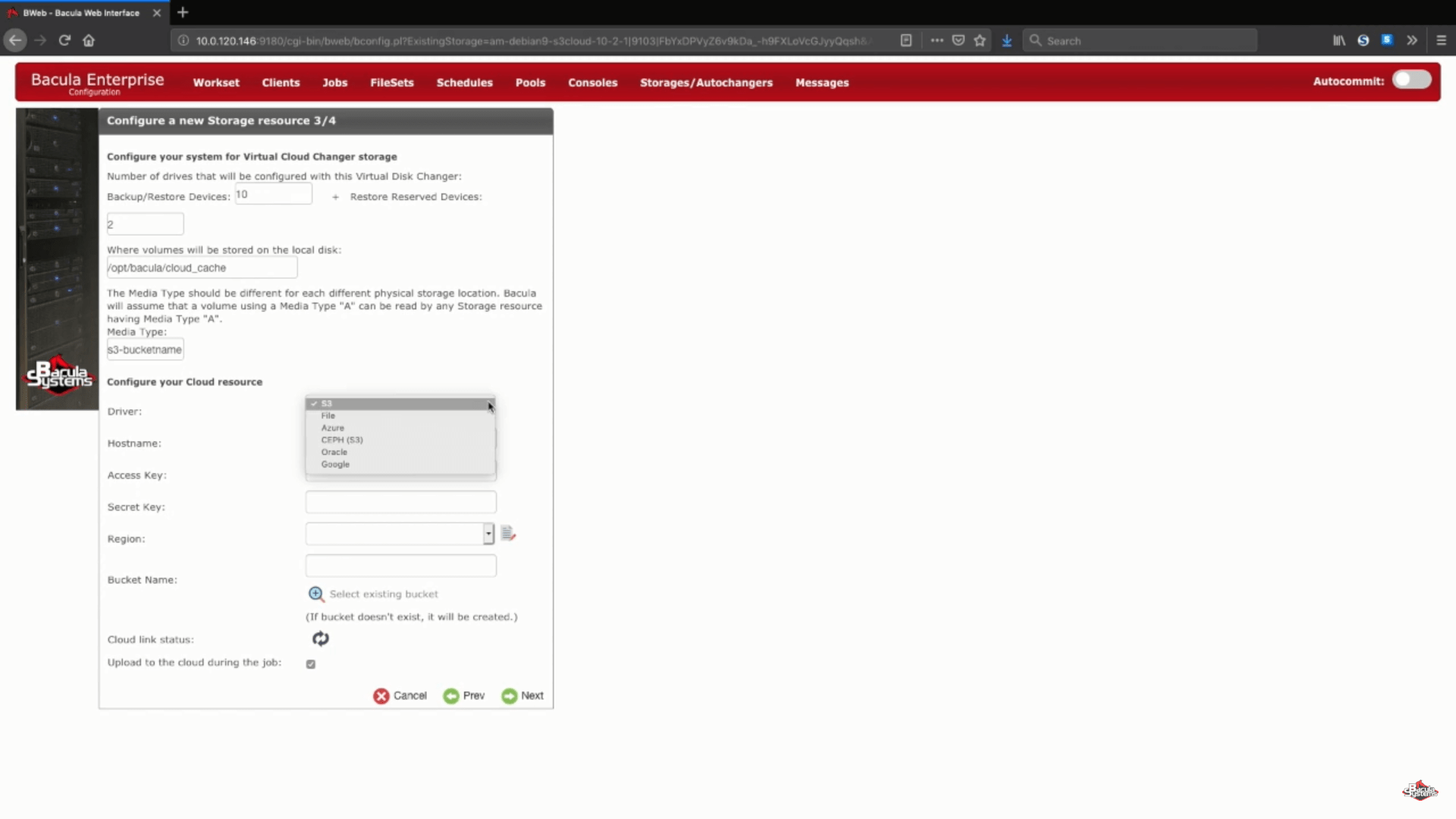
Ein weiterer Teil dieses Schrittes ist die Auswahl Ihres AWS S3 Cloud-Treibers aus einer Liste von unterstützten Cloud-Treibern.
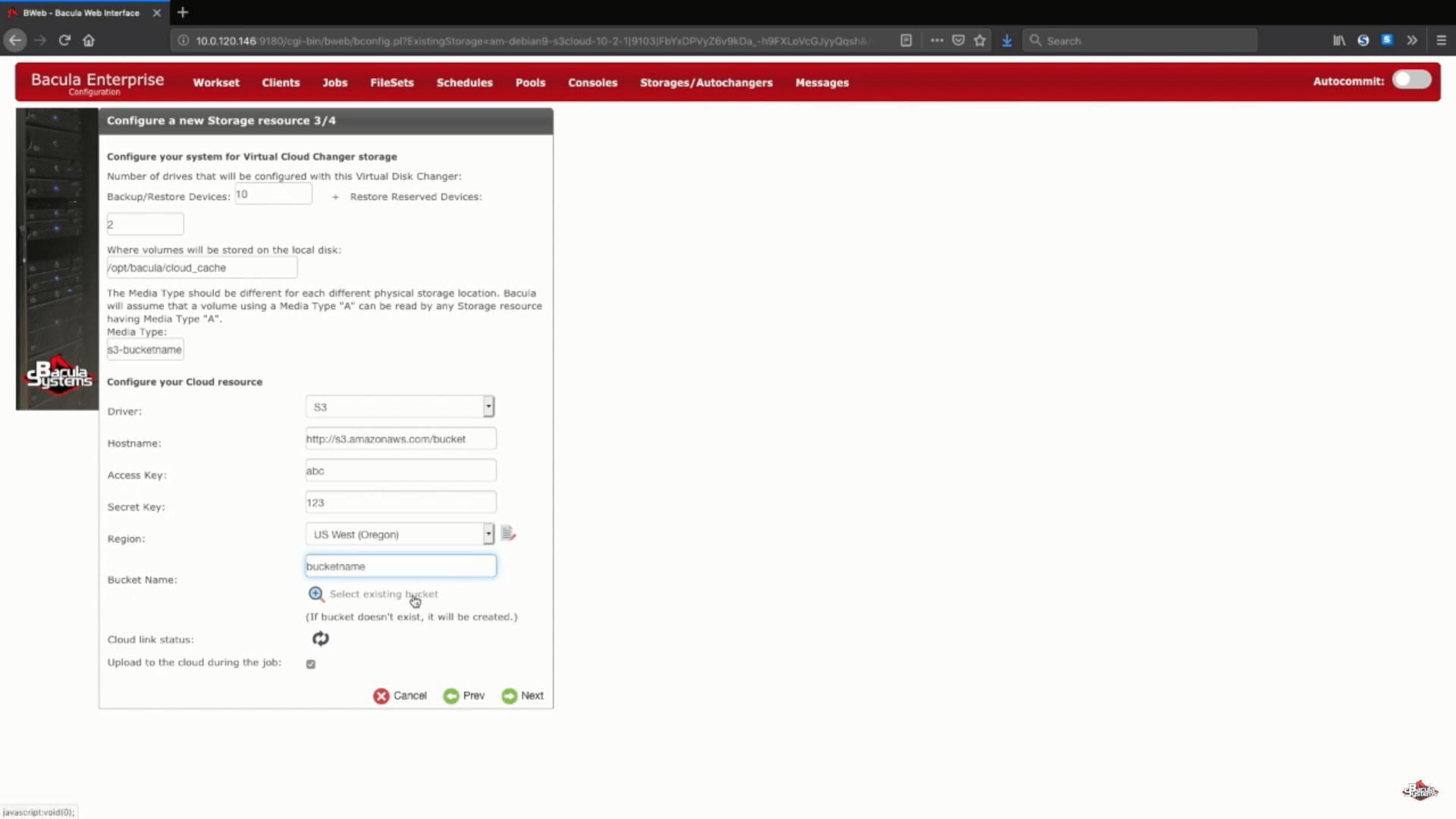
Als Nächstes stellen wir eine Liste mit beliebigen Informationen wie Cloud-Hostname, Kontoinformationen, Region usw. ein. Sie haben auch die Möglichkeit, einen bestehenden Bucket auszuwählen, indem Sie sich mit Ihrem bestehenden Konto verbinden, oder einen Namen in die entsprechende Zeile einzugeben, um die Erstellung eines neuen Buckets zu bestätigen.
Abschluss der Einrichtung des S3-Speichers
Es verbleiben zwei mögliche Optionen: Cloud-Link-Status und „Upload in die Cloud während des Auftrags“. Mit der Schaltfläche „Cloud-Link-Status“ können Sie sofort überprüfen, ob Ihr aktuelles System mit einer Cloud Ihrer Wahl verbunden ist. „Während des Auftrags in die Cloud hochladen“ ist eine Option, die als Teil der Standardeinstellungen gewählt wird, um Ihre gesicherten Daten in die Cloud hochzuladen, sobald sie bereit sind (sogar während eines Sicherungsauftrags), aber Sie können diese Option auch deaktivieren, wenn Sie den Upload nach Beendigung eines Auftrags oder mit einem anderen Zeitplan im Hinterkopf durchführen möchten.
Im nächsten Schritt dieses Assistenten geben Sie einfach den Namen Ihres bevorzugten Speichers und eine optionale Beschreibung ein.
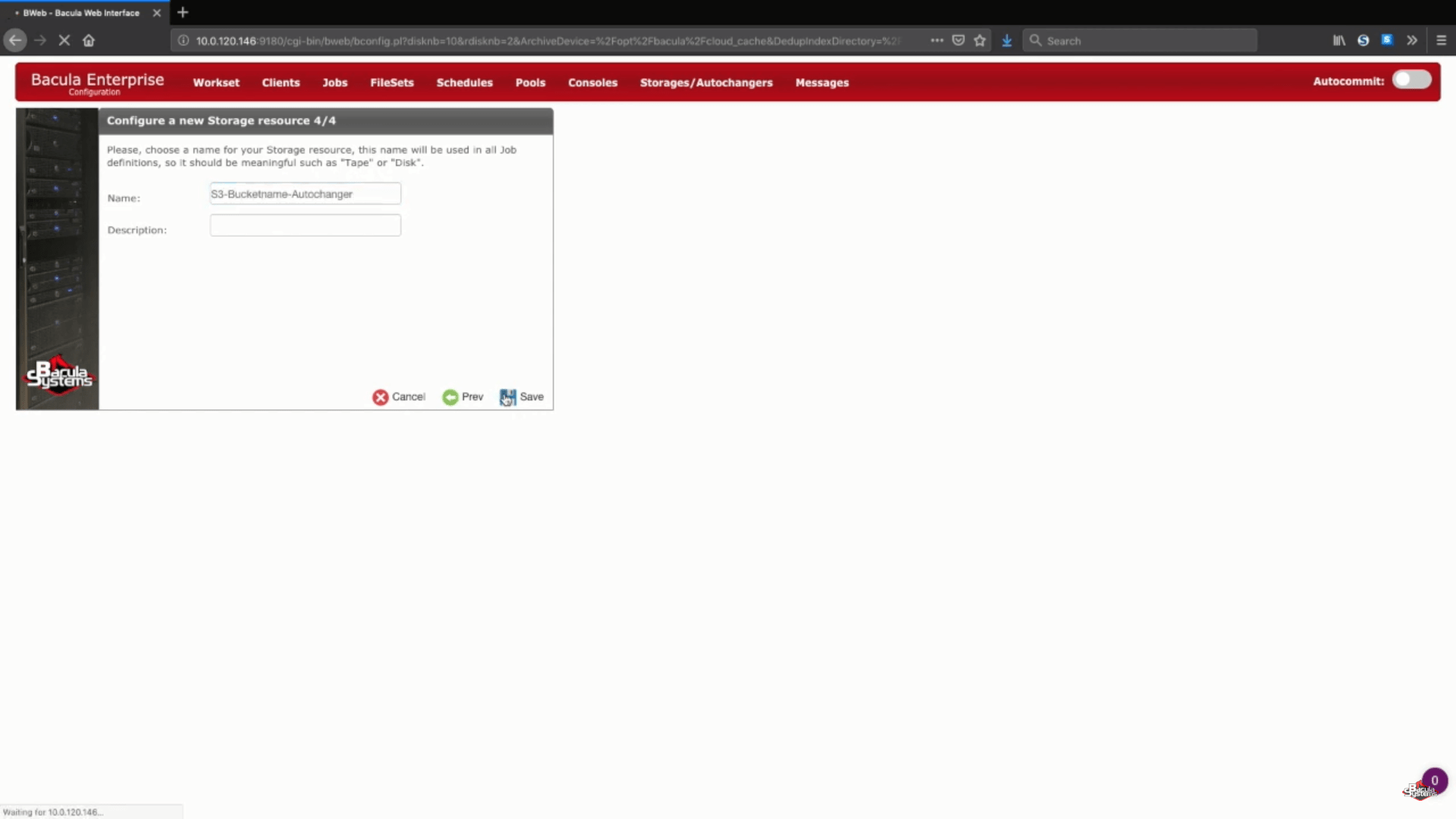
Speichern Ihrer neuen S3-Sicherungseinstellungen
Nach diesem Schritt können Sie auf die Schaltfläche „Speichern“ klicken, damit alle vorherigen Änderungen in die Produktion übernommen werden. Denken Sie daran, dass Sie Ihren Speicher-Daemon neu laden müssen, um alles ordnungsgemäß in die Produktion zu übertragen, was bedeutet, dass alle laufenden Aufträge während des Prozesses fehlschlagen würden.
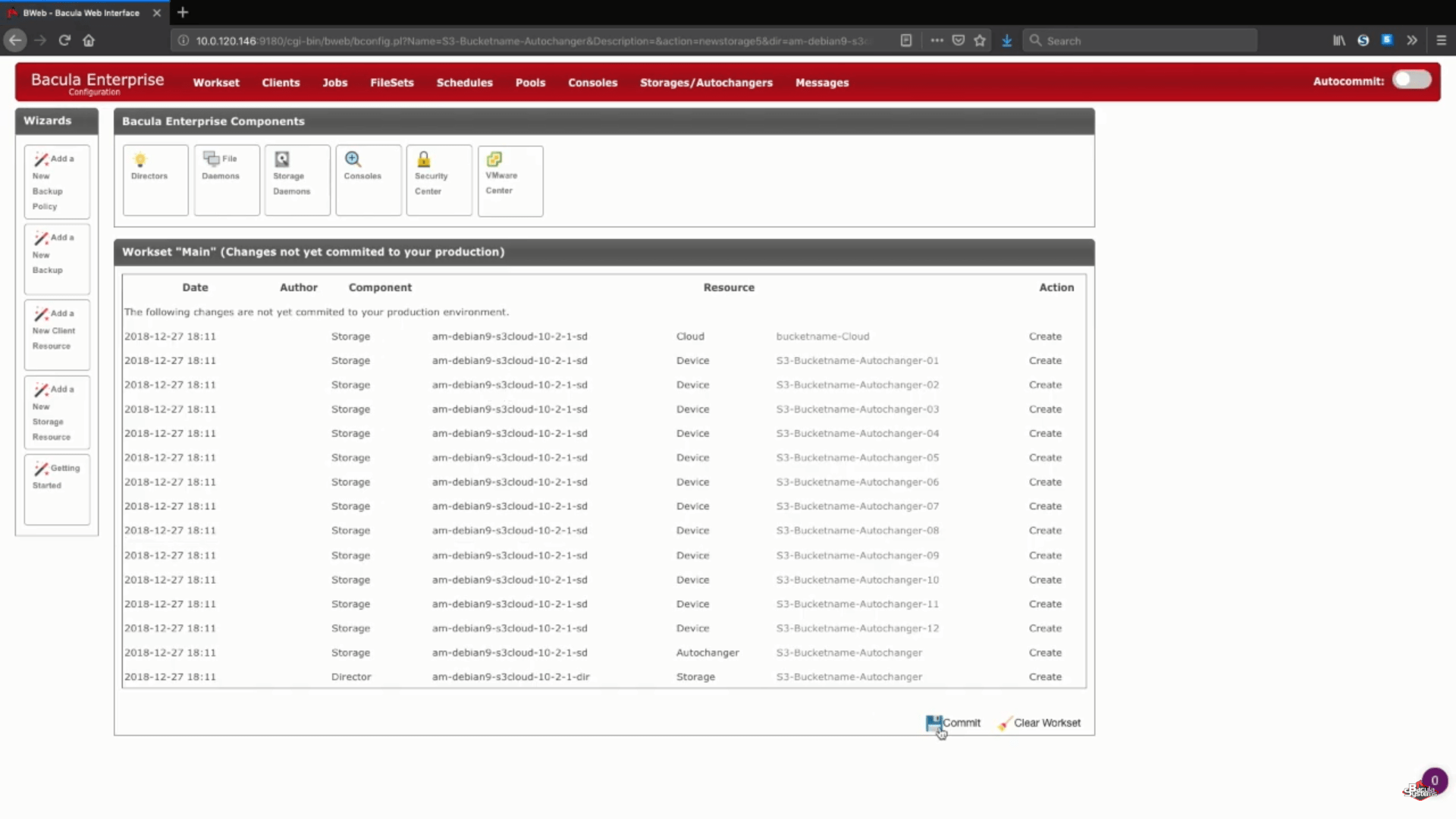
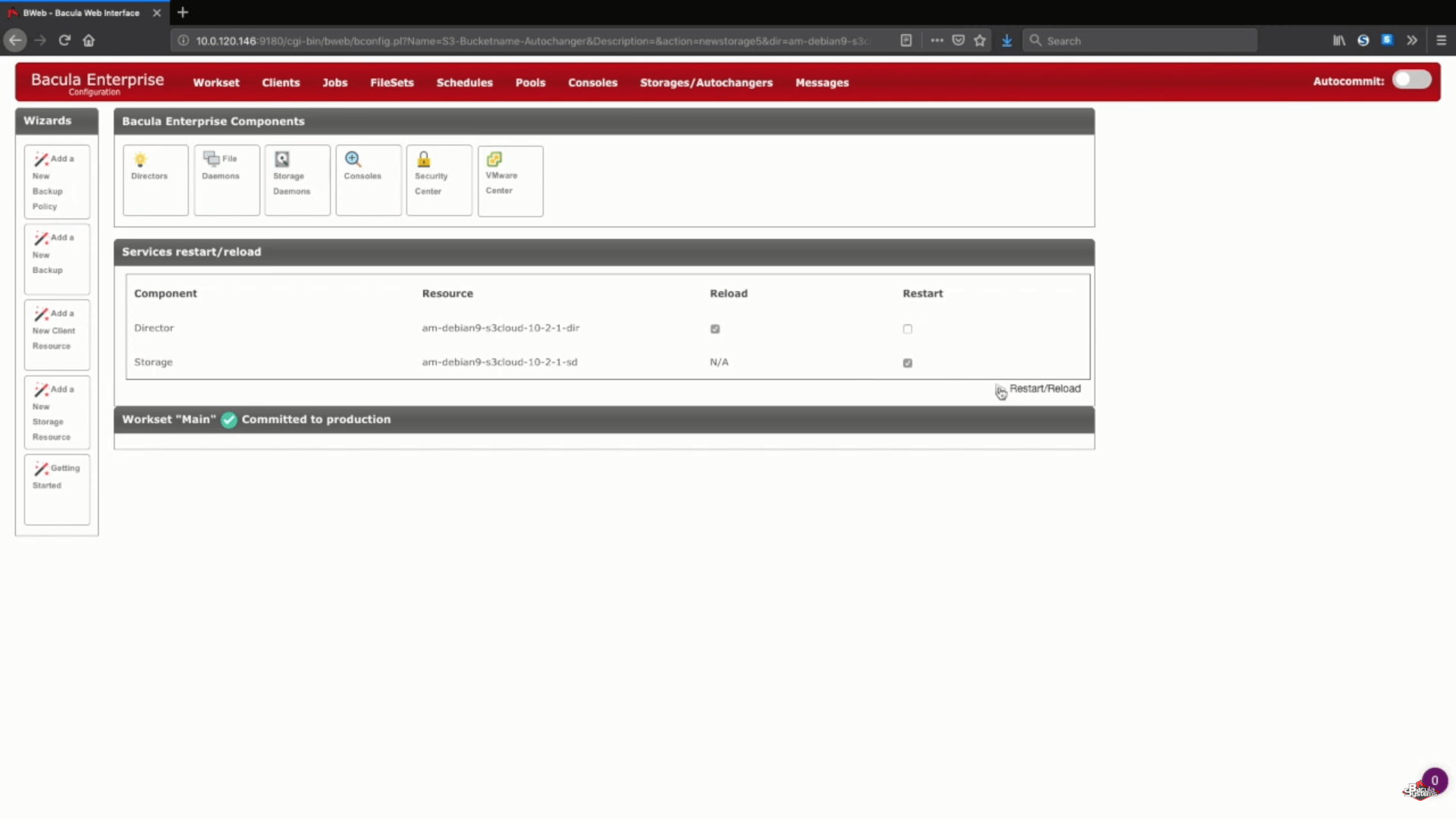
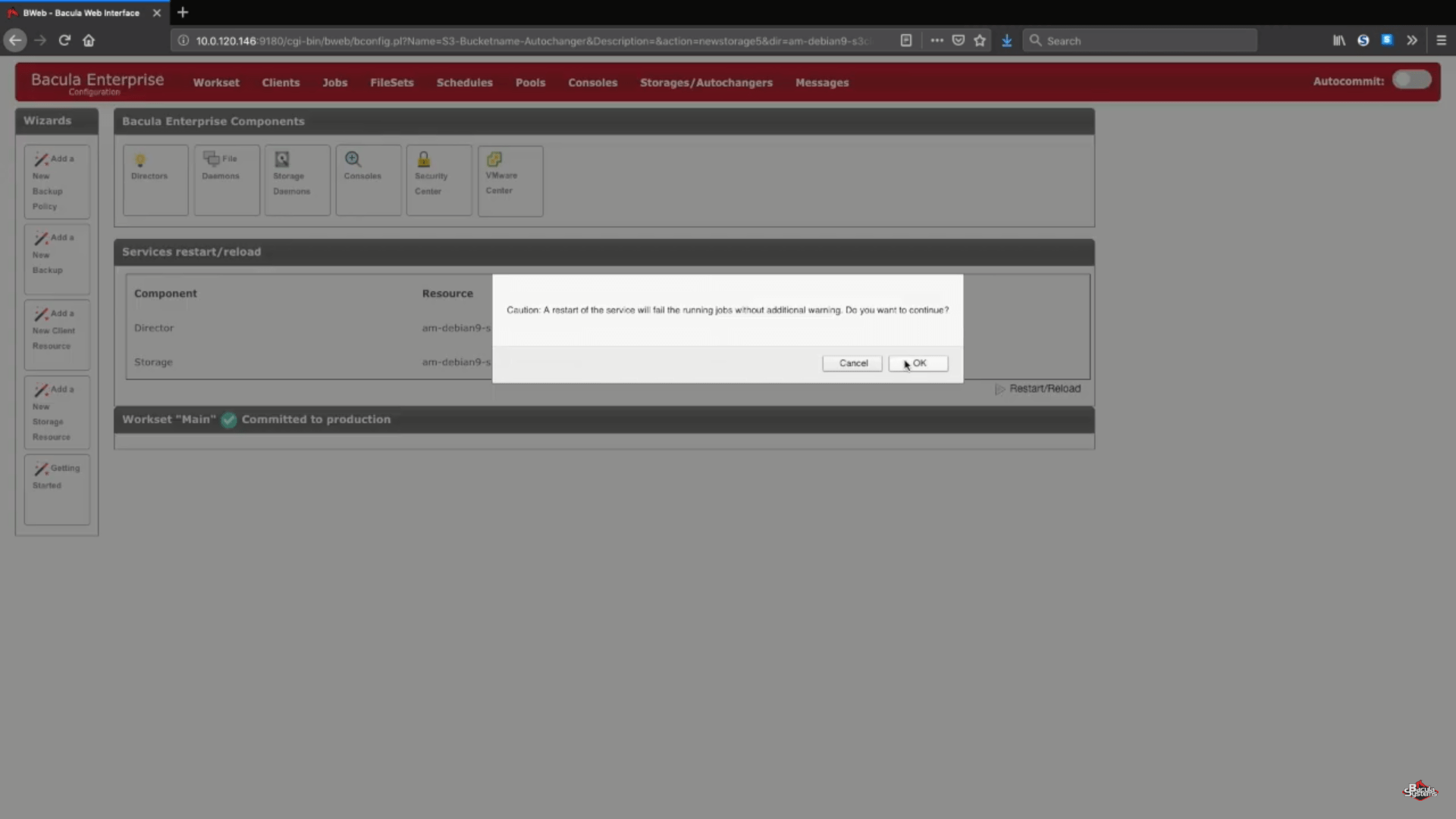
Ein logischer Schritt wäre dann, neue Backup-Pools für diesen speziellen Cloud-Speicher einzurichten und die Jobs so zu konfigurieren, dass sie Daten in die neuen Pools schreiben. Sie können sich an die Dokumentation von Bacula wenden, unseren Support kontaktieren oder unseren YouTube-Kanal besuchen, um Hilfe zu diesen Schritten zu erhalten.
Testen der AWS-Sicherungseinstellungen
Um zu testen, ob alles, was wir gerade gemacht haben, richtig funktioniert, führen wir einen kleinen vollständigen Amazon S3-Sicherungsauftrag manuell direkt auf dem neuen Speichergerät aus. Normalerweise wird dieser Prozess mithilfe eines Auftragsplans und/oder anderer Konfigurationen automatisiert.
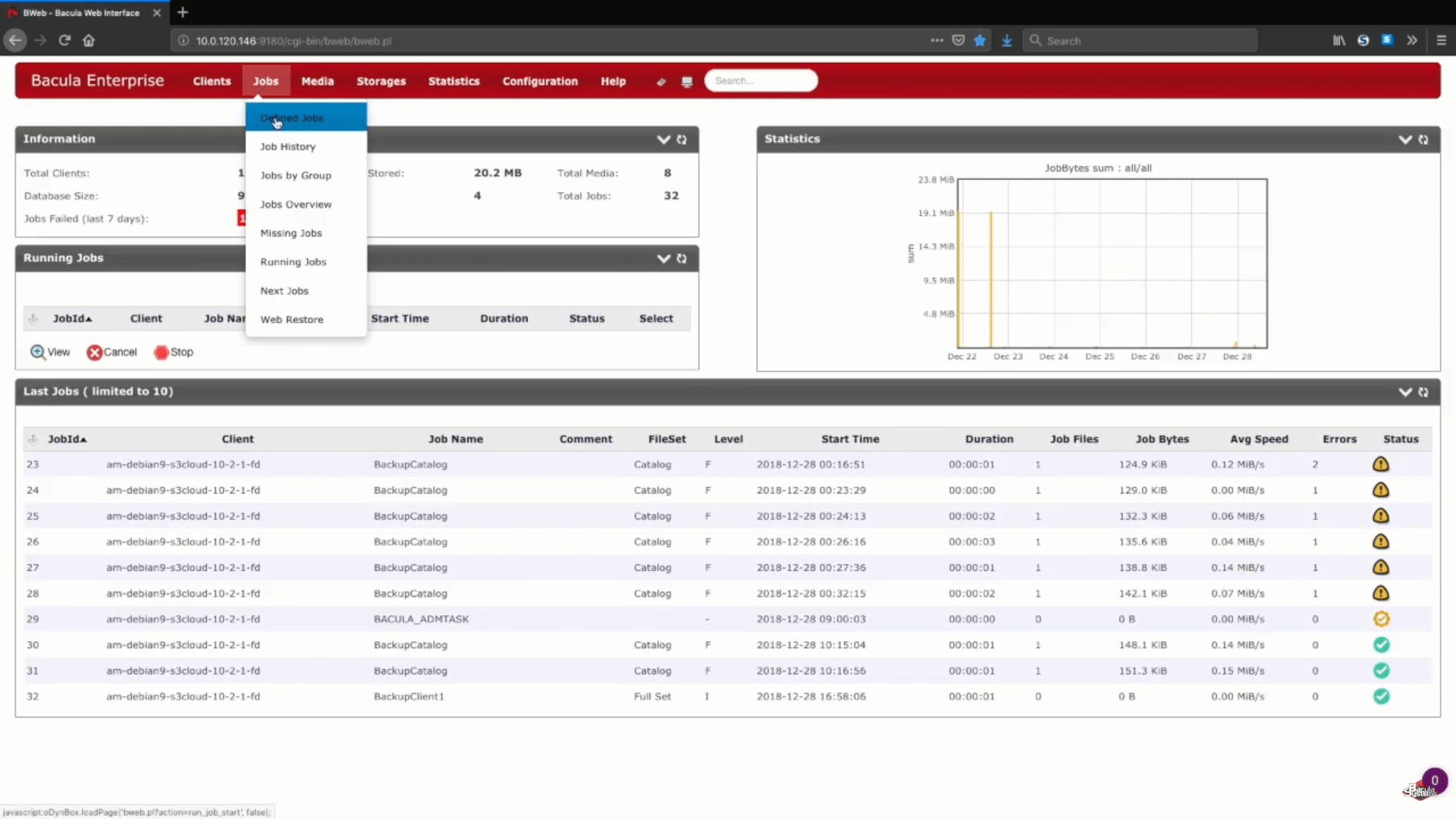
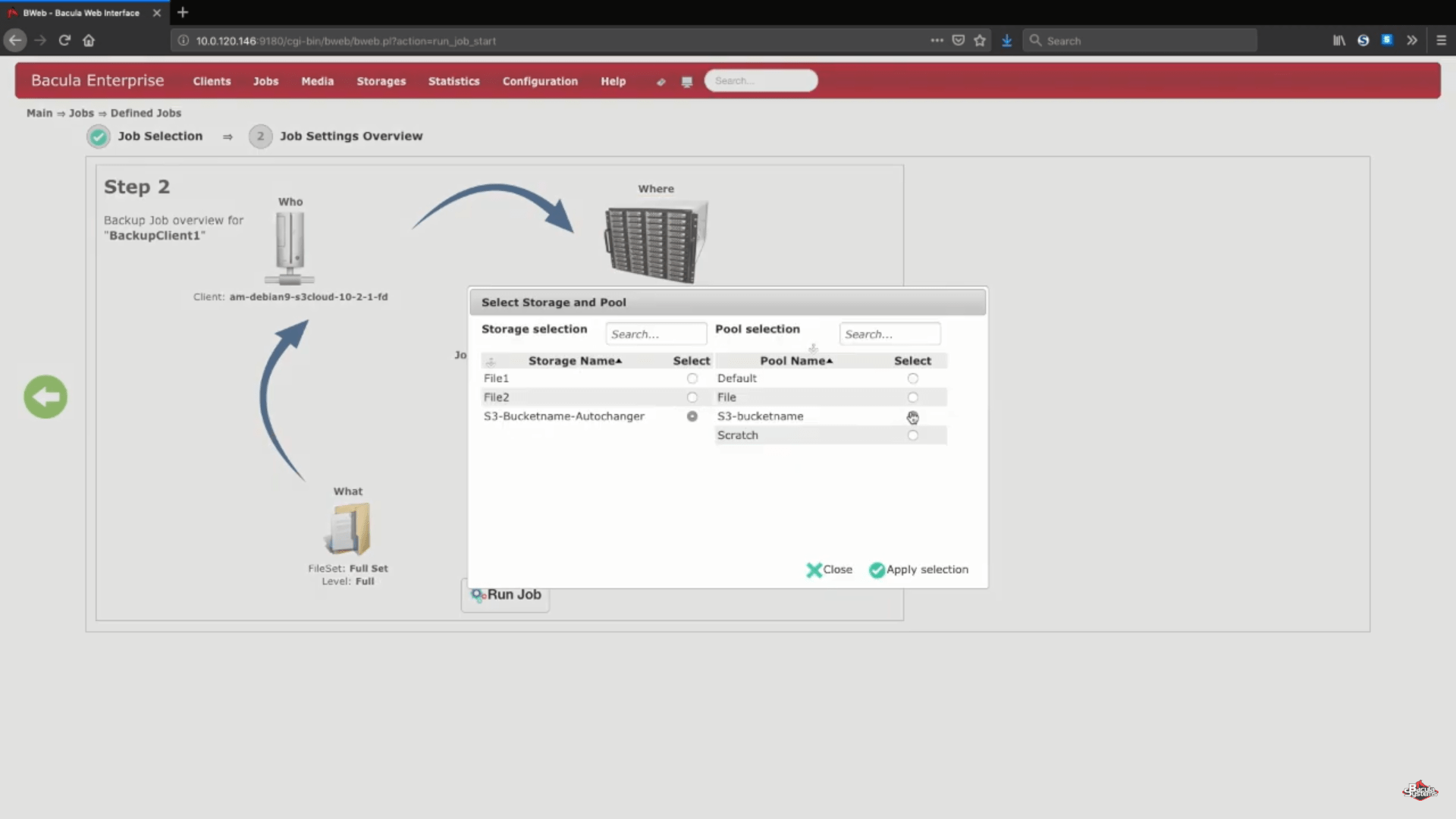
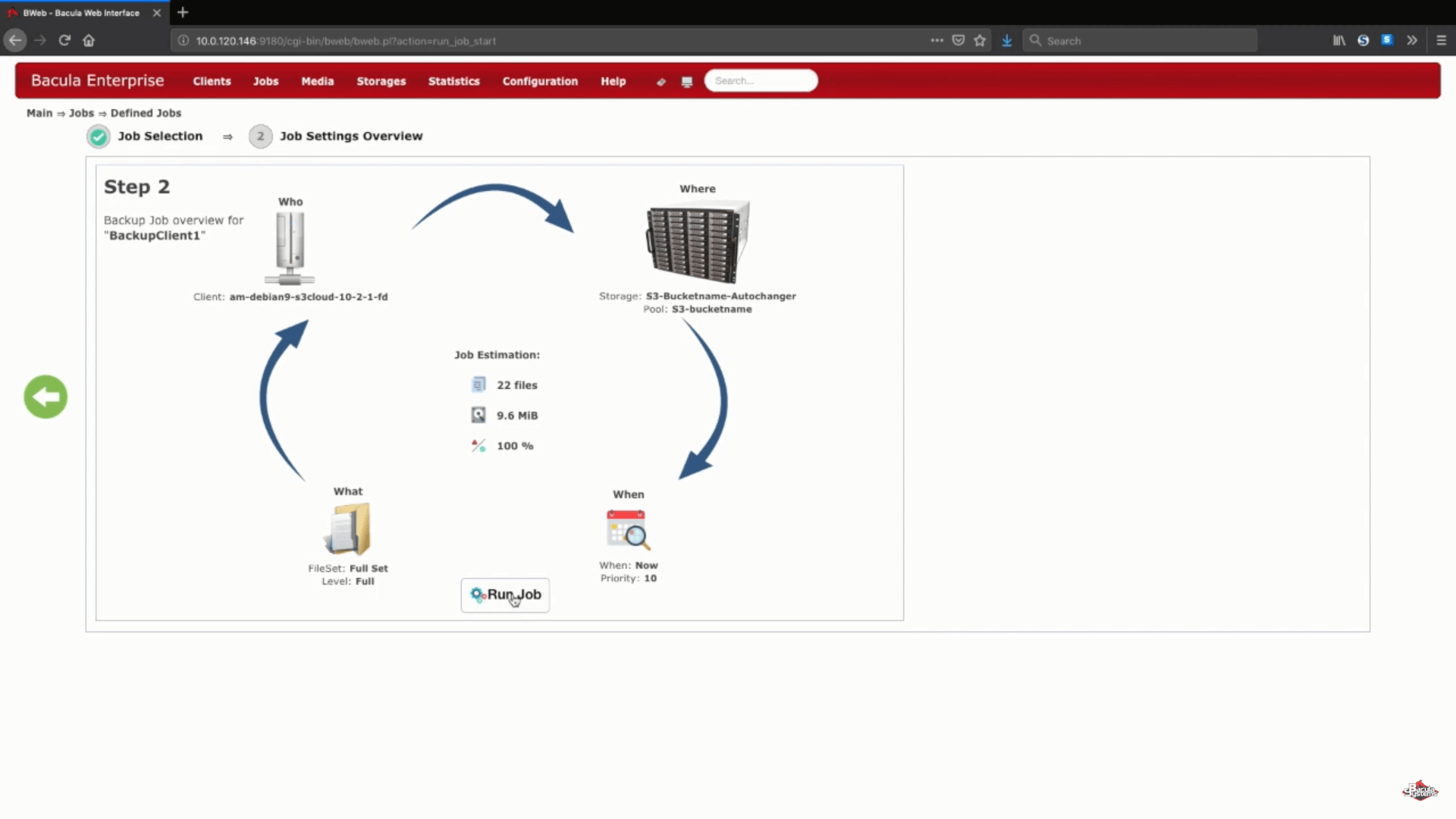
Nachdem der Job gelaufen ist, können wir die Protokolle des gesamten Prozesses sehen, und dieser spezielle Abschnitt (auf dem Screenshot unten) zeigt uns, dass alles korrekt hochgeladen wurde.
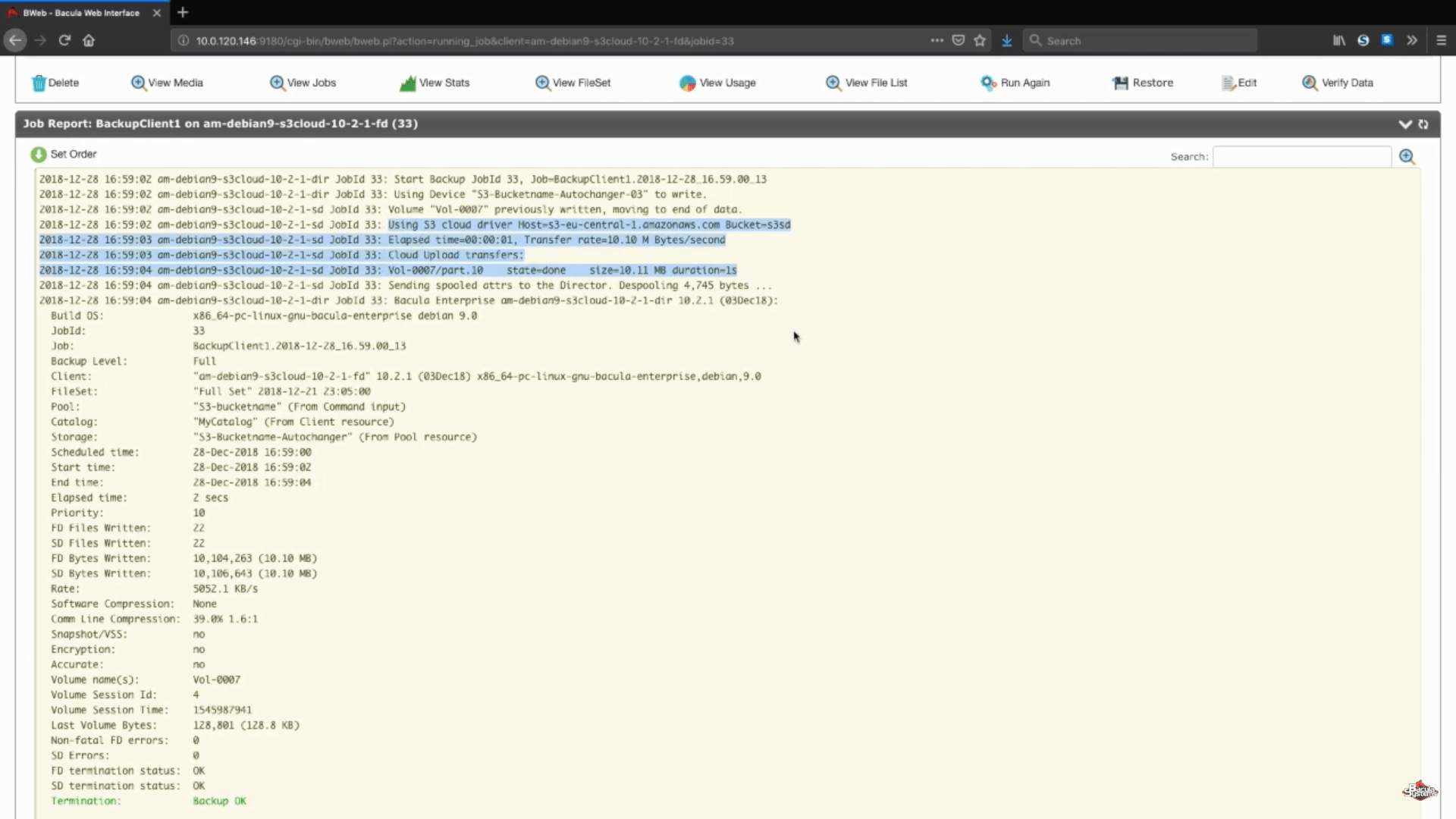
Fazit
Bacula Enterprise ist eine gute Wahl für die zuverlässige Verwaltung Ihrer AWS S3- und anderer Cloud-Sicherungen, einschließlich der Erstellung und Konfiguration neuerer Sicherungsspeicher und der Einrichtung von Sicherungsaufträgen, die automatisch ausgeführt werden sollen. Außerdem verfügt es über erweiterte Konfigurations- und Anpassungsmöglichkeiten in Kombination mit hochmodernen und aktuellen Anti-Ransomware-Funktionen.

