Contents
- Usando o AWS Backup para criar backups
- AWS Backup e sua interação com outros serviços baseados na AWS
- AWS backup e EC2
- Atualização 2022
- Operações básicas com o console S3 da Amazon
- Outros métodos para fazer backup do seu bucket do Amazon S3
- Versionamento e replicação do bucket
- Soluções de backup corporativo para AWS S3 com custos mínimos de restauração.
- Backup do AWS S3 com Bacula Enterprise
- Adicionando um novo armazenamento S3 no Bacula Enterprise
- Configurando seu backup do AWS S3 usando o Bacula Enterprise
- Concluindo o processo de instalação do armazenamento S3
- Salvando suas novas configurações de backup do S3
- Testando as configurações do backup do AWS
- Conclusão
Usando o AWS Backup para criar backups
Fazer backup de suas informações é talvez a parte mais importante para as proteger de qualquer dano, bem como para assegurar o compliance. Mesmo os servidores e armazenamentos mais duradouros são suscetíveis a bugs, erros humanos e outras possíveis razões para um desastre. Mas criar e administrar todos os seus fluxos de tarefas de backup pode ser um trabalho assustador em geral. Portanto, há uma variedade de métodos que você pode usar para simplificar todo o processo de criação de um backup enquanto usa o AWS S3.
Uma escolha popular é a própria solução de backup da Amazon, o AWS Backup. O AWS backup pode fornecer uma maneira de gerenciar seus backups tanto no AWS Cloud, como on-premise, e ele também suporta uma variedade de outras aplicações da Amazon.
O processo de backup em si é bastante fácil. Um usuário teria que criar uma política de backup (seu plano de backup) especificando uma série de parâmetros, como frequência de backup, a quantidade de tempo que esses backups devem ser mantidos, etc. Assim que a política for estabelecida, o AWS Backup deve começar a fazer o backup de seus dados automaticamente. Depois disso, você poderá usar o console do AWS Backup para visualizar seus recursos de backup, ter a opção de restaurar um backup específico ou apenas monitorar suas atividades de backup e restauração.
AWS Backup e sua interação com outros serviços baseados na AWS
Há muitos serviços diferentes da AWS que podem oferecer vários recursos úteis e trabalhar em conjunto com o serviço AWS Backup. Por exemplo, esses serviços incluem, mas não são exclusivos da AWS:
- Amazon EBS (Elastic block store);
- Amazon RDS (Serviço de banco de dados relacional);
- Backups do Amazon DynamoDB;
- Snapshots de gateways de armazenamento AWS, etc.
É claro que você tem que habilitar o serviço específico que deseja usar em seu processo de backup antes de usá-lo. Se você tentar iniciar ou criar o backup usando recursos específicos de um serviço que você ainda não habilitou, provavelmente receberá uma mensagem de erro e não será capaz de executar o processo de criação.
Para encontrar a lista de serviços que você pode ligar ou desligar, basta seguir esses passos:
- Abra o console do AWS backup.
- Entre no menu “Settings “.
- Vá para a página “Service opt-in” e clique em “Configure resources”.
Isso deve levá-lo à página com uma série de nomes de serviço e alternâncias, e você pode facilmente alternar cada um dos serviços específicos dentro ou fora da página. Clicando em “Confirm” depois de fazer as mudanças, você salvará suas operações.
AWS backup e EC2
O AWS backup é capaz de implementar muitas das capacidades de serviço existentes da AWS no processo de criação de um backup. Um bom exemplo disso é a capacidade de snapshot do EBS que é usada para criar backups de acordo com o plano que você criou. A criação de snapshots do PBE, por outro lado, pode ser feita usando o EC2 API (Elastic compute cloud). Dessa forma, você poderá gerenciar seus backups a partir de um console de backup centralizado AWS, monitorá-los, agendar operações diferentes, e assim por diante.
O AWS backup pode realizar tarefas de backup em instâncias completas do EC2, permitindo que você tenha menos necessidade de interagir com a própria camada de armazenamento. A maneira como isso funciona também é bastante simples. Basicamente, o AWS backup tira um snapshot do volume de armazenamento raiz do EBS, assim como dos volumes associados e das configurações de lançamento. Todos os dados são armazenados num formato de imagem específico chamado AMI (imagem da máquina Amazon) com suporte de volume.
Os arquivos de backup AMI EC2 também podem ser criptografados no processo de backup da mesma forma que o backup da AWS faz com os snapshots do EBS. O usuário pode usar a chave padrão KMS se não tiver uma, ou pode usar sua própria chave para aplicá-la ao backup.
Esse processo é muito superior e mais fácil de personalizar do que a forma integrada do AWS EC2 para fazer backup e restaurar dados. Por exemplo, o processo de backup do EC2 cria originalmente um snapshot do volume, exigindo pouca ou nenhuma configuração, e só isso. Esse processo pode ser feito dentro do console do Amazon EC2 em “Snapshots > Create Snapshot > *escolha o volume* > Create”.
O processo de restauração dos recursos do EC2 pode ser feito de várias maneiras diferentes: Console do AWS backup, linha de comando ou apenas a API. Em comparação com os outros dois, o console de backup tem muitos limites de funcionalidade para o processo de restauração e não pode restaurar vários parâmetros, como endereços ipv6, algumas identificações específicas, e assim por diante. Os outros dois métodos, por outro lado, são capazes de fazer uma restauração completa de uma maneira ou de outra.
Também é possível restaurar volumes EBS a partir de um snapshot. No entanto, esse processo é um pouco mais complicado e inclui duas partes: restaurar um volume a partir de um snapshot e anexar um novo volume a uma instância.
A restauração do volume é bastante simples e pode ser feita dentro da página EC2, indo a ELASTIC BLOCK STORE, Snapshots > *selecione o snapshot* > Create Volume. Anexar um volume recentemente restaurado a uma instância, por outro lado, é um processo ligeiramente diferente que você pode fazer indo a Volumes > Actions > Attach Volume > *escolha o volume por nome ou por ID* > Attach. Também é recomendável manter o nome do dispositivo sugerido durante todo esse processo.
Atualização 2022
Desde o início de 2022, o AWS Backup acrescentou mais um serviço, o Amazon Simple Storage Service, ou Serviço de Armazenamento Simples da Amazon (S3). O mundo moderno tem muitas exigências e possibilidades quando se trata de opções de armazenagem, e é bastante normal depender de vários locais ou serviços de armazenamento diferentes ao mesmo tempo.
Esse tipo de integração permite que o AWS Backup proteja e governe os dados do S3, assim como faz com outros serviços da Amazon. Há três vantagens principais quando se trata de usar a integração entre o AWS Backup e o Amazon S3:
- Melhor compliance, com os painéis de controle integrados;
- Processo de restauração mais fácil, com processos de restauração point in time;
- Uma gestão centralizada de backup mais conveniente, tornando o controle do ciclo de vida do backup muito mais fácil de se trabalhar.
No momento em que estou escrevendo, o AWS Backup para S3 ainda é um lançamento, mas já pode oferecer funcionalidades básicas de backup, como backups point in time, backups periódicos, restaurações, e assim por diante. Ele também pode ser completamente automatizado usando as organizações AWS.
Operações básicas com o console S3 da Amazon
O próprio kit de ferramentas S3 da Amazon permite algumas operações básicas quando se trata de recuperar ou armazenar um arquivo específico do bucket. É possível destacar quatro operações diferentes que podem ser feitas usando apenas o software de backup do Amazon S3, mas primeiro temos que chegar ao console dele.
Isso pode ser feito indo até a página de serviços AWS usando este link. Inserir suas informações de login deve permitir que você acesse a primeira tela do conjunto de ferramentas dos serviços AWS. Depois disso, é possível encontrar o console S3, ou indo ao menu “Services” e encontrando o S3 lá, ou digitando “S3” na barra de busca localizada na parte superior da página.
- Criando o S3 bucket.
- Um bucket é um tipo de container que o Amazon S3 usa para armazenar seus arquivos. Um bucket pode ser criado na interface AWS S3 clicando no botão “Create Bucket” (Criar bucket) na tela de título.
- Vale notar que a página da internet pode ter um aspecto diferente, dependendo de você já ter ou não criado um bucket antes dentro desta conta. Se houver outros buckets já existentes, vai ter uma tela que lhe permitirá administrar esses buckets, inclusive os renomeando ou apagando completamente.
- Por outro lado, se essa é a primeira vez que você cria um bucket dentro dessa conta do AWS S3, terá uma tela correspondente descrevendo uma maneira de criar um bucket. Se esse for o caso, você poderá usar ou o botão “Create bucket” (Criar bucket) ou o botão “Get start” (Começar). Ambos devem levar ao mesmo lugar: a tela de criação do bucket.
- O primeiro aviso da tela deve ser sobre a criação de um nome para seu novo bucket, e o campo também notificará você se o nome do bucket não atender a alguns dos regulamentos da própria Amazon. Você também terá que escolher uma região apropriada para seu futuro bucket. Uma vez que você tenha feito isso, clique em “Next” (Próximo) para continuar.
- A segunda tela de criação de bucket permite que você habilite uma das propriedades de seu bucket de backup do Amazon S3, tais como Tags, Versioning, Encryption, Server-access logging e Object level logging. Com o objetivo de manter essa explicação simples, não ativaremos nenhuma dessas propriedades. Clique em “Next” (Próximo) para prosseguir.
- A tela seguinte permite a personalização das permissões, incluindo tanto as permissões do sistema como as permissões do usuário. Você também pode mudar seus próprios níveis de permissão e acrescentar pessoas específicas para ter acesso a esse bucket. Nosso exemplo mantém todos os níveis de permissão padrão, com o criador tendo acesso a qualquer coisa dentro do bucket. Clique em “Next” (próximo) quando terminar.
- A última parte do processo é a tela de confirmação, que permite a você revisar todas as configurações que realizou anteriormente. Isso inclui permissões, propriedades e nomes. Clicar no botão “Create bucket” depois de terminar o processo de revisão faz exatamente o que ele diz: cria um bucket com suas configurações específicas.
- Carregando um arquivo.
- Carregar um arquivo no novo bucket do AWS S3 também é relativamente fácil, se você estiver começando a partir do console do Amazon S3. Clicando no nome de seu novo bucket AWS, você terá acesso a ele e ao seu conteúdo.
- Assim que você estiver na landing page do seu bucket, poderá iniciar o processo de carregamento clicando no botão “Upload”, na parte esquerda da página.
- Há duas maneiras de carregar um arquivo na janela seguinte: ou arrastando e soltando um arquivo na página, ou clicando no botão “Add files” e selecionando o arquivo depois. Depois de ter escolhido o arquivo a ser carregado, você pode clicar em “Next” (Próximo) para prosseguir.
- Assim como no processo de criação do bucket de backup S3, você pode alterar as permissões do arquivo antes de carregá-lo, incluindo tanto as suas próprias permissões (as contas que têm acesso a esse arquivo), como as permissões públicas. Use o botão “Next” (Próximo) para continuar.
- A próxima página é mais sobre propriedades específicas para seu arquivo, tais como classe de armazenamento (Standard, Standard-IA e Redundância reduzida), criptografia (Nenhuma, chave mestra S3 e chave mestra KMS), e metadados. Depois que terminar de escolher uma das opções, você pode continuar através do botão “Next” (Próximo).
- A última tela dessa sequência tem tudo a ver com a confirmação de todas as suas mudanças antes de fazer o upload. Suas propriedades, permissões e a quantidade de arquivos escolhidos estão todos descritos aqui. Clicar no botão “Upload” depois de verificar novamente os detalhes, iniciará o processo de upload.
- Baixando um arquivo.
- O download de um arquivo do seu bucket AWS S3 pode ser feito em duas etapas fáceis. Primeiro, você tem que estar na landing page do bucket, na qual verá todos os arquivos que estão sendo armazenados dentro dele. O primeiro passo que você terá que fazer é clicar no campo de seleção à esquerda do arquivo que deseja baixar.
- Ao selecionar pelo menos um arquivo da lista, surge uma janela pop-up de descrição, que tem dois botões: “Download” e “Copy path”. Use o botão “Download” para baixar o arquivo em questão.
- Eliminando um arquivo ou um bucket.
- Eliminar arquivos desnecessários, ou mesmo buckets, não é apenas fácil, é também altamente recomendado pela própria Amazon para evitar a desordem excessiva de seus arquivos. Para começar, vamos ver o processo de eliminação dos arquivos.
- Assim que você chegar à landing page de um bucket, a primeira coisa que deve fazer é clicar no campo de seleção à esquerda do arquivo que deseja apagar.
- Após escolher o(s) arquivo(s) para eliminação, você pode pressionar o botão “More” perto dos botões “Upload” e “Create Folder” e escolher a opção “Delete” na lista suspensa.
- Você verá uma tela de confirmação que lhe mostrará quais arquivos serão apagados, e terá que clicar novamente em “Delete” para iniciar o processo de exclusão.
- O processo de eliminação de um bucket inteiro é um pouco diferente. Primeiro, você precisará sair da landing page do bucket e voltar para o console principal do Amazon S3, que lista todos os seus buckets.
- Clicar no espaço em branco à direita do bucket que você deseja eliminar, selecionar o bucket, e clicar no botão “Delete bucket”, iniciará o processo de eliminação.
Vale a pena notar que todas essas operações básicas poderiam ser feitas apenas com o próprio sistema da Amazon e sem a adição de quaisquer soluções de backup do AWS.
Outros métodos para fazer backup do seu bucket do Amazon S3
O uso do AWS Backup não é a única opção quando se trata de backups do S3. Há uma variedade de opções diferentes que podem ser feitas tanto por uma aplicação dentro do ecossistema Amazon, quanto por soluções de terceiros.
Por exemplo, aqui estão várias outras maneiras de criar um backup do S3 sem usar o aplicativo AWS Backup:
- Criar backups usando o Amazon Glacier;
- Utilizar o AWS SDK para copiar um bucket do S3 para outro;
- Copiar informações para o servidor de produção do qual é feito, por sua vez, backup;
- Utilizar versionamento como um serviço de backup.
Vale a pena mencionar que a maioria desses métodos não são exatamente rápidos ou convenientes. O Amazon Glacier, por exemplo, seria uma boa solução de backup se não fosse muito mais lenta do que seu processo de backup comum, já que o Glacier se destina mais ao arquivamento de dados, e menos aos backups.
Versionamento e replicação do bucket
O versionamento é um assunto que merece ser abordado mais a fundo. O versionamento de objeto é um recurso do Amazon S3 que permite a proteção de dados contra uma variedade de mudanças indesejadas, incluindo exclusão, corrupção, e assim por diante. Ele funciona criando uma nova cópia de um arquivo cada vez que ele é modificado de alguma forma (quando está armazenado no S3).
O bucket do S3 armazena todas essas diferentes versões do mesmo arquivo, o que lhe dá a possibilidade de acessar e restaurar qualquer uma delas. Isso às vezes pode até neutralizar a exclusão, já que apagar uma versão atual do arquivo geralmente não afeta suas versões anteriores.
Vale a pena ter em mente que o uso do versionamento como solução de backup pode aumentar significativamente os custos de armazenamento, devido à quantidade de dados que precisam ser armazenados. Nesse caso, talvez seja uma boa ideia criar a sua política de ciclo de vida para versões anteriores de arquivos, de modo que cópias mais recentes possam substituir as mais antigas, tornando o versionamento mais econômico no geral.
O versionamento do S3 pode ser habilitado usando o AWS Management Console, indo até Services > S3 (Na categoria “Storage”) > Buckets > Bucket_name. Cada bucket tem uma série de opções diferentes e personalizáveis que são separadas em várias abas. Estamos à procura de uma aba chamada “Properties” (Propriedades).
O versionamento do bucket é uma das primeiras opções que aparecem na aba “Properties” (Propriedades). Embora esteja desativada por padrão, tudo que você tem que fazer para ativá-la é selecionar “Edit” na opção “Bucket Versioning”, e mudar “Bucket Versioning” na janela seguinte de “Suspend” para “Enable”.
Você perceberá que, ao habilitar o versionamento de buckets, vai aparecer uma dica na tela recomendando atualizar suas regras de ciclo de vida, a fim de estabelecer o processo de versionamento da maneira correta. As regras de ciclo de vida podem ser alteradas na guia “Management” (Administração) dentro do mesmo menu de detalhes do bucket.
Em primeiro lugar, precisamos criar uma regra de ciclo de vida (botão “Create lifecycle rule” (Criar regra do ciclo de vida). Nesse caso, você terá que inserir um nome e escolher o escopo da função (pode ser aplicado a todo o bucket ou a arquivos específicos escolhidos com filtros).
Você também pode personalizar a maneira como essa regra se comporta, usando a parte “Lifecycle rule actions” desse menu. Aqui você pode estabelecer uma série de regras que dizem respeito às versões atuais e anteriores dos arquivos, bem como os pré-requisitos para a expiração da versão (com sua posterior eliminação). Depois de ter criado tudo, basta clicar em “Create Rule” para que a regra do ciclo de vida seja gerada e aplicada.
Embora o versionamento possa ser ótimo para trabalhar com arquivos específicos, ele pode não ser uma escolha viável quando você está mantendo versões anteriores de muitos arquivos. Felizmente, o versionamento não é a única alternativa aqui, já que também existe a replicação de buckets.
Essa opção pode ser encontrada dentro do mesmo menu que antes, só que em outra categoria chamada “Replication rules”. Clicar em “Create replication rule” (Criar regra de replicação), abrirá uma nova página para você, com uma série de ajustes para a futura regra de replicação de buckets.
Aqui, você pode mudar o nome da regra, definir o status dela no momento da criação (se ela ficaria ativada ou desativada desde o início), selecionar um bucket-alvo para ser replicado e um bucket de destino para armazenar a cópia do original. Opções adicionais nesta página incluem controle de tempo de replicação, sincronização de modificação de réplicas, várias métricas de replicação, e mais.
Essa opção também não é perfeita, pois envolve a cópia de um bucket inteiro, o que é um aumento massivo na quantidade de espaço de armazenamento consumido. Como a maioria dessas opções tem seus próprios problemas e deficiências, você talvez queira considerar uma solução de terceiros para suas necessidades de backup e restauração do S3.
Falando de soluções de terceiros, embora haja muitas soluções diferentes no mercado, examinaremos uma das mais promissoras: a solução fornecida pelo Bacula Enterprise.
Soluções de backup corporativo para AWS S3 com custos mínimos de restauração.
O Bacula fornece soluções de backup nativamente integradas ao AWS S3 como parte de suas extensas opções de backup e recuperação baseadas em nuvens corporativas. Ele oferece integração nativa com nuvens públicas e privadas através da interface S3 da Amazon, com suporte transparente para S3-IA. O backup do AWS S3 está disponível para Linux, Windows e outras plataformas. No entanto, tem outra coisa importante que sua empresa deveria saber sobre o backup do Amazon S3 com o Bacula Enterprise: ele permite que você tenha um controle único sobre seu backup em nuvem e, ao mesmo tempo, consiga uma redução significativa dos custos com armazenamento em nuvem.
Backup do AWS S3 com Bacula Enterprise
Para iniciar o processo de backup do AWS com o Bacula, é preciso primeiro entrar no modo de configuração. Depois disso, você verá várias novas opções disponíveis. Você precisa daquela com o título “Add a New Storage Resource”.
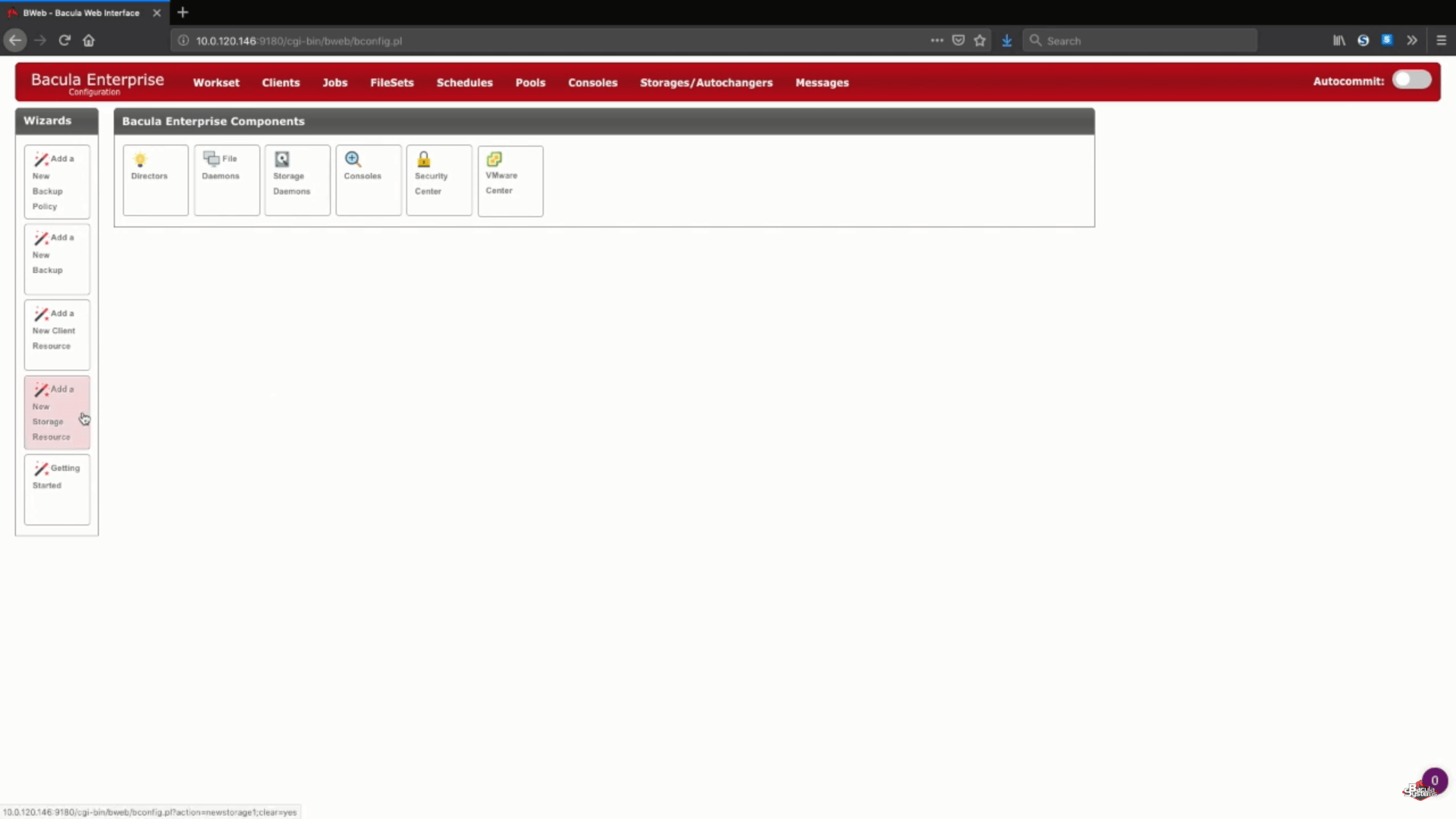
Adicionando um novo armazenamento S3 no Bacula Enterprise
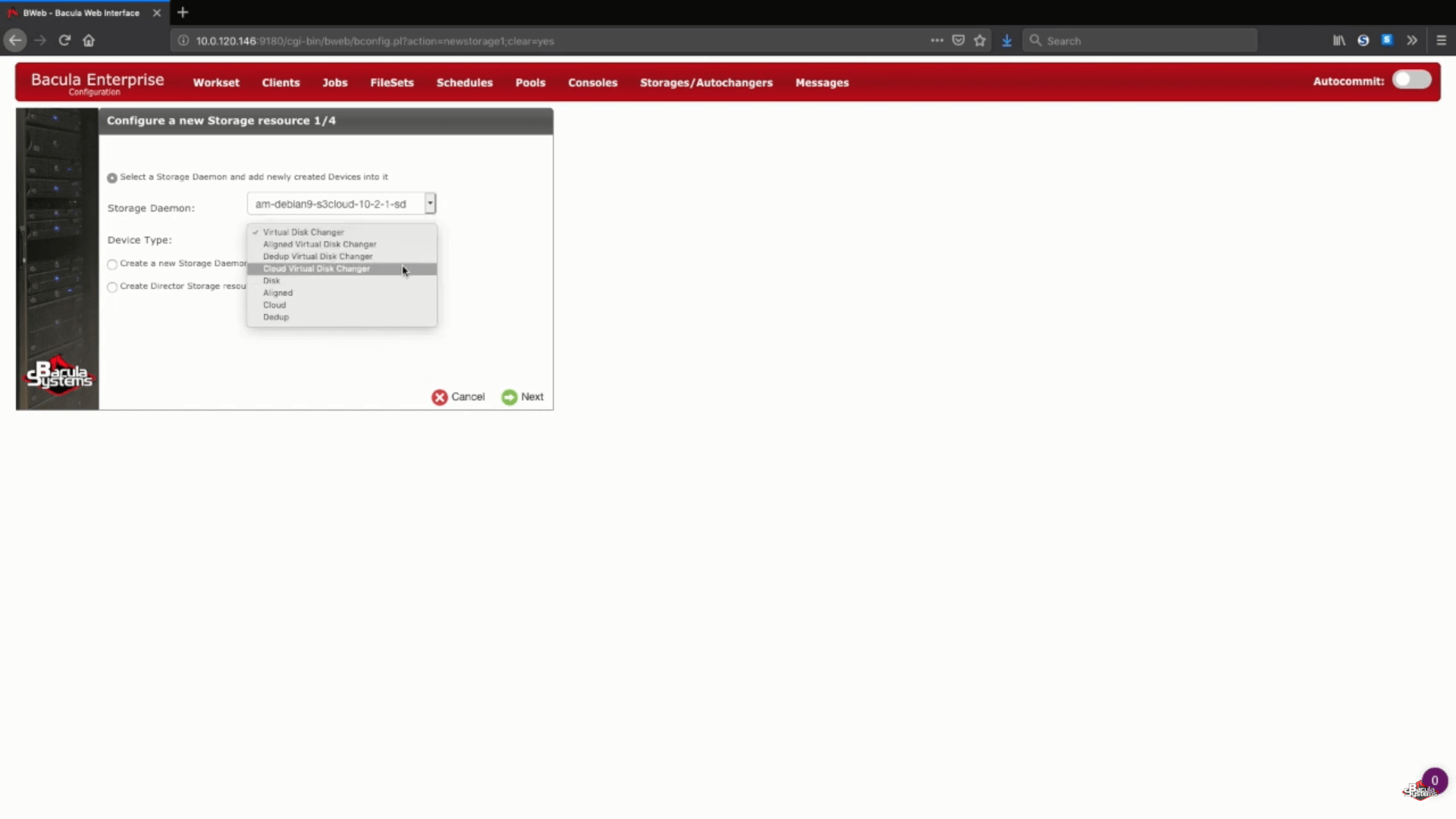
Neste exemplo específico, estamos adicionando um novo armazenamento do Amazon S3 a um storage daemon existente. Escolheremos também a opção “Cloud Virtual Disk Changer” em “Device Type”. Esse tipo de dispositivo permite vários backups simultâneos para o mesmo armazenamento em nuvem.
Como nosso storage daemon já existe, todas as informações do passo 2 (Configuração de um novo recurso de armazenamento) podem ser retiradas dos dispositivos criados anteriormente.
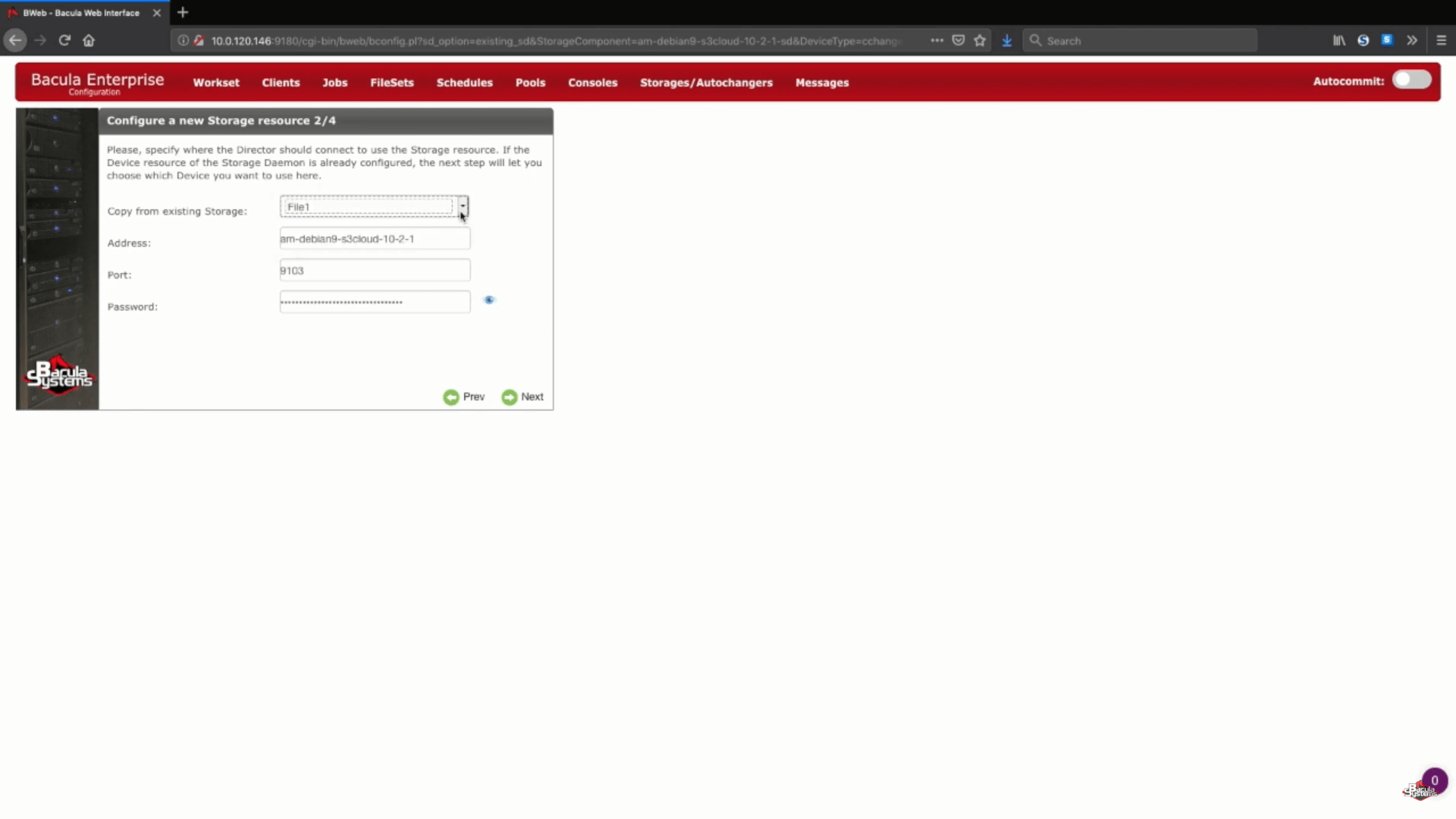
Configurando seu backup do AWS S3 usando o Bacula Enterprise
O próximo passo do processo de backup do AWS é a configuração das informações de armazenamento em nuvem. Nesse exemplo, armazenaremos nossos volumes de backup no cloud cache, que normalmente é usado como uma pequena área temporária durante o carregamento de um backup para uma nuvem, mas ainda pode conter uma semana ou mais de dados, para permitir backups locais durante esse período, e backups em nuvem, se o período for maior que uma semana. Você sempre pode falar com os especialistas do suporte da Bacula para saber mais sobre o tamanho do armazenamento em nuvem, a política de retenção de cache e o comportamento do carregamento em nuvem.
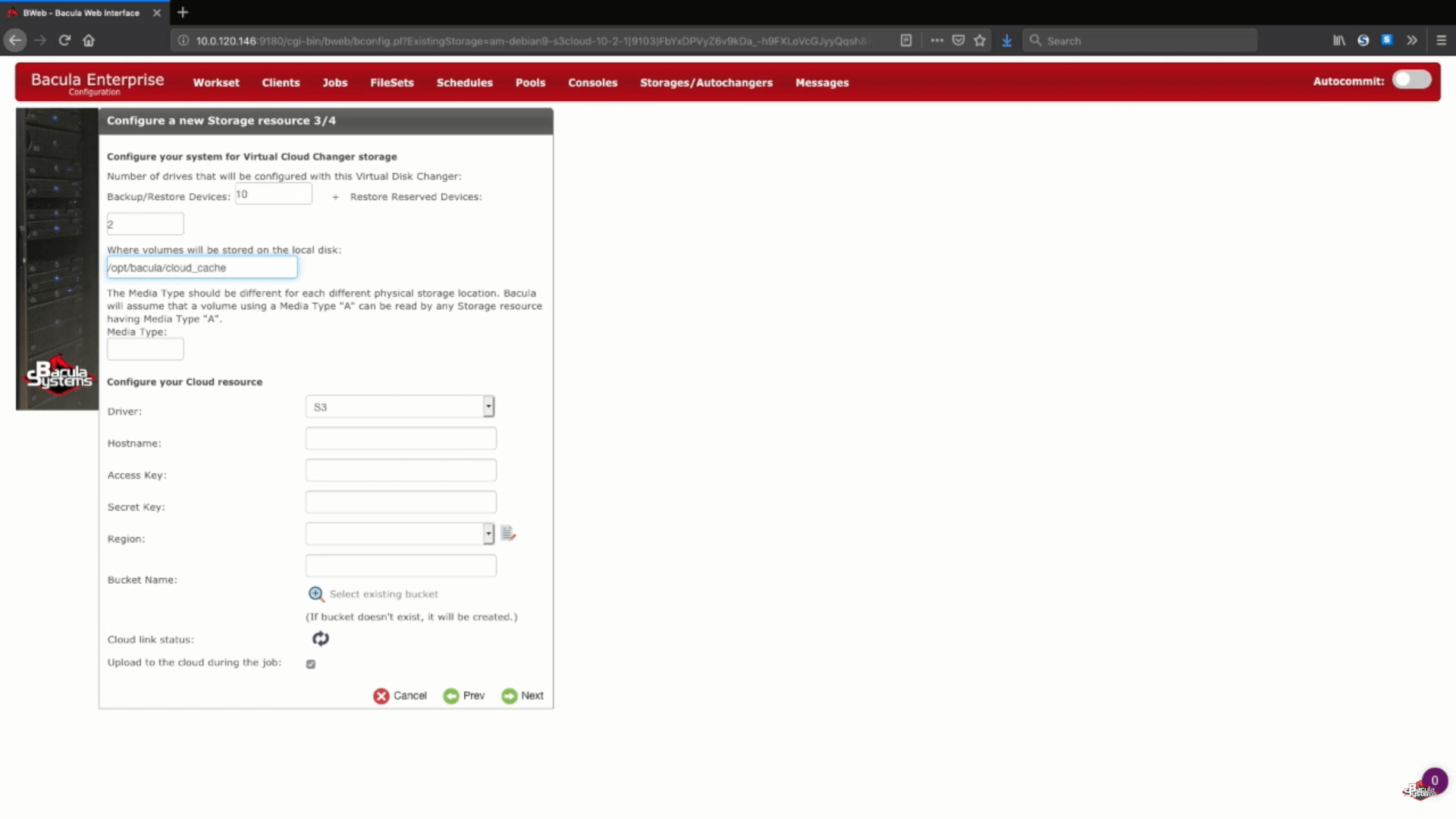
Em seguida, escolheremos um tipo único de mídia para nosso novo dispositivo de armazenamento, para facilitar a visualização dos arquivos desse dispositivo específico por parte do Bacula.
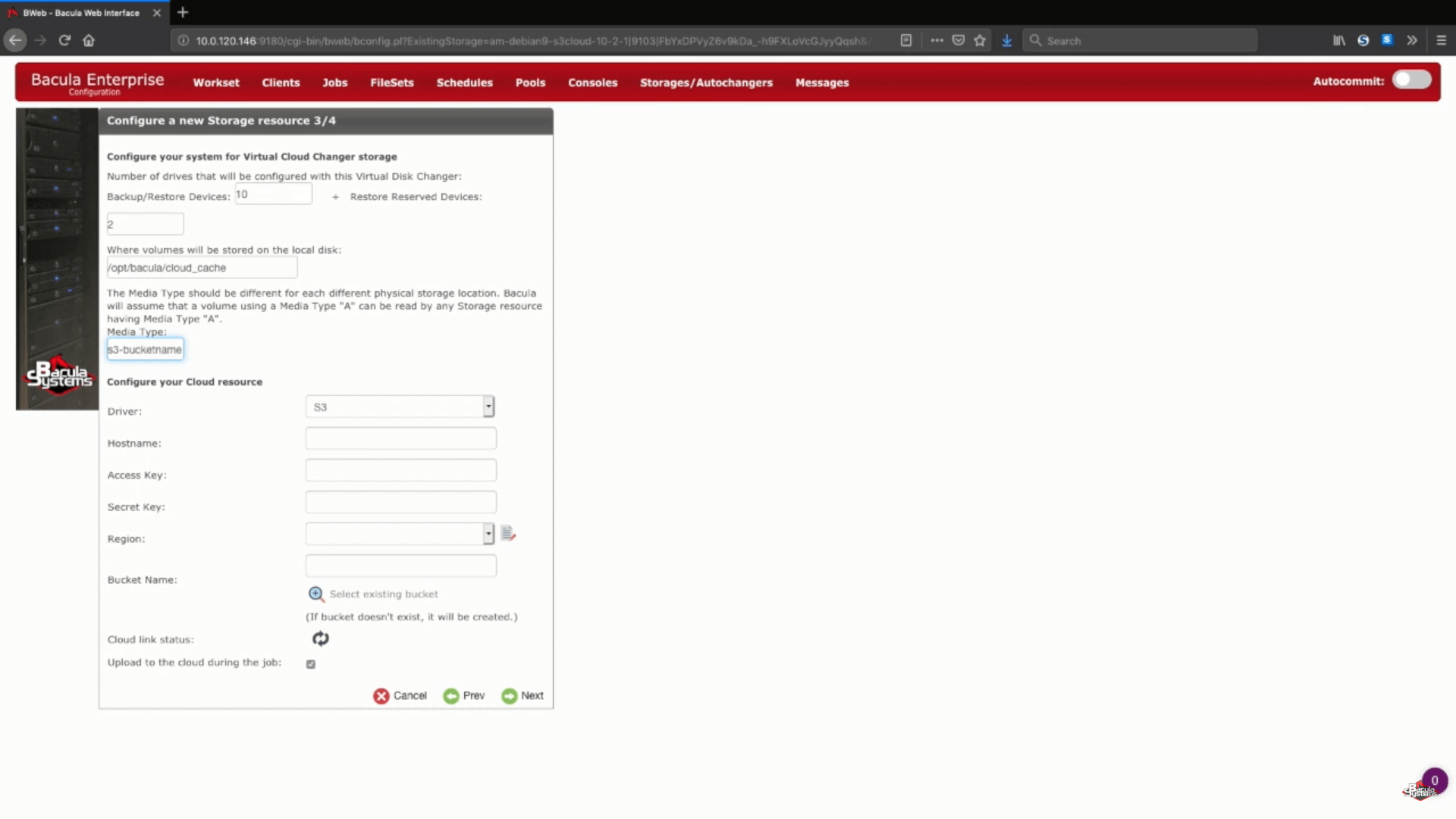
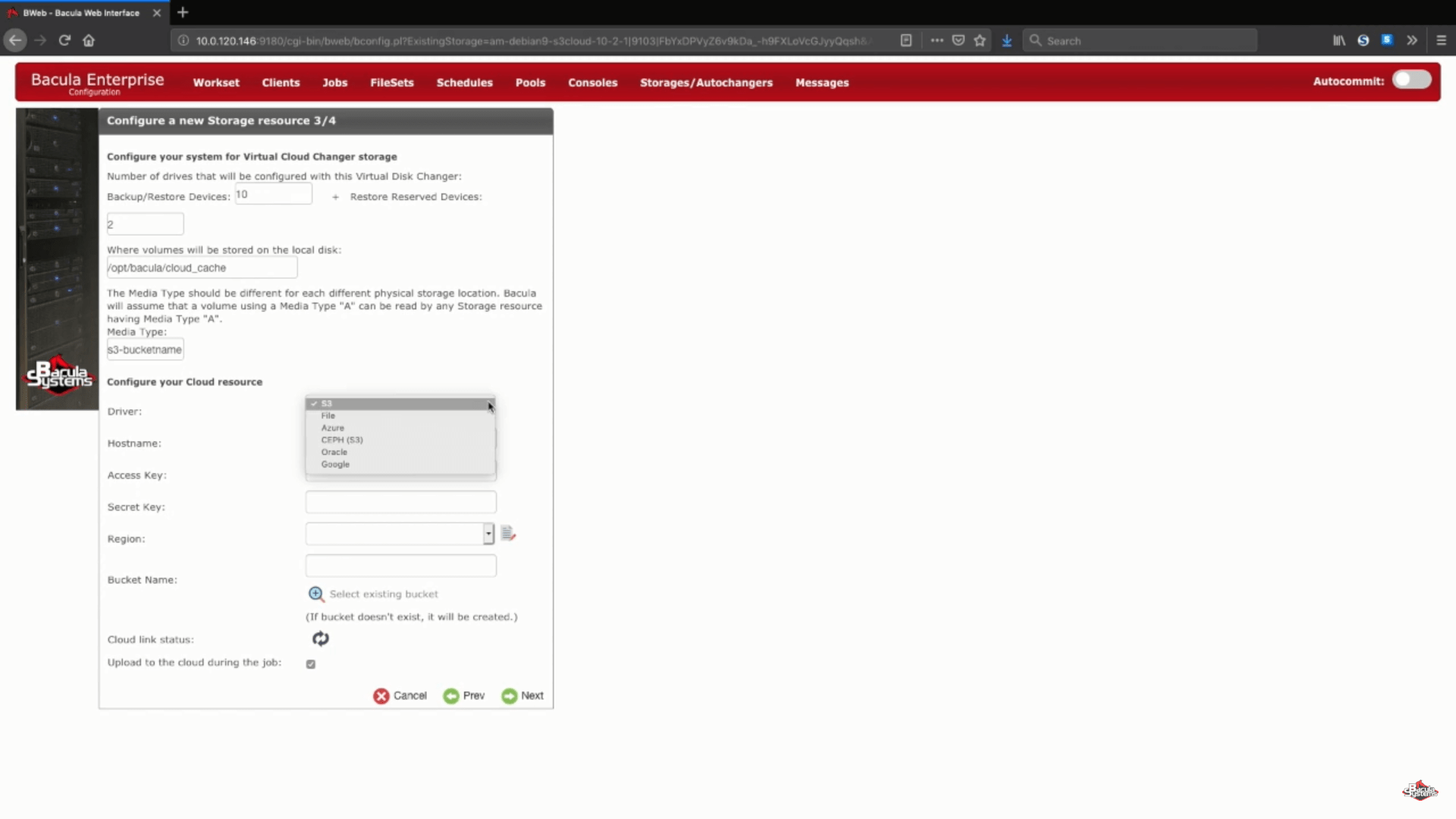
Outra parte desse passo é escolher seu driver AWS S3 a partir de uma lista de drivers de nuvem suportados.
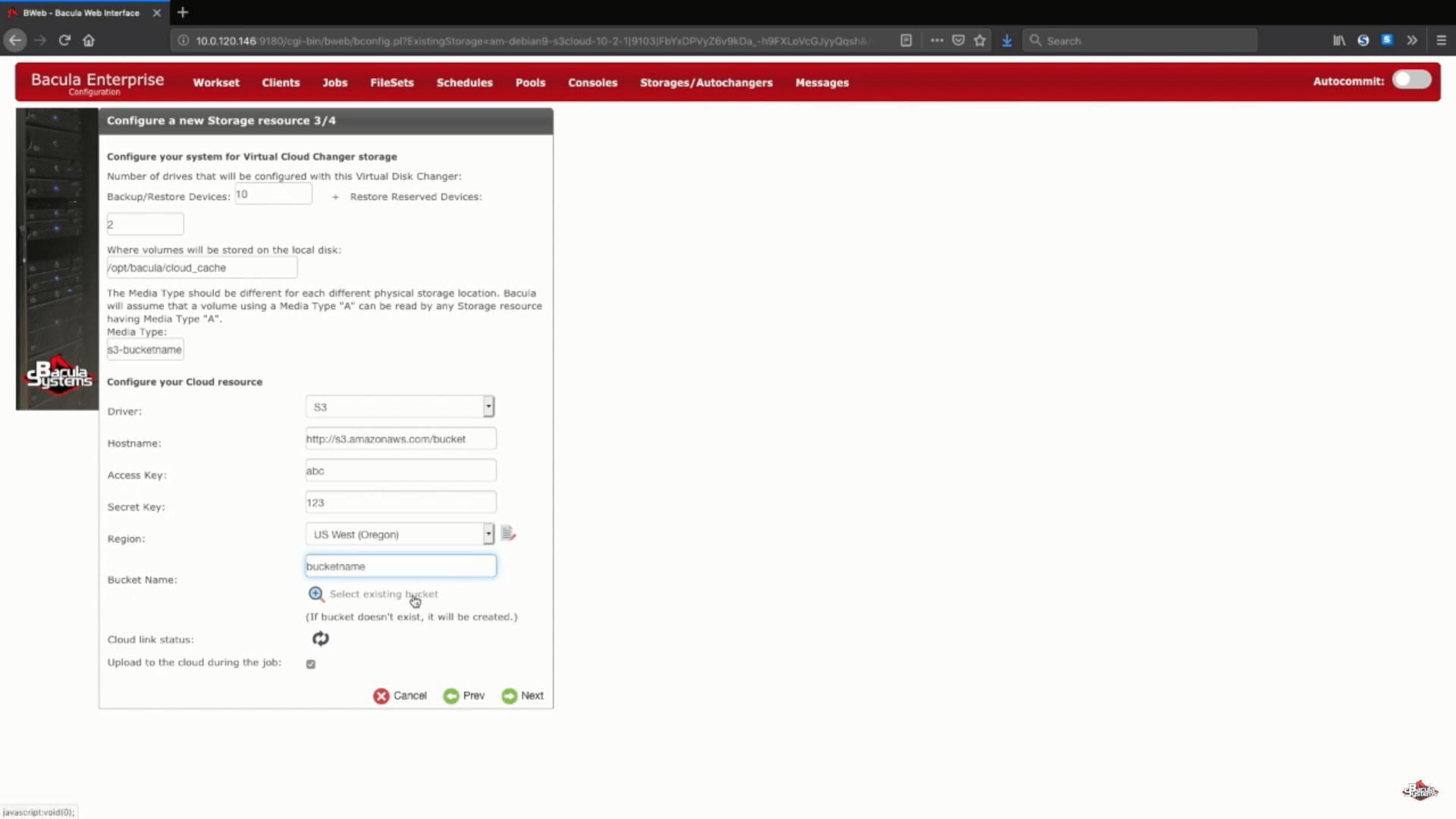
Em seguida, elaboraremos uma lista de informações arbitrárias, como hostname, informações de conta, região e assim por diante. Você também poderá escolher entre selecionar um bucket existente, conectando-se à sua conta existente, ou digitar um nome na linha correspondente para confirmar a criação de um novo bucket.
Concluindo o processo de instalação do armazenamento S3
Restam duas opções possíveis: “Cloud link status” e “Upload to the cloud during the job”. O botão “Cloud link status” permite que você verifique imediatamente a conexão de seu sistema atual com uma nuvem de sua escolha. “Upload to the cloud during the job” é uma opção que é escolhida como parte das configurações padrão para carregar seus dados de backup para a nuvem assim que ela estiver pronta (mesmo no processo de uma tarefa de backup), mas você também pode desativar essa opção se desejar carregar depois que uma tarefa estiver terminada ou com alguma outra programação em mente.
O próximo passo desse assistente é simplesmente digitar o nome do seu armazenamento e a descrição opcional.
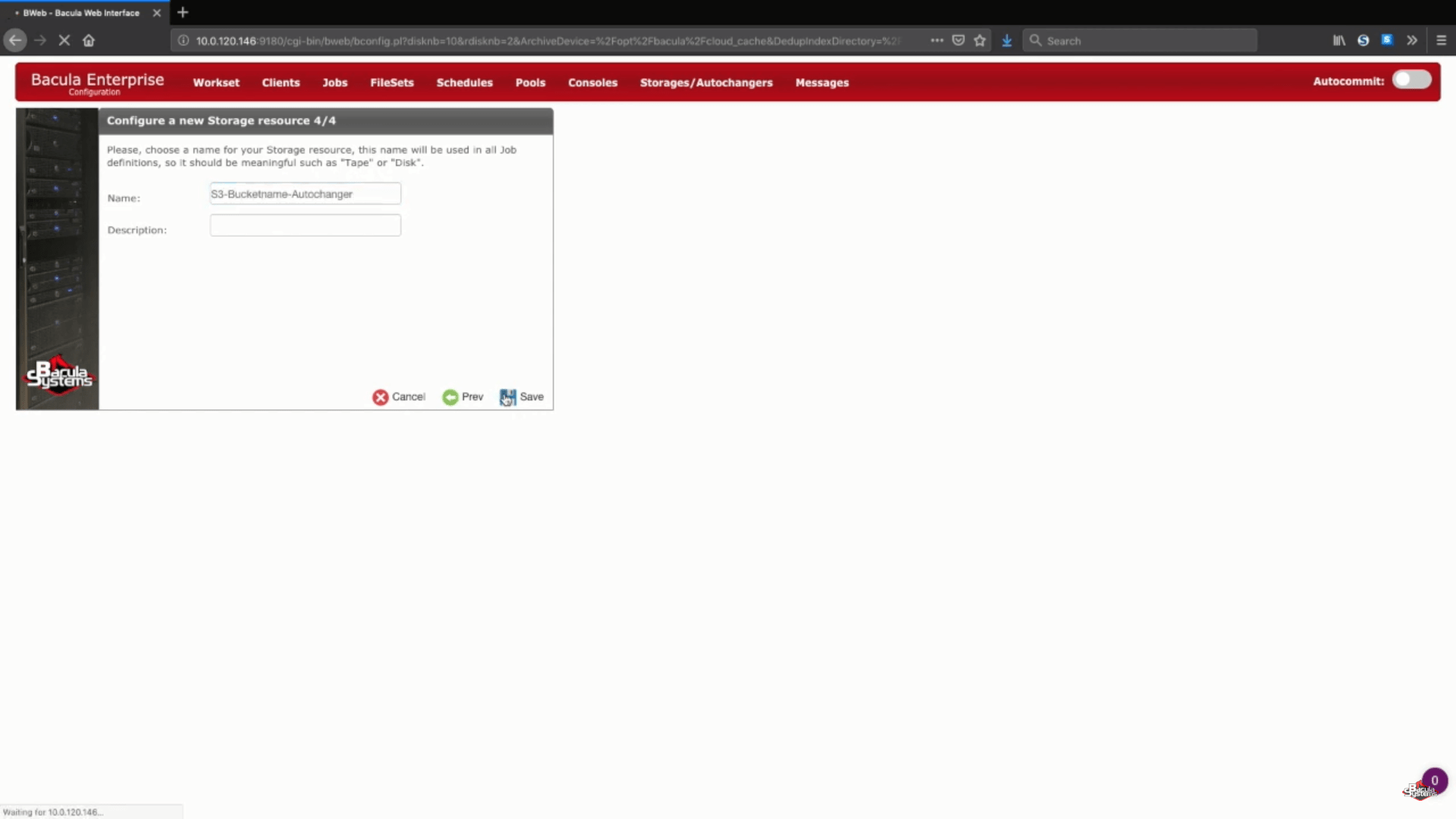
Salvando suas novas configurações de backup do S3
Após essa etapa, você pode clicar no botão “Save” para permitir que todas as mudanças anteriores entrem em vigor. Tenha em mente que, para que tudo seja devidamente colocado em prática, você terá que recarregar seu storage daemon, o que significa que qualquer tarefa que esteja em andamento fracassaria.
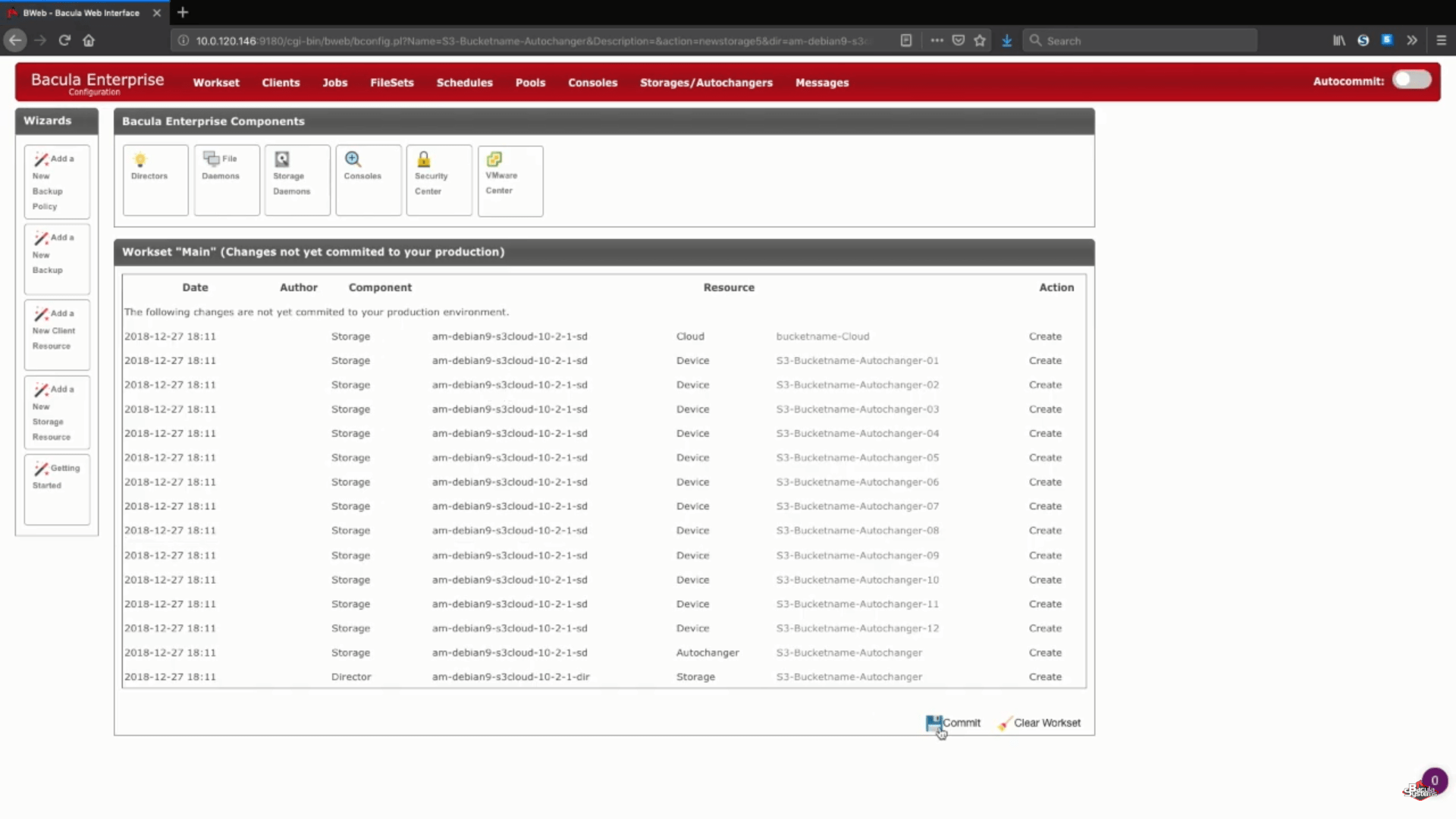
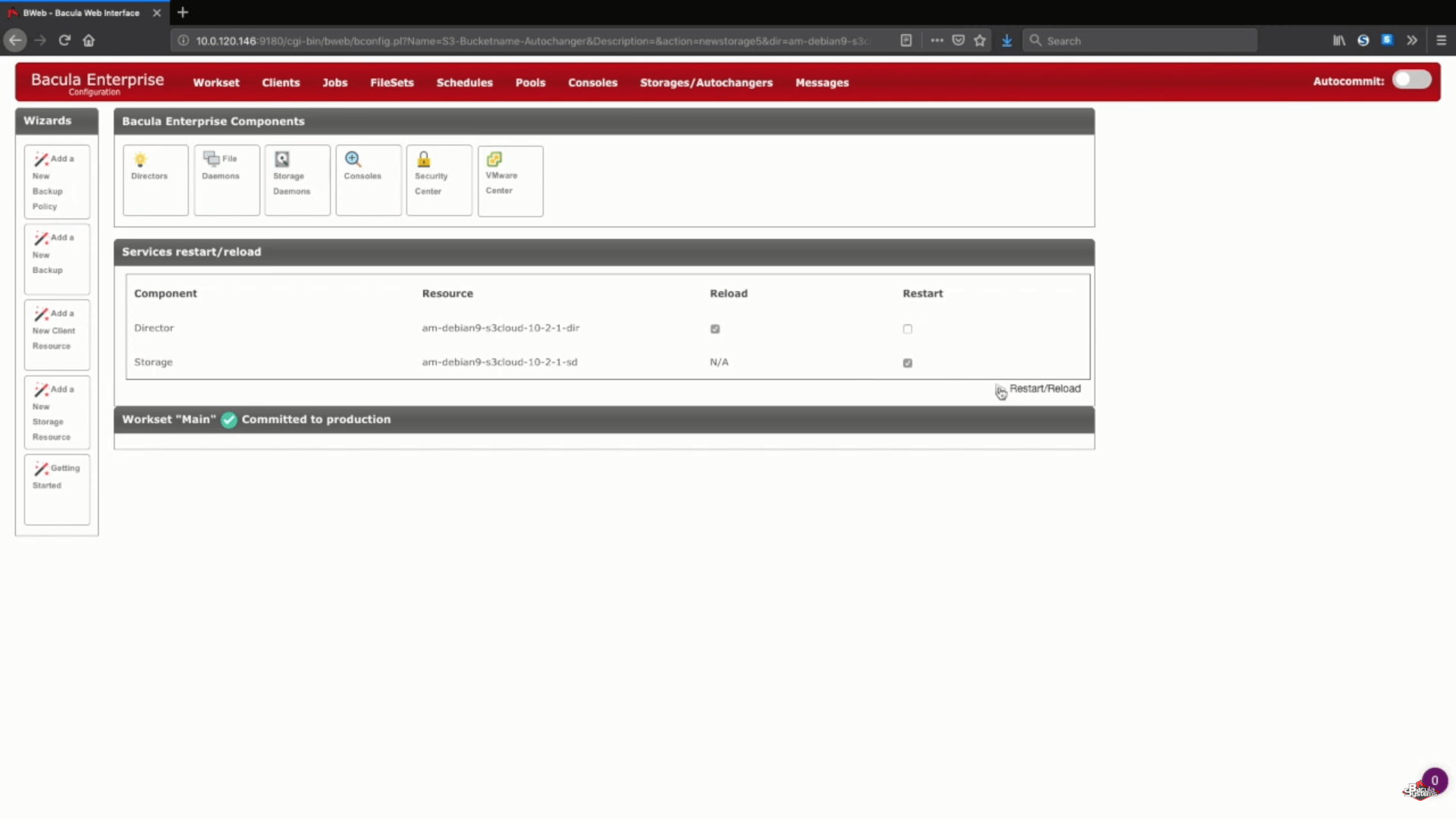
Um passo lógico depois disso seria a criação de novos pools de backup para esse armazenamento específico em nuvem e a configuração adequada de tarefas para gravar dados nos novos pools. Você pode acessar a documentação do Bacula, contatar nosso suporte ou ver nosso canal no YouTube para obter ajuda com relação a esses passos.
Testando as configurações do backup do AWS
Para testar se tudo o que acabamos de fazer está funcionando corretamente, faremos uma pequena tarefa de backup completo do Amazon S3 manualmente, diretamente no novo dispositivo de armazenamento. Normalmente, esse processo é automatizado usando um cronograma de tarefas e/ou outras configurações.
Após a execução da tarefa, poderemos ver os registros de todo o processo, e esta seção específica (na imagem abaixo) nos mostra que tudo foi carregado corretamente.
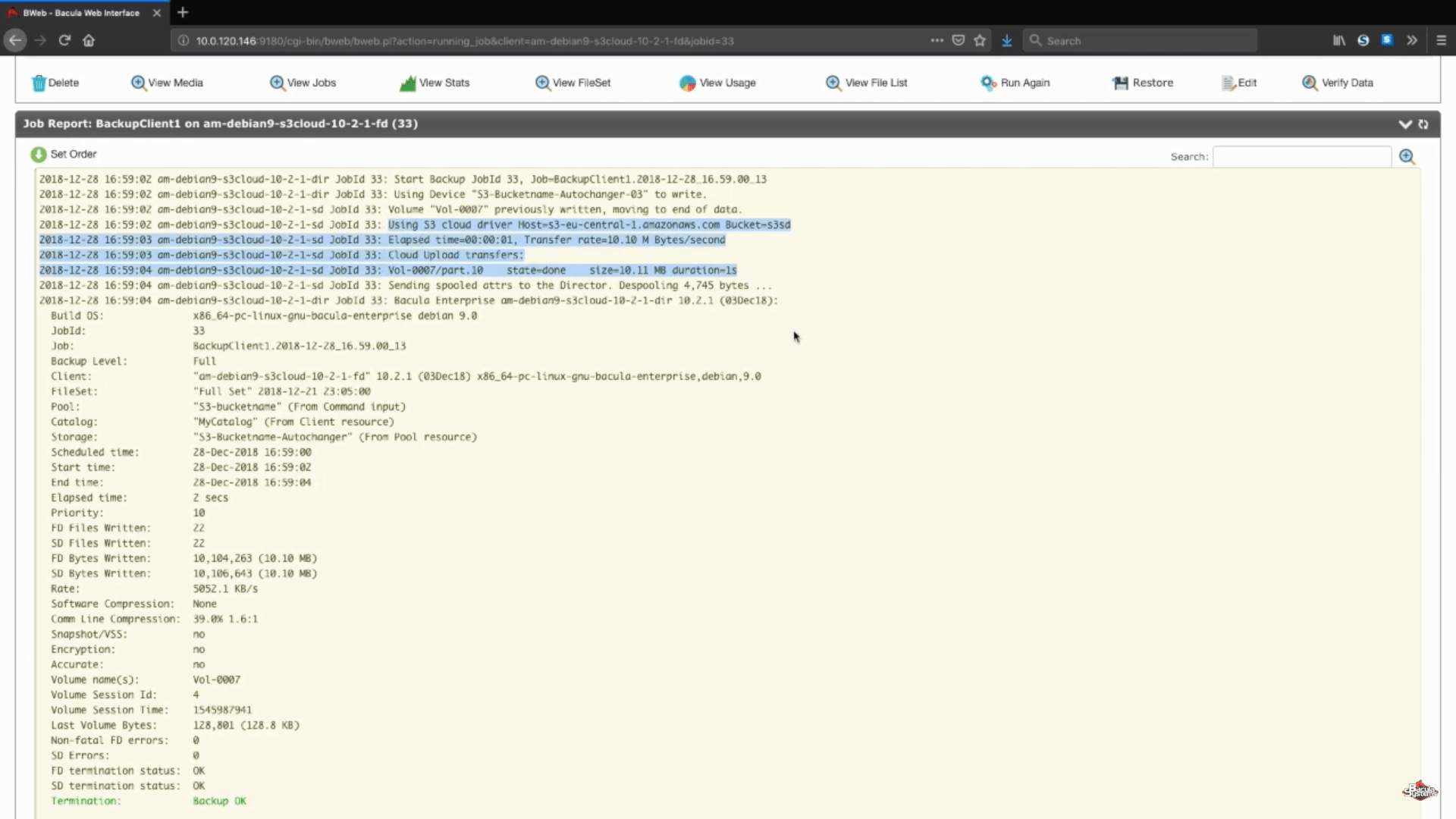
Conclusão
O Bacula Enterprise é uma ótima escolha para administrar seu AWS S3 e outros backups em nuvem de maneira confiável, incluindo a criação e configuração de novos armazenamentos de backup, e a criação de tarefas de backup a serem executadas automaticamente. Ele também tem funcionalidades avançadas de configuração e personalização, combinadas com recursos anti-ransomware extremamente modernos e atualizados.

