Kubernetes Sicherungs- und Wiederherstellungslösungen
Bacula sichert Ihre Cluster – von GitOps bis zum Tape.
Die Kubernetes-Orchestrierung bietet eine beeindruckende Agilität, wenn es um die Bereitstellung als Ganzes geht, aber ihre dynamische Natur führt auch zu komplexen Herausforderungen im Bereich der Datensicherung. Kritische Anwendungsdaten und -konfigurationen müssen jederzeit wiederherstellbar sein, um die Servicekontinuität aufrechtzuerhalten, selbst wenn Pods ausfallen oder Cluster katastrophale Probleme haben. Die nativen Kubernetes-Tools(etcdctl, kubectl) bieten nur einfache Snapshot-Funktionen und verfügen nicht über die Funktionen für die Automatisierung der Planung, die Verwaltung der Aufbewahrung, die Verschlüsselung und die Compliance, die alle Unternehmensumgebungen benötigen.
Bacula Enterprise ist ein großartiges Beispiel für eine solche Backup- und Wiederherstellungslösung für Unternehmen. Es bietet speziell entwickelte Kubernetes-Backup-Funktionen durch direkte API-Integration zum Schutz von Clustern, persistenten Volumes und Anwendungskonfigurationen, ohne dass Agenten installiert oder laufende Workloads unterbrochen werden müssen. Die betreffende Plattform eignet sich für alles, von Entwicklungsclustern mit nur Dutzenden von Pods bis hin zu Produktionsinfrastrukturen, die Tausende von Containern gleichzeitig verwalten. Die Lösung von Bacula bietet automatisierte Schutzfunktionen, die den kompletten Anwendungsstatus erfassen, unabhängig davon, wie komplex die Bereitstellung tatsächlich ist.
Einfache Cluster-Snapshots reichen in modernen Unternehmensumgebungen nicht mehr aus, vor allem, wenn man die Compliance-Anforderungen im Auge hat. Daher benötigen Unternehmen heute verschlüsselte Backups, unveränderlichen Speicher, granulare Wiederherstellungsoptionen und detaillierte Prüfprotokolle, um nachzuweisen, dass ihre Datensicherungsbemühungen alle erforderlichen gesetzlichen Standards erfüllen. Bacula Enterprise bietet Datenschutzfunktionen auf Unternehmensniveau, die Frameworks wie GDPR, HIPAA, SOC 2 und viele andere branchenspezifische Vorschriften erfüllen und gleichzeitig das hohe Maß an Geschwindigkeit und Flexibilität bieten, das Kubernetes-Anwender standardmäßig erwarten.
Bacula ist nicht nur in der Lage, Raw Volumes oder Cluster-Snapshots zu sichern, sondern kann auch ganze Anwendungen in einem brauchbaren Zustand rekonstruieren, einschließlich:
- Persistente Daten → Persistent Volume Claims (PVCs), Speicherklassen, CSI-Snapshots.
- Konfiguration & Metadaten → ConfigMaps, Secrets, Anmerkungen, Labels.
- Bereitstellungskontext → Bereitstellungen, StatefulSets, Helm-Diagramme, Operatoren.
- Service Exposure → Dienste, Ingress-Regeln und Netzwerkabhängigkeiten.
Bacula Enterprise ist außerdem vollständig kompatibel mit Tanzu, Rancher Longhorn, OKD und vielen anderen Kubernetes-bezogenen Umgebungen.

Die Kubernetes-Sicherungsfunktionen von Bacula Enterprise
- Sicherung der Konfiguration von Kubernetes-Cluster-Ressourcen
- Fähigkeit zur Wiederherstellung einzelner Kubernetes-Konfigurationsressourcen
- Sicherung und Wiederherstellung persistenter Daten
- Wiederherstellung der Konfiguration von Kubernetes-Ressourcen in einem lokalen Verzeichnis
- Konsistenzgesicherte Sicherung und Wiederherstellung von persistenten Volumes
- Fähigkeit zur Wiederherstellung von Kubernetes persistenten Volumes in einem lokalen Verzeichnis
- CSI-Snapshot-Unterstützung
Das Kubernetes-Modul von Bacula Enterprise kann eine Reihe von Kubernetes-Ressourcen sichern, einschließlich, aber nicht ausschließlich:
- Einsätze
- Pods
- Dienste
- Persistente Volume-Ansprüche

Kubernetes Plugin Konfiguration & Bereitstellung
Plugin-Architektur und Integration
- Design des File Daemon-Moduls – Verwendet ein standardmäßiges Bacula File Daemon-Plugin, das sich problemlos in die bestehende Bacula-Infrastruktur integrieren lässt, so dass keine separaten Backup-Server oder dedizierten Verwaltungsschichten speziell für Kubernetes-Umgebungen erforderlich sind.
- Flexible Einsatzoptionen – Bacula kann auf Kubernetes-Master-Knoten, Worker-Knoten oder externen Management-Servern mit Netzwerkzugriff auf die Kubernetes-API installiert werden, was eine hohe Flexibilität bei der Bereitstellung je nach Sicherheitsanforderungen und Netzwerkarchitektur ermöglicht.
- Zero Workload Modification – Sie können Cluster sichern, ohne Container-Images, Kubernetes-Manifeste oder laufende Pod-Konfigurationen zu ändern. Dadurch entfällt die Notwendigkeit, Anwendungsteams zu koordinieren oder Änderungen an der Bereitstellungspipeline zu planen.
Cluster-Zugang und -Erkennung
- Mehrere Authentifizierungsmethoden – Die Lösung kann sich mit Kubernetes-Clustern verbinden, indem sie kubeconfig-Dateien, Token für Dienstkonten oder eine clusterinterne Authentifizierung für Pods, die innerhalb von Kubernetes ausgeführt werden, verwendet und so verschiedene Sicherheitsarchitekturen und Einsatzszenarien unterstützt.
- Automatische Ressourcenaufzählung – Das Plugin fragt die Kubernetes-API ab, um Namespaces, Bereitstellungen, Dienste, persistente Volumes und andere Ressourcen zu ermitteln, die für den Schutz zur Verfügung stehen, und schafft so Möglichkeiten für die Planung und Validierung von Backups, bevor der Auftrag ausgeführt wird.
- Auswahl auf Namespace-Ebene – Zielt auf bestimmte Namespaces für die Sicherung ab oder schließt System-Namespaces von Sicherungsaufträgen aus und bietet so eine granulare Kontrolle darüber, welche Cluster-Komponenten von der Sicherung erfasst werden sollen.
Workflow für Sicherungsvorgänge
- API-gesteuerte Datenerfassung – Ruft Cluster-Konfigurationen und persistente Volume-Daten über Kubernetes-API-Aufrufe und nicht über Dateisystemzugriff ab, um die Kompatibilität mit verschiedenen Speicher-Backends und Container-Laufzeitumgebungen zu gewährleisten.
- Bereitstellung von Backup-Proxy-Pods – Startet automatisch temporäre Proxy-Pods (mit geringem Ressourcenverbrauch) innerhalb des Clusters, um die Übertragung von Persistent-Volume-Daten zu erleichtern; diese Pods werden nach Abschluss des Backups ebenfalls automatisch entfernt, um einen zusätzlichen Cluster-Ressourcenverbrauch außerhalb der Backup-Fenster zu vermeiden.
- Konfigurierbare Ausführungskontrolle – Sowohl Befehle vor als auch nach dem Backup können in bestimmten Pods ausgeführt werden, um anwendungskonsistente Backups von Datenbanken oder zustandsbehafteten Anwendungen (die vor der Datenerfassung ein Quiescing erfordern) zu erstellen.
Steuerelemente für Wiederherstellungsvorgänge
- Duale Wiederherstellungsziele – Stellen Sie Kubernetes-Ressourcen über die API direkt in Clustern wieder her oder exportieren Sie Konfigurationen und Volume-Daten für alle möglichen Zwecke in lokale Verzeichnisse.
- Flexible Benennungsoptionen – Workloads können entweder mit den Originalnamen für die Wiederherstellung an Ort und Stelle oder mit neuen, generierten Namen auf der Grundlage der ursprünglichen Bezeichner und Job-Metadaten (für parallele Testumgebungen oder Blue-Green Deployment-Szenarien) wiederhergestellt werden.
- Selektive Ressourcenwiederherstellung – Das Plugin bietet die Wahl zwischen kompletten Clustern, einzelnen Namespaces, spezifischen Bereitstellungen oder einzelnen persistenten Volumes, je nach den Anforderungen an den Wiederherstellungsumfang, um eine unnötige Wiederherstellung der nicht betroffenen Infrastruktur während gezielter Wiederherstellungsvorgänge zu vermeiden.
Verwaltung und Überwachung
- Einheitliche Verwaltungskonsole – Konfigurieren und überwachen Sie Kubernetes-Backup-Jobs über die grafische BWeb-Oberfläche von Bacula zusammen mit anderen Infrastruktur-Schutzmaßnahmen, so dass keine separaten Kubernetes-spezifischen Backup-Verwaltungstools erforderlich sind.
- Automatisierung über die Befehlszeile – Verwenden Sie bconsole für die skriptfähige Jobkonfiguration, für automatisierte Wiederherstellungstests und für die Integration in bestehende betriebliche Runbooks und Disaster-Recovery-Verfahren.
- Umfassende Protokollierung – Erfasst detaillierte Betriebsprotokolle einschließlich API-Interaktionen, Status der Ressourcenverarbeitung und Datenübertragungsmetriken für die Fehlerbehebung, Leistungsanalyse und Compliance-Dokumentation.
Vorteile des Kubernetes-Sicherungs- und Wiederherstellungsmoduls
Agentenloser Cluster-Schutz
- Integration auf API-Ebene – Schützt Kubernetes-Cluster durch direkte API-Kommunikation, ohne dass Backup-Agenten in Container-Images installiert oder Pod-Spezifikationen geändert werden müssen. Damit entfallen der Wartungsaufwand und die Sicherheitsbedenken, die mit Backup-Software in Containern verbunden sind.
- Keine Änderungen an der Infrastruktur – Sichert laufende Cluster, ohne dass Änderungen an Deployments, StatefulSets oder Helm-Diagrammen erforderlich sind. Dies ermöglicht den sofortigen Schutz bestehender Workloads, ohne dass Images neu erstellt oder Kubernetes-Manifeste aktualisiert werden müssen.
- Automatische Erkennung von Workloads – Neue Namespaces und Deployments, die mit den Backup-Richtlinien übereinstimmen, werden automatisch und ohne manuelle Job-Konfiguration geschützt, so dass eine konsistente Abdeckung gewährleistet ist, wenn die Kubernetes-Infrastruktur skaliert und weiterentwickelt wird.
Vollständige Erfassung des Anwendungsstatus
- Einheitliche Konfigurationssicherung – Erfasst alle Kubernetes-Ressourcen, die das Anwendungsverhalten definieren, einschließlich Deployments, Services, ConfigMaps, Secrets, Ingress-Regeln und Ressourcenkontingente als zusammenhängende Sicherungssätze und nicht als isolierte Komponenten.
- Persistent Data Protection – Sichert den Anwendungsstatus, der neben den Cluster-Konfigurationen in Persistent Volume Claims gespeichert ist, und stellt sicher, dass Workloads mit ihren Daten und nicht nur mit leeren Container-Definitionen wiederhergestellt werden können.
- Konsistente Cluster-Snapshots – Koordiniert die Sicherung des etcd-Cluster-Status mit persistenten Volume-Daten, um die Konsistenz zwischen der Konfiguration der Kubernetes-Kontrollebene und dem tatsächlichen Anwendungsspeicher aufrechtzuerhalten und die Wiederherstellung von nicht übereinstimmenden Infrastrukturzuständen zu verhindern.
Agentenloser Cluster-Schutz
- Integration auf API-Ebene – Schützt Kubernetes-Cluster durch direkte API-Kommunikation, ohne dass Backup-Agenten in Container-Images installiert oder Pod-Spezifikationen geändert werden müssen. Damit entfallen der Wartungsaufwand und die Sicherheitsbedenken, die mit Backup-Software in Containern verbunden sind.
- Keine Änderungen an der Infrastruktur – Sichert laufende Cluster, ohne dass Änderungen an Deployments, StatefulSets oder Helm-Diagrammen erforderlich sind. Dies ermöglicht den sofortigen Schutz bestehender Workloads, ohne dass Images neu erstellt oder Kubernetes-Manifeste aktualisiert werden müssen.
- Automatische Erkennung von Workloads – Neue Namespaces und Deployments, die mit den Backup-Richtlinien übereinstimmen, werden automatisch und ohne manuelle Job-Konfiguration geschützt, so dass eine konsistente Abdeckung gewährleistet ist, wenn die Kubernetes-Infrastruktur skaliert und weiterentwickelt wird.
Vollständige Erfassung des Anwendungsstatus
- Einheitliche Konfigurationssicherung – Erfasst alle Kubernetes-Ressourcen, die das Anwendungsverhalten definieren, einschließlich Deployments, Services, ConfigMaps, Secrets, Ingress-Regeln und Ressourcenkontingente als zusammenhängende Sicherungssätze und nicht als isolierte Komponenten.
- Persistent Data Protection – Sichert den Anwendungsstatus, der neben den Cluster-Konfigurationen in Persistent Volume Claims gespeichert ist, und stellt sicher, dass Workloads mit ihren Daten und nicht nur mit leeren Container-Definitionen wiederhergestellt werden können.
- Konsistente Cluster-Snapshots – Koordiniert die Sicherung des etcd-Cluster-Status mit persistenten Volume-Daten, um die Konsistenz zwischen der Konfiguration der Kubernetes-Kontrollebene und dem tatsächlichen Anwendungsspeicher aufrechtzuerhalten und die Wiederherstellung von nicht übereinstimmenden Infrastrukturzuständen zu verhindern.
Sichere und effiziente Bereitstellung von Kubernetes-Clustern
Effektive DevOps-Umgebungen müssen skalierbar und so weit wie möglich automatisiert sein. Bacula Enterprise ist auf Stabilität, Zuverlässigkeit und hohe Skalierbarkeit ausgelegt und seine Container-Backup-Module zielen darauf ab, die Arbeit von IT- und DevOps-Abteilungen zu erleichtern, die Docker, Kubernetes, SUSE oder Openshift einsetzen. Es macht den Einsatz von Kubernetes deutlich sicherer und bequemer.
Ganz gleich, ob Sie Ihre Container-Umgebung für das Lift-and-Shift von monolithischen Anwendungen, das Refactoring von Legacy-Anwendungen oder den Aufbau neuer verteilter Anwendungen einsetzen – Entwickler und Systemadministratoren können die fortschrittliche Kubernetes-Backup-Technologie von Bacula mit einem besonders hohen Maß an Flexibilität nutzen – entweder über die grafische Benutzeroberfläche von Bacula oder über die Befehlszeilenschnittstelle. Denken Sie daran, dass dieses hohe Maß an Flexibilität und Anpassungsmöglichkeiten grundlegend für den Ansatz von Bacula ist: den Benutzer durch die Einführung einer breiten Palette von Optionen zur Erreichung seiner Ziele zu unterstützen.
Warum Kubernetes-Umgebungen sichern?
Da zustandsbehaftete Anwendungen zunehmend auf Kubernetes umgestellt werden, wird der Schutz von persistenten Daten und Clusterkonfigurationen für Produktionsumgebungen entscheidend. Unternehmen müssen SLAs einhalten und sicherstellen, dass containerisierte Dienste in korrekten Zuständen verfügbar bleiben. Daher sind effektive Backups und Wiederherstellungen für jede Kubernetes-Produktionsumgebung unerlässlich.
Bacula Enterprise ermöglicht die Mobilität von Clustern durch flexible Wiederherstellungsvorgänge. Unternehmen können persistente Volumes und Konfigurationen in verschiedenen Kubernetes-Clustern wiederherstellen und so die Migration zwischen Cloud-Anbietern, die Notfallwiederherstellung an alternativen Standorten und die schnelle Replikation von Umgebungen für Tests unterstützen. Diese Flexibilität reduziert die Anbieterbindung und vereinfacht Multi-Cloud-Kubernetes-Strategien für AWS, GCP, Azure und private Infrastrukturen.
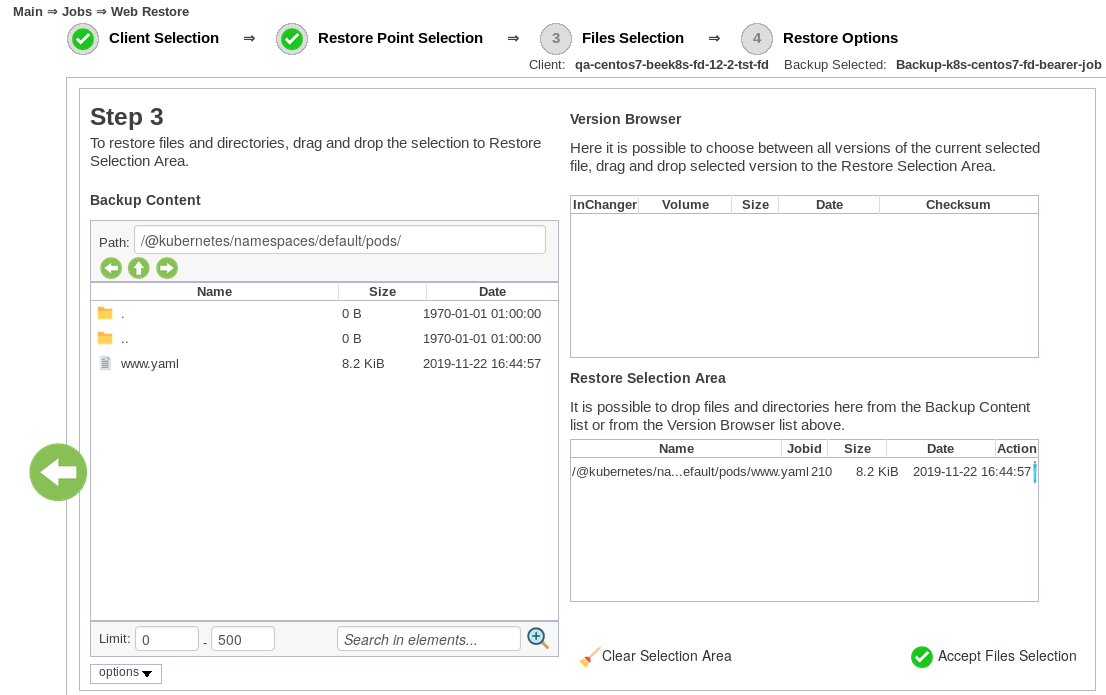
Kubernetes Wiederherstellungsprozess
Das Bacula Kubernetes-Backup-Modul bietet zwei Ziele für die Wiederherstellung an:
- Wiederherstellung direkt in den Kubernetes-Cluster
- Wiederherstellung in ein lokales Verzeichnis
Um eine optimale Sicherung und Wiederherstellung von Kubernetes-Container-Umgebungen zu gewährleisten, sollten die Daten automatisch gesichert werden und die Systemadministratoren sollten die Sicherungen regelmäßig testen, um sicherzustellen, dass sie im Falle einer Wiederherstellung das tun, was nötig ist.
Zentrale Enterprise-Funktionen für jeden Bacula-Benutzer
Das Kubernetes-Backup-Modul arbeitet innerhalb der umfassenden Datensicherungsplattform von Bacula Enterprise. Alle in diesem Abschnitt beschriebenen Funktionen sind plattformübergreifende Funktionen, die in jeder Bacula-Installation, einschließlich Kubernetes-Umgebungen, verfügbar sind.
Datenschutz & Compliance
Unternehmenssicherheit und die Einhaltung gesetzlicher Vorschriften sind für die Architektur von Bacula von grundlegender Bedeutung:
- Verschlüsselung in der gesamten Backup-Kette – Die AES-256-Verschlüsselung schützt Kubernetes-Konfigurationen, persistente Volumendaten und etcd-Backups von der Erfassung über die Netzwerkübertragung bis hin zum endgültigen Speicherziel, wobei die flexible Schlüsselverwaltung sowohl zentralisierte als auch verteilte Architekturen unterstützt.
- Ransomware-resistenter Speicher – Die Integration mit WORM-Speichersystemen (Write Once, Read Many) und unveränderlichen Backup-Zielen verhindert die unbefugte Änderung oder Löschung von Kubernetes-Backup-Daten und schützt so vor Ransomware-Angriffen und bösartigen Insider-Bedrohungen, die auf die Backup-Infrastruktur abzielen.
- Rollenbasierte Berechtigungssysteme – Granulare Zugriffskontrollen schränken ein, welche Administratoren bestimmte Namespaces sichern, bestimmte Arbeitslasten wiederherstellen oder auf Clusterkonfigurationen zugreifen können, was eine Aufgabentrennung ermöglicht und den Aktionsradius bei Sicherheitsvorfällen begrenzt.
- Umfassende Prüfprotokolle – Jeder Sicherungsvorgang, jede Wiederherstellungsanforderung und jede Konfigurationsänderung wird mit Zeitstempel und Benutzerzuordnung protokolliert. So erhalten Sie die detaillierten Aktivitätsaufzeichnungen, die Sie für Compliance-Berichte, Sicherheitsanalysen und forensische Untersuchungen benötigen.
- Anpassung an Branchenvorschriften – Integrierte Funktionen erfüllen die Anforderungen von GDPR, HIPAA, SOC 2, PCI DSS und branchenspezifischen Vorschriften durch konfigurierbare Aufbewahrungskontrollen, Verschlüsselungsstandards und Audit-Protokollierung, die die Einhaltung von Datenschutzvorschriften belegen.
- Zero-Knowledge-Konfigurationsunterstützung – Die Architektur ermöglicht Szenarien, in denen Backup-Administratoren Kubernetes-Schutzoperationen verwalten, ohne auf sensible Anwendungsdaten, ConfigMaps oder in Backups enthaltene Secrets zuzugreifen.
Wiederherstellung & Geschäftskontinuität
Umfassende Wiederherstellungsfunktionen gewährleisten eine schnelle Wiederherstellung nach jedem Ausfallszenario:
- Verteilungsübergreifende Datenübertragung – Extrahieren und Wiederherstellen von Kubernetes-Ressourcen zwischen verschiedenen Distributionen und Plattformen, um Migrationen von On-Premises in die Cloud, zwischen Cloud-Anbietern oder von einer Kubernetes-Variante zu einer anderen (EKS zu AKS, Rancher zu OpenShift usw.) zu ermöglichen.
- Replikation von Backups an mehreren Standorten – Kopieren Sie Kubernetes-Backups automatisch an geografisch verteilte Standorte, um sich vor Katastrophen auf Standortebene zu schützen und die Verfügbarkeit von Wiederherstellungspunkten unabhängig vom Status des primären Rechenzentrums sicherzustellen.
- Hochfrequente Sicherungspläne – Die Unterstützung von Sicherungsintervallen, die in Minuten statt in Stunden gemessen werden, bietet einen nahezu kontinuierlichen Schutz für sich schnell ändernde containerisierte Anwendungen und minimiert potenzielle Datenverlustfenster.
Speicherinfrastruktur & Effizienz
Bacula maximiert den Wert des Speichers durch intelligente Datenverwaltung und Zielflexibilität:
- Globale Deduplizierung – Eliminiert doppelte Datenblöcke in allen Kubernetes-Backups, unabhängig von Namespace, Cluster oder Backup-Auftrag, und speichert jeden einzelnen Block nur einmal, um den Speicherverbrauch drastisch zu reduzieren.
- Konfigurierbare Komprimierungsalgorithmen – Wendet eine Komprimierung an, die den CPU-Overhead gegen die Speicherplatzersparnis auf der Grundlage von Datenmerkmalen abwägt, wobei die Algorithmusauswahl für die Kubernetes-Arbeitslastmuster optimiert ist.
- Immerwährende inkrementelle Architektur – Nach der ersten vollständigen Sicherung werden bei allen nachfolgenden Vorgängen nur die geänderten Daten erfasst, wodurch wiederkehrende vollständige Sicherungen und die damit verbundenen Speicher- und Zeitanforderungen entfallen.
- Umgang mit spärlichen Daten – Erkennt und verarbeitet spärliche Dateien und Volumes auf intelligente Weise und sichert nur zugewiesene Blöcke und nicht den leeren Speicherplatz, der bei Ansprüchen auf persistente Volumes üblich ist.
- Netzwerkeffiziente Operationen – Algorithmen zur Änderungsverfolgung minimieren die Bandbreitennutzung, indem nur geänderte Blöcke zwischen den Sicherungsläufen übertragen werden, was für verteilte Kubernetes-Cluster an mehreren Standorten entscheidend ist.
- Heterogene Speicherziele – Schreiben Sie Kubernetes-Backups auf Festplatten-Arrays, NAS/SAN-Speicher, Cloud-Objektspeicher (S3, Azure Blob, Google Cloud Storage), Bandbibliotheken oder eine beliebige Kombination auf der Grundlage von Aufbewahrungs- und Leistungsanforderungen.
- Automatisierte Tiering-Workflows – Migrieren Sie Backup-Daten zwischen Speicherklassen auf der Grundlage von Alter, Zugriffsmustern oder benutzerdefinierten Richtlinien und verschieben Sie ältere Kubernetes-Backups automatisch in einen wirtschaftlichen Langzeitspeicher.
- Universelle S3-Kompatibilität – Integration mit jedem S3-kompatiblen Speicheranbieter wie AWS, MinIO, Wasabi, Backblaze B2 und anderen für eine flexible, kostengünstige Langzeitspeicherung.
Unternehmensmanagement & Kontrolle
Zentralisierte Verwaltungstools bieten Transparenz und Kontrolle über alle Kubernetes-Backup-Vorgänge:
- Zwei Verwaltungsoberflächen – Wählen Sie zwischen einer grafischen Webkonsole (BWeb) für die visuelle Verwaltung und voll funktionsfähigen Befehlszeilentools für die Automatisierung, Skripterstellung und Integration von DevOps-Workflows.
- Mandantenfähige Architektur – Service Provider und große Unternehmen können isolierte Umgebungen mit unabhängigen Kubernetes-Backup-Konfigurationen, separaten Ressourcenpools, benutzerdefiniertem Branding und eindeutigen Verwaltungsgrenzen erstellen.
- Detailliertes Reporting Framework – Erstellen Sie Backup-Statusberichte, Analysen der Speichernutzung, Compliance-Dokumentation, SLA-Metriken und Leistungsstatistiken, die nach einem bestimmten Zeitplan an die Beteiligten übermittelt werden.
- Externe Integrationspunkte – Verbinden Sie sich mit Überwachungsplattformen, ITSM-Ticketing-Systemen, SIEM-Lösungen und Identitätsanbietern (LDAP, Active Directory) für einen einheitlichen IT-Betrieb und Single Sign-On.
- Automatisierte Ressourcenerkennung – Erkennen und inventarisieren Sie Kubernetes-Cluster, Namespaces, persistente Volumes und Bereitstellungen in der gesamten Infrastruktur mit Abfragefunktionen, die die Planung und Überprüfung von Backups unterstützen.
- Kontrolle der Auswirkungen auf die Arbeitslast – Passen Sie die Gleichzeitigkeit von Backups, die Bandbreitenbegrenzung und die Ressourcenzuweisung an, um die Geschwindigkeit der Sicherung gegen die Auswirkungen auf die Leistung des Kubernetes-Clusters in der Produktion abzuwägen.
- Unbegrenzt skalierbare Architektur – Das Design unterstützt Umgebungen von einzelnen Entwicklungsclustern bis hin zu Tausenden von Kubernetes-Produktionsinstallationen unter zentraler Verwaltung mit verteilter Backup-Ausführung.
Wirtschaftliche Vorteile
Das Lizenzierungsmodell von Bacula Enterprise beseitigt kapazitätsabhängige Preishindernisse:
- Cluster-unabhängige Lizenzierung – Die Anzahl der Kubernetes-Cluster, Namespaces, Pods oder persistenten Volumes wirkt sich nicht auf die Lizenzkosten aus und ermöglicht eine unbegrenzte Erweiterung der containerisierten Infrastruktur ohne Budgetbeschränkungen.
- Vorhersehbare Investitionsplanung – Eine unkomplizierte Preisstruktur verhindert Budgetüberraschungen, wenn die Einführung von Kubernetes zunimmt, die Anzahl der Container steigt oder die Datenmengen im Unternehmen wachsen.
- Ressourcenunabhängiges Kostenmodell – Die Anzahl der Pods, StatefulSet-Mengen, PVC-Größen und etcd-Backup-Volumina führen nicht zu Lizenzerhöhungen, im Gegensatz zu Wettbewerbern, deren Preise auf geschützten Kapazitäten oder Ressourceneinheiten basieren.
- Wirtschaftliche Vorteile bei hohen Volumina – Unternehmen, die umfangreiche oder schnell skalierende Kubernetes-Infrastrukturen schützen, erhalten zunehmend signifikante Kostenvorteile im Vergleich zu Wettbewerbern mit kapazitätsbasierter Lizenzierung.
- Profitabilität für Service Provider – MSPs und Hosting-Provider können Kubernetes-Backup-Funktionen für Unternehmen anbieten und dabei gesunde Margen beibehalten, die nicht durch das Wachstum von Tenant-Clustern oder die Erweiterung von Daten eingeschränkt werden.
Häufig gestellte Fragen
Warum nicht einfach native Kubernetes-Backup-Tools verwenden?
Native Tools wie etcdctl bieten grundlegende Cluster-Snapshots, aber ihnen fehlen Unternehmensfunktionen wie Verschlüsselung, Compliance-Berichte, langfristige Aufbewahrungsrichtlinien und eine zentrale Verwaltung über eine heterogene Infrastruktur hinweg. Außerdem integrieren sie Kubernetes-Backups nicht in umfassendere IT-Backup-Strategien für Datenbanken, VMs und physische Server. Bacula Enterprise bietet einen einheitlichen Schutz für Ihre gesamte Infrastruktur und erfüllt gleichzeitig die gesetzlichen Anforderungen und Audit-Standards.
Wie unterscheidet sich die Sicherung von Kubernetes-Clustern von der Sicherung virtueller Maschinen?
Kubernetes-Cluster bestehen aus mehreren miteinander verbundenen Komponenten – etcd-Status, persistente Volumes, ConfigMaps, Secrets und Ressourcendefinitionen -, die als zusammenhängende Einheit und nicht als einzelne Festplatten-Images gesichert werden müssen. VM-Backups erfassen den gesamten Maschinenzustand auf Hypervisor-Ebene, während Kubernetes-Backups eine Integration auf API-Ebene erfordern, um Container-Orchestrierung und Anwendungsabhängigkeiten zu verstehen. Die dynamische, flüchtige Natur von Pods bedeutet, dass Backup-Lösungen schnell wechselnde Arbeitslasten verfolgen und sowohl die Infrastrukturkonfiguration als auch die Anwendungsdaten separat erfassen müssen.
Kann ich Kubernetes-Cluster sichern, während sie laufen?
Ja, Bacula führt Backups von laufenden Kubernetes-Clustern durch, ohne dass Ausfallzeiten erforderlich sind oder Arbeitslasten angehalten werden müssen. Das Plugin erfasst den Cluster-Status und persistente Volume-Daten über die Kubernetes-API, während die Anwendungen normal weiterlaufen. Bei Anwendungen, die Konsistenz erfordern, kann Bacula vor der Datenerfassung Befehle innerhalb der Pods ausführen, um Datenbanken stillzulegen oder Puffer zu leeren, bevor die Daten erfasst werden.
Wie kann ich auf eine andere Kubernetes-Distribution wiederherstellen?
Bacula stellt Kubernetes-Ressourcen als standardmäßige YAML-Konfigurationen und persistente Volume-Daten wieder her, die auf jede konforme Kubernetes-Distribution angewendet werden können. Während der Wiederherstellung geben Sie die Verbindungsdetails des Zielclusters an, und Bacula erstellt Namespaces, Bereitstellungen, Dienste und Daten auf der Zielplattform neu. Einige distributionsspezifische Funktionen müssen möglicherweise manuell angepasst werden, aber die Kernarbeitslasten werden in der Regel zwischen EKS, AKS, GKE, OpenShift und Standard-Kubernetes-Installationen übertragen.
Was passiert mit meinen Daten, wenn Pods gelöscht werden?
Die Daten im Pod-Dateisystem gehen sofort verloren, wenn Pods zerstört werden, es sei denn, Sie verwenden persistente Volumes, um den Anwendungsstatus extern zu speichern. Bei ephemeren Containern, die ohne PVCs laufen, gehen alle Daten, die während ihrer Lebensdauer geschrieben wurden, verloren, wenn sie beendet werden. Die automatisierten Cluster-Backups von Bacula erfassen sowohl die Pod-Konfigurationen, die für die Wiederherstellung von Containern benötigt werden, als auch die Daten auf den persistenten Volumes, die den kritischen Anwendungsstatus enthalten, und gewährleisten so eine vollständige Wiederherstellung unabhängig von den Ereignissen im Pod-Lebenszyklus.
Weitere Hilfe zur Sicherung von Kubernetes-Containern:
- Möchten Sie alle unsere Backup-Lösungen sehen? Volle Unterstützung für Hypervisor und Datenbanken.
- Unsere Server-Backup-Lösungen umfassen Tools für Windows, Linux und mehr.
- Sehen Sie sich die Funktionen des Bacula Enterprise Datensicherungs- und Wiederherstellungsprogramms an.
- Unterstützt Bacula Ihren Speichertyp? Werfen Sie einen Blick auf unsere Storage-Backup-Lösungen.
- Lesen Sie unsere Vision von flexiblen und skalierbaren Backup-Software-Systemen.
- Interessieren Sie sich für Sybase-Backup und -Wiederherstellung? Werfen Sie einen Blick auf unsere SAP ASE-Backup-Lösung.
Das könnte Sie auch interessieren: