Contents
- Utilizar AWS Backup para crear copias de seguridad
- AWS Backup y su interacción con otros servicios basados en AWS
- Respaldo de AWS y EC2
- Actualización de 2022
- Operaciones básicas con la consola de Amazon S3
- Otros métodos para hacer copias de seguridad de su cubo de Amazon S3
- Versión y replicación de cubos
- Soluciones de copia de seguridad de AWS S3 de nivel empresarial con costes de restauración mínimos.
- Respaldo de AWS S3 con Bacula Enterprise
- Añadir un nuevo almacenamiento S3 en Bacula Enterprise
- Configuración de la copia de seguridad del almacenamiento de AWS S3 con Bacula Enterprise
- Finalizando el proceso de configuración del almacenamiento S3
- Guardar la nueva configuración de la copia de seguridad en S3
- Probando la configuración de la copia de seguridad de AWS
- Conclusión
Utilizar AWS Backup para crear copias de seguridad
Hacer copias de seguridad de su información -datos- es quizá la parte más importante para protegerla de cualquier daño, así como para garantizar la conformidad. Incluso los servidores y almacenamientos más duraderos son susceptibles de sufrir fallos, errores humanos y otras posibles razones para un desastre. Sin embargo, crear y gestionar todos los flujos de trabajo de las copias de seguridad puede ser una tarea desalentadora en general. Por lo tanto, hay una variedad de métodos que puede utilizar para simplificar todo el proceso de creación de una copia de seguridad mientras utiliza AWS S3.
Una opción popular es la propia solución de copias de seguridad de Amazon: AWS Backup. La copia de seguridad de AWS puede proporcionar una forma de gestionar sus copias de seguridad tanto en la nube de AWS como en las instalaciones, así como soportar una variedad de otras aplicaciones de Amazon.
El proceso de copia de seguridad en sí es bastante sencillo. Un usuario tendría que crear una política de copias de seguridad -su plan de copias de seguridad- especificando una serie de parámetros como la frecuencia de las copias de seguridad, la cantidad de tiempo que éstas deben mantenerse, etc. Tan pronto como se configure la política, AWS Backup debería comenzar a realizar copias de seguridad de sus datos automáticamente. Después podrá utilizar la consola de AWS Backup para ver sus recursos respaldados, tener la opción de restaurar una copia de seguridad específica o simplemente supervisar su actividad de copia de seguridad y restauración.
AWS Backup y su interacción con otros servicios basados en AWS
Hay un montón de diferentes servicios de AWS que pueden ofrecer varias características útiles y trabajar en conjunto con el servicio de AWS Backup. Por ejemplo, estos servicios incluyen, pero no exclusivamente:
- Amazon EBS (Elastic block store);
- Amazon RDS (Servicio de base de datos relacional);
- Copias de seguridad de DynamoDB de Amazon;
- Las instantáneas de la pasarela de almacenamiento de AWS, etc.
Por supuesto, tiene que habilitar el servicio específico que desea utilizar en su proceso de copia de seguridad antes de utilizarlo en primer lugar. Si intenta iniciar o crear la copia de seguridad utilizando recursos específicos de un servicio que aún no ha habilitado, probablemente recibirá un mensaje de error en su lugar y no podrá realizar el proceso de creación.
Para encontrar la lista de servicios que puede activar o desactivar, tiene que seguir una serie de pasos:
- Abra la consola de copias de seguridad de AWS.
- Entre en el menú «Settings».
- Desplácese a la página «Service opt-in» y haga clic en «Configure resources».
Esto debería llevarle a la página con una serie de nombres de servicios y conmutadores, y podrá activar o desactivar fácilmente cada uno de los servicios específicos. Al hacer clic en «Confirm» después de realizar los cambios, se guardarán las operaciones.
Respaldo de AWS y EC2
El backup de AWS es capaz de implementar muchas de las capacidades de los servicios de AWS existentes en el proceso de creación de un backup. Un buen ejemplo de ello es la capacidad de creación de instantáneas de EBS, que se utiliza para crear copias de seguridad de acuerdo con el plan de copias de seguridad que se haya creado. La creación de instantáneas de EBS, por otra parte, puede realizarse mediante la API de EC2 (Elastic compute cloud). De este modo, podrá gestionar sus copias de seguridad desde una consola centralizada de copias de seguridad de AWS, supervisarlas, programar diferentes operaciones, etc.
El backup de AWS puede realizar trabajos de backup en instancias EC2 completas, lo que le permite tener menos necesidad de interactuar con la propia capa de almacenamiento. Su funcionamiento también es bastante sencillo: el backup de AWS toma una instantánea del volumen de almacenamiento EBS raíz, así como de los volúmenes asociados y las configuraciones de lanzamiento. Todos los datos se almacenan en un formato de imagen específico denominado AMI (imagen de máquina de Amazon) con respaldo de volumen.
Los archivos de copia de seguridad de AMI de EC2 también se pueden cifrar en el proceso de copia de seguridad de la misma manera que la copia de seguridad de AWS lo hace con las instantáneas de EBS. Puede utilizar la clave KMS por defecto si no tiene una, o puede utilizar la suya propia para aplicarla a la copia de seguridad.
Este proceso es muy superior y más fácil de personalizar que la forma incorporada de AWS EC2 para respaldar y restaurar los datos. Por ejemplo, el proceso de copia de seguridad para EC2 crea originalmente una instantánea del volumen, que requiere poca o ninguna configuración, y eso es todo. Se puede hacer dentro de la consola de Amazon EC2 en «Snapshots > Create Snapshot > *elegir el volumen en cuestión* > Create».
El proceso de restauración de los recursos EC2 puede realizarse de varias maneras: La consola de backup de AWS, la línea de comandos o simplemente la API. En comparación con los otros dos, la consola de copia de seguridad tiene muchos límites de funcionalidad para el proceso de restauración y no puede restaurar varios parámetros como direcciones ipv6, algunos ID específicos, etc. Los otros dos métodos, en cambio, son capaces de hacer una restauración completa de una u otra manera.
También es posible restaurar volúmenes EBS a partir de una instantánea. Sin embargo, este proceso es un poco más complicado e incluye dos partes: restaurar un volumen a partir de una instantánea y adjuntar un nuevo volumen a una instancia.
La restauración de volúmenes es bastante sencilla y puede realizarse dentro de la página de EC2 yendo a ELASTIC BLOCK STORE, Snapshots > *seleccionar la instantánea en cuestión* > Create Volume. Adjuntar un volumen recién restaurado a una instancia, por otro lado, es un proceso ligeramente diferente que puede realizar yendo a Volumes > Actions > Attach Volume > *elegir el volumen por nombre o por ID* > Attach. También se recomienda mantener el nombre del dispositivo sugerido durante todo este proceso.
Actualización de 2022
Desde principios de 2022, AWS Backup ha añadido otro de sus servicios con el que puede trabajar: Amazon Simple Storage Service (S3). El mundo moderno tiene muchas necesidades y posibilidades en lo que respecta a las opciones de almacenamiento, y es bastante normal depender de varios lugares o servicios de almacenamiento diferentes a la vez.
Este tipo de integración permite a AWS Backup proteger y gobernar los datos de S3, al igual que hace con otros servicios de Amazon. Hay tres ventajas principales a la hora de utilizar la integración entre AWS Backup y Amazon S3:
- Mejor cumplimiento de la normativa, con los cuadros de mando incorporados;
- Proceso de restauración más sencillo con procesos de restauración puntuales;
- Una gestión de copias de seguridad centralizada más cómoda, que hace que el control del ciclo de vida de las copias de seguridad sea mucho más fácil de trabajar.
En el momento de escribir este artículo, AWS Backup para S3 es una vista previa, pero ya puede ofrecer la funcionalidad básica de backups: backups puntuales, backups periódicos, restauraciones, etc. También puede automatizarse por completo mediante AWS Organizations.
Operaciones básicas con la consola de Amazon S3
El propio conjunto de herramientas de S3 de Amazon permite realizar algunas operaciones básicas cuando se trata de recuperar o almacenar un archivo específico del bucket. Es posible señalar cuatro operaciones diferentes que se pueden realizar utilizando únicamente el software de copia de seguridad de Amazon S3 – pero tenemos que llegar a la consola de Amazon S3, primero.
Se puede hacer accediendo a la página de servicios de AWS mediante este enlace, introduciendo su información de acceso debería permitirle acceder a la primera pantalla del conjunto de herramientas de servicios de AWS. Después es posible encontrar la consola de S3 dirigiéndose al menú «Servicios» y encontrando allí S3, o escribiendo «S3» en la barra de búsqueda situada en la parte superior de la página.
- Creación de un cubo S3.
- Un cubo es un tipo de contenedor que Amazon S3 utiliza para almacenar sus archivos. Se puede crear un cubo en la interfaz de AWS S3 haciendo clic en el botón «Create Bucket» en la pantalla de título.
- Cabe destacar que la página web tendrá un aspecto diferente dependiendo de si ya ha creado un cubo antes dentro de esta cuenta o no. Si hay otros cubos ya creados, se encontrará con una pantalla que le permitirá gestionar dichos cubos, incluyendo el cambio de nombre o la eliminación directa de los mismos.
- Por otro lado, si es la primera vez que crea un cubo dentro de esta cuenta de copia de seguridad de AWS S3, verá una pantalla correspondiente que describe la forma de crear un cubo en primer lugar. Si esto ocurre, puede utilizar el botón «Create bucket» o el botón «Get started», ambos deberían llevar al mismo lugar: la pantalla de creación de cubos.
- El primer aviso de la pantalla debería ser sobre la creación de un nombre para su nuevo cubo, y el campo también le notificaría si el nombre del cubo no cumple con algunas de las regulaciones propias de Amazon relacionadas con el nombre del cubo. También tendrá que elegir una región adecuada para su futuro cubo. Una vez hecho esto, haga clic en «Next» para continuar.
- La segunda pantalla de creación de cubos le permite habilitar una de las propiedades de su cubo de copia de seguridad de Amazon S3, como Etiquetas, Versionado, Cifrado, Registro de acceso al servidor y Registro a nivel de objeto. Con el propósito de mantener esta explicación simple, no vamos a habilitar ninguna de estas propiedades. Haga clic en «Next» para continuar.
- La siguiente pantalla permite personalizar los permisos, incluyendo tanto los del sistema como los de los usuarios. También puede cambiar sus propios niveles de permiso y añadir personas específicas para que tengan acceso a este cubo. Nuestro ejemplo mantiene todos los niveles de permiso por defecto – con el creador teniendo acceso a cualquier cosa dentro de este cubo. Haga clic en «Next» cuando haya terminado.
- La última parte del proceso es la pantalla de confirmación, que le permite revisar todos los ajustes que ha configurado previamente. Esto incluye los permisos, las propiedades y los nombres. Al hacer clic en el botón «Create bucket» después de terminar el proceso de revisión, se hace exactamente lo que dice: se crea un cubo con su configuración específica.
- Carga de un archivo.
- Subir un archivo a su nuevo cubo de AWS S3 también es relativamente fácil, si lo hace desde la consola de Amazon S3. Haciendo clic en el nombre de su nuevo bucket de AWS podrá acceder a dicho cubo y a su contenido.
- En cuanto se encuentre en la página de aterrizaje de su cubo, puede iniciar el proceso de carga haciendo clic en el botón «Upload» en la parte izquierda de la página.
- Hay dos maneras de cargar un archivo en la siguiente ventana: arrastrando y soltando un archivo en la página, o haciendo clic en el botón «Add files» y seleccionando el archivo en cuestión después. Una vez que haya elegido el archivo que desea cargar, puede hacer clic en «Next» para continuar.
- Al igual que en el proceso de creación de la copia de seguridad del cubo de S3, puede cambiar los permisos del archivo antes de subirlo, incluyendo tanto sus propios permisos, las cuentas que tienen acceso a este archivo y los permisos públicos. Utilice el botón «Next» para continuar.
- La siguiente página trata más sobre las propiedades específicas de su archivo, como la clase de almacenamiento (Estándar, Estándar-IA y Reducción de la redundancia), el cifrado (Ninguno, Clave maestra de S3 y Clave maestra de KMS) y los metadatos. Una vez que haya elegido una de las opciones, puede continuar a través del botón «Next».
- La última pantalla de esta secuencia consiste en confirmar todos sus cambios antes de subirlos. Aquí se desplazan las propiedades, los permisos y la cantidad de archivos elegidos. Al hacer clic en el botón «Upload» después de comprobar los detalles, debería comenzar el proceso de carga.
- Recuperación de un archivo.
- La descarga de un archivo de su cubo de AWS S3 puede realizarse en dos sencillos pasos. En primer lugar, tiene que estar en la página de aterrizaje de su cubo, en la que verá todos los archivos que están almacenados en dicho cubo. El primer paso que tendrá que realizar es hacer clic en el campo de la marca de verificación a la izquierda del archivo que desea descargar
- Al seleccionar al menos un archivo de la lista aparece una ventana emergente de descripción, que tiene dos botones: «Download» y «Copy path». Utilice el botón «Download» para recibir el archivo en cuestión.
- Borrar un archivo o un cubo.
- Eliminar archivos o incluso cubos innecesarios no sólo es fácil, sino que también es muy recomendado por la propia Amazon para evitar el desorden excesivo de sus archivos. En primer lugar, el proceso de eliminación de archivos.
- En cuanto llegue a la página de inicio de un cubo, lo primero que tiene que hacer es pulsar el campo de la casilla de verificación situado a la izquierda del archivo que desea eliminar.
- Después de elegir el archivo o los archivos que desea eliminar, puede pulsar el botón «More» situado cerca de los botones «Upload» y «Create Folder» y elegir la opción «Delete» de la lista desplegable.
- Recibirá una pantalla de confirmación que le mostrará los archivos que se eliminarán, y tendrá que hacer clic en «Delete» una vez más para iniciar el proceso de eliminación.
- El proceso de eliminación de un bucket completo es ligeramente diferente. En primer lugar, tendrá que salir de la página de aterrizaje de su cubo y volver a la consola principal de copias de seguridad de Amazon S3 que enumera todos sus cubos.
- Al hacer clic en el espacio en blanco a la derecha del cubo que desea eliminar, se seleccionaría el cubo y al hacer clic en el botón «Delete bucket» se iniciaría el proceso de eliminación.
Cabe destacar que todas estas operaciones básicas podrían realizarse sólo con el propio sistema de Amazon y sin añadir ninguna solución de copia de seguridad de AWS.
Otros métodos para hacer copias de seguridad de su cubo de Amazon S3
El uso de AWS Backup no es la única opción cuando se trata de copias de seguridad en S3. Hay una variedad de opciones diferentes que pueden ser realizadas tanto por una aplicación dentro del ecosistema de Amazon como por soluciones de terceros.
Por ejemplo, aquí hay varias formas más de crear una copia de seguridad de S3 sin utilizar la aplicación AWS Backup:
- Crear copias de seguridad utilizando Amazon Glacier;
- Utilizar el SDK de AWS para copiar un bucket de S3 a otro;
- Copie la información en el servidor de producción del que se hace una copia de seguridad;
- Utilice el versionado como servicio de copia de seguridad.
Cabe mencionar que la mayoría de estos métodos no son precisamente rápidos o convenientes. Amazon Glacier, por ejemplo, sería una buena solución de copia de seguridad si no fuera mucho más lenta que su proceso de copia de seguridad habitual, ya que Glacier se ocupa más de archivar datos y menos de realizar copias de seguridad continuas.
Versión y replicación de cubos
El versionado es un tema que merece ser profundizado. El versionado de objetos es una característica de Amazon S3 que permite la protección de los datos frente a una serie de cambios no deseados, como la eliminación, la corrupción, etc.; funciona creando una nueva copia de un archivo cada vez que este archivo en particular se modifica de alguna manera (cuando se almacena en S3).
El cubo de S3 almacena todas estas versiones diferentes del mismo archivo, lo que le da la posibilidad tanto de acceder como de restaurar cualquiera de estas versiones anteriores. Esto puede incluso contrarrestar a veces el borrado, ya que la eliminación de una versión actual del archivo no suele afectar a sus versiones anteriores.
Merece la pena tener en cuenta que el uso del versionado como solución de copia de seguridad puede aumentar significativamente sus costes de almacenamiento debido a las cantidades de datos que hay que guardar. En este caso, es posible que desee configurar su política de ciclo de vida para las versiones anteriores de los archivos, de modo que las copias más nuevas puedan sustituir a las más antiguas, haciendo del versionado una solución globalmente más rentable.
El versionado de S3 se puede habilitar mediante la consola de administración de AWS yendo a Services > S3 (En la categoría «Storage») > Buckets > bucket_name. Cada cubo tiene un montón de diferentes opciones personalizables que están separadas en múltiples pestañas. Buscamos una pestaña llamada «Properties».
El versionado de cubos es una de las primeras opciones que aparecen en la pestaña «Properties». Aunque está desactivado por defecto, todo lo que tiene que hacer para activarlo es seleccionar «Edit» en la opción «Bucket Versioning», y cambiar «Bucket Versioning» en la siguiente ventana de «Suspend» a «Enable».
Puede notar que al habilitar el versionado de cubos aparece un consejo útil que le indica que debe actualizar sus reglas de ciclo de vida para configurar el versionado como un proceso de la manera correcta. Las reglas del ciclo de vida pueden modificarse en la pestaña «Management» dentro del mismo menú de detalles del cubo.
En primer lugar, tiene que crear una regla de ciclo de vida (botón «Create lifecycle rule») – tendrá que introducir un nombre y elegir el alcance de la función (puede aplicarse a todo el cubo o a archivos específicos elegidos con filtros).
También puede personalizar la forma en que se comporta esta regla en primer lugar utilizando la parte «Lifecycle rule actions» de este menú. Aquí puede configurar una serie de reglas que afectan a las versiones actuales y anteriores de los archivos, así como los requisitos previos para la expiración de la versión (con su posterior eliminación). Una vez configurado todo, sólo tiene que hacer clic en «Create Rule» para que se genere y aplique la regla del ciclo de vida.
Aunque el versionado puede ser estupendo para trabajar con archivos específicos, puede no ser una opción viable cuando hay demasiados archivos de los que se conservan versiones anteriores. Por suerte, el versionado no es la única alternativa en este caso, ya que también existe la replicación de cubos.
Esta opción se encuentra dentro del mismo menú que antes; otra categoría bajo las «Lifecycle rules» llamada «Replication rules». Al hacer clic en «Create replication rule» se le abrirá una nueva página con una serie de ajustes para la futura regla de replicación de cubos.
Aquí puede cambiar el nombre de una regla, definir el estado de la regla en el momento de la creación (si se activaría o desactivaría desde el principio), seleccionar un cubo de destino para replicar y un cubo de destino para almacenar la copia del original. Las opciones adicionales de esta página incluyen el control del tiempo de replicación, la sincronización de la modificación de la réplica, varias métricas de replicación y mucho más.
Esta opción tampoco es perfecta, ya que implica copiar la totalidad de un cubo, lo que supone un aumento masivo de la cantidad de espacio de almacenamiento consumido. Dado que la mayoría de estas opciones tienen sus propios problemas y deficiencias, es posible que desee considerar una solución de terceros para sus necesidades de copia de seguridad y restauración en S3.
Hablando de soluciones de terceros, aunque hay muchas en el mercado, examinaremos una de las más prometedoras: la solución proporcionada por Bacula Enterprise.
Soluciones de copia de seguridad de AWS S3 de nivel empresarial con costes de restauración mínimos.
Bacula ofrece soluciones de copia de seguridad de AWS S3 integradas de forma nativa como parte de sus amplias opciones de copia de seguridad y recuperación basadas en la nube para empresas. Ofrece integración nativa con nubes públicas y privadas a través de la interfaz de Amazon S3, con soporte transparente para S3-IA. Las copias de seguridad de AWS S3 están disponibles para Linux, Windows y otras plataformas. Sin embargo, hay algo más que su organización debería saber sobre el backup de Amazon S3 con Bacula Enterprise: la posibilidad de tener un control único sobre su backup en la nube, y al mismo tiempo aportar una importante reducción de costes en la nube para las soluciones de backup de AWS.
Respaldo de AWS S3 con Bacula Enterprise
Para comenzar el proceso de copia de seguridad de AWS con Bacula, primero debe entrar en el modo de configuración. Después podrá ver varias opciones nuevas disponibles. Necesita la titulada «Add a New Storage Resource».
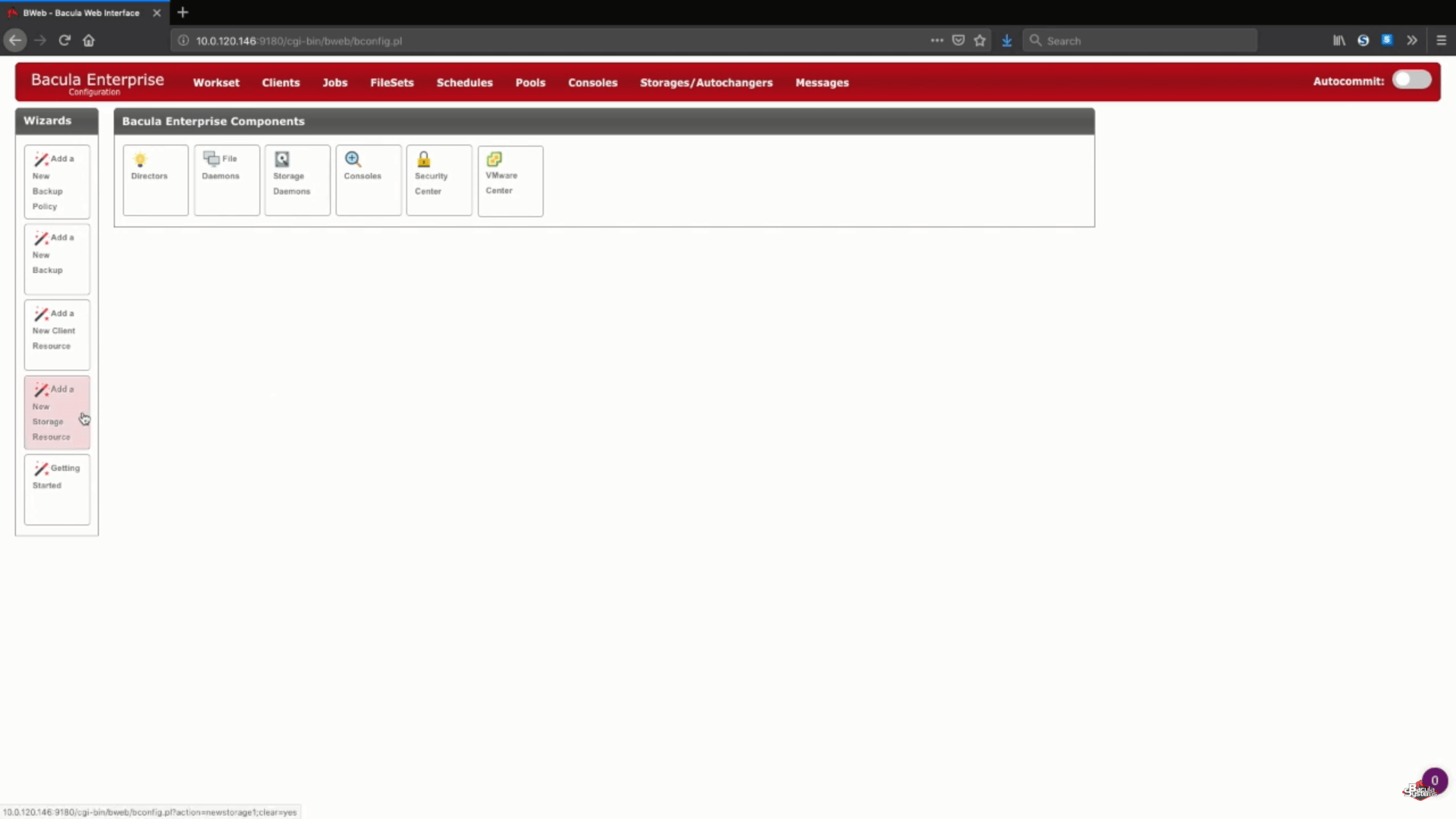
Añadir un nuevo almacenamiento S3 en Bacula Enterprise
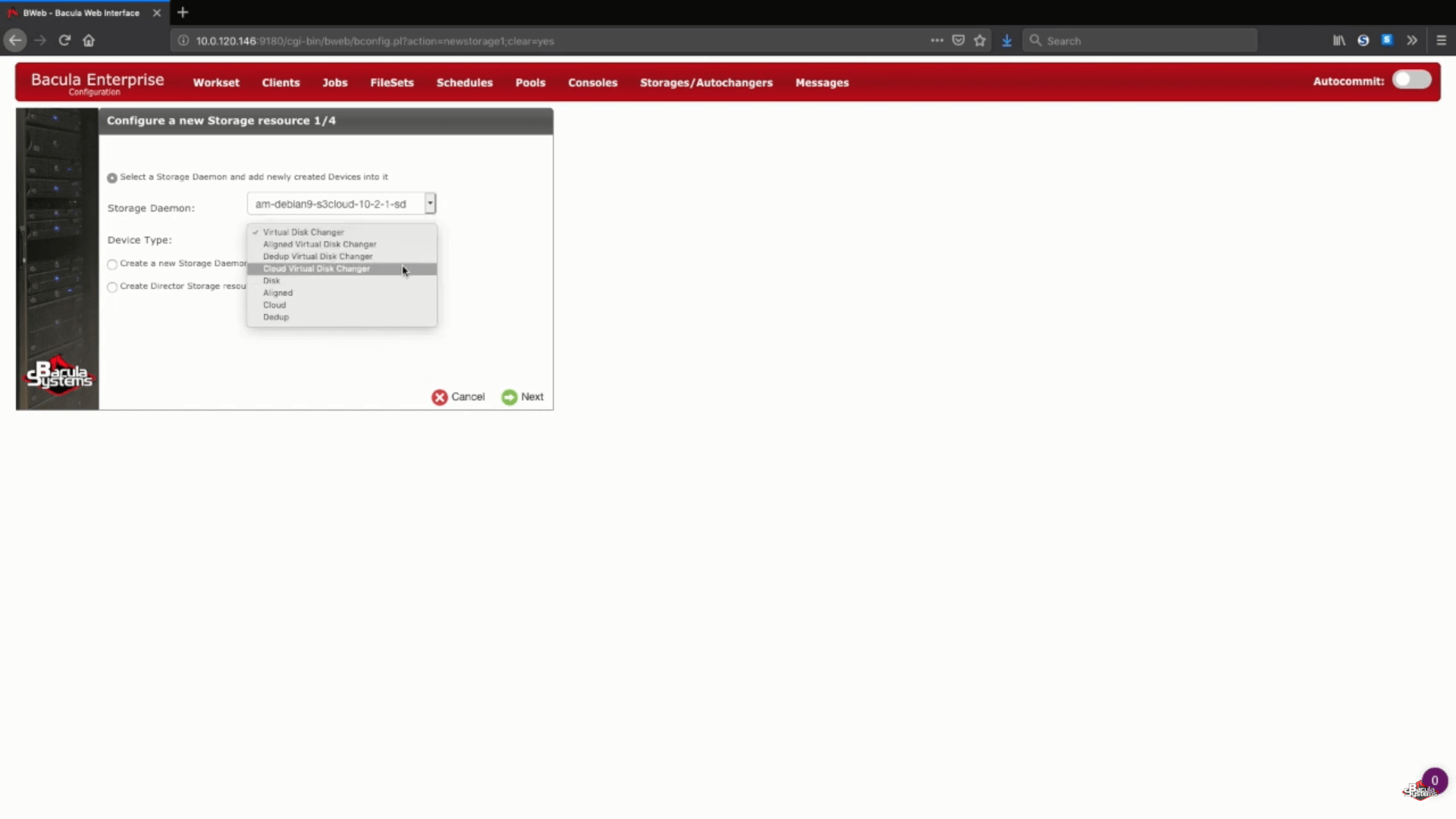
En este ejemplo concreto vamos a añadir un nuevo almacenamiento Amazon S3 a un Storage Daemon existente. También elegiremos el «Cloud Virtual Disk Changer» en el «Device Type» – este tipo de dispositivo permite realizar varias copias de seguridad simultáneas en el mismo almacenamiento en la nube.
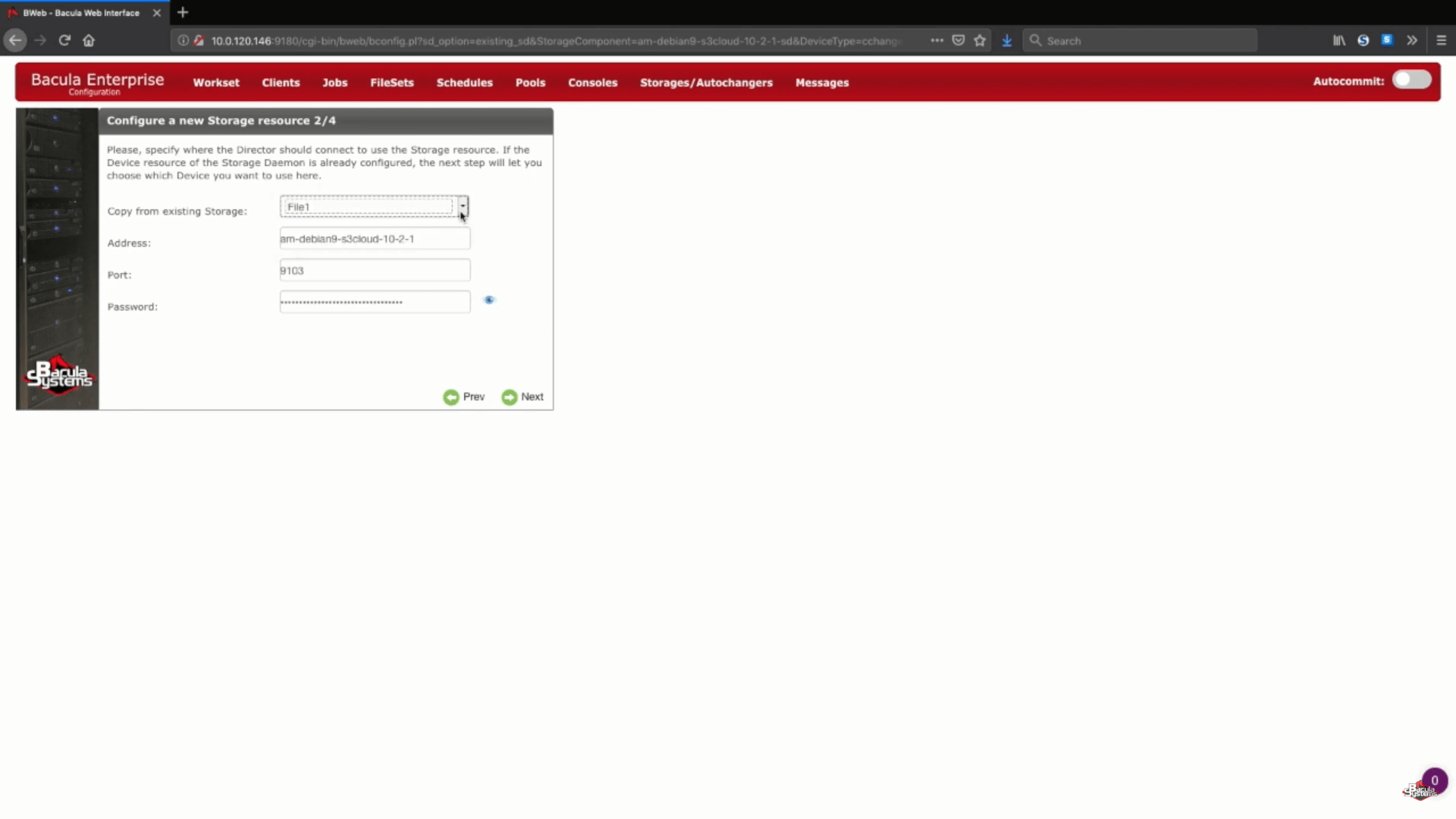
Dado que nuestro Storage Daemon ya existe, toda la información del paso 2 (Configuración de un nuevo recurso de almacenamiento) puede tomarse de los dispositivos previamente creados.
Configuración de la copia de seguridad del almacenamiento de AWS S3 con Bacula Enterprise
El siguiente paso del proceso de copia de seguridad de AWS es la configuración de la información de almacenamiento en la nube. En este ejemplo vamos a almacenar nuestros volúmenes de copia de seguridad en la caché de la nube, que se utiliza normalmente como una pequeña área temporal entre la carga de una copia de seguridad en la nube, pero todavía puede contener una semana o más de los datos para permitir las copias de seguridad locales para ese período, y las copias de seguridad en la nube si el período de tiempo es superior a una semana. Siempre puede ponerse en contacto con los expertos de soporte de Bacula para saber más sobre el tamaño de almacenamiento de la caché en la nube, la política de retención de la caché y el comportamiento de carga en la nube.
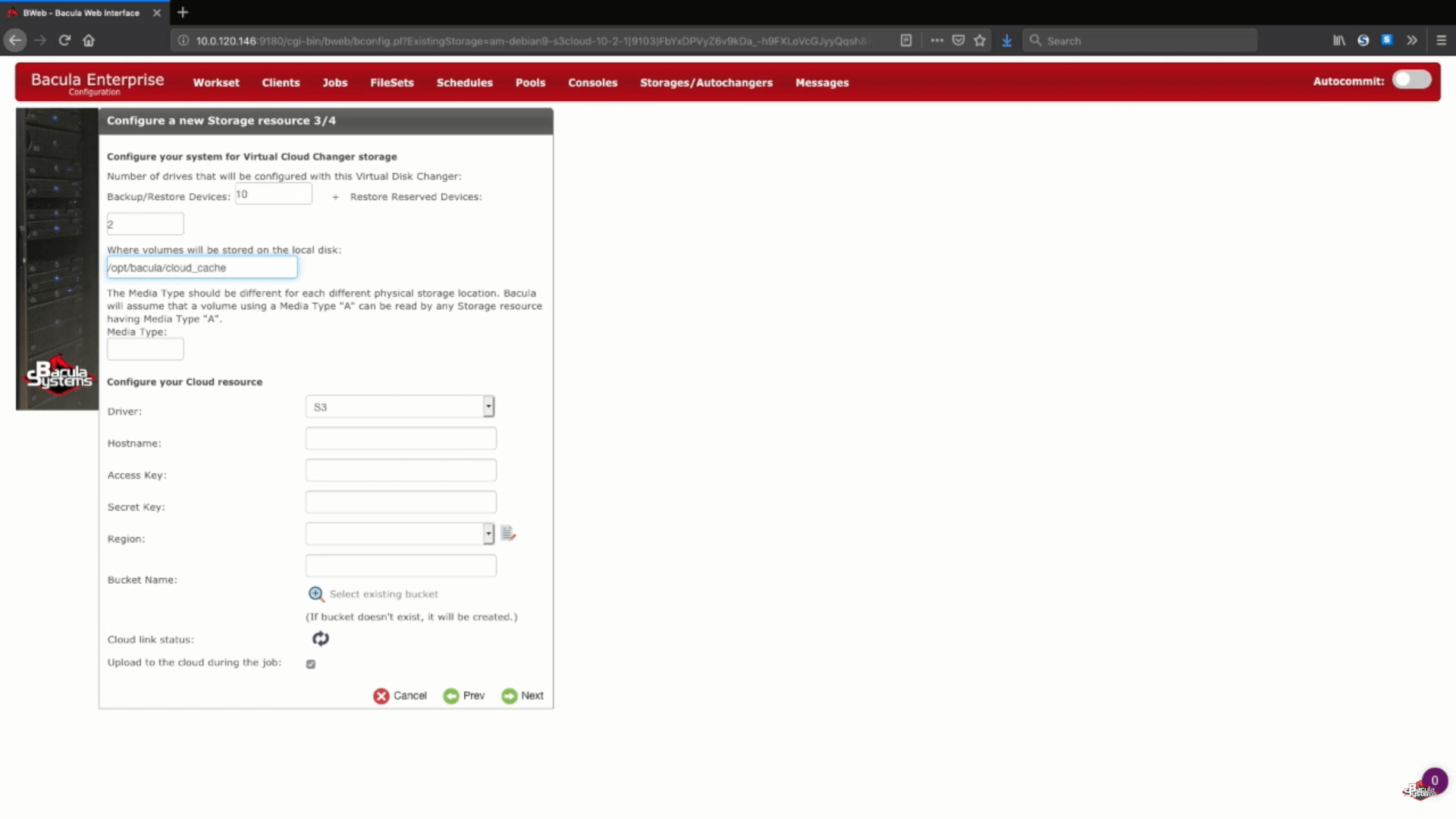
A continuación, elegiremos un tipo de medio único para nuestro nuevo dispositivo de almacenamiento, para facilitar que Bacula vea los archivos de este dispositivo de almacenamiento específico.
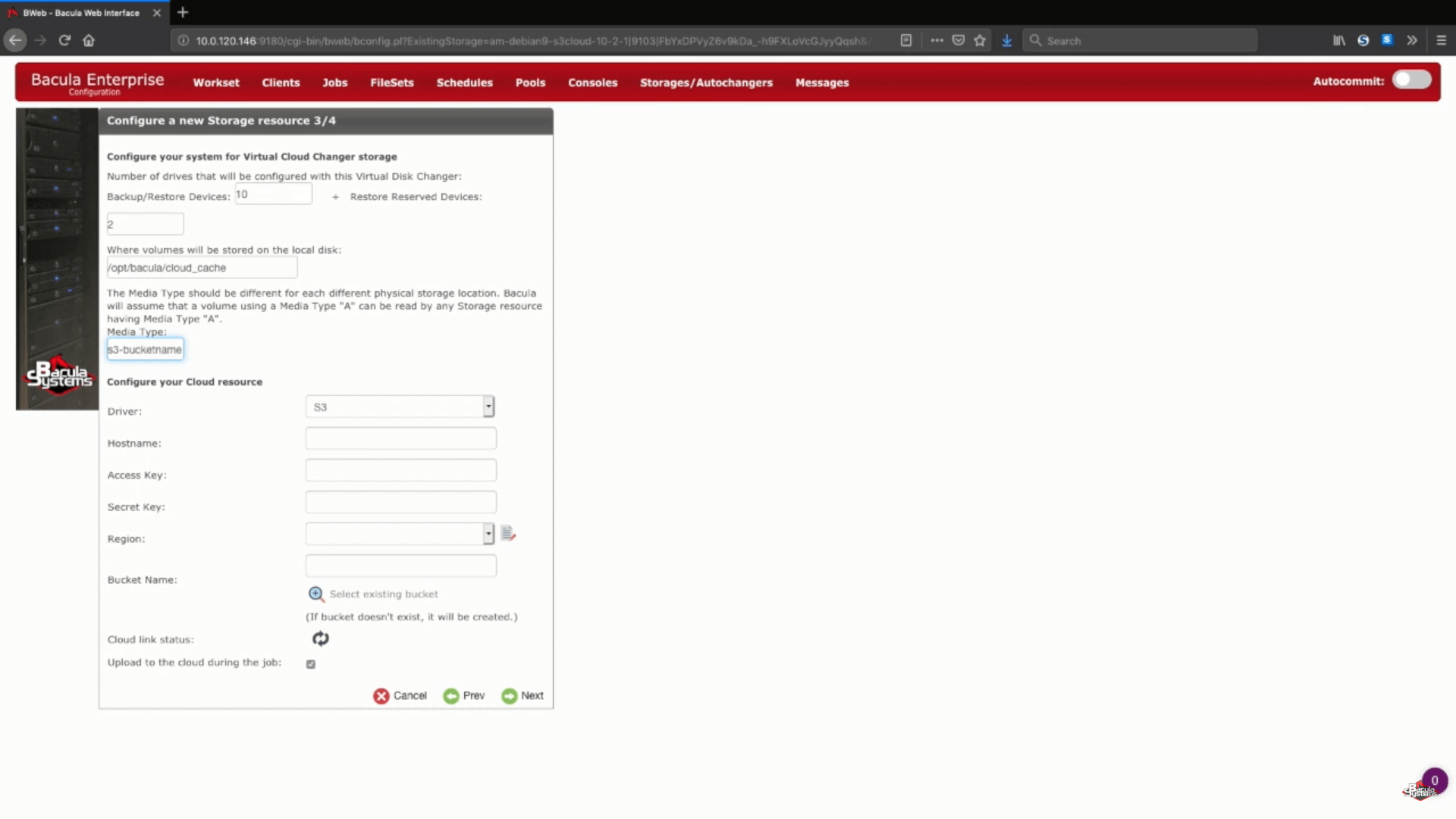
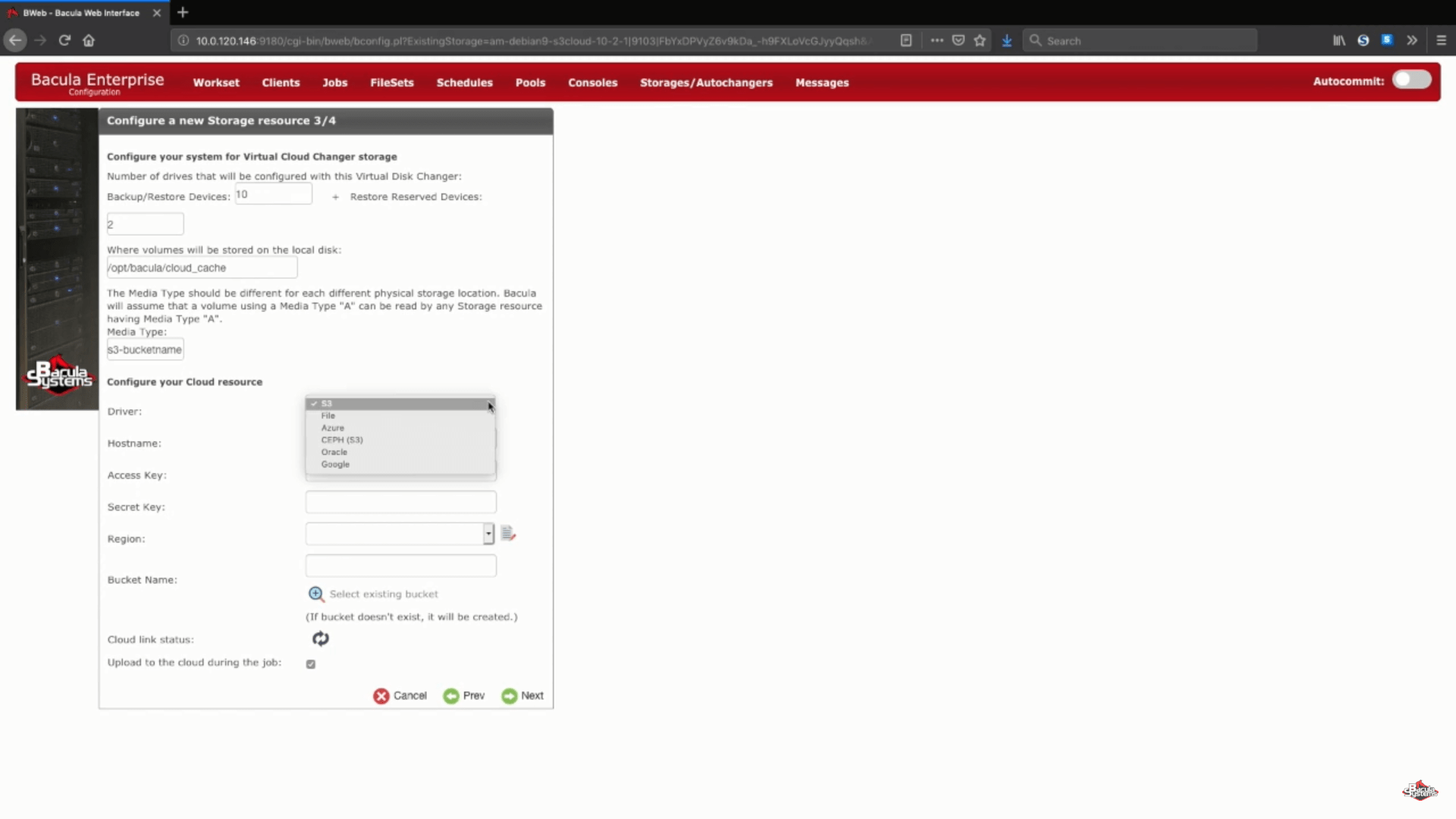
Una parte más de este paso es elegir su controlador de nube de AWS S3 de una lista de controladores de nube compatibles.
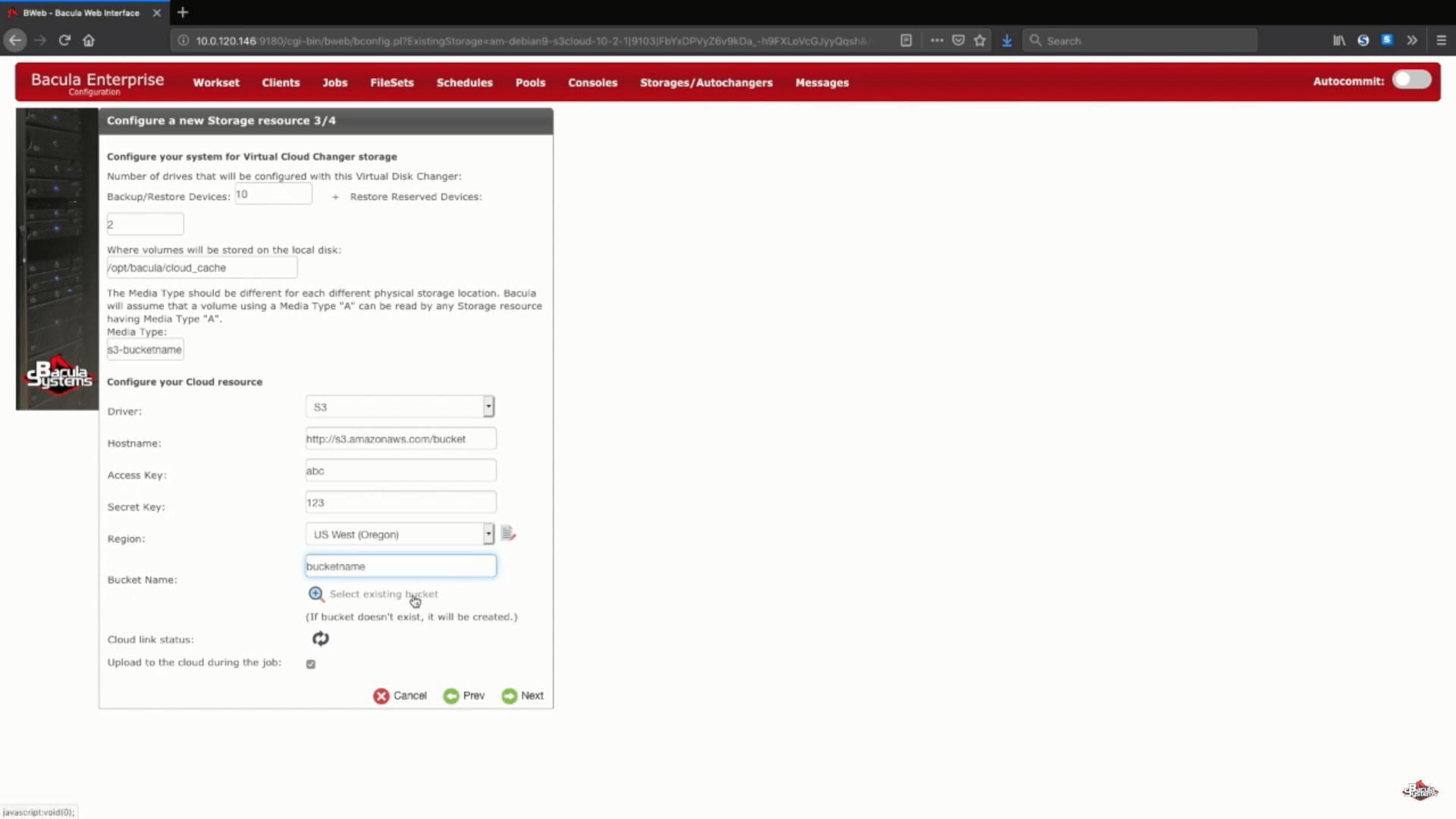
A continuación, configuramos una lista de información arbitraria como el nombre de host de la nube, la información de la cuenta, la región, etc. También podrá elegir entre elegir un cubo existente conectándose a su cuenta actual o introducir un nombre en la línea correspondiente para confirmar la creación de un nuevo cubo.
Finalizando el proceso de configuración del almacenamiento S3
Quedan dos opciones posibles: estado del enlace a la nube y «upload to the cloud during the job». El botón de estado de enlace a la nube le permite comprobar inmediatamente la conexión de su sistema actual con la nube que elija. «Upload to the cloud during the job» es una opción que se elige como parte de la configuración por defecto para subir sus datos de copia de seguridad a la nube tan pronto como estén listos (incluso en el proceso de un trabajo de copia de seguridad), pero también puede desactivar esta opción si desea subirlos después de que un trabajo haya terminado o con algún otro horario en mente.
El siguiente paso de este asistente es simplemente escribir el nombre de su almacenamiento preferido y una descripción opcional.
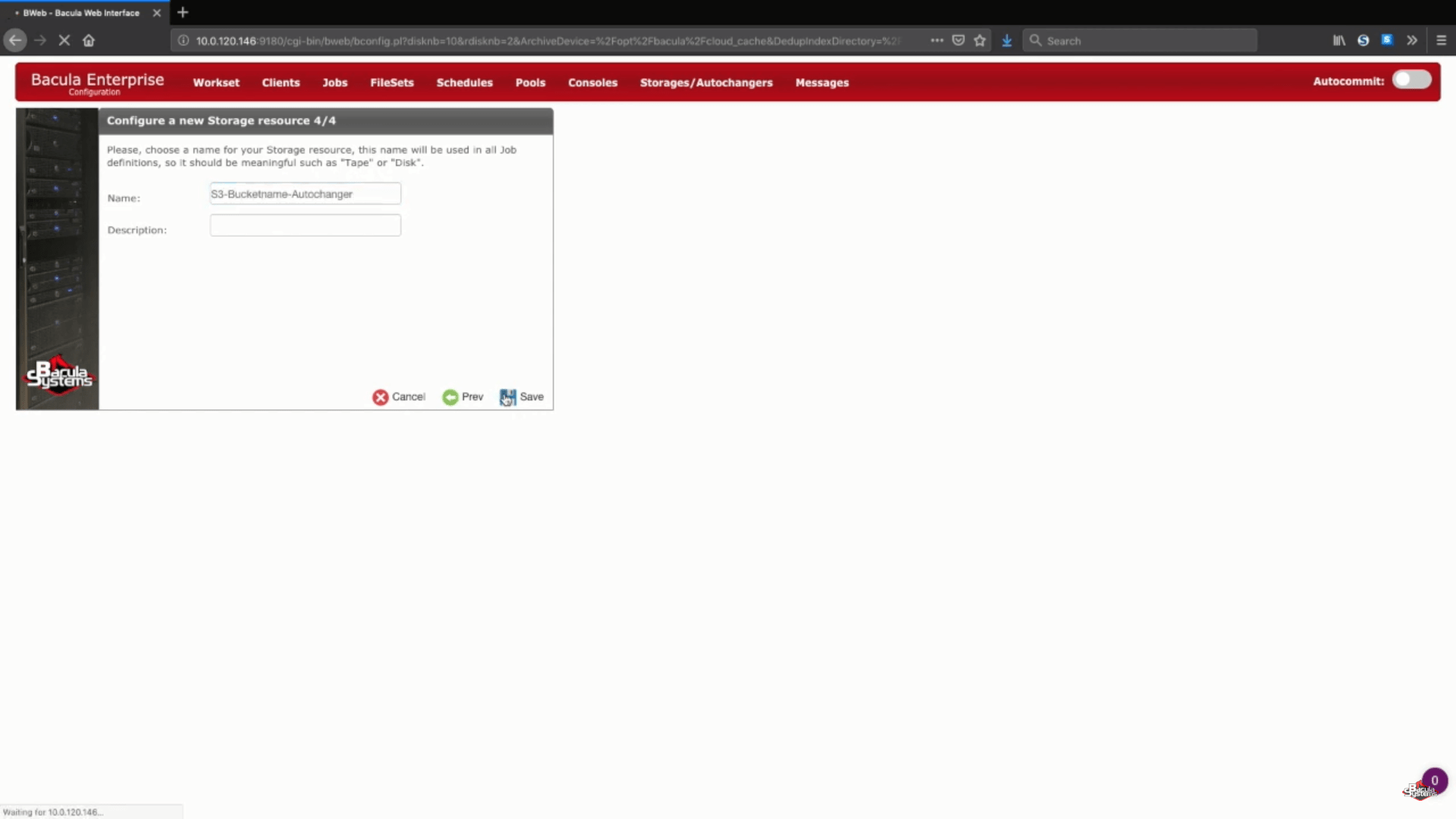
Guardar la nueva configuración de la copia de seguridad en S3
Después de este paso puede pulsar el botón «Save» para permitir que todos los cambios anteriores se comprometan a la producción. Tenga en cuenta que para confirmar correctamente todo a la producción tendrá que recargar su demonio de almacenamiento, lo que significa que cualquier trabajo que se esté ejecutando fallaría en el proceso.
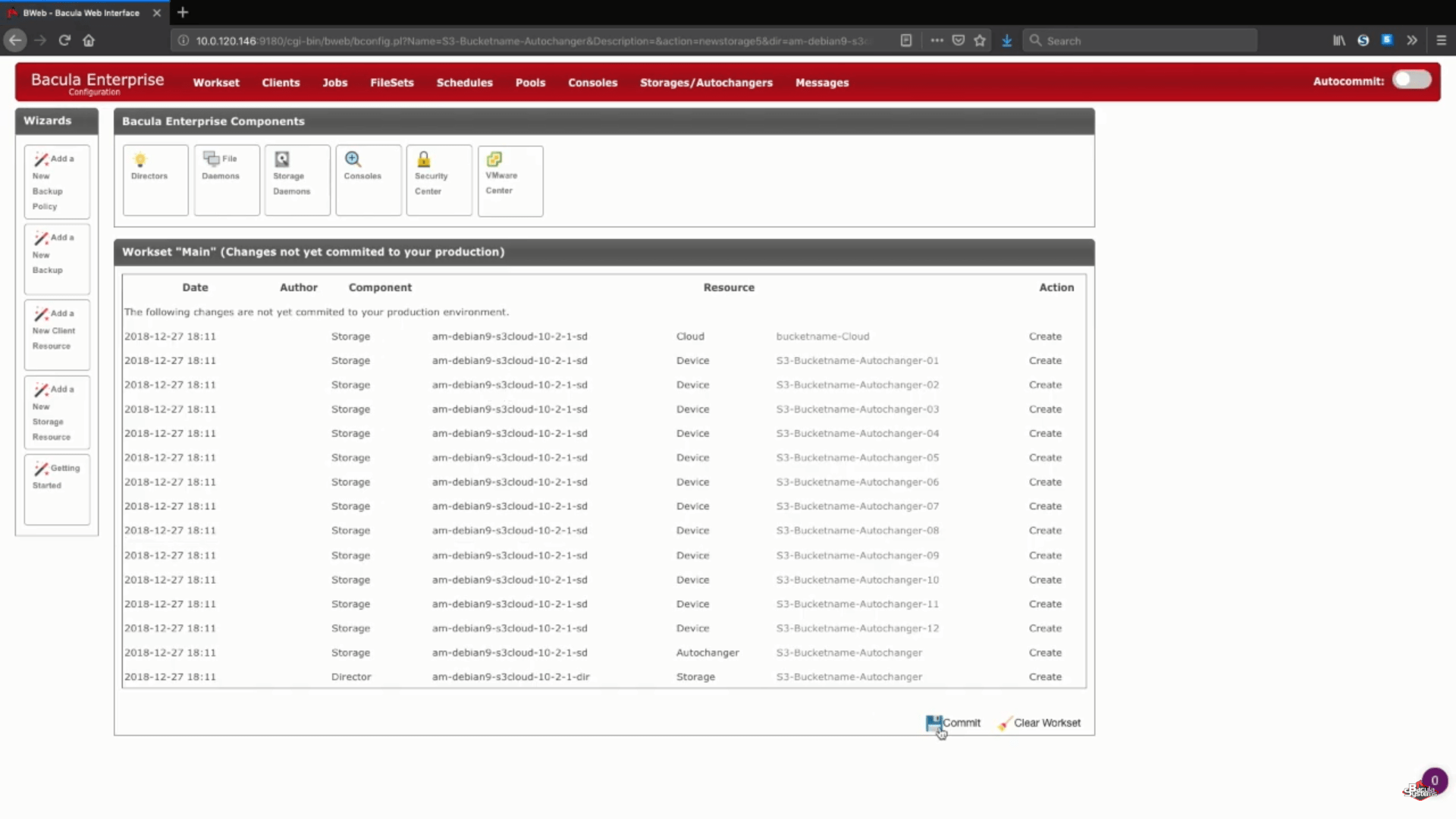
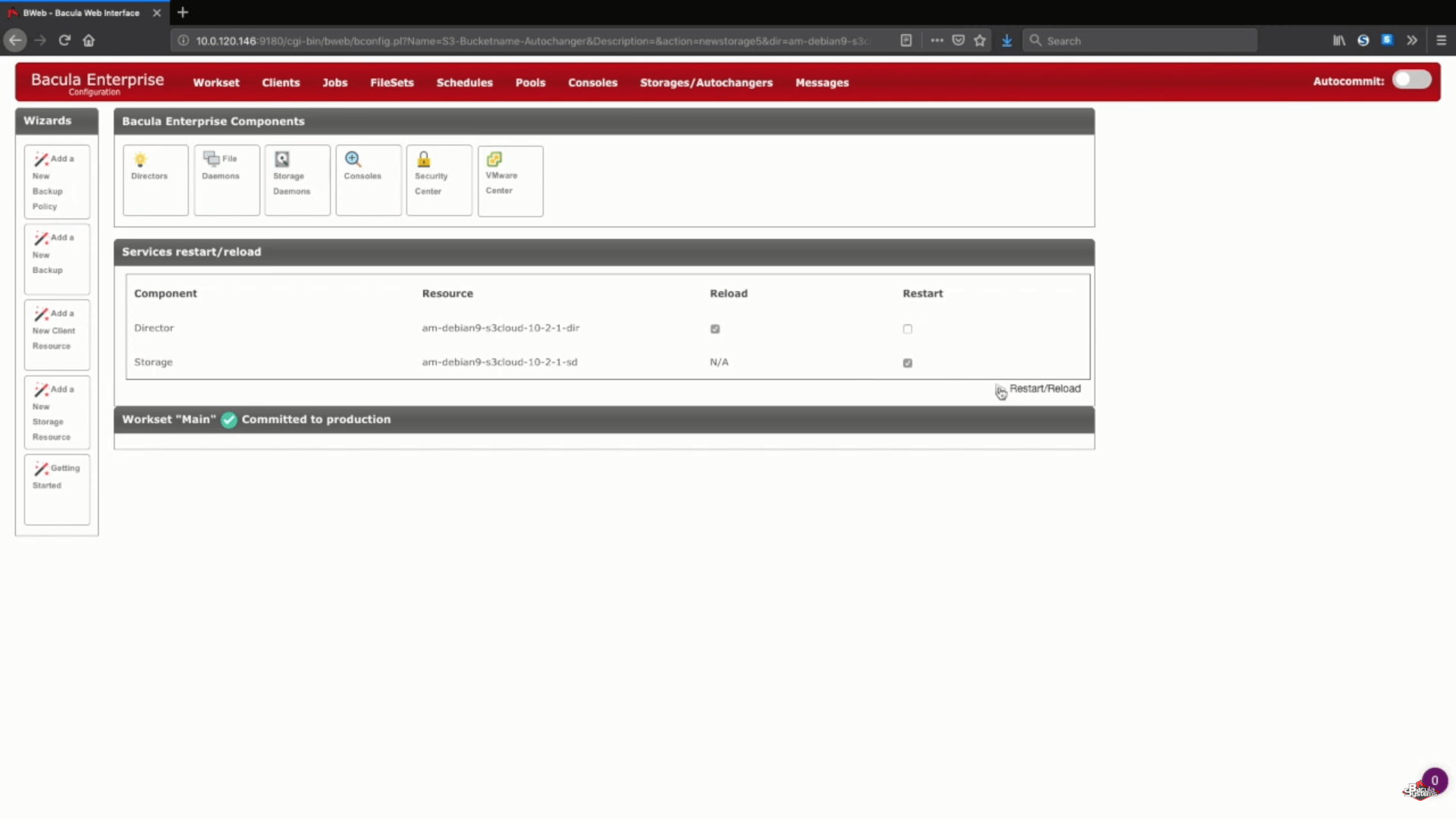
Un paso lógico después de esto sería configurar nuevos pools de copias de seguridad para este almacenamiento en la nube específico y configurar adecuadamente los trabajos para escribir datos en los nuevos pools. Puede dirigirse a la documentación de Bacula, ponerse en contacto con nuestro soporte o ver nuestro canal de YouTube para obtener ayuda respecto a estos pasos.
Probando la configuración de la copia de seguridad de AWS
Para probar que todo lo que acabamos de hacer funciona correctamente, ejecutaremos manualmente un pequeño trabajo de copia de seguridad completa de Amazon S3 directamente en el nuevo dispositivo de almacenamiento. Normalmente este proceso se automatiza utilizando una programación de trabajos y/o otras configuraciones.
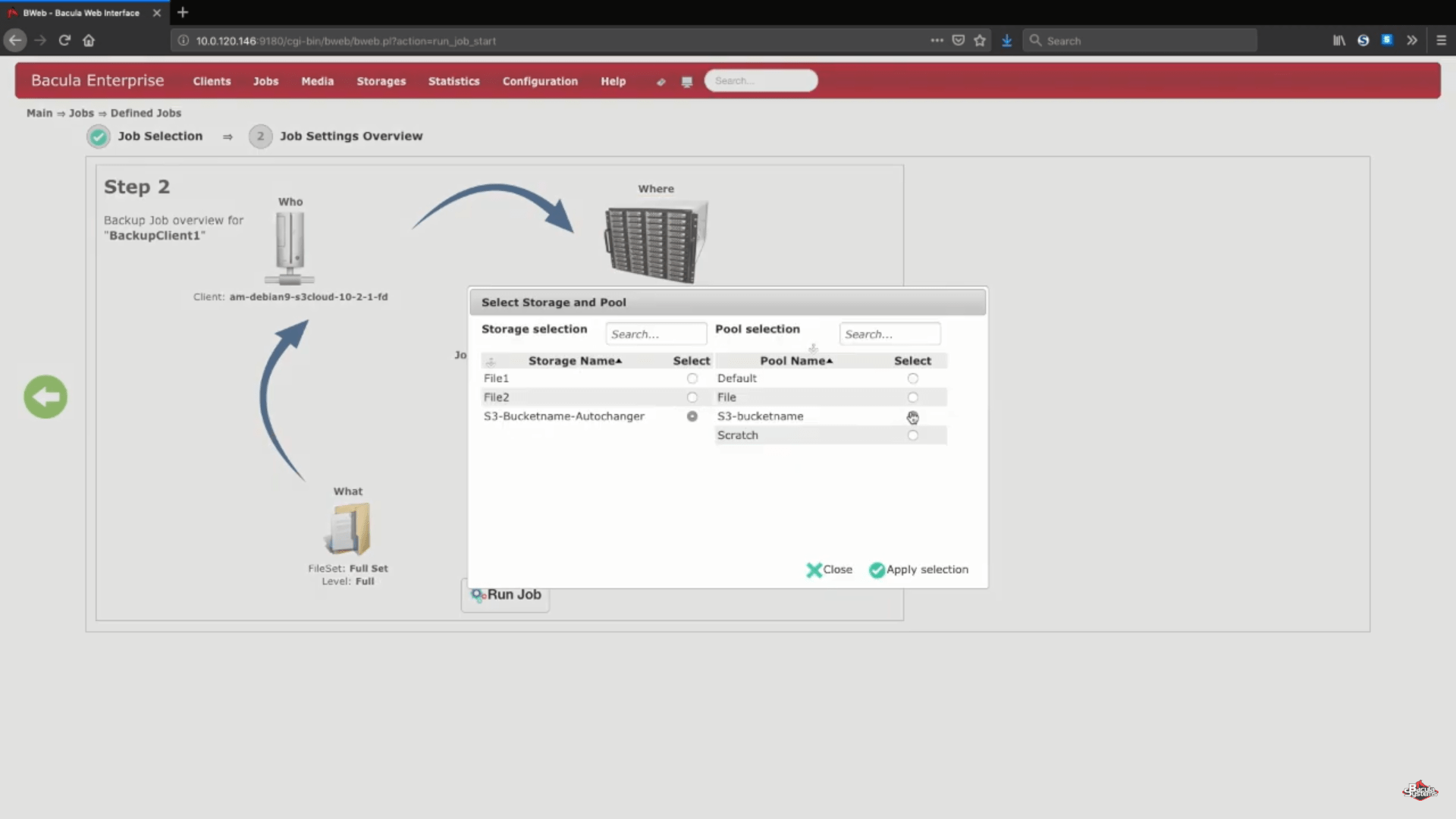
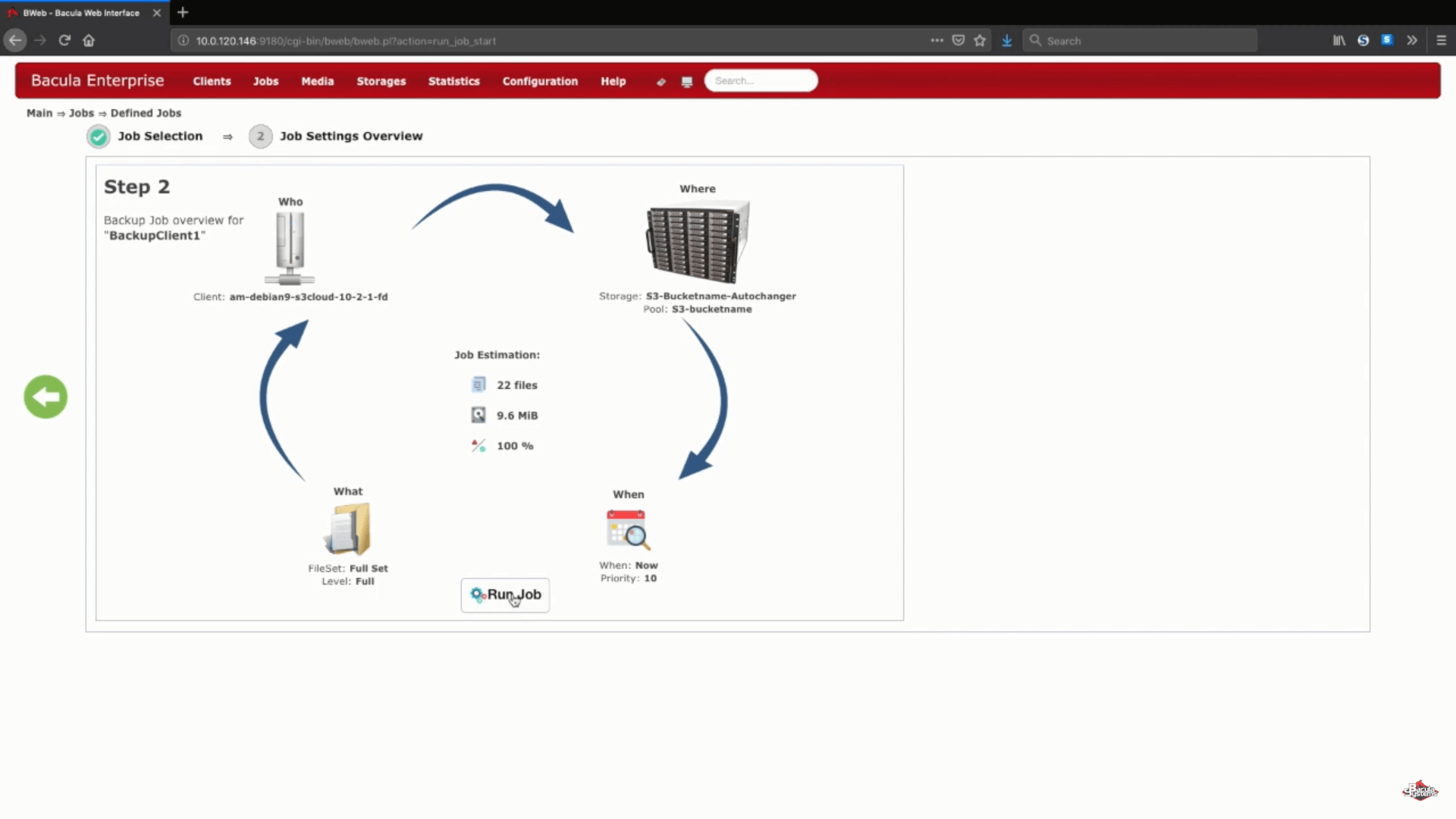
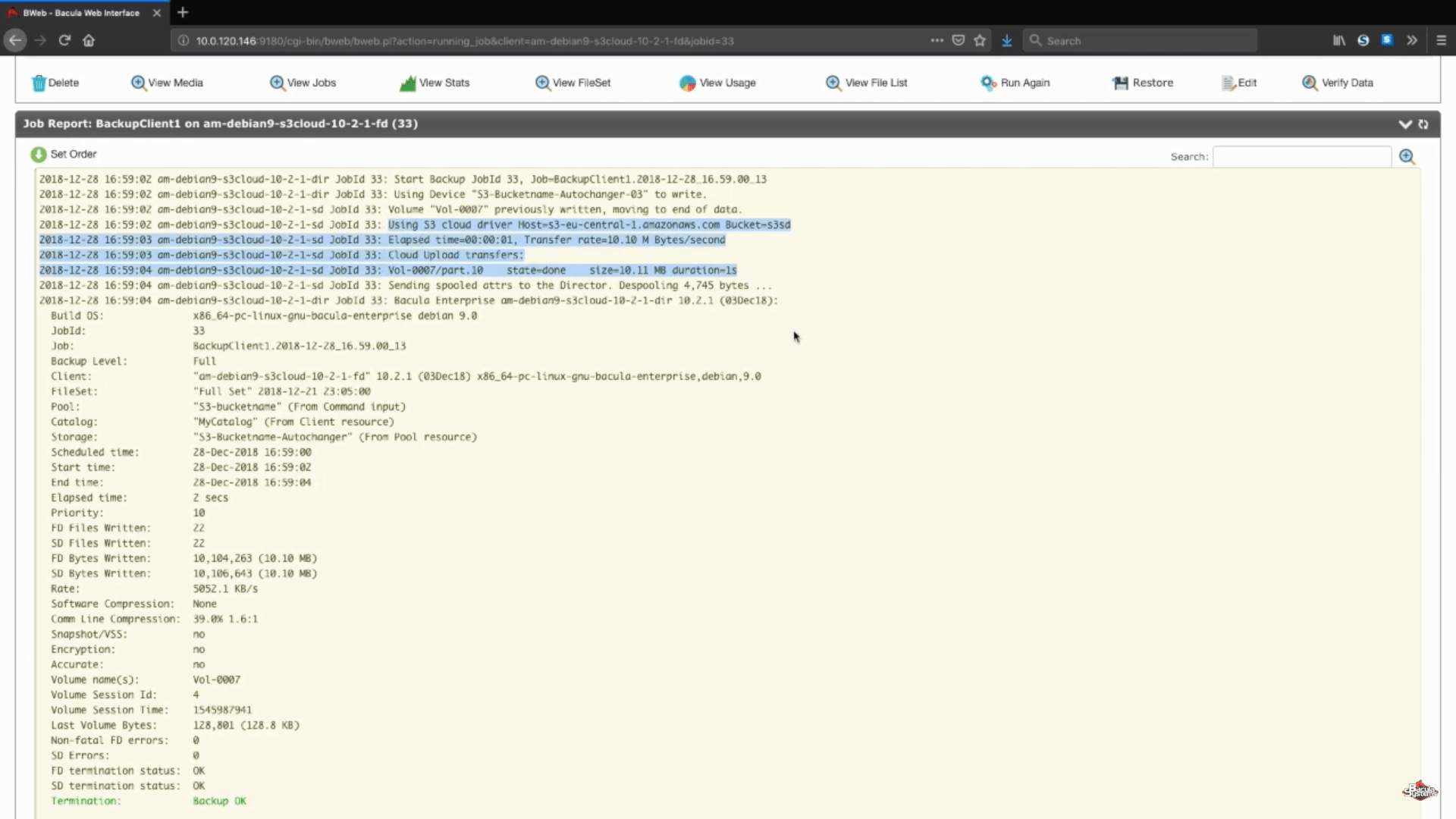
Después de que el trabajo se haya ejecutado podremos ver los registros de todo el proceso, y esta sección específica (en la captura de pantalla de abajo) nos muestra que todo se ha cargado correctamente.
Conclusión
Bacula Enterprise es una opción sólida para gestionar de forma fiable sus copias de seguridad de AWS S3 y otras nubes, incluyendo la creación y configuración de nuevos almacenamientos de copias de seguridad y la configuración de trabajos de copia de seguridad para que se realicen automáticamente. También cuenta con capacidades avanzadas de configuración y personalización combinadas con funciones ultramodernas y actualizadas contra el ransomware.

