Come fare il backup di Kubernetes? Backup e ripristino di Kubernetes.
Bacula protegge i vostri cluster, da GitOps al nastro.
L’orchestrazione Kubernetes offre un’agilità impressionante quando si tratta di implementazione nel suo complesso, ma la sua natura dinamica tende anche a creare sfide complesse nel reparto di protezione dei dati. I dati e le configurazioni delle applicazioni critiche devono essere sempre recuperabili per mantenere la continuità del servizio, anche in caso di guasti dei pod o di problemi gravi dei cluster. Gli strumenti nativi di Kubernetes (etcdctl, kubectl) offrono solo funzionalità di snapshot di base, prive delle caratteristiche di automazione della pianificazione, gestione della conservazione, crittografia e conformità necessarie in tutti gli ambienti aziendali.
Bacula Enterprise è un ottimo esempio di soluzione di backup e ripristino di livello aziendale, che offre funzionalità di backup Kubernetes appositamente progettate attraverso l’integrazione diretta dell’API per proteggere cluster, volumi persistenti e configurazioni delle applicazioni senza la necessità di installare agenti o interrompere i carichi di lavoro in esecuzione. La piattaforma in questione si occupa di tutto, dai cluster di sviluppo con solo poche decine di pod alle infrastrutture di produzione che gestiscono migliaia di container contemporaneamente. La soluzione Bacula offre funzionalità di protezione automatizzate che acquisiscono lo stato completo dell’applicazione, indipendentemente dalla complessità della sua implementazione.
Le semplici istantanee dei cluster non sono più sufficienti in un ambiente aziendale moderno, soprattutto se si considerano tutti i requisiti di conformità. Pertanto, le aziende necessitano ora di backup crittografati, archiviazione immutabile, opzioni di ripristino granulare e audit trail dettagliati per dimostrare che le loro misure di protezione dei dati soddisfano tutti gli standard normativi richiesti. Bacula Enterprise offre funzionalità di protezione dei dati di livello aziendale, soddisfacendo i requisiti di normative quali GDPR, HIPAA, SOC 2 e molte altre normative specifiche del settore, pur mantenendo l’elevato livello di velocità e flessibilità che gli utenti Kubernetes si aspettano di default.
Bacula non è solo in grado di eseguire il backup di volumi raw o snapshot di cluster, ma può anche ricostruire intere applicazioni in uno stato utilizzabile, tra cui:
- Dati persistenti → Persistent Volume Claims (PVC), classi di archiviazione, snapshot CSI.
- Configurazione e metadati → ConfigMap, segreti, annotazioni, etichette.
- Contesto di distribuzione → Distribuzioni, StatefulSets, grafici Helm, operatori.
- Esposizione dei servizi → Servizi, regole di ingresso e dipendenze di rete.
Bacula Enterprise è inoltre completamente compatibile con Tanzu, Rancher Longhorn, OKD e molti altri ambienti correlati a Kubernetes.

Funzionalità di backup Kubernetes di Bacula Enterprise
- Backup della configurazione delle risorse del cluster Kubernetes
- Possibilità di ripristinare una singola risorsa di configurazione Kubernetes
- Capacità di eseguire il backup e il ripristino dei dati persistenti
- Possibilità di ripristinare la configurazione delle risorse Kubernetes nella directory locale
- Backup e ripristino dei volumi persistenti con garanzia di coerenza
- Possibilità di ripristinare i dati dei volumi persistenti Kubernetes nella directory locale
- Supporto CSI Snapshot
Il modulo Kubernetes di Bacula Enterprise è in grado di eseguire il backup di numerose risorse Kubernetes, tra cui, a titolo esemplificativo ma non esaustivo:
- Distribuzioni
- Pod
- Servizi
- Richieste di volumi persistenti

Configurazione e implementazione del plugin Kubernetes
Architettura e integrazione del plugin
- Design del modulo File Daemon – Utilizza un plugin Bacula File Daemon standard che si integra facilmente con l’infrastruttura Bacula esistente, evitando la necessità di server di backup separati o di livelli di gestione dedicati per gli ambienti Kubernetes in particolare.
- Opzioni di distribuzione flessibili – Bacula può essere installato su nodi master Kubernetes, nodi worker o server di gestione esterni con accesso di rete all’API Kubernetes, garantendo un’ampia flessibilità in termini di distribuzione in base ai requisiti di sicurezza e all’architettura di rete.
- Zero modifiche del carico di lavoro – È in grado di proteggere i cluster senza modificare le immagini dei container, i manifesti Kubernetes o le configurazioni dei pod in esecuzione, il che elimina la necessità di coordinare i team applicativi o di pianificare le modifiche alla pipeline di distribuzione.
Accesso e scoperta del cluster
- Metodi di autenticazione multipli – La soluzione può connettersi ai cluster Kubernetes utilizzando i file kubeconfig, i token dell’account di servizio o l’autenticazione all’interno del cluster per i pod che vengono eseguiti all’interno di Kubernetes, fornendo supporto per diverse architetture di sicurezza e scenari di distribuzione.
- Enumerazione automatica delle risorse – Il plugin interroga l’API di Kubernetes per scoprire gli spazi dei nomi, le distribuzioni, i servizi, i volumi persistenti e altre risorse disponibili per la protezione, creando opportunità per la pianificazione e la convalida del backup prima dell’esecuzione del lavoro.
- Selezione a livello di spazio dei nomi – punta a spazi dei nomi specifici per il backup o esclude gli spazi dei nomi del sistema dai lavori di protezione, fornendo un controllo granulare su quali componenti del cluster devono ricevere la copertura di backup.
Flusso di lavoro dell’operazione di backup
- Acquisizione dei dati basata su API – Recupera le configurazioni del cluster e i dati del volume persistente tramite chiamate API Kubernetes, non tramite accesso al filesystem, per garantire la compatibilità con vari backend di storage e ambienti di runtime dei container.
- Distribuzione di pod proxy di backup – Avvia automaticamente pod proxy temporanei (con un basso consumo di risorse) all’interno del cluster per facilitare il trasferimento dei dati del volume persistente; questi pod vengono anche rimossi automaticamente dopo il completamento del backup per evitare un ulteriore consumo di risorse del cluster al di fuori delle finestre di backup.
- Controllo dell’esecuzione configurabile – I comandi pre-backup e post-backup possono essere eseguiti all’interno di pod specifici per creare backup coerenti con l’applicazione dei database o delle applicazioni stateful (quelle che richiedono il quiescing prima dell’acquisizione dei dati).
Controlli dell’operazione di ripristino
- Doppia destinazione di ripristino – Recupera le risorse Kubernetes direttamente nei cluster tramite API o esporta le configurazioni e i dati dei volumi in directory locali per tutti i tipi di scopi.
- Opzioni di denominazione flessibili – I carichi di lavoro possono essere ripristinati con i nomi originali per il ripristino in loco o con nomi nuovi, generati, basati sugli identificatori originali e sui metadati del lavoro (per ambienti di test paralleli o scenari di distribuzione blue-green).
- Recupero selettivo delle risorse – Il plugin offre la possibilità di scegliere tra cluster completi, singoli spazi di nomi, distribuzioni specifiche o singoli volumi persistenti in base ai requisiti dell’ambito di recupero, per evitare il ripristino non necessario dell’infrastruttura non interessata durante le operazioni di recupero mirate.
Amministrazione e monitoraggio
- Console di gestione unificata – Configura e monitora i lavori di backup Kubernetes attraverso l’interfaccia grafica BWeb di Bacula insieme ad altre protezioni dell’infrastruttura, eliminando la necessità di strumenti di amministrazione di backup separati specifici per Kubernetes.
- Automazione da riga di comando – Utilizzi la bconsole per la configurazione dei lavori tramite script, i test di ripristino automatizzati e l’integrazione con i runbook operativi esistenti e le procedure di disaster recovery.
- Registrazione completa – Acquisisce registri operativi dettagliati, comprese le interazioni API, lo stato di elaborazione delle risorse e le metriche di trasferimento dei dati per la risoluzione dei problemi, l’analisi delle prestazioni e la documentazione di conformità.
Vantaggi del modulo di backup e ripristino di Kubernetes
Protezione dei cluster senza agenti
- Integrazione a livello di API – Protegge i cluster Kubernetes attraverso una comunicazione API diretta, senza installare agenti di backup all’interno delle immagini dei container o modificare le specifiche dei pod, eliminando i costi di manutenzione e i problemi di sicurezza associati al software di backup all’interno dei container.
- Zero modifiche all’infrastruttura – Esegue il backup dei cluster in esecuzione senza richiedere modifiche alle distribuzioni, agli StatefulSet o ai grafici Helm, consentendo la protezione dei carichi di lavoro esistenti immediatamente senza ricostruire le immagini o aggiornare i manifesti Kubernetes.
- Rilevamento automatico dei carichi di lavoro – I nuovi spazi dei nomi e le distribuzioni che corrispondono alle politiche di backup ricevono automaticamente la protezione senza configurazione manuale del lavoro, garantendo una copertura coerente con la scalabilità e l’evoluzione dell’infrastruttura Kubernetes.
Acquisizione completa dello stato dell’applicazione
- Backup unificato della configurazione – Cattura tutte le risorse Kubernetes che definiscono il comportamento dell’applicazione, compresi le distribuzioni, i servizi, le ConfigMaps, i segreti, le regole di ingresso e le quote di risorse come set di backup coesivi anziché come componenti isolati.
- Protezione dei dati persistenti – Salvaguarda lo stato dell’applicazione memorizzato nei Persistent Volume Claims insieme alle configurazioni del cluster, assicurando che i carichi di lavoro possano essere ripristinati con i loro dati e non solo con le definizioni vuote dei container.
- Istantanee del cluster coerenti – Coordina il backup dello stato del cluster etcd con i dati dei volumi persistenti per mantenere la coerenza tra la configurazione del piano di controllo di Kubernetes e lo storage effettivo dell’applicazione, evitando il ripristino di stati dell’infrastruttura non corrispondenti.
Operazioni di ripristino flessibili
- Funzionalità di ripristino granulare – Ripristina interi cluster, singoli spazi dei nomi, distribuzioni specifiche o singoli volumi persistenti in base ai requisiti di ripristino, evitando di ripristinare inutilmente l’infrastruttura non interessata durante gli scenari di ripristino mirati.
- Mobilità cross-cluster – Ripristina i carichi di lavoro Kubernetes su cluster diversi per il disaster recovery, la migrazione tra cloud provider o la creazione di ambienti di sviluppo dai backup di produzione, senza dipendere dalla disponibilità del cluster originale.
- Avvio configurabile del carico di lavoro – Può controllare se le applicazioni ripristinate si avviano automaticamente per il ripristino immediato del servizio o se rimangono ferme per la convalida e la revisione della configurazione prima di portare i carichi di lavoro online negli ambienti di produzione.
Integrazione operativa aziendale
- Gestione centralizzata di più cluster – Proteggete più cluster Kubernetes attraverso diverse distribuzioni, cloud provider e installazioni on-premise da un’unica distribuzione di Bacula Enterprise, eliminando la necessità di soluzioni di backup separate per ogni ambiente.
- Protezione unificata dell’infrastruttura – Integra il backup di Kubernetes con i lavori Bacula esistenti che proteggono database, macchine virtuali e server fisici, fornendo politiche di backup, gestione della conservazione e procedure di ripristino coerenti nell’intera infrastruttura IT.
- Automazione basata su criteri – Definisce le pianificazioni di backup, i criteri di conservazione e le destinazioni di archiviazione una sola volta e le applica automaticamente ai cluster Kubernetes che corrispondono ai criteri, riducendo il carico amministrativo e garantendo standard di protezione coerenti.
Distribuzione sicura ed efficiente dei cluster Kubernetes
Gli ambienti DevOps efficaci devono essere scalabili e automatizzati, ove possibile. Bacula Enterprise è progettato per essere stabile, affidabile e altamente scalabile e i suoi moduli di backup dei container mirano ad alleggerire i carichi di lavoro dei reparti IT e DevOps che utilizzano Docker, Kubernetes, SUSE o Openshift. Rende Kubernetes significativamente più sicuro e conveniente da distribuire.
Sia che l’ambiente container implementato venga utilizzato per il lift-and-shift di applicazioni monolitiche, sia che si tratti di refactoring di applicazioni legacy, sia che si tratti di nuove applicazioni distribuite, gli sviluppatori e gli amministratori di sistema possono utilizzare l’avanzata tecnologia di backup Kubernetes di Bacula con un livello di flessibilità particolarmente elevato, sia tramite l’interfaccia GUI che tramite l’interfaccia della riga di comando di Bacula. Ricordiamo che questo alto livello di flessibilità e di possibilità di personalizzazione è fondamentale per l’approccio di Bacula: responsabilizzare l’utente introducendo un’ampia gamma di opzioni per raggiungere i suoi obiettivi.
Perché fare il backup degli ambienti Kubernetes?
Con il crescente passaggio delle applicazioni statiche a Kubernetes, la protezione dei dati persistenti e delle configurazioni dei cluster diventa fondamentale per gli ambienti di produzione. Le organizzazioni devono mantenere gli SLA e garantire che i servizi containerizzati rimangano disponibili negli stati corretti, rendendo il backup e il ripristino efficaci essenziali per qualsiasi implementazione Kubernetes di produzione.
Bacula Enterprise consente la mobilità del cluster attraverso operazioni di ripristino flessibili. Le organizzazioni possono ripristinare volumi e configurazioni persistenti su cluster Kubernetes diversi, supportando la migrazione tra provider cloud, il disaster recovery su siti alternativi e la replica rapida dell’ambiente per i test. Questa flessibilità riduce il vendor lock-in e semplifica le strategie Kubernetes multi-cloud su AWS, GCP, Azure e infrastrutture private.
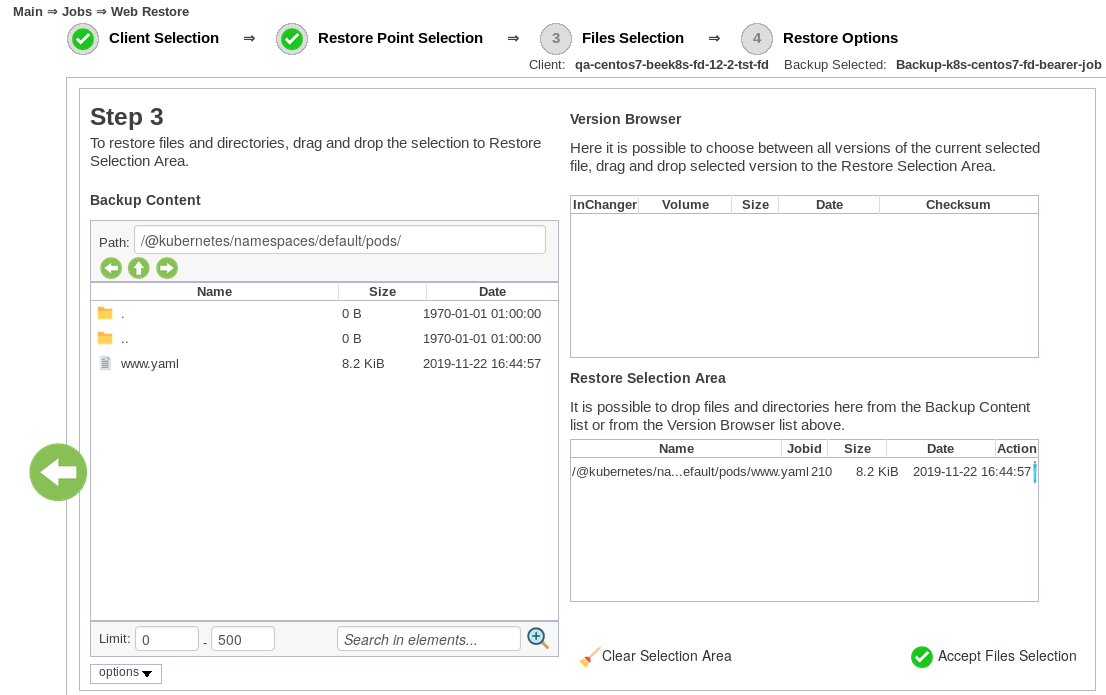
Processo di ripristino Kubernetes
Il modulo di backup di Bacula Kubernetes offre una scelta di due obiettivi per le operazioni di ripristino:
- Ripristino diretto al cluster Kubernetes
- Ripristino in una directory locale
Per garantire le migliori prassi di backup e ripristino per gli ambienti di container Kubernetes, i dati dovrebbero essere sottoposti a backup automatico e gli amministratori di sistema dovrebbero testare regolarmente i backup per assicurarsi che facciano ciò che serve quando è necessario il ripristino.
Funzionalità aziendali di base per ogni utente di Bacula
Il modulo di backup Kubernetes opera all’interno della piattaforma completa di protezione dei dati di Bacula Enterprise. Tutte le funzioni descritte in questa sezione sono funzionalità a livello di piattaforma, disponibili per ogni implementazione Bacula, compresi gli ambienti Kubernetes.
Protezione dei dati e conformità
La sicurezza aziendale e la conformità normativa sono fondamentali per l’architettura di Bacula:
- Crittografia lungo tutta la catena di backup – La crittografia AES-256 protegge le configurazioni Kubernetes, i dati dei volumi persistenti e i backup etcd dall’acquisizione alla trasmissione in rete fino alle destinazioni finali di archiviazione, con una gestione flessibile delle chiavi che supporta architetture sia centralizzate che distribuite.
- Archiviazione resistente ai ransomware – L’integrazione con i sistemi di archiviazione WORM (Write Once, Read Many) e con i target di backup immutabili impedisce la modifica o l’eliminazione non autorizzata dei dati di backup di Kubernetes, proteggendo dagli attacchi ransomware e dalle minacce interne malevole che hanno come obiettivo l’infrastruttura di backup.
- Sistemi di autorizzazioni basati sui ruoli – I controlli di accesso granulari limitano gli amministratori che possono eseguire il backup di specifici spazi dei nomi, ripristinare particolari carichi di lavoro o accedere alle configurazioni del cluster, consentendo la separazione dei compiti e limitando il raggio di esplosione durante gli incidenti di sicurezza.
- Tracciati di audit completi – Ogni operazione di backup, richiesta di ripristino e modifica della configurazione viene registrata con data e ora e attribuzione dell’utente, fornendo i registri dettagliati delle attività necessari per i rapporti di conformità, le analisi di sicurezza e le indagini forensi.
- Allineamento alle normative di settore – Le funzionalità integrate soddisfano i requisiti di GDPR, HIPAA, SOC 2, PCI DSS e le normative specifiche del settore, grazie a controlli di conservazione configurabili, standard di crittografia e registrazioni di audit che dimostrano la conformità alla protezione dei dati.
- Supporto di configurazione a conoscenza zero – L’architettura consente scenari in cui gli amministratori di backup gestiscono le operazioni di protezione di Kubernetes senza accedere ai dati sensibili delle applicazioni, alle ConfigMaps o ai segreti contenuti nei backup.
Recupero e continuità aziendale
Funzionalità di ripristino complete assicurano un rapido recupero da qualsiasi scenario di guasto:
- Movimento dei dati cross-distribuzione – Estrazione e ripristino delle risorse Kubernetes tra distribuzioni e piattaforme diverse, consentendo migrazioni da on-premises a cloud, tra provider cloud o da un sapore Kubernetes a un altro (da EKS a AKS, da Rancher a OpenShift, ecc.).
- Replica di backup multisito – Copia automaticamente i backup di Kubernetes in sedi geograficamente distribuite, proteggendo dai disastri a livello di sito e garantendo la disponibilità del punto di ripristino indipendentemente dallo stato del centro dati primario.
- Programmi di protezione ad alta frequenza – Il supporto di intervalli di backup misurati in minuti anziché in ore offre una protezione quasi continua per le applicazioni containerizzate in rapida evoluzione, riducendo al minimo le finestre di perdita potenziale dei dati.
Infrastruttura di archiviazione ed efficienza
Bacula massimizza il valore dello storage attraverso la gestione intelligente dei dati e la flessibilità della destinazione:
- Deduplicazione globale – Elimina i blocchi di dati duplicati in tutti i backup Kubernetes, indipendentemente dallo spazio dei nomi, dal cluster o dal lavoro di backup, archiviando ogni blocco unico una sola volta per ridurre drasticamente il consumo di spazio.
- Algoritmi di compressione configurabili – Applica una compressione che bilancia il sovraccarico della CPU con il risparmio di spazio in base alle caratteristiche dei dati, con una selezione di algoritmi ottimizzata per i modelli di carico di lavoro di Kubernetes.
- Architettura incrementale perpetua – Dopo il backup completo iniziale, tutte le operazioni successive acquisiscono solo i dati modificati, eliminando i backup completi ricorrenti e i relativi requisiti di tempo e archiviazione.
- Gestione dei dati sparsi – Riconosce ed elabora in modo intelligente i file e i volumi sparsi, eseguendo il backup solo dei blocchi allocati, anziché dello spazio vuoto comunemente presente nelle richieste di volumi persistenti.
- Operazioni efficienti in rete – Gli algoritmi di tracciamento delle modifiche riducono al minimo l’utilizzo della larghezza di banda, trasferendo solo i blocchi modificati tra le esecuzioni di backup, un aspetto critico per i cluster Kubernetes distribuiti su più siti.
- Target di archiviazione eterogenei – Scriva i backup di Kubernetes su array di dischi, archivi NAS/SAN, archiviazione di oggetti nel cloud (S3, Azure Blob, Google Cloud Storage), librerie a nastro o qualsiasi combinazione in base ai requisiti di conservazione e prestazioni.
- Flussi di lavoro di tiering automatizzati – Migra i dati di backup tra le classi di archiviazione in base all’età, ai modelli di accesso o ai criteri personalizzati, spostando automaticamente i backup Kubernetes più vecchi verso l’archiviazione economica a lungo termine.
- Compatibilità universale con S3 – Si integra con qualsiasi provider di storage compatibile con S3, tra cui AWS, MinIO, Wasabi, Backblaze B2 e altri, per una conservazione a lungo termine flessibile ed economica.
Gestione e controllo aziendale
Gli strumenti di amministrazione centralizzata offrono visibilità e controllo delle operazioni di backup Kubernetes:
- Doppia interfaccia di gestione – Scelga tra la console web grafica (BWeb) per la gestione visiva e gli strumenti a riga di comando completi per l’automazione, lo scripting e l’integrazione del flusso di lavoro DevOps.
- Architettura multi-tenant – I service provider e le grandi organizzazioni possono creare ambienti isolati con configurazioni di backup Kubernetes indipendenti, pool di risorse separati, branding personalizzato e confini amministrativi distinti.
- Struttura di reporting dettagliata – Genera rapporti sullo stato del backup, analisi dell’utilizzo dello storage, documentazione sulla conformità, metriche SLA e statistiche sulle prestazioni con consegna programmata agli stakeholder.
- Punti di integrazione esterni – Si connette con piattaforme di monitoraggio, sistemi di ticketing ITSM, soluzioni SIEM e identity provider (LDAP, Active Directory) per operazioni IT unificate e single sign-on.
- Rilevamento automatico delle risorse – Rileva e inventaria cluster Kubernetes, spazi dei nomi, volumi persistenti e implementazioni nell’infrastruttura, con funzionalità di interrogazione a supporto della pianificazione e della verifica dei backup.
- Controlli sull’impatto del carico di lavoro – Regola la concomitanza dei backup, i limiti di larghezza di banda e l’allocazione delle risorse per bilanciare la velocità di protezione con l’impatto sulle prestazioni del cluster Kubernetes di produzione.
- Architettura a scala illimitata – Il design supporta ambienti da singoli cluster di sviluppo a migliaia di installazioni Kubernetes di produzione, sotto una gestione centralizzata con esecuzione di backup distribuita.
Vantaggi economici
Il modello di licenza di Bacula Enterprise elimina gli ostacoli dei prezzi basati sulla capacità:
- Licenze indipendenti dal cluster – Il numero di cluster Kubernetes, namespace, pod o volumi persistenti non influisce sui costi della licenza, consentendo un’espansione illimitata dell’infrastruttura containerizzata senza vincoli di budget.
- Pianificazione prevedibile degli investimenti – La struttura lineare dei prezzi elimina le sorprese di budget quando l’adozione di Kubernetes cresce, il numero di container aumenta o i volumi di dati si espandono in tutta l’organizzazione.
- Modello di costo indipendente dalle risorse – I conteggi dei pod, le quantità di StatefulSet, le dimensioni dei PVC e i volumi di backup etcd non determinano aumenti delle licenze, a differenza dei concorrenti che applicano prezzi basati sulla capacità protetta o sulle unità di risorse.
- Vantaggi economici ad alto volume – Le organizzazioni che proteggono infrastrutture Kubernetes consistenti o in rapida scalata ottengono vantaggi economici sempre più significativi rispetto ai concorrenti con licenze basate sulla capacità.
- Redditività dei fornitori di servizi – Gli MSP e i fornitori di hosting possono offrire funzionalità di backup Kubernetes a livello aziendale, mantenendo margini sani e non limitati dalla crescita dei cluster dei locatari o dall’espansione dei dati.
Domande frequenti
Perché non utilizzare gli strumenti di backup nativi di Kubernetes?
Gli strumenti nativi come etcdctl forniscono istantanee di base del cluster, ma mancano di funzioni aziendali come la crittografia, il reporting di conformità, le politiche di conservazione a lungo termine e la gestione centralizzata su infrastrutture eterogenee. Inoltre, non integrano i backup di Kubernetes con strategie di backup IT più ampie che coprono database, macchine virtuali e server fisici. Bacula Enterprise offre una protezione unificata su tutta l’infrastruttura, soddisfacendo i requisiti normativi e gli standard di audit.
In che modo il backup dei cluster Kubernetes è diverso dal backup delle macchine virtuali?
I cluster Kubernetes sono costituiti da più componenti interconnessi – stato di Etcd, volumi persistenti, ConfigMaps, Secrets e definizioni di risorse – che devono essere acquisiti come un’unità coesa piuttosto che come immagini disco individuali. I backup delle macchine virtuali catturano gli stati interi delle macchine a livello di hypervisor, mentre i backup di Kubernetes richiedono un’integrazione a livello di API per comprendere l’orchestrazione dei container e le dipendenze delle applicazioni. La natura dinamica ed effimera dei pod significa che le soluzioni di backup devono seguire i carichi di lavoro in rapida evoluzione e acquisire separatamente sia la configurazione dell’infrastruttura che i dati delle applicazioni.
Posso eseguire il backup dei cluster Kubernetes mentre sono in esecuzione?
Sì, Bacula esegue backup di cluster Kubernetes in esecuzione senza richiedere tempi di inattività o sospendere i carichi di lavoro. Il plugin acquisisce lo stato del cluster e i dati del volume persistente attraverso l’API Kubernetes, mentre le applicazioni continuano a funzionare normalmente. Per le applicazioni che richiedono coerenza, Bacula può eseguire comandi di pre-backup all’interno dei pod per mettere in quiescenza i database o svuotare i buffer prima di acquisire i dati.
Come faccio a ripristinare una distribuzione Kubernetes diversa?
Bacula ripristina le risorse Kubernetes come configurazioni YAML standard e dati di volume persistenti che possono essere applicati a qualsiasi distribuzione Kubernetes conforme. Durante il ripristino, lei specifica i dettagli di connessione del cluster di destinazione e Bacula ricrea gli spazi dei nomi, le distribuzioni, i servizi e i dati sulla piattaforma di destinazione. Alcune caratteristiche specifiche della distribuzione possono richiedere una regolazione manuale, ma i carichi di lavoro principali si trasferiscono tipicamente tra EKS, AKS, GKE, OpenShift e installazioni Kubernetes standard.
Cosa succede ai miei dati quando i pod vengono eliminati?
I dati del filesystem del pod vengono persi immediatamente quando i pod vengono distrutti, a meno che non si utilizzino volumi persistenti per archiviare esternamente lo stato dell’applicazione. I contenitori effimeri in esecuzione senza PVC perdono tutti i dati scritti durante la loro vita quando vengono terminati. I backup automatizzati del cluster di Bacula catturano sia le configurazioni dei pod necessarie per ricreare i container, sia i dati dei volumi persistenti che contengono lo stato applicativo critico, assicurando un ripristino completo indipendentemente dagli eventi del ciclo di vita dei pod.
Ulteriore aiuto sul backup dei container Kubernetes:
- Vuole vedere tutte le nostre soluzioni di backup? Supporto completo per hypervisor e database.
- Le nostre soluzioni di backup dei server includono strumenti per Windows, Linux e altro ancora.
- Visualizza le caratteristiche del programma di backup e ripristino dei dati di Bacula Enterprise.
- Bacula supporta il suo tipo di storage? Dia un’occhiata alle nostre soluzioni di backup dello storage.
- Legga la nostra visione sui sistemi software di backup flessibili e scalabili.
- È interessato al backup e al ripristino di Sybase? Dia un’occhiata alla nostra soluzione di backup per SAP ASE.
Potresti anche essere interessato a: