

Contents
- Características importantes de una solución de copia de seguridad de Kubernetes competente
- Tipos de datos de los que hay que hacer una copia de seguridad en Kubernetes
- Base de datos Kubernetes etcd
- Archivos Docker
- Imágenes de archivos Docker
- Bases de datos
- Volúmenes persistentes
- Mercado de soluciones de copia de seguridad de Kubernetes
- Kasten K10
- Portworx
- Cohesity
- OpenEBS
- Rancher Longhorn
- Rubrik
- Druva
- Zerto
- La solución de copia de seguridad de Kubernetes de Bacula Enterprise
- Características del módulo Kubernetes de Bacula Enterprise
- Velero & Bacula Enterprise: ¿Cuál es la diferencia?
Aunque la suposición de que Kubernetes se utilizaba antes principalmente por los equipos de DevOps puede haber sido algo correcta, muchas empresas están ahora desplegando activamente contenedores en entornos operativos. También están eligiendo cada vez más los enfoques centrados en los contenedores en lugar de las máquinas virtuales tradicionales. Esto se debe a las diversas ventajas de flexibilidad, rendimiento y coste que los contenedores pueden proporcionar a menudo. Sin embargo, a medida que los contenedores se adentran en el lado de las operaciones del entorno de TI, aumenta la preocupación por los aspectos de seguridad de los contenedores en un entorno de misión crítica, incluidos sus datos persistentes en el contexto de los procesos de copia de seguridad y restauración.
Al principio, la inmensa mayoría de las aplicaciones en contenedores eran sin estado, lo que les permitía tener un proceso de despliegue mucho más fácil en una nube pública. Pero eso cambió con el tiempo, y ahora se despliegan en contenedores muchas más aplicaciones con estado que antes. Este cambio es la razón por la que la copia de seguridad y la recuperación en Kubernetes es ahora un tema importante para muchas organizaciones.
Características importantes de una solución de copia de seguridad de Kubernetes competente
La naturaleza dinámica de los entornos Kubernetes hace más difícil que los sistemas y técnicas de copia de seguridad más tradicionales funcionen bien en el contexto de los nodos y aplicaciones Kubernetes. Tanto el RPO como el RTO deben ser mucho más estrictos, ya que las aplicaciones deben estar constantemente en funcionamiento, o ser especialmente críticas, etc.
Esto nos lleva a discernir tres características diferentes que son muy recomendables para toda empresa en general, y una clara necesidad cuando se trata de las mejores prácticas de copias de seguridad de Kubernetes:
- Recuperación de desastres;
- Copia de seguridad y restauración;
- Alta disponibilidad local.
En un entorno Kubernetes., el contexto de estos tres aspectos de la copia de seguridad puede cambiar ligeramente de su definición normal:
La alta disponibilidad local como característica tiene que ver más con la prevención de fallos/protección desde un centro de datos específico o a través de zonas de disponibilidad (si hablamos de la nube, por ejemplo). Un fallo «local» es el que se produce en la infraestructura/nodo/aplicación utilizada para ejecutar la aplicación. En un escenario perfecto, su solución de copia de seguridad de Kubernetes debería ser capaz de reaccionar ante este fallo manteniendo la aplicación en funcionamiento, lo que significa esencialmente que no hay tiempo de inactividad para el usuario final. Uno de los ejemplos más comunes de un fallo local es un volumen de nube atascado que se produce tras el fallo de un nodo.
Desde esta perspectiva, la alta disponibilidad local como característica puede considerarse una base del sistema global de protección de datos. Por un lado, para llevar a cabo dicha tarea, su solución necesita ofrecer algún tipo de sistema de replicación de datos a nivel local y también tiene que estar en la ruta de datos en primer lugar. Es importante mencionar que proporcionar disponibilidad local mediante la restauración de copias de seguridad sigue considerándose copia de seguridad y restauración y no alta disponibilidad local, debido al tiempo de recuperación global.
Respaldo y restauración es otra parte importante de un sistema de respaldo de Kubernetes. En la mayoría de los casos de uso, realiza una copia de seguridad de toda la aplicación fuera de las instalaciones de un clúster local de Kubernetes. El contexto de Kubernetes también trae a colación otra consideración importante: si el software de copia de seguridad «entiende» lo que se incluye en una aplicación de Kubernetes, como:
- Configuración de la aplicación;
- Recursos de Kubernetes;
- Datos
Una copia de seguridad correcta de Kubernetes debe guardar todas las partes anteriores como una sola unidad para que sea útil en el sistema Kubernetes después de restaurarla. Dirigirse a máquinas virtuales, servidores o discos específicos no significa que un software «entienda» las aplicaciones de Kubernetes. Idealmente, un software para Kubernetes debería ser capaz de realizar copias de seguridad de aplicaciones específicas, grupos específicos de aplicaciones, así como de todo el espacio de nombres de Kubernetes. Esto no quiere decir que sea completamente diferente del proceso de copia de seguridad habitual: las copias de seguridad de Kubernetes también pueden beneficiarse en gran medida de algunas de las características habituales de una copia de seguridad habitual, como la retención, la programación, el cifrado, la clasificación por niveles, etc.
La capacidad de recuperación ante desastres (DR) es probablemente esencial para cualquier organización que utilice Kubernetes en una situación de misión crítica, al igual que en el empleo de cualquier otra tecnología. En primer lugar, la DR necesita «comprender» el contexto de las copias de seguridad de Kubernetes, al igual que la copia de seguridad y la restauración. También puede tener diferentes niveles tanto de RTO como de RPO y diferentes niveles de protección según estos niveles. Por ejemplo, puede haber un requisito estricto de RPO cero que implique estrictamente un tiempo de inactividad cero, o puede haber un RPO de 15 minutos, con requisitos algo menos estrictos. Tampoco es raro que diferentes aplicaciones tengan RTO y RPO completamente diferentes dentro de la misma base de datos.
Otra distinción importante de un sistema de recuperación de desastres específico para Kubernetes es que también debería ser capaz de trabajar con metadatos hasta cierto punto (etiquetas, réplicas de aplicaciones, etc.). La incapacidad de ofrecer esta característica podría conducir fácilmente a una recuperación desarticulada en general, así como a la pérdida de datos en general o a un tiempo de inactividad adicional.
Tipos de datos de los que hay que hacer una copia de seguridad en Kubernetes
Como cualquier sistema complejo, Kubernetes y Docker tienen una serie de tipos de datos específicos que necesitarán para reconstruir toda la base de datos correctamente en caso de desastre. Para hacerlo más fácil, es posible dividir todos los tipos de datos y archivos de configuración en dos categorías diferentes: datos de configuración y datos persistentes.
La configuración (y la información de estado deseado) incluye:
- Base de datos etcd de Kubernetes
- Archivos Docker
- Imágenes de archivos Docker
Los datos persistentes (modificados o creados por los propios contenedores) son:
- Bases de datos
- Volúmenes persistentes
Base de datos Kubernetes etcd
Es una parte integral del sistema que contiene la información sobre los estados del clúster. Se puede hacer una copia de seguridad manual o automática, dependiendo de su solución de copia de seguridad. El método manual es a través del comando etcdctl snapshot save db, que crea un único archivo con el nombre snapshot.db.
Otro método para hacer lo mismo es mediante la activación de ese mismo comando justo antes de crear una copia de seguridad del directorio en el que aparecería este archivo. Esta es una de las formas de integrar esta copia de seguridad específica en todo el entorno.
Archivos Docker
Dado que los propios contenedores Docker se ejecutan a partir de imágenes, estas imágenes tienen que estar basadas en algo, y éstas, a su vez, se crean a partir de archivos Docker. Para una correcta configuración de Docker se recomienda utilizar una especie de repositorio como sistema de control de versiones para la totalidad de sus archivos Docker (GitHub, por ejemplo). Para facilitar la extracción de versiones anteriores, todos los archivos Docker deben almacenarse en un repositorio específico que permita a los usuarios extraer versiones anteriores de esos archivos si es necesario.
También se recomienda un repositorio adicional para los archivos YAML que están asociados a todos los despliegues de Kubernetes, que existen en forma de archivos de texto. Hacer una copia de seguridad de estos repositorios es también una necesidad, utilizando las herramientas de terceros o las capacidades integradas de algo como GitHub.
Es importante mencionar que todavía se puede hacer una copia de seguridad de los archivos Docker, incluso si está ejecutando contenedores desde imágenes sin sus archivos Docker. Hay un comando específico que es docker image history, que le permite crear un archivo Docker desde su imagen actual. También hay varias herramientas de terceros que pueden hacer lo mismo.
Imágenes de archivos Docker
Las propias imágenes Docker también deben ser respaldadas en un repositorio. Tanto el repositorio privado como el público pueden utilizarse para ese mismo fin. Varios proveedores de la nube tienden a proporcionar repositorios privados a sus clientes, también. Si le falta la imagen desde la que se ejecuta su contenedor, un comando específico que sea docker commit debería poder crearle esa imagen.
Bases de datos
La integridad también es crucial cuando se trata de bases de datos que los contenedores utilizan para almacenar sus datos. En algunos casos, es posible apagar el contenedor en cuestión antes de crear una copia de seguridad de los datos, pero, de nuevo, el tiempo de inactividad que se requiere es probable que provoque muchos problemas a la empresa en cuestión.
Otro método para hacer copias de seguridad de la base de datos dentro de los contenedores es mediante la conexión al propio motor de la base de datos. Se debe utilizar un montaje bind de antemano para adjuntar un volumen del que se pueda hacer una copia de seguridad en primer lugar, y luego se puede utilizar el comando mysqldump (o similar) para crear una copia de seguridad. El archivo de copia de seguridad en cuestión también debería ser respaldado posteriormente mediante su sistema de copia de seguridad.
Volúmenes persistentes
Es justo decir que hay múltiples métodos diferentes para que los contenedores tengan acceso a una especie de almacenamiento persistente. Si se trata de volúmenes tradicionales de Docker, éstos residen en un directorio que se encuentra debajo de la configuración de Docker. Los montajes Bind, por otro lado, pueden ser cualquier directorio que se monte dentro de un contenedor. A pesar de que los volúmenes tradicionales son más preferidos en la comunidad Docker, ambos son relativamente iguales cuando se trata de hacer una copia de seguridad de los datos. Una tercera forma de realizar la misma operación es mediante el montaje de un directorio NFS o de un objeto único como volumen dentro de un contenedor.
Estos tres métodos tienen el mismo problema cuando se trata de hacer una copia de seguridad de los datos: la consistencia de una copia de seguridad no es completa si los datos dentro de un contenedor cambian a mitad de la copia de seguridad. Por supuesto, siempre es posible ganar consistencia apagando el volumen antes de hacer la copia de seguridad, pero en la mayoría de los casos el tiempo de inactividad de estos sistemas está básicamente fuera de lugar en aras de la continuidad del negocio.
Hay algunas formas de hacer copias de seguridad de los datos dentro de los contenedores que son específicas del método. Por ejemplo, los volúmenes tradicionales de Docker podrían montarse en otro contenedor que no modificara ninguno de los datos hasta que se completara el proceso de copia de seguridad. O si está utilizando un volumen montado en bind, es posible crear una imagen tar de un volumen completo y luego hacer una copia de seguridad de la imagen.
Por desgracia, todas esas opciones son realmente difíciles de llevar a cabo cuando se trata de Kubernetes. Por esa misma razón, siempre se recomienda almacenar la información de estado en la base de datos y fuera del sistema de archivos del contenedor.
Dicho esto, si está utilizando un directorio montado en bind o un sistema de archivos montado en NFS como almacenamiento persistente, también es posible hacer una copia de seguridad de esos datos utilizando los métodos habituales, como una instantánea. Esto debería conseguirle mucha más consistencia que la tradicional copia de seguridad a nivel de archivo del mismo volumen.
Mercado de soluciones de copia de seguridad de Kubernetes
En el contexto de estos tres importantes factores/características, veamos algunos ejemplos más de una solución de copia de seguridad y recuperación de Kubernetes. Los ejemplos que utilizamos aquí son Kasten, Portworx, Cohesity, OpenEBS y Rancher Longhorn.
Kasten K10
Kasten K10 (recientemente adquirida por Veeam) es una solución de backup y restauración que también se enorgullece de sus sistemas de movilidad y recuperación de desastres. El proceso de copia de seguridad con Kasten se simplifica gracias a su capacidad para descubrir automáticamente las aplicaciones, así como a otras muchas características, como el cifrado de datos, el control de acceso basado en roles y una interfaz fácil de usar. Al mismo tiempo, puede trabajar con muchos servicios de datos diferentes, como MySQL, PostgreSQL, MongoDB, Cassandra, AWS, etc.
La alta disponibilidad local no está disponible con él, ya que Kasten no admite directamente la replicación dentro de un único clúster y depende, en cambio, de los sistemas de almacenamiento de datos subyacentes. La recuperación de desastres también está sólo parcialmente «ahí» ya que Kasten no puede lograr casos de RPO cero debido a la falta de un componente de ruta de datos. También cabe destacar el hecho de que las copias de seguridad de Kasten son únicamente asíncronas, lo que suele suponer un tiempo de inactividad adicional entre las operaciones.
Portworx
Portworx PX-Backup es una empresa de gestión de datos que desarrolla una plataforma de almacenamiento en la nube para gestionar y acceder a la base de datos de los proyectos Kubernetes. Es otro ejemplo de solución de gestión de datos y, a pesar de sus limitaciones como tal, una de las principales ventajas de utilizar Portworx es la alta disponibilidad de los datos.
Las operaciones de copia de seguridad y recuperación, la comprensión de las aplicaciones de Kubernetes, la alta disponibilidad local y la recuperación de desastres, entre otras características, hacen de Portworx una buena solución para la copia de seguridad de Kubernetes, si lo que busca es una solución especializada en tareas relacionadas con Kubernetes.
Otra parte importante de PX-Backup es su escalabilidad, que permite realizar copias de seguridad bajo demanda / programadas de cientos de aplicaciones a la vez. La solución también admite configuraciones de múltiples bases de datos y puede restaurar aplicaciones directamente en los servicios de la nube, como Amazon, Google, Microsoft, etc.
Cohesity
Cohesity es un competidor relativamente popular en el campo de las copias de seguridad y recuperación en general, pero sus capacidades relacionadas con Kubernetes todavía tienen algo de espacio para crecer. En primer lugar, Kubernetes es una adición relativamente nueva para ellos, y han añadido la «comprensión» para las aplicaciones de Kubernetes desde el principio, pero al mismo tiempo sólo funciona para todas las aplicaciones dentro del mismo espacio de nombres, y no se pueden proteger aplicaciones específicas dentro de ese espacio de nombres.
Por otro lado, también hay capacidades de recuperación rápida, copias de seguridad incrementales de las aplicaciones basadas en políticas, consolidación del estado de los datos y muchas otras capacidades.

OpenEBS
OpenEBS es otro ejemplo de solución que ha conseguido algunos resultados con sólo una de las tres características de nuestra lista, y en este caso se trata de alta disponibilidad local.
Al mismo tiempo, OpenEBS también puede integrarse con Velero, creando una solución combinada de Kubernetes que destaca en la migración de datos de Kubernetes. OpenEBS, por sí solo, sólo puede realizar copias de seguridad de aplicaciones individuales (algo directamente opuesto a lo que hace Cohesity). También cuenta con características como el almacenamiento en varias nubes, su naturaleza de código abierto y una gigantesca lista de plataformas Kubernetes compatibles, desde AWS y Digital Ocean hasta Minikube, Packet, Vagrant, GCP y otras.
Sin embargo, es posible que esto no cubra las necesidades de los usuarios, ya que algunos pueden necesitar esas copias de seguridad del espacio de nombres en casos de uso específicos.
Rancher Longhorn
Rancher Longhorn es el último de nuestros ejemplos, y este es probablemente el menos conocido de todos. Su comunidad es relativamente pequeña para una solución de código abierto, y no permite realizar copias de seguridad completas de Kubernetes con metadatos y recursos para realizar una recuperación consciente de las aplicaciones. Sin embargo, hay una característica única en ella que destaca, y se llama DR Volume. DR Volume puede configurarse como fuente y como destino, haciendo que el volumen se active en un nuevo clúster que se basa en los últimos datos respaldados.
Las capacidades de Rancher para trabajar con muchos tipos de plataformas de contenedores diferentes y permitir diferentes métodos de copia de seguridad son lo que lo diferencia del resto, y ya existe la capacidad de soportar el motor Kubernetes, los despliegues Docker y las distribuciones K3. Los contenedores Docker, por ejemplo, tienen que crear un tarball que podría actuar como copia de seguridad para Rancher.
Rubrik
Muchos otros actores de mayor envergadura en el campo de la copia de seguridad y la recuperación han comenzado a ofrecer sus propios servicios en términos de copia de seguridad y restauración de Kubernetes – Rubrik es un buen ejemplo: permite a los usuarios implementar el amplio conjunto de características de gestión de Rubrik en el campo de las implementaciones de Kubernetes.
Permite la flexibilidad en cuanto al destino de la restauración, así como la protección de los objetos de Kubernetes y una plataforma unificada que proporciona una visión general de todo el sistema. También cuenta con funciones como la automatización de las copias de seguridad, la recuperación granular, la replicación de instantáneas, etc. Rubrik también puede trabajar con Volúmenes Persistentes y es capaz de replicar espacios de nombres, ofreciéndole la variación cuando se trata de desarrollo y/o pruebas antes del despliegue.
Druva
Otra variante de este tipo de solución es la presentada por Druva, que ofrece una solución de copia de seguridad y restauración de Kubernetes bastante sencilla pero eficaz, con todas las características básicas esperadas: instantáneas, copia de seguridad y restauración, automatización y algunas funcionalidades adicionales. Druva también puede restaurar aplicaciones enteras dentro de Kubernetes, con mucha movilidad en cuanto al destino de la restauración.
Además, Druva admite múltiples roles de administrador, puede crear copias de cargas de trabajo para la resolución de problemas y realizar copias de seguridad de áreas específicas como espacios de nombres o grupos de aplicaciones. También hay una variedad de opciones de retención, una protección completa de los datos de Kubernetes, soporte para Amazon EC2 y EKS (cargas de trabajo de contenedores personalizados).
Zerto
Zerto también es una buena opción si busca una plataforma de gestión de copias de seguridad multifuncional con soporte nativo para Kubernetes. Ofrece todo lo que puede desear de una solución moderna de copia de seguridad y restauración de Kubernetes: CDP (protección continua de datos), replicación de datos a través de instantáneas y una mínima dependencia del proveedor gracias a que Zerto es compatible con todas las plataformas Kubernetes del ámbito empresarial.
Zerto también ofrece la protección de datos como una de las estrategias principales desde el primer día, ofreciendo a las aplicaciones la posibilidad de generarse con protección desde el principio. Zerto también tiene muchas capacidades de automatización, es capaz de proporcionar una amplia información y puede trabajar con diferentes almacenamientos en la nube a la vez.

Como queda claro en este blog, el tema de Kubernetes es aún relativamente nuevo y el mercado todavía está tratando de ponerse al día con la lista completa de características que cualquier sistema basado en Kubernetes exige desde el principio. Toda la naturaleza de Kubernetes convierte a las aplicaciones en un animal muy diferente de lo que eran antes, y esto nos lleva a la lista actual de soluciones que destacan en una cosa y luchan por ponerse al día en la otra.
Evidentemente, Kubernetes es un área tecnológica en rápido crecimiento, por lo que es seguro decir que pronto aparecerán más soluciones, y que las actuales probablemente serán aún mejores de lo que son ahora. Un ejemplo de una nueva y potente solución de Kubernetes está representado en Bacula Enterprise.
La solución de copia de seguridad de Kubernetes de Bacula Enterprise
La propia naturaleza de los entornos Kubernetes los hace a la vez muy dinámicos y potencialmente complejos. Hacer una copia de seguridad de un clúster Kubernetes no debería añadir innecesariamente complejidad. Y, por supuesto, suele ser importante -si no crítico- que los administradores de sistemas y otro personal de TI tengan un control centralizado sobre el sistema completo de copias de seguridad y recuperación de toda la organización, incluyendo cualquier entorno Kubernetes. De este modo, factores como el cumplimiento, la capacidad de gestión, la velocidad, la eficiencia y la continuidad del negocio se vuelven mucho más realistas. Al mismo tiempo, el enfoque ágil de los equipos de desarrollo no debe verse comprometido de ninguna manera.
Bacula Enterprise es único en este espacio porque es una solución empresarial integral para entornos de TI completos (no sólo Kubernetes) que también ofrece copia de seguridad y recuperación de Kubernetes integrada de forma nativa, incluyendo múltiples clústeres, tanto si las aplicaciones o los datos residen fuera como dentro de un clúster específico. El departamento de operaciones de toda empresa reconoce la necesidad de contar con una estrategia de recuperación adecuada cuando se trata de la recuperación de clústeres, actualizaciones y otras situaciones. Un clúster que se encuentra en un estado irrecuperable puede ser revertido al estado estable con Bacula si tanto los archivos de configuración como los volúmenes persistentes del clúster fueron respaldados correctamente de antemano.
Otra forma de mostrar los métodos de trabajo de Bacula es mediante la imagen siguiente:
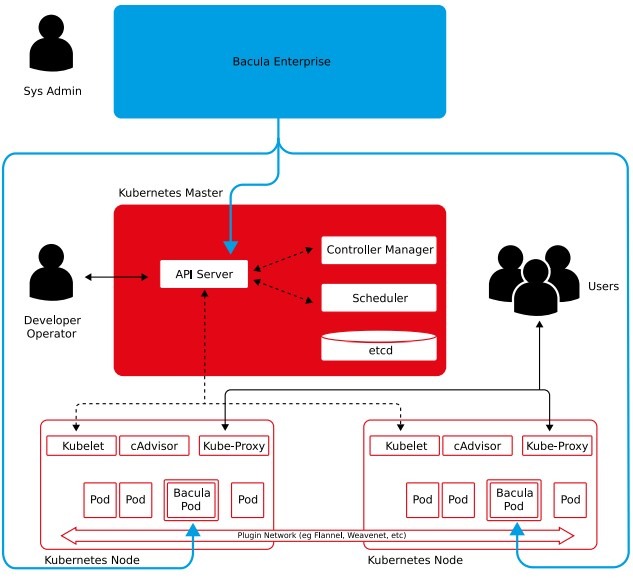
Una de las principales ventajas del módulo Kubernetes de Bacula es la posibilidad de realizar copias de seguridad de varios recursos de Kubernetes, entre ellos:
- Pedazos;
- Servicios;
- Despliegues;
- Volúmenes persistentes;
Características del módulo Kubernetes de Bacula Enterprise
El funcionamiento de este módulo consiste en que la solución en sí misma no forma parte del entorno de Kubernetes, sino que accede a los datos relevantes dentro del clúster a través de los pods de Bacula que se adjuntan a los nodos individuales de Kubernetes en un clúster. El despliegue de estos pods es automático y funciona en función de las necesidades.
Algunas otras características que el módulo de copia de seguridad de Kubernetes también incluye son:
- Respaldo y restauración de Kubernetes para volúmenes persistentes;
- Restauración de un único recurso de configuración de Kubernetes;
- La capacidad de restaurar archivos de configuración y/o datos de volúmenes persistentes al directorio local;
- La capacidad de hacer una copia de seguridad de la configuración de los recursos de los clústeres de Kubernetes.
También cabe destacar que Bacula admite fácilmente varias plataformas de almacenamiento en la nube de forma simultánea, incluidas las de AWS, Google, Glacier, Oracle Cloud y Azure, a nivel de integración nativa. Por lo tanto, las capacidades de la nube híbrida están incorporadas, incluyendo la gestión avanzada de la nube y las funciones de almacenamiento automatizado en la nube, lo que permite una fácil integración de los servicios de la nube pública o privada para apoyar diversas tareas.
La flexibilidad de la solución es especialmente importante hoy en día, ya que muchas empresas y compañías son cada vez más complejas en cuanto a las diferentes familias de hipervisores y contenedores. Al mismo tiempo, esto aumenta significativamente la demanda de flexibilidad de los proveedores de bases de datos. Las capacidades de Bacula en este sentido son sustancialmente elevadas, ya que combina su amplia lista de compatibilidad con diversas tecnologías para alcanzar unos estándares de flexibilidad especialmente elevados sin encerrarse en un solo proveedor.
La complejidad cada vez mayor de los diferentes aspectos del trabajo de cualquier organización aumenta constantemente, y la mayoría de las veces es más fácil y rentable utilizar una solución para todo el entorno de TI, y no varias soluciones a la vez. Bacula está diseñado para hacer exactamente esto, y también es capaz de proporcionar tanto una interfaz tradicional basada en la web para sus necesidades de configuración, como el clásico control de tipo línea de comandos. Estas dos interfaces pueden incluso utilizarse simultáneamente.
El plugin de copia de seguridad de Kubernetes de Bacula permite dos tipos de objetivos principales para las operaciones de restauración:
- Restaurar en un directorio local;
- Restaurar en un clúster.
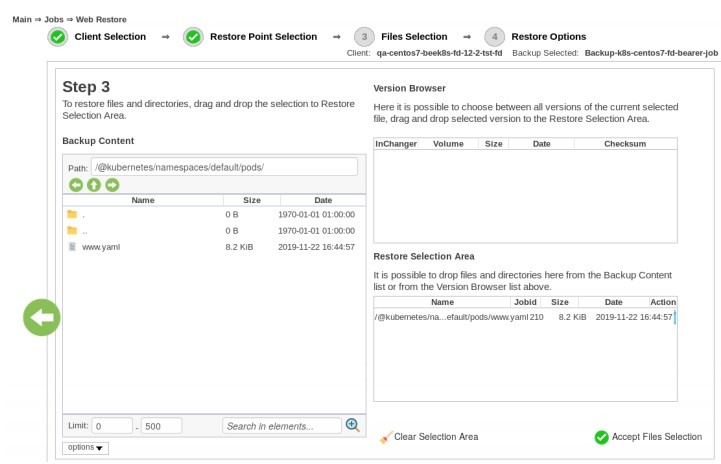
Las copias de seguridad periódicas y/o automatizadas son muy recomendables para garantizar el mejor entorno posible de copia de seguridad y recuperación de los contenedores. Probar las copias de seguridad de vez en cuando también debería ser obligatorio para el administrador del sistema. En la siguiente imagen, verá una parte del proceso de restauración, concretamente la parte de Selección de Restauración, en la que puede elegir qué archivos y/o directorios quiere restaurar:
Otra parte del proceso de restauración que encontrarás es la página de opciones avanzadas de restauración, que tiene este aspecto:
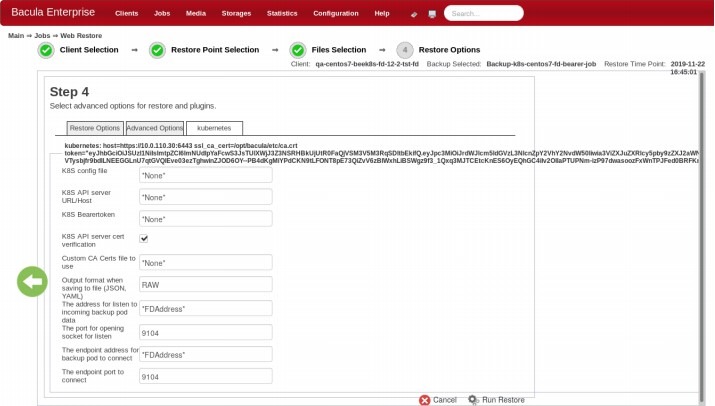
Aquí puedes especificar múltiples opciones diferentes, como el formato de salida, la ruta del archivo de configuración de KBS, el puerto del punto final, y más.
También es fácil vigilar todo el proceso de restauración después de la personalización, gracias a la página de registro de trabajos de restauración que escribe cada acción una por una:
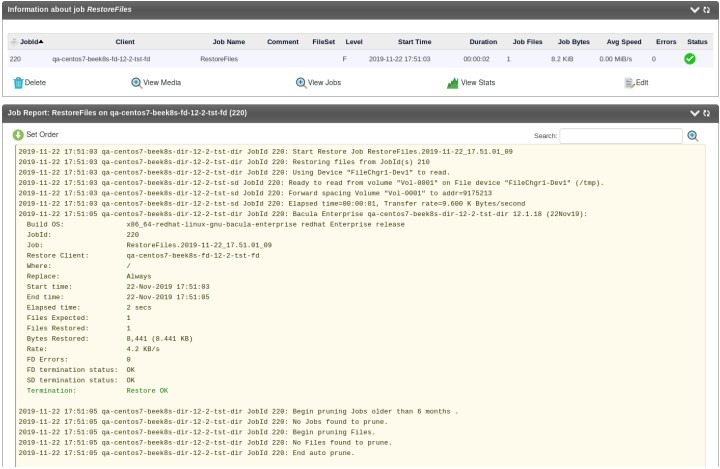
Otra capacidad importante del módulo Kubernetes es la función de listado de plugins, que ofrece mucha información útil sobre sus recursos Kubernetes disponibles, incluidos los espacios de nombres, los volúmenes persistentes, etc. Para ello, el módulo utiliza un comando especial .ls con un parámetro específico plugin=<plugin>.
El módulo Kubernetes de Bacula ofrece una variedad de características, algunas de las cuales son:
- Redistribución rápida y eficiente de los recursos del clúster;
- Salvaguarda del estado del clúster de Kubernetes;
- Guardar las configuraciones para utilizarlas en otras operaciones;
- Manteniendo las configuraciones modificadas tan seguras como sea posible y restaurando exactamente el mismo estado que antes.
Aunque esto ocurre a menudo, es muy recomendable evitar pagar a su proveedor en función del volumen de datos. No tiene sentido que un proveedor que está dispuesto a aprovecharse de su organización de esta manera le exija un rescate ahora o en el futuro. En su lugar, fíjese bien en los modelos de licencia de Bacula Systems, que eliminan a sus clientes de la exposición a los cargos por crecimiento de datos, a la vez que facilitan a los departamentos de compras de los clientes la previsión de los costes futuros. Este enfoque más razonable de Bacula proviene de sus raíces de código abierto y resuena bien en un entorno DevOps.
Velero & Bacula Enterprise: ¿Cuál es la diferencia?
Eso no quiere decir que no haya otras soluciones en el mercado, tanto de primera calidad como gratuitas. Por ejemplo, Velero.
Velero (antes llamado Heptio Ark) es una solución de copia de seguridad y restauración gratuita de código abierto que se centra principalmente en el trabajo con clústeres Kubernetes / volúmenes persistentes. Tiene la capacidad de trabajar con un número de diferentes plataformas de nube a través de plugins específicos, y usted puede elegir si desea ejecutarlo en las instalaciones o dentro de la plataforma de nube pública de su elección.
Los tres principales campos de destino de las capacidades de Velero son:
- Replicación de clústeres de producción con fines de prueba o desarrollo;
- Capacidades generales de copia de seguridad y restauración para clústeres Kubernetes;
- Función de migración de clústeres.
La idea de cómo funciona Velero consiste en dos partes principales: un servidor que trabaja dentro de su clúster y un cliente local representado por una línea de comandos para sus necesidades operativas. También es bastante único en la forma en que funciona con los clústeres de Kubernetes, también.
La forma en que funciona es que la API de Kubernetes se utiliza para capturar el estado específico de los clústeres y realizar el proceso de restauración cuando sea necesario. Esto es diferente de lo que hacen la mayoría de las demás soluciones: acceden directamente a las bases de datos etcd de Kubernetes e interactúan con los datos en cuestión a través de ellas (Bacula Pods es uno de esos ejemplos). Las ventajas de hacerlo todo a través de la API son las siguientes:
- Incluso si los recursos que se exponen a través de la API se almacenan en una base de datos separada – todavía pueden ser rápida y eficientemente respaldados y/o restaurados;
- Las copias de seguridad pueden ser algo selectivas, capturando subconjuntos específicos de los recursos de un clúster, filtrados por tipo de recurso, espacio de nombres, etc., esto proporciona mucha más flexibilidad en cuanto a los datos de los que se quiere hacer una copia de seguridad;
- No es raro que los usuarios de ofertas gestionadas de Kubernetes no tengan acceso a la base de datos subyacente de etcd, lo que hace que las copias de seguridad y las restauraciones directas sean básicamente imposibles y obligan a utilizar diversas soluciones alternativas.
Cuando se trata de comparar directamente Velero y Bacula, se puede decir que cada uno tiene sus propias ventajas y beneficios.
Bacula es mucho más completo en cuanto a ser una solución de copia de seguridad y recuperación amplia y empresarial, y ofrece una gama especialmente amplia de funciones y tecnologías que cabría esperar de una solución de alto nivel empresarial. Por lo tanto, Bacula ofrece una solución completa de copia de seguridad en una sola plataforma para empresas medianas y grandes. Bacula también cuenta con ‘BWeb’; una completa interfaz web para las numerosas funciones que ofrece. Bacula es probablemente la solución que elegiría un director de TI cuando necesite realizar copias de seguridad de entornos de TI complejos y cambiantes utilizando una única y moderna plataforma.
Velero, por otro lado, es específico en el sentido de que no intenta cubrir todos los aspectos de las copias de seguridad de todas las aplicaciones, datos y tipos de almacenamiento, sino que se centra únicamente en el trabajo con Kubernetes. Algunos usuarios podrían encontrar esto más atractivo que una solución «todo en uno». También está el enfoque único que adopta Velero para trabajar con los datos y las copias de seguridad: a través de la API. Y lo último, pero definitivamente no lo menos importante – es gratuito y de código abierto. A pesar de todas las ventajas que tiene Bacula, está diseñado para ser una solución de gama alta para medianas y grandes empresas, y eso, por supuesto, no es representativo de todos los usuarios de Kubernetes.

